Scribe Notes
Function-Unit Architectures
By Steve Schlosser
 Slide 1: Function-Unit Architectures
Slide 1: Function-Unit Architectures
 Slide 2: Monday's Class
Slide 2: Monday's Class
Everyone should prepare a brief overview of their approach to their
kernel, explain how they'll implement it and prepare a few slides.
 Slide 3: Tool Status
Slide 3: Tool Status
New cvhasm and cvhsim which add some command line switches and run on
AIX and Solaris.
 Slide 4: A RC Taxonomy
Slide 4: A RC Taxonomy
Some metrics for describing CCMs relative to picture at left.
bandwidth -------------->
functionality <--------------
target size <--------------
latency <--------------
available resources <--------------
# of applications -------------->
granularity <--------------
arch complexity -------------->
compiler complexity <--------------
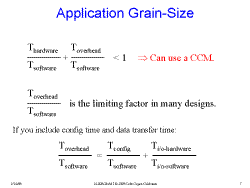 Slide 5: Application Grain-Size
Slide 5: Application Grain-Size
Overhead is the limiting factor in many designs.
 Slide 6: Functional-Unit Architectures
Slide 6: Functional-Unit Architectures
How do these affect the cycle time?
What effects do caches have?
How do you handle unsafe configurations? Compile time? Run time?
 Slide 7: PRISC
Slide 7: PRISC
The PRISC PFUs implement small logic functions and are simply an
additional functional unit in the datapath. They are accessed through
special instructions which load the results of the PFU computation
into standard CPU registers.
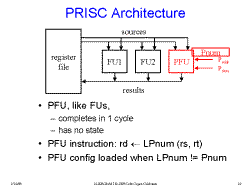 Slide 8: PRISC Architecture
Slide 8: PRISC Architecture
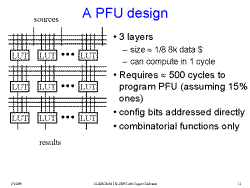 Slide 9: A PFU design
Slide 9: A PFU design
A modest fabric consisting only of LUTs and interconnect. There is no
state at all. Among other things, this avoids costly state saving
across context switching.
 Slide 10: Programming a PRISC
Slide 10: Programming a PRISC
One of the most intersting aspects of the PRISC is the automatic
compiler. Using profile information, it extracts small sections of
code to be converted into hardware and then called using PFU
instructions. Several different methods are used to choose code
sections and then optimize.
 Slide 11: Function Width Analysis
Slide 11: Function Width Analysis
An example of optimization used in PRISC is Function Width Analysis in
which the compiler examines a computation to determine how wide of a
bus it must generate. For example, in the following calculation, only
2 bits are required:
int x, y, z;
return (((x & 15) + (y | z)) & 2);
The compiler builds a tree which shows that the last operation (& 2)
reduces the entire result to two bits and therefore builds the entire
datapath accordingly.
 Slide 12: Optimizations -1
Slide 12: Optimizations -1
Finds operations that can be done in parallel. This reduces branches
but increases the number of required functional blocks. The other
problem is that there is no way to communicate exceptions back to the
main processor.
 Slide 13: Optimizations -2
Slide 13: Optimizations -2
This kind of optimization reduces the number of branches, but leads to
an exponential increase in the number of code blocks because the
compiler must generate two blocks for each if statement.
 Slide 14: PRISC Results
Slide 14: PRISC Results
 Slide 15: Extensions?
Slide 15: Extensions?
Some other extensions:
Prefetching of configurations
Add pipeline registers...?
More than 2 operands for each PFU, otherwise DAGs are limited.
 Slide 16: Chimera
Slide 16: Chimera
Do some of these extensions look familiar?
 Slide 17: Chimera Architecture
Slide 17: Chimera Architecture
Shadow Register file - 9 regs
Result Bus
config cache, memory bus
RISC core
Decode selects row to write back - CAM
 Slide 18: Register Usage
Slide 18: Register Usage
The fact that the fabric uses system registers for state rather than
having its own registers makes context switching much
simpler/transparent to the operating system.
 Slide 19: Processor/Fabric Communication
Slide 19: Processor/Fabric Communication
The fact that the compiler has to ensure the latency is problematic.
What if the architecture changes slightly?
Still doesn't address exception handling.
 Slide 20: Chimera Results
Slide 20: Chimera Results
 Slide 21: Garp
Slide 21: Garp
Garp addresses many of the same problems as the other architectures
and has a similar approach. However, Garp is the only one in which
the array can directly address memory, which is significant.
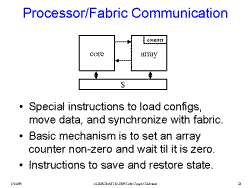 Slide 22: Processor/Fabric Communication
Slide 22: Processor/Fabric Communication
Much more co-processor-like than the other two architectures.
 Slide 23: Micro-Architecture
Slide 23: Micro-Architecture
The Garp takes an interesting approach to routing and delay
estimation. Interconnect delays are defined to be either short or
long. Logic functions are broken into three categories: simple, any
function without the carry chain, and any function with the carry
chain. The result is the ability to simplify timing specifications
and make better estimates.
However, the Garp has a problem in that it is physically larger than a
standard FPU. It is harder to justify the larger expense than that of
the smaller PRISC system. The Hauser and Wawrzynek paper does not
explain very clearly how the Garp is actually attached to its host RISC
core.
 Slide 24: Some Results
Slide 24: Some Results
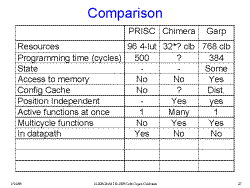 Slide 25: Comparison
Slide 25: Comparison
Some other metrics for comparing the three machines:
PRISC Chimaera Garp
Automatic Compilation? Yes No No
Forward Compatibility? Yes No Yes
Scribed by Steve Schlosser