


Next: Evaluation of WOLFIE
Up: Our Solution: WOLFIE
Previous: Candidate Generation Phase
After deriving initial candidates, the greedy search begins. The
heuristic used to evaluate candidates attempts to help
assure that a small but covering lexicon is learned. The heuristic first looks
at the weighted
sum of two components, where p is the phrase and m
its candidate meaning:
- 1.
-
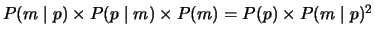
- 2.
- The generality of m
Then, ties in this value are broken by preferring
less ambiguous (those with fewer current meanings) and shorter
phrases.
The first component is analogous the cluster evaluation heuristic
used by COBWEB [Fisher1987], which measures the utility
of clusters based on attribute-value pairs and categories, instead of
meanings and phrases. The probabilities are
estimated from the training data and then updated as learning
progresses to account for phrases and meanings already covered.
We will see how this updating works as we continue through our example of
the algorithm.
The goal of this part of the heuristic is to maximize the
probability of predicting the correct meaning for a randomly sampled
phrase. The equality holds by Bayes Theorem. Looking at the right
side,
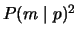 is the expected probability that meaning m is
correctly guessed for a given phrase, p. This assumes a strategy of
probability matching, in which a meaning m is chosen for p with
probability
is the expected probability that meaning m is
correctly guessed for a given phrase, p. This assumes a strategy of
probability matching, in which a meaning m is chosen for p with
probability
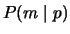 and correct with the same probability. The
other term, P(p), biases the component by how common the phrase is.
Interpreting the left side of the equation, the first term biases
towards lexicons with low ambiguity, the second towards low synonymy,
and the third towards frequent meanings.
The second component of the heuristic, generality, is computed
as the negation of the number of vertices in the meaning's tree
structure, and helps prefer smaller, more general meanings.
For
example, in the candidate set above, if all else were equal, the
generality portion of the heuristic would prefer state(_), with
generality value -1, over largest(_,state(_)) and
(state(S),loc(_,S)), each with generality value -2, as the meaning
of ``estado''.
Learning a meaning with fewer terms helps evenly distribute the vertices
in a sentence's representation among the meanings of the phrases in
that sentence, and thus leads to a lexicon that is more likely to be
correct. To see this, we note that some pairs of words tend to
frequently co-occur (``grande'' and ``estado'' in our example),
and so their joint representation (meaning) is likely to be in the
set of candidate meanings for both words. By preferring a more
general meaning, we easily ignore these incorrect joint meanings.
In this example and all experiments, we use a weight of 10 for the
first component of the heuristic, and a weight of 1 for the second.
The first component has smaller absolute values and is therefore given
a higher weight. Modulo this consideration,
results are not overly-sensitive to the weights and
automatically setting them using cross-validation on the training set
[Kohavi John1995] had little effect on overall performance.
In Table 2 we illustrate the calculation of the
heuristic measure for some of the above fourteen pairs, and its value
for all. The calculation shows the sum of multiplying
10 by the first component of the
heuristic and multiplying 1 by the second component.
The first component is simplified as follows:
and correct with the same probability. The
other term, P(p), biases the component by how common the phrase is.
Interpreting the left side of the equation, the first term biases
towards lexicons with low ambiguity, the second towards low synonymy,
and the third towards frequent meanings.
The second component of the heuristic, generality, is computed
as the negation of the number of vertices in the meaning's tree
structure, and helps prefer smaller, more general meanings.
For
example, in the candidate set above, if all else were equal, the
generality portion of the heuristic would prefer state(_), with
generality value -1, over largest(_,state(_)) and
(state(S),loc(_,S)), each with generality value -2, as the meaning
of ``estado''.
Learning a meaning with fewer terms helps evenly distribute the vertices
in a sentence's representation among the meanings of the phrases in
that sentence, and thus leads to a lexicon that is more likely to be
correct. To see this, we note that some pairs of words tend to
frequently co-occur (``grande'' and ``estado'' in our example),
and so their joint representation (meaning) is likely to be in the
set of candidate meanings for both words. By preferring a more
general meaning, we easily ignore these incorrect joint meanings.
In this example and all experiments, we use a weight of 10 for the
first component of the heuristic, and a weight of 1 for the second.
The first component has smaller absolute values and is therefore given
a higher weight. Modulo this consideration,
results are not overly-sensitive to the weights and
automatically setting them using cross-validation on the training set
[Kohavi John1995] had little effect on overall performance.
In Table 2 we illustrate the calculation of the
heuristic measure for some of the above fourteen pairs, and its value
for all. The calculation shows the sum of multiplying
10 by the first component of the
heuristic and multiplying 1 by the second component.
The first component is simplified as follows:
where
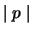 is the number of times phrase p appears in the
corpus, t is the initial number of candidate phrases,
and
is the number of times phrase p appears in the
corpus, t is the initial number of candidate phrases,
and
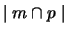 is the number of times that meaning
m is paired with phrase p. We can ignore t
since the number of phrases in the corpus is the same for each pair, and has
no effect on the ranking.
is the number of times that meaning
m is paired with phrase p. We can ignore t
since the number of phrases in the corpus is the same for each pair, and has
no effect on the ranking.
Table 2:
Heuristic Value of Sample Candidate Lexical Entries
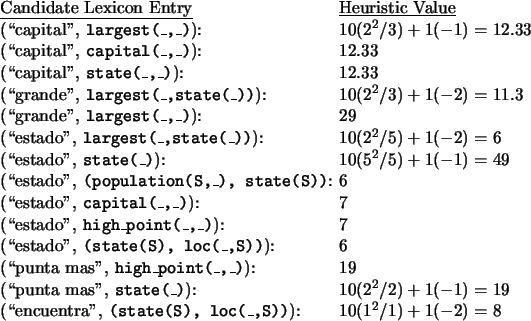 |
The highest scoring pair is (``estado'', state(_)),
so it is added to the lexicon.
Next is the candidate generalization step (2.2), described
algorithmically in Figure 8. One of the key
Figure 8:
The Candidate Generalization Phase
 |
ideas of the algorithm is that each phrase-meaning choice can
constrain the candidate meanings of phrases yet to be learned.
Given
the assumption that each portion of the representation is due to at
most one phrase in the sentence (exclusivity), once part of a
representation is covered, no other phrase in the sentence can be
paired with that meaning (at least for that sentence). Therefore, in
step 2.2 the candidate meanings for words in the same sentences as the
word just learned are generalized to exclude the representation just
learned. We use an operation analogous to set difference when finding the
remaining uncovered vertices of the representation when generalizing
meanings to eliminate covered vertices from candidate pairs. For
example, if the meaning largest(_,_) were learned for a
phrase in sentence 2, the meaning left behind would be a forest
consisting of the trees
high_point(S,_) and (state(S), area(S,_)).
Also, if
the generalization results in an empty tree, new LICS are calculated.
In our example, since state(_) is covered in sentences 1, 2,
3, 6, and 7, the candidates for several other words in those sentences
are generalized. For example, the meaning (state(S), loc(_,S))
for ``encuentra'', is generalized to loc(_,_), with a new
heuristic value of
10(12/1) + 1(-1)=9. Also, our single-use
assumption allows us to remove all candidate pairs containing
``estado'' from the set of candidate meanings, since the learned pair covers all occurrences
of ``estado'' in that set.
Note that the pairwise matchings to generate candidate items, together
with this updating of the candidate set, enable multiple meanings to
be learned for ambiguous phrases, and makes the algorithm less
sensitive to the initial rate of sampling for LICS. For example, note that
``capital'' is ambiguous in this data set, though its ambiguity is an
artifact of the way that the query language was designed, and one
does not ordinarily think of it as an ambiguous word. However, both
meanings will be learned: The second pair added to the final lexicon
is (``grande'', largest(_,_)), which causes a
generalization to the empty meaning for the first candidate entry in
Table 2, and since no new LICS from sentence 4 can be
generated, its entire remaining meaning is added to the candidate
meaning set for both ``capital'' and ``más.''
Subsequently, the greedy search continues until the resulting
lexicon covers the training corpus, or until no candidate phrase
meanings remain.
In rare cases, learning errors occur that leave some
portions of representations uncovered.
In our example, the following lexicon is learned:
(``estado'', state(_)),
(``grande'', largest(_)),
(``area'', area(_)),
(``punta'', high_point(_,_)),
(``población'', population(_,_)),
(``capital'', capital(_,_)),
(``encuentra'', loc(_,_)),
(``alta'', loc(_,_)),
(``bordean'', next_to(_)),
(``capital'', capital(_)).
In the next section, we discuss the ability of WOLFIE to learn lexicons that are useful for parsers and parser acquisition.
Next: Evaluation of WOLFIE
Up: Our Solution: WOLFIE
Previous: Candidate Generation Phase
Cindi Thompson
2003-01-02