


One obvious concern about the criterion described here is its computational cost. In situations where obtaining new examples may take days and cost thousands of dollars, it is clearly wise to expend computation to ensure that those examples are as useful as possible. In other situations, however, new data may be relatively inexpensive, so the computational cost of finding optimal examples must be considered.
Table 1 summarizes the computation times for the two
learning algorithms discussed in this paper. Note
that, with the mixture of Gaussians, training time depends linearly on
the number of examples, but prediction time is
independent. Conversely, with locally weighted regression, there is no
``training time'' per se, but the cost of additional examples accrues
when predictions are made using the training set.
Note
that, with the mixture of Gaussians, training time depends linearly on
the number of examples, but prediction time is
independent. Conversely, with locally weighted regression, there is no
``training time'' per se, but the cost of additional examples accrues
when predictions are made using the training set.
While the training time incurred by the mixture of Gaussians may make
it infeasible for selecting optimal action learning actions in
realtime control, it is certainly fast enough to be used in many
applications. Optimized, parallel implementations will also enhance
its utility. Locally
weighted regression is certainly fast enough for many control
applications, and may be made faster still by optimized, parallel
implementations. It is worth noting that, since the prediction speed
of these learners depends on their training set size, optimal data
selection is doubly important, as it creates a parsimonious training
set that allows faster predictions on future points.
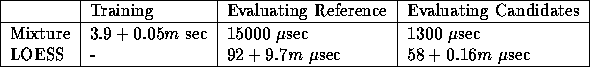
Table 1:
Computation times on a Sparc 10 as a function of training set size
m. Mixture model had 60 Gaussians trained for 20 iterations.
Reference times are per reference point; candidate times are per
candidate point per reference point.