Scribe Notes
Splash: Architecture & Application
By Taylor Wray
 Slide 1: Splash: Architecture & Application
Slide 1: Splash: Architecture & Application
 Slide 2: Admin
Slide 2: Admin
- The handin procedure is revised. You will no longer be locked out of your directory if you handin late, but the files will be flagged as late.
 Slide 3: Splash-2
Slide 3: Splash-2
A quick overview of the basics of the Splash-2.
- Attached processor to a Sparc-2 base.
- In Systolic mode, instructions are processed sequentially through the array boards.
- In SIMD mode one instruction is broadcast to every array board.
- dbC is a c-like language capable of SIMD instructions
- It is vital to know the architecture of the system to be able to take advantage of its strengths, or even to do anything at all.
 Slide 4: Splash-2 System
Slide 4: Splash-2 System
- The External I/O ports were probably inspired by the PAM, which allowed direct connections to external devices.
- The (pink) SBus is used either as an extension of the SBus line from the host to load programs, or as a return path for data from the Array boards.
- The RBus is used when in Systolic Mode.
- the SIMD Bus is used in SIMD Mode.
- The lines on the right are used to chain the boards together in Systolic Mode using the RBus.
 Slide 5: Splash-2 Components
Slide 5: Splash-2 Components
The TI crossbar chips were discontinued, which severely limited production of Splash-2.
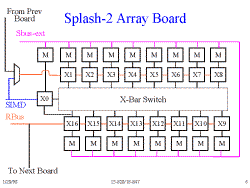 Slide 6: Splash-2 Array Board
Slide 6: Splash-2 Array Board
The crossbar switch takes 9 nibbles in, each of which can be routed to any destination. It can also change between 8 configurations on the fly. Its full reprogrammability power was never exploited, as the designers never used more than 4 modes, and often only 1.
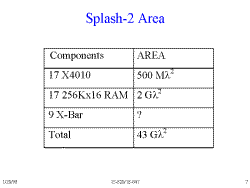 Slide 7: Splash-2 Area
Slide 7: Splash-2 Area
Looking at the number of Operations per lamba squared is one measure of how efficient a system is.
- The Xilinx chips take up approximately 25% of each Array Board.
- The RAM is mostly wasted space since it is not used for this application.
 Slide 8: Misc
Slide 8: Misc
- The data path has a maximum "data size" of 32 bits(but can be smaller). The extra bits are used as tag bits.
- It is important to notice that the SBus is used both for memory access and as a return path for data. So it is not possible to load memory and run the board at the same time.
- All boards must be turned off at the same time, meaning that there can be no dynamic reconfiguration.
- Each Xilinx chip is programmed bit-serially, but each chip on an Array Board is loaded in parallel. Still, with a low-bound of approximately 400 bits per CLB and 400 CLBs per chip, it will take around 160K bits to program each Array Board used, so programming time is on the order of 1000s of ms; far too long for our purposes.
 Slide 9: Splash-1
Slide 9: Splash-1
- Like the PNAC, Splash-1 was originally targeted to DNA string matching.
- The X3090s have fewer and smaller CLBs (only 5-inputs each) than Splash-2's 4010s.
- Only direct connections are possible, no nifty Crossbar or SIMD Mode.
- The host transfer card had only limited FIFO buffers, limiting transfer rate to ~1MHz.
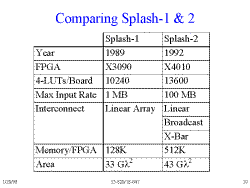 Slide 10: Comparing Splash-1 & 2
Slide 10: Comparing Splash-1 & 2
- Note that the SBus (hence, communication to the host) is no longer a bottleneck.
- The 4010 chips have much more space on them, so only 16 are required vs. 32 3090s on Splash-1.
 Slide 11: Programming Splash-2
Slide 11: Programming Splash-2
In SIMD mode, using dbC, there is somewhat less programming to be done because the Crossbar and X0 have fixed configurations.
Discussion
Herman asked the question: "How much of the needed code is interfacing rather than Core Kernel programming?" Answer: Most of it; the majority of the core of the program is X1-16, which leaves the Crossbar, Interface Card, X0, and host programming which is primarily interfacing.
So how can we clean up the architecture? Perhaps we could remove the SBus from the memory connections on each board, or at least hide it from the programmer. The main use for the memory connected to each Xilinx chip is either as scratch memory, a large LUT, and occasionally for memory output.
Another suggestion was to use DRAM on the host machine instead of SRAM on the Array Boards. Unfortunately, passing every value to be stored across the SBus to the host is slow, and requires many more resources than an on-board solution. Also, the integration of caching would be very difficult.
A more effective way of cleaning up at least one portion of the interfacing was to use larger Xilinx chips and do away with the Crossbar altogether. Which, incidentally, is what the Wildfire boards from Annapolis Micro Systems does. X0 on each chip is the only Crossbar, with a PCI bus to the host, and more FIFO buffers.
 Slide 12: Comparing Strings By Edit Distance
Slide 12: Comparing Strings By Edit Distance
 Slide 13: Issues in Algorithm Design
Slide 13: Issues in Algorithm Design
- For this alphabet, we only need 2 bits to represent each letter in the string.
- Notice that the cost for a Substitute is the same as that for an Insert/Delete combination. But we will use the Substitute when we can because we like having a single-operation substitution. Keep in mind that this is only an example, and there are cases where Insert/Delete and Substitute have different costs.
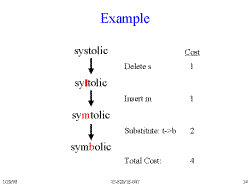 Slide 14: Example
Slide 14: Example
Algorithm
Find the distance between Strings of 2 different lengths.
Always assume you have a minimum distance.
 Slide 15: Edit Distance by Dynamic Programming
Slide 15: Edit Distance by Dynamic Programming
Given is a recursive algorithm for calculating Edit Distance.
- If both the strings are empty, there is no cost.
- If the source string is non-empty and the target string is empty, total cost is delete plus the cost of a source string that is one character shorter.
- Similarly, if the source string is empty and the target string is non-empty, total cost is insert plus the cost of a target string that is one character shorter.
- If the source string is longer by some amount and the target is nonempty, total cost is the cost of the previous operatoins plus a delete cost.
- If the source string is shorter by some margin and the target is nonempty, total cost is the cost of the previous operations plus a delete cost.
- If the Strings are of equal length, and have the same characters, there is no cost.
- If the strings are of equal length, and the characters are different, total cost is the previous costs plus a substitution.
- Take the minimum cost available.
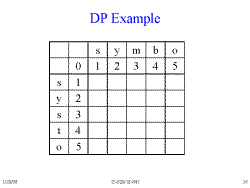 Slide 16: DP Example
Slide 16: DP Example
The way to visualize a Dynamic Programming comparison of two strings.
Notice that the cost to build each string "from scratch" is listed underneath or to the right of each string. Each string is built by doing an Insert operation at the end of the string for each letter, at a cost of 1/letter.
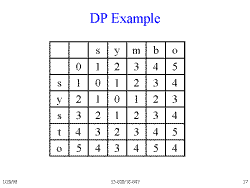 Slide 17: DP Example
Slide 17: DP Example
Here is the completed table for building one string based on the other (the distance between each string).
To move to the from a location to adjoining location is as follows:
- Right, Down: 1
- Diagonal: 0 or 2
Diagonals have a zero distance when the source and target letters are the same, because only a Match operation seperates them. Otherwise, there is a distance of 2 for a substitution.
The number in the lower right hand location gives the minimum distance from one string to another. Note that there are multiple paths from the lower right corner to the upper left, but only paths that are decreasing in value are valid.
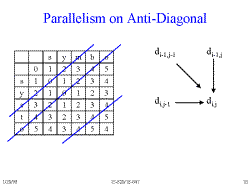 Slide 18: Parallelism on Anti-Diagonal
Slide 18: Parallelism on Anti-Diagonal
Because of the dependencies you can compute all the cells on an anti-diagonal at the same time.
 Slide 19: Bidirectional PE Example-1
Slide 19: Bidirectional PE Example-1
Each string begins with a cost to build the string from scratch, and the cost between the strings being compared. To begin, the Total cost is the same as the build cost, but will change as the strings pass each other.
As the strings begin their comparison, the Total cost for each string is updated by taking the minimum of their build costs and the match/substitute/insert/delete cost. In this case, only a match is required, so the distance is listed as 0.
 Slide 20: Bidirectional PE Example-2
Slide 20: Bidirectional PE Example-2
See how only one PE has done any work in the upper example. In the next cycle, that PE is idle. These bubbles in the system present a serious performance drain.
 Slide 21: Bidirectional PE Example-3
Slide 21: Bidirectional PE Example-3
 Slide 22: Bidirectional PE Example-4
Slide 22: Bidirectional PE Example-4
 Slide 23: Bidirectional PE Example-5
Slide 23: Bidirectional PE Example-5
 Slide 24: Bidirectional Summary
Slide 24: Bidirectional Summary
This implementation is small and fast when compared to PNAC (which was custom VLSI designed for this problem). PNAC was capable of 500 million cells/s whereas Splash 2 is capable of 2.1 billion cells/s.
Part of what helps keep Splash-2 small is that the entire difference is not accumulated within the PEs; instead, each cell keeps the difference between itself and its predecessor, and the total is accumulated at the end. Despite this, it is not as effecient as PNAC. What makes this algorithm so incredibly inefficient is the cycle of processing is as follows:
- Data Load/Pipe Fill.
- Compare.
- Drain.
As the number of processing elements increases, the fill/drain time becomes brutal. Another drawback is that only half of the PEs can be in use at any given time. For this reason, Bidirectional algorithms usually are not as good as Unidirectional algorithms.
 Slide 25: Unidirectional Approach
Slide 25: Unidirectional Approach
It is plain to see that the Unidirectional Approach is more effecient than the Bidirectional Approach. Not only does it use fewer PEs, but useful work is being done on the data as soon as it enters the pipe.
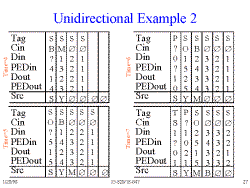
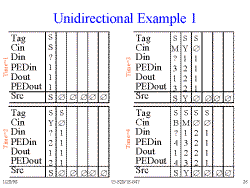 Slide 26: Unidirectional Example 1
Slide 26: Unidirectional Example 1
In this approach, each PE is associated with 1 row of the distance graph. (see Slide #17)
The Tag bits have three states
- PR : New String
- SR : Store
- TR : Target Compare
- In order to do multiple targets on one source string, we need a fourth state: New Target
The program for the Unidirectional approach is much more complicated, and requires more storage, but has two major advantages
- It requires only n PEs.
- Active processing is done while the pipe fills.
On the examples, only the first letter of each tag is listed. The values shown for Cin, Dout, and PEDout are those at the end of the clock cycle.
 Slide 27: Unidirectional Example 2
Slide 27: Unidirectional Example 2
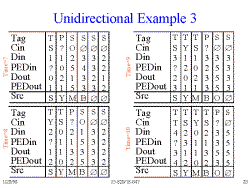 Slide 28: Unidirectional Example 3
Slide 28: Unidirectional Example 3
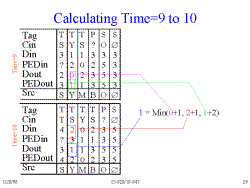 Slide 29: Calculating Time=9 to 10
Slide 29: Calculating Time=9 to 10
At time 10, the value of Dout is 1 because it is the minimum of
- d3,2 = d2,2+deletecost = 2+1
- d3,2 = d3,1+insertcost = 0+1
- d3,2 = d2,1+substitute cost = 1+2
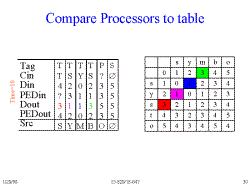 Slide 30: Compare Processors to table
Slide 30: Compare Processors to table
Note how the anti-diagonal in the table corresponds to positions in the PEs.
 Slide 31: Unidirectional Example 4
Slide 31: Unidirectional Example 4
 Slide 32: Do we need an additional tag?
Slide 32: Do we need an additional tag?
It appears from running the algorithm that a fourth tag is needed to
reset Dout so the next target string can begin from scratch.
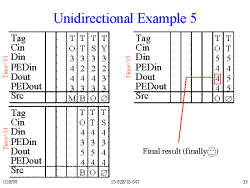 Slide 33: Unidirectional Example 5
Slide 33: Unidirectional Example 5
 Slide 34: Unidirectional Summary
Slide 34: Unidirectional Summary
Actually, the savings from compiling in the source sring would be quite large since all the machinary to load
source characters would be removed. In addition the comparators can be special cased.
 Slide 35: Reducing the Datapath
Slide 35: Reducing the Datapath
In order to reduce the size of comparators, etc. required, we take advantage that the table entries are never off by more than 1 or 2. So there can be an accumulation of the Deltas at the end, instead of percolating the total distance throughout the pipeline.
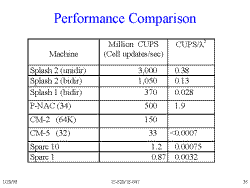 Slide 36: Performance Comparison
Slide 36: Performance Comparison
In terms of real estate, the Unidirectional approach on Splash-2 is more efficient than any but the PNAC (a custom VLSI solution). Splash-2 is so fast because the local communication is limited to a 2-bit datapath and it has a simple data controller.
The Unidirectional approach has much more state, but is still smaller.
The Bidirectional approach has many bubbles in the datapath, and can only operate on 1/2 the lenght of the largest string.
 Slide 37: The Perfect Application
Slide 37: The Perfect Application
How else could we make this algorithm more efficient?
For sufficiently large databases, treat the source string as a constant. Then we can fix some of the state and comparisons, saving a great deal both in area and speed.
Scribed by Taylor Wray