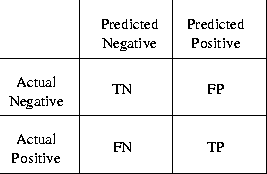
Predictive accuracy is the performance measure generally associated with machine learning algorithms and is defined as Accuracy = (TP+TN)/(TP+FP+TN+FN). In the context of balanced datasets and equal error costs, it is reasonable to use error rate as a performance metric. Error rate is 1-Accuracy. In the presence of imbalanced datasets with unequal error costs, it is more appropriate to use the ROC curve or other similar techniques [19,23,1,13,24].
 |
ROC curves can be thought of as representing the family of best decision
boundaries for relative costs of TP and FP. On an ROC curve the X-axis
represents ![]() and the Y-axis represents
and the Y-axis represents ![]() .The ideal point on the ROC curve would be (0,100), that is all positive
examples are classified correctly
and no negative examples are misclassified as positive. One way an ROC
curve can be swept out is by manipulating the balance of training samples for each class in the
training set. Figure 2 shows an illustration.
The line y = x represents the scenario of randomly guessing the class. Area Under
the ROC Curve (AUC) is a useful metric for classifier performance as it is independent of the
decision criterion selected and prior probabilities. The AUC comparison can establish a dominance
relationship between classifiers. If the ROC curves are intersecting, the total AUC is an average
comparison between models [14]. However, for some specific cost and class distributions, the
classifier having maximum AUC may in fact be suboptimal. Hence, we also compute the ROC convex hulls,
since the points lying on the ROC convex hull are potentially optimal
[25,1].
.The ideal point on the ROC curve would be (0,100), that is all positive
examples are classified correctly
and no negative examples are misclassified as positive. One way an ROC
curve can be swept out is by manipulating the balance of training samples for each class in the
training set. Figure 2 shows an illustration.
The line y = x represents the scenario of randomly guessing the class. Area Under
the ROC Curve (AUC) is a useful metric for classifier performance as it is independent of the
decision criterion selected and prior probabilities. The AUC comparison can establish a dominance
relationship between classifiers. If the ROC curves are intersecting, the total AUC is an average
comparison between models [14]. However, for some specific cost and class distributions, the
classifier having maximum AUC may in fact be suboptimal. Hence, we also compute the ROC convex hulls,
since the points lying on the ROC convex hull are potentially optimal
[25,1].