We assume the reader is familiar with basic complexity classes, such
as P, NP and (uniform) classes of the polynomial hierarchy
[49,17]. Here we just briefly introduce
non-uniform classes [26]. In the
sequel, C, ![]() , etc. denote arbitrary classes of the polynomial
hierarchy.
, etc. denote arbitrary classes of the polynomial
hierarchy.
We assume that the input instances of problems are strings built over
an alphabet ![]() . We denote with
. We denote with ![]() the empty string and
assume that the alphabet
the empty string and
assume that the alphabet ![]() contains a special symbol
contains a special symbol ![]() to
denote blanks. The length of a string
to
denote blanks. The length of a string
![]() is
denoted by
is
denoted by ![]() .
.
An advice ![]() is a function that takes an integer and returns a
string.
is a function that takes an integer and returns a
string.
Advices are important in complexity theory because definitions and results are often based on special Turing machines that can determine the result of an oracle ``for free'', that is, in constant time.
An advice-taking Turing machine is a Turing machine enhanced
with the possibility to determine ![]() in constant time, where
in constant time, where
![]() is the input string.
is the input string.
Of course, the fact that ![]() can be determined in constant time
(while
can be determined in constant time
(while ![]() can be an intractable or even undecidable function) makes
all definitions based on advice-taking Turing machine different from
the same ones based on regular Turing machine. For example, an
advice-taking Turing machine can calculate in polynomial time many
functions that a regular Turing machine cannot (including some
untractable ones).
can be an intractable or even undecidable function) makes
all definitions based on advice-taking Turing machine different from
the same ones based on regular Turing machine. For example, an
advice-taking Turing machine can calculate in polynomial time many
functions that a regular Turing machine cannot (including some
untractable ones).
Note that the advice is only a function of the size of the input, not of the input itself. Hence, advice-taking Turing machines are closely related to non-uniform families of circuits [3]. Clearly, if the advice were allowed to access the whole instance, it would be able to determine the solution of any problem in constant time.
An advice-taking Turing machine uses polynomial advice if
there exists a polynomial ![]() such that the advice oracle
such that the advice oracle ![]() satisfies
satisfies
![]() for any nonnegative integers
for any nonnegative integers ![]() .
.
The non-uniform complexity classes are based on advice-taking Turing machines. In this paper we consider a simplified definition, based on classes of the polynomial hierarchy.
If C is a class of the polynomial hierarchy, then C/ poly is the class of languages defined by Turing machines with the same time bounds as C, augmented by polynomial advice.
Any class C/poly is also known as non-uniform C, where
non-uniformity is due to the presence of the advice. Non-uniform and
uniform complexity classes are related: Karp and Lipton
[27] proved that if NP ![]() P/poly
then
P/poly
then
![]() PH, i.e., the polynomial hierarchy
collapses at the second level, while Yap [52]
generalized their results, in particular by showing that if NP
PH, i.e., the polynomial hierarchy
collapses at the second level, while Yap [52]
generalized their results, in particular by showing that if NP
![]() coNP/poly then
coNP/poly then
![]() PH, i.e., the
polynomial hierarchy collapses at the third level. An inprovement of
this results has been given by Köbler and Watanabe
[33]: they proved that
PH, i.e., the
polynomial hierarchy collapses at the third level. An inprovement of
this results has been given by Köbler and Watanabe
[33]: they proved that
![]() implies that the polynomial hierarchy collapses to
ZPP(
implies that the polynomial hierarchy collapses to
ZPP(
![]() ). The collapse of the polynomial hierarchy is
considered very unlikely by most researchers in structural complexity.
). The collapse of the polynomial hierarchy is
considered very unlikely by most researchers in structural complexity.
We now summarize some definitions and results proposed to formalize the compilability of problems [6], adapting them to the context and terminology of PKR formalisms. We remark that it is not the aim of this paper to give a formalization of compilability of problems, or to analyze problems from this point of view. Rather, we show how to use the compilability classes as a technical tool for proving results on the relative efficiency of formalisms in representing knowledge in little space.
Several papers in the literature focus on the problem of reducing the complexity of problems via a preprocessing phase [30,28,32]. This motivates the introduction of a measure of complexity of problems assuming that such preprocessing is allowed. Following the intuition that a knowledge base is known well before questions are posed to it, we divide a reasoning problem into two parts: one part is fixed or accessible off-line (the knowledge base), and the second one is varying, or accessible on-line (the interpretation/formula). Compilability aims at capturing the on-line complexity of solving a problem composed of such inputs, i.e., complexity with respect to the second input when the first one can be preprocessed in an arbitrary way. In the next section we show the close connection between compilability and the space efficiency of PKR formalisms.
A function ![]() is called poly-size if there exists a polynomial
is called poly-size if there exists a polynomial
![]() such that for all strings
such that for all strings ![]() it holds
it holds
![]() . An
exception to this definition is when
. An
exception to this definition is when ![]() represents a number: in this
case, we impose
represents a number: in this
case, we impose
![]() . As a result, we can say that the
function
. As a result, we can say that the
function ![]() used in advice-taking turing machine is a polysize
function.
used in advice-taking turing machine is a polysize
function.
A function ![]() is called poly-time if there exists a polynomial
is called poly-time if there exists a polynomial
![]() such that for all
such that for all ![]() ,
, ![]() can be computed in time less than or
equal to
can be computed in time less than or
equal to ![]() . These definitions easily extend to binary functions
as usual.
. These definitions easily extend to binary functions
as usual.
We define a language of pairs ![]() as a subset of
as a subset of
![]() . This is necessary to represent the two inputs to a
PKR reasoning problem, i.e., the knowledge base (KB), and the formula
or interpretation. As an example, the problem of Inference in
Propositional Logic (PLI) is defined as follows.
. This is necessary to represent the two inputs to a
PKR reasoning problem, i.e., the knowledge base (KB), and the formula
or interpretation. As an example, the problem of Inference in
Propositional Logic (PLI) is defined as follows.

It is well known that PLI is coNP-complete, i.e., it is one of the
``hardest'' problems among those belonging to coNP. Our goal is to
prove that PLI is the ``hardest'' theorem-proving problem among
those in coNP that can be solved by preprocessing the first input
in an arbitrary way, i.e., the KB. To this end, we introduce a new
hierarchy of classes, the non-uniform compilability classes,
denoted as
![]() C, where C is a generic uniform complexity class, such
as P, NP, coNP, or
C, where C is a generic uniform complexity class, such
as P, NP, coNP, or ![]() .
.
A language of pairs
![]() belongs to
belongs to
![]() C iff there exists a binary poly-size function
C iff there exists a binary poly-size function ![]() and a language of pairs
and a language of pairs
![]() such that for all
such that for all
![]() it holds:
it holds:
Notice that the poly-size function ![]() takes as input both
takes as input both ![]() (the
KB) and the size of
(the
KB) and the size of ![]() (either the formula or the interpretation).
This is done for technical reason, that is, such assumption allows
obtaining results that are impossible to prove if the function
(either the formula or the interpretation).
This is done for technical reason, that is, such assumption allows
obtaining results that are impossible to prove if the function ![]() only takes
only takes ![]() as input [6]. Such assuption is useful
for proving negative results, that is, theorems of impossibility
of compilation: indeed, if it is impossible to reduce the
complexity of a problem using a function that takes both
as input [6]. Such assuption is useful
for proving negative results, that is, theorems of impossibility
of compilation: indeed, if it is impossible to reduce the
complexity of a problem using a function that takes both ![]() and
and ![]() as input, then such reduction is also impossible using a
function taking
as input, then such reduction is also impossible using a
function taking ![]() only as its argument.
only as its argument.
Clearly, any problem whose time complexity is in C is also in
![]() C:
just take
C:
just take ![]() and
and ![]() . What is interesting is that some
problem in C may belong to
. What is interesting is that some
problem in C may belong to
![]() with
with
![]() ,
e.g.,, some problems in NP are in
,
e.g.,, some problems in NP are in
![]() P. This is true for example
for some problems in belief revision [8]. In the rest
of this paper, however, we mainly focus on ``complete'' problems,
defined below.
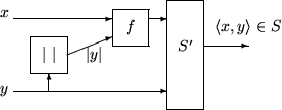
A pictorial representation of the class
P. This is true for example
for some problems in belief revision [8]. In the rest
of this paper, however, we mainly focus on ``complete'' problems,
defined below.
A pictorial representation of the class
![]() C is in
Figure 1, where we assume that
C is in
Figure 1, where we assume that ![]() .
.
For the problem PLI no method proving that it belongs to
![]() P is
known. In order to show that it (probably) does not belong to
P is
known. In order to show that it (probably) does not belong to
![]() P,
we define a notion of reduction and completeness.
P,
we define a notion of reduction and completeness.
Given two problems ![]() and
and ![]() ,
, ![]() is non-uniformly comp-reducible
to
is non-uniformly comp-reducible
to ![]() (denoted as
(denoted as
![]() ) iff there exist two poly-size binary
functions
) iff there exist two poly-size binary
functions ![]() and
and ![]() , and a polynomial-time binary function
, and a polynomial-time binary function ![]() such that
for every pair
such that
for every pair
![]() it holds that
it holds that
![]() if and only if
if and only if
![]() .
.
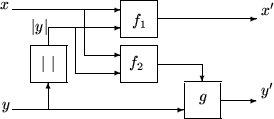
The
![]() reductions can be represented as depicted in
Figure 2.
reductions can be represented as depicted in
Figure 2.
Therefore, it is possible to define the notions of hardness and
completeness for
![]() C for every complexity class C.
C for every complexity class C.
We now have the right complexity class to completely characterize the
problem PLI. In fact PLI is
![]() coNP-complete
[6, Theorem 7]. Furthermore, the hierarchy formed by
the compilability classes is proper if and only if the polynomial
hierarchy is proper [6,27,52] -- a fact
widely conjectured to be true.
coNP-complete
[6, Theorem 7]. Furthermore, the hierarchy formed by
the compilability classes is proper if and only if the polynomial
hierarchy is proper [6,27,52] -- a fact
widely conjectured to be true.
Informally, we may say that
![]() NP-hard problems are ``not compilable
to P'', as from the above considerations we know that if there exists a
preprocessing of their fixed part that makes them on-line solvable in
polynomial time, then the polynomial hierarchy collapses. The same holds for
NP-hard problems are ``not compilable
to P'', as from the above considerations we know that if there exists a
preprocessing of their fixed part that makes them on-line solvable in
polynomial time, then the polynomial hierarchy collapses. The same holds for
![]() coNP-hard problems. In general, a problem which is
coNP-hard problems. In general, a problem which is
![]() C-complete for a
class C can be regarded as the ``toughest'' problem in C, even after
arbitrary preprocessing of the fixed part. On the other hand, a problem in
C-complete for a
class C can be regarded as the ``toughest'' problem in C, even after
arbitrary preprocessing of the fixed part. On the other hand, a problem in
![]() C is a problem that, after preprocessing of the fixed part, becomes a
problem in C (i.e., it is ``compilable to C'').
C is a problem that, after preprocessing of the fixed part, becomes a
problem in C (i.e., it is ``compilable to C'').
We close the section by giving another example of use of the
compilability classes through the well-known formalism of
Circumscription [41].
Let ![]() be any propositional formula. The minimal models of
be any propositional formula. The minimal models of
![]() are the truth assignments satisfying
are the truth assignments satisfying ![]() having as
few positive values as possible (w.r.t.
having as
few positive values as possible (w.r.t.
set containment). The
problem we consider is: check whether
a given model is a minimal model of a propositional formula.
This problem, called Minimal Model checking (MMC),
can be reformulated as the problem of model
checking in Circumscription, which is
known to be co-NP-complete [4].
If we consider the knowledge base ![]() as given off-line, and the truth
assignment
as given off-line, and the truth
assignment ![]() as given on-line, we obtain the following definition:
as given on-line, we obtain the following definition:
This problem can be shown to be
![]() coNP-complete
[6, Theorem 13]. Hence, it is very unlikely that it
can be in
coNP-complete
[6, Theorem 13]. Hence, it is very unlikely that it
can be in
![]() P; that is, it is very unlikely that there exists some
off-line processing of the knowledge base, yielding (say) some data
structure
P; that is, it is very unlikely that there exists some
off-line processing of the knowledge base, yielding (say) some data
structure ![]() , such that given
, such that given ![]() , it can now checked in polynomial
time whether
, it can now checked in polynomial
time whether ![]() is a minimal model of
is a minimal model of ![]() . This, of course, unless
. This, of course, unless
![]() has exponential size. This observation applies also when
has exponential size. This observation applies also when ![]() is
a knowledge base in Propositional Logic, and led to the interpretation
that Circumscription is more compact, or succint, than PL
[9,21]. Our framework allows to
generalize these results for all PKR formalisms, as shown in the
sequel.
is
a knowledge base in Propositional Logic, and led to the interpretation
that Circumscription is more compact, or succint, than PL
[9,21]. Our framework allows to
generalize these results for all PKR formalisms, as shown in the
sequel.