The world of pixel manipulation is a world of special cases. The need for rapid execution forces programmers to abandon the usual goals of modularity and reusability. The results are code bloat, inflexible systems, and missed deadlines. This thesis addresses the problem by looking at various graphics and media interfaces as programming languages, and using semantics-based techniques to transform flexible graphics operations into high-performance routines. More generally, we demonstrate a portable, easy-to-use interface to run-time code generation.
Programmers designing interfaces and implementing libraries with the C programming language expose alternate entry points or use fast-path optimization techniques[footnote: With the fast-path technique, two implementations for a single operation are provided, one that is always correct, and one correct only on some condition, but that runs faster. The condition is checked every time the routine is invoked.] to support media with different numbers of bits per pixel, different alignments in memory, or optional channels such as transparency and depth. Unless a particular combination is directly implemented in one routine, its operation will require either conditional branches inside a loop over the pixels, or buffers to hold partial results. But conditional branches reduce bandwidth, and buffers increase latency and memory traffic. We can bypass these problems by generating special cases and fused, one-pass loops as needed. With this technique, known as run-time code generation (RTCG), code may depend on (and therefore must temporally follow) some program execution and input.
We face three questions. Can we produce good enough code? Is the time spent generating this code worth its speed-up? And is the programmer-time spent learning and using RTCG worth its speed-up? My dissertation examines the first question by building three prototype systems and measuring a collection of examples. The second question is addressed elsewhere. The third question remains for the future.
My thesis is that run-time code generation a programmer to write pixel-level graphics in a flexible high-level language without losing the performance of hand-specialized C. Furthermore, the notions of specialization, binding times (temporal types), and compiler generation from research in partial evaluation (PE) provide portable and accessible means to automate the creation of the special cases. The thesis is tested by building systems and benchmarking common kernels.
I claim that a programmer can write image-processing programs in an interpretive style where a program may include an image's layout in memory as well as operations on it. Such a program can be conceived, type-checked, and debugged as a normal one-stage program, then specialization can be used to compile these programs into efficient kernels.
fun rgb_to_mono_1 rgb_start rgb_end m_start m_end =
if (rgb_start = rgb_end) then ()
else let val w = load_word rgb_start
in (store_word m_start (76*(w&0xff) +
154*((w>>8)&0xff) +
25*((w>>16)&0xff));
rgb_to_mono_1 (rgb_start+1) rgb_end
(m_start+1) m_end)
end
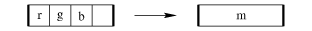 ps
psrgb_start, and 32-bit output m_start. The
diagram below the code illustrates the memory layout of the source and
destination buffers. Heavy lines indicate 32-bit word boundaries.
fun rgb_to_mono_2 r0 r1 b0 b1 g0 g1 m0 m1 =
if (r0 = r1) then ()
else let val rw = load_word r0
val gw = load_word g0
val bw = load_word b0
in
(store_word m0
(((9*(rw&0xff) + 20*(gw&0xff) + 3*(bw&0xff))>>5) |
((9*(rw>>8)&0xff + 20*(gw>>8)&0xff + 3*(bw>>8)&0xff)>>5)<<16);
store_word (m0+1)
(((9*(rw>>16)&0xff + 20*(gw>>16)&0xff + 3*(bw>>16)&0xff)>>5) |
((9*(rw>>24)&0xff + 20*(gw>>24)&0xff + 3*(bw>>24)&0xff)>>5)<<16);
rgb_to_mono_2 (r0+1) r1 (b0+1) b1 (g0+1) g1 (m0+2) m1)
end
 ps
ps
 ps
ps
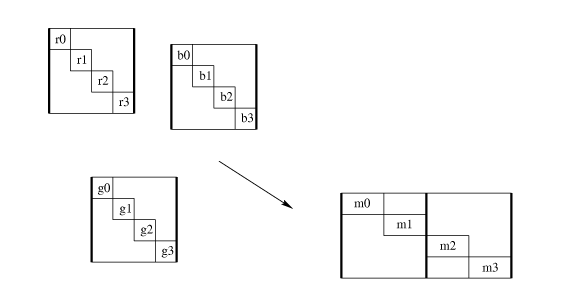
Here is a concrete example. Say we need to convert a 24-bit RGB color
image to grayscale. Two possible implementations appear in Figures
rgbm1 and rgbm2. These and other examples use ML
syntax extended with infix bit operations as found in the C
programming language (<< >> & |). The load_word primitive
accesses the contents of a memory location.
Rgb_to_mono_1 assumes (1) that the pixels are stored one per
32-bit word (interleaved and ignoring 8 bits), (2) a particular linear
weighting, and (3) 32-bit output. Rgb_to_mono_2 assumes (1) that
each channel is stored separately in memory (sequential) and
word-aligned, (2) a different combination function, and (3) 16-bit
word-aligned output. Other possibilites such as packing four pixels
into three words (Figure rgbm3d), 12-bit resolution, or
run-length coding would result in further variations. Codes like
these make good use of instruction-level parallelism and run fast, but
are of limited utility due to their assumptions.
A concrete result of this thesis is a system that can produce residual programs like Figures rgbm1 and rgbm2 from a general program that can handle any channel organization, bits per pixel, combination procedure, etc. Such a program appears in Figure rgbm.
fun rgb_to_mono f r g b m =
if (r s_end) then () else
((m s_put) (f (r s_get) (g s_get) (b s_get));
rgb_to_mono f (r s_next) (g s_next)
(b s_next) (m s_next))
s_put etc).
In order to produce the fast special cases, I supply the assumptions
(the program) to a code-generator (the compiler). Figure assumptions shows how to do this. The quote syntax creates names for
the equality assumptions rather than to name type variables (as in
ML). Though slightly hypothetical, this language is essentially the
Simple system from Section simple. Note that it has no
ordinary (if any) type discipline. Section spec summarizes
how we build a procedure like co_rgb_to_mono from the text of rgb_to_mono.
val rgbm1 =
let fun S x = vector_signal ('start+x) ('stop+x) 32 8
fun C x y z = 76*x + 154*y + 25*z
in co_rgb_to_mono C (S 0) (S 8) (S 16)
(vector_signal 'start1 'stop1 32 32)
end
val rgbm2 =
let fun S x y = vector_signal x y 8 8
fun C x y z = (9*x+20*y+3*z)/32
in co_rgb_to_mono C
(S 'x0 'y0) (S 'x1 'y1) (S 'x2 'y2)
(vector_signal 'start1 'stop1 16 16)
end
rgbm1 start stop start1 stop1;
rgbm2 x0 y0 x1 y1 x2 y2 start1 stop1;
The rest of this chapter is organized as follows: the next section takes an abstract look at the software engineering problems of media processing and motivates my approach. Section spec introduces the structures and techniques of specialization and partial evaluation. Section history connects this story to the published literature on the subject, and Section contributions identifies this work's novel contributions. The final section returns to the big picture and sketches some applications, and concludes by peering into the future.
Programmers sometimes struggle with the contradictory goals of latency, bandwidth, and program size. This section explores three solution-paths to a series of increasingly general software design problems. Consider an audio-processing program that loops over many sound samples. Figure inttab gives pseudo-code for the natural implementation strategy. I start with a loop over a per-sample operation, then parameterize it by adding conditionals inside the loop.
Eventually, the per-sample operation is parameterized with an inductively defined type. Such a parameter is sometimes called a little language, especially if the grammar is not regular and the language is Turing complete. Figure it contains an example. The per-sample operation has become a call to an interpreter for expressions in this language. Of course, the problem with this interpretive alternative is that these conditionals are tested repeatedly while their values remain constant. Although this kind of program runs very slowly, it is easy to write.
 ps
psForeach loops over a statement; eval recursively switches over several statements. The leftmost box
represents the unparameterized loop. Subsequent boxes represent
parameterizations by booleans. The final box, connected with a dotted
line, represents parameterization by an inductively defined type.
datatype Exp = e_val of int
| e_var of string
| e_plus of Exp * Exp
| e_times of Exp * Exp
Another implementation appears in Figure buftab. This technique is known as buffering or batching. The conditionals are independently hoisted out of the loops to eliminate the redundant tests. This requires multiple passes and temporary storage between passes. In the limit, this results in an interpreter with vector primitives. There are three problems with this alternative: accessing the buffers consumes memory bandwidth; the latency is increased because the first result is not ready until an entire buffer has been processed; and handling dynamic, sample-dependent control-flow becomes problematic.
 ps
psWe can think of these two alternatives as giving the inner control-flow to either the expression reduction or the samples. The third alternative appears in Figure spectab; here we hoist the conditionals together, resulting in one loop for each combination. Although this gives us optimal bandwidth and latency, because the number of combinations grows exponentially with the amount of parameterization, simple application of this alternative does not scale. In particular, when the type is inductive, the program would have infinite size.
 ps
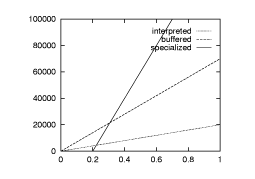
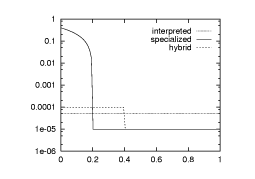
psThe idea of run-time code generation is to avoid the exponential blow-up by generating the special cases lazily. By sacrificing a spike in latency we optimize asymptotic bandwidth and latency. The situation is depicted in the graphs of Figure through.
When a problem is best solved with multiple passes, then the above arguments applie to the implementation of each pass. This happens in situations such as the compostion of wide convolutions.
 ps
ps 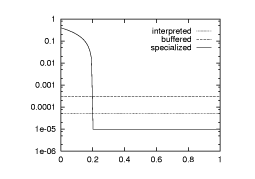 ps
psEven if in theory my RTCG system can produce good enough code and can generate it fast enough, in reality it may be too difficult to use. After all, writing programs that write programs is a notoriously bug-prone process. The next section suggests an interface to RTCG designed to alleviate this problem.
Specialization is a program transformation that takes a procedure and some of its arguments, and returns a procedure that is the special case obtained by fixing those arguments.
Formally, a specializer ![]()
![]() and
and ![]() denote program texts,
denote program texts, ![]() and
and ![]() denote ordinary values, and semantic brackets
denote ordinary values, and semantic brackets ![]()
There are many ways to implement ![]()
![]() maps functions to functions, but
maps functions to functions, but ![]()
![]()
![]() as is possible knowing only its first
argument and return a residual program that finishes the
computation. This gives us a way of factoring or staging computations
[JoSche86] and is most useful if we use this residual program
many times. In practice, specializers do less work than is possible
in order to avoid code-space explosion. The annotations and
heuristics used to decide when to stop working are the subject of
Section practical.
as is possible knowing only its first
argument and return a residual program that finishes the
computation. This gives us a way of factoring or staging computations
[JoSche86] and is most useful if we use this residual program
many times. In practice, specializers do less work than is possible
in order to avoid code-space explosion. The annotations and
heuristics used to decide when to stop working are the subject of
Section practical.
Partial evaluation (PE) as described in [JoGoSe93, Consel88, WCRS91] is a syntax-directed, semantics-based, source-to-source program transformation that performs specialization. Although we say automatic, in fact some human input in the form of hints or annotations has proven necessary.
One of the primary applications of PE is compiler generation,
frequently abbreviated cogen. If the function ![]() above
happens to be an interpreter, then
above
happens to be an interpreter, then ![]() is the compiled version of
is the compiled version of ![]() , a program in the
subject language. And so (at least theoretically)
, a program in the
subject language. And so (at least theoretically) ![]() is a compiler for the
language defined by the interpreter
is a compiler for the
language defined by the interpreter ![]() . Another level of
self-application yields
. Another level of
self-application yields ![]() , a compiler generator. These are known as the
Futamura projections [Futamura71].
, a compiler generator. These are known as the
Futamura projections [Futamura71].
Research on practical compiler generation is widespread [Mosses78, JoSeSo85, Lee89]. This thesis concerns systems implemented directly with a static analysis known as binding-time analysis (BTA). Binding-time analysis classifies each variable and operation in the interpreter source text as either static (program) or dynamic (data). Basically, values that depend on dynamic values are dynamic. Recent research [DaPfe96] indicates that binding times can be modeled with temporal logic, and thus incorporated into type systems.
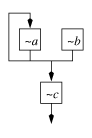
Let us now feel how compiler generation fits into the situation from the previous section. Initially the programmer type-checks and debugs a one-stage interpreter. Because specialization preserves the semantics of the code, producing an efficient two-stage procedure (a compiler that performs RTCG) is then just a matter of annotation and tweeking. Binding-time analysis performs the bookkeeping of program division and the specializer handles the mechanics of code construction. As an added bonus, since after annotation the source program can still run in one stage, it can be run in parallel with the compiler to soften the latency spike (Figure paris).
 ps
psCogen is not magic. It does not write any new code, it merely reorganizes the text of the procedures given to it and inserts calls to its own libraries. However, easing the creation of compilers from interpreters makes languages lightweight. Such a cogen promises to (and in fact may be specifically designed to) alleviate the implementation difficulties of interactive media.
This section surveys the literature on metaprogramming and run-time code generation and places this work in perspective. This section uses a lot of jargon; explanations appear in the relevant references.
Run-time code generation per se has long history including exile,
reconsideration [KeEgHe91], and a growing body of research
demonstrating substantial performance gains in operating systems [PuMaIo88, EngKaOT95, MuVoMa97]. I define ![]() of an RTCG system
as the average number of cycles spent by the compiler per instruction
generation. For reference, a typical value of
of an RTCG system
as the average number of cycles spent by the compiler per instruction
generation. For reference, a typical value of ![]() for a C or
ML compiler is 175,000[footnote:
for a C or
ML compiler is 175,000[footnote: ![]() of GCC -O on x86 is about
200,000 (45 * 133M / (77k/2.5)), IRIX CC -O is about 120,000 (25 *
150M / (120k/4)), and SML/NJ v109.28 on a DEC Alpha is 176,000 (1320 *
150M / (4.5M/4)). The formula is the product of measured user time
and clock speed divided by the number of instructions. The latter is
estimated with the size of the compiler's output divided by the
average number of bytes per instruction. Thanks to Perry Cheng for
helping collect the SML data.]
of GCC -O on x86 is about
200,000 (45 * 133M / (77k/2.5)), IRIX CC -O is about 120,000 (25 *
150M / (120k/4)), and SML/NJ v109.28 on a DEC Alpha is 176,000 (1320 *
150M / (4.5M/4)). The formula is the product of measured user time
and clock speed divided by the number of instructions. The latter is
estimated with the size of the compiler's output divided by the
average number of bytes per instruction. Thanks to Perry Cheng for
helping collect the SML data.]
In the C and C++ programming world the lack of portable interfaces and
the difficult nature of RTCG prevent more wide-spread use. However in
the Common LISP world [Steele90], use of RTCG (via eval, compile, and defmacro) is considered an essential advanced
technique [Graham94].
While macro-expansion happens at compile time rather than run time, it is the form of metaprogramming that people today are most familiar with. Experience with second-generation lexical macro systems such as ANSI C's [ANSI90] and the omission of macros from typed languages such as Java [GoJoSte96] and SML [MiToHa90] has given macro systems something of a bad reputation.
(defvar g 2)(defmacro f (x) `(+ g ,x))
(let ((g 17)) (f 419))
g in the body of let, the local definition of
g takes precedence.
Despite this, s-expression systems continue to succeed with macros.
Lisp's quasi-quote/unquote syntax was a good start, but syntactic
systems suffer from the variable capture pitfall [KFFD86] (see
Figure vcp). Scheme's syntax-rules [R4RS] fixed this
hygiene problem for a limited class of rewriting macros. Further
improvements are the subject of active research [Carl96, HiDyBru92]. Macros for typed languages are also certainly possible
[Haynes93]. One way to think about BTA is as a static analysis
that places the backquotes and commas automatically.
The `C language (pronounced ``tick-C'') [EnHsKa95] extends ANSI C
with an interface for RTCG inspired by Lisp's backquote mechanism,
though significantly more difficult to use due to limitations in the
orthogonality, generality, and type regularity of the extensions. The
recent implementation shows good performance in realistic situations
with either of two backends [PoEnKa97]. Tcc's icode backend performs basic optimizations such as instruction
scheduling, peephole, and register allocation, resulting in ![]() between 1000 and 2500. The vcode backend uses macros to
emit code in one pass;
between 1000 and 2500. The vcode backend uses macros to
emit code in one pass; ![]() is between 100 and 500.
is between 100 and 500.
Familiar compile-time systems for C include C++ templates [SteLe95] and parser generators such as yacc [Johnson75][footnote: In fact, LR(k) parser generation is a special case of polyvariant compiler generation [Mossin93, SpeThi95].]. However, as corroborated by the work in compiler generation for C [CHNNV96, Andersen94], we believe C's lack of static semantics makes these systems inherently more difficult to build, use, and understand.
Fabius [LeLe96] uses fast automatic specialization for run-time
code generation of a first-order subset of ML.
Essentially, it is a compiler generator where the syntax of currying
indicates staged computation, including memoization. Because the
binding times are implicit in every function call, no inter-procedural
analysis is required. Its extensions run very fast (![]() is
six).
is
six).
Tempo [CHNNV96] attempts to automate RTCG for use by operating systems. It applies binding-time analysis combined with various other analyses to ANSI C. It emits GCC code that includes template-based code-generating functions, using a great hack to remain, at least in theory, as portable as GCC.
This thesis makes the following contributions.
Nitrous is a directly-implemented memoizing compiler generator for a higher-order language. It accepts and produces (and its compilers produce) programs written in an intermediate language similar to three-address code. This design allows low-overhead run-time code generation as well as multi-stage compiler generation (where one generates a compiler from an interpreter written in a language defined by another interpreter). This system is the subject of Chapter system and a previous paper [Draves96]. Its relevant features are:
#1(s,d) is static[footnote: In Lisp syntax that
would read (car (cons s d)).] where s is static and d
is dynamic. The value (s, d) is called a partially-static
structure. Nitrous supports a kind of partially static integer I
call cyclic integers. With these, the BTA determines that (d*32+5)%32 is static (five in this case).
A specializer with these features is powerful enough to implement (among other things) the subject of Chapter bit-addr and [Draves97]:
More generally, this was the first research to explicitly apply partial evaluation to run-time code generation [Draves95].
The rest of the dissertation consists of five chapters and an
appendix. Chapter pe defines a specializer ![]() and briefly
discusses its implementation, Chapter bit-addr extends it to
cover bit-addressing, and Chapter system describes the Nitrous
implementation. Chapter benchmarks presents benchmark data
from Nitrous and from a small and simple implementation appear.
Chapter conc concludes by critically assessing the systems and
considering how to improve them.
and briefly
discusses its implementation, Chapter bit-addr extends it to
cover bit-addressing, and Chapter system describes the Nitrous
implementation. Chapter benchmarks presents benchmark data
from Nitrous and from a small and simple implementation appear.
Chapter conc concludes by critically assessing the systems and
considering how to improve them.
This section looks at what specializers can do for interactive media. We begin with some already implemented and benchmarked examples, then move on to speculation.
We can use bit-addressing to implement an object-oriented
signal-processing interface. This is the language used in Figure
rgbm to write rgb_to_mono. It allows the programmer to
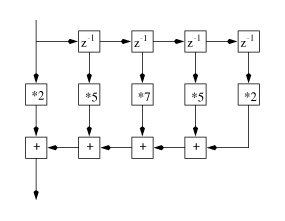
work at the dataflow level, by connecting signals as if they were tinker toys. Figure fir shows a linear filter built with a
graphical transliteration of this interface. Figure fircode
shows a higher-level way to build a filter. Section eg
discusses these systems.
 ps
ps
val kernel = [2, 5, 7, 5, 2] val prefix = ['a, 'b, 'c, 'd, 'e] val filter5 = (filter sig16 kernel prefix)
As another example, consider an interactive sound designer. A particular voice is defined by a small program; Figure fm is a typical example of a depiction of a wavetable synthesizer[footnote: Wavetable synthesis is just like FM (Frequency Modulation) synthesis, but sinusoids are replaced with lookup-tables.]. Most systems allow the user to pick from several predefined voices and adjust their scalar and wavetable parameters. With RTCG, the user may define voices with their own wiring diagrams.
 ps
ps  ps
psNext example: consider a typical window system with graphics state consisting of the screen position of a window, the current video mode and resolution, the typeface, etc. Common graphics operations such as EraseRect, BitBlit, DrawString, and BrushStroke may be specialized to this graphics state. I expect that RTCG will increase perceived usability of systems when the number of graphics states in use at any one time is small relative to the number of potentially useful states, and the time spent doing graphics operations is large.
Operations such as decoding an image and blitting it to the screen are ordinarily implemented in two-passes. With RTCG, when a file or network connection to a compressed video source is opened, a DecodeAndBlit routine may be generated that avoids an intermediary buffer, and thus reduces communication latency. The same idea applies to the parts of an operating system that implement network protocols.
My final example: artificial evolution of two-dimensional cellular
automata. The standard technique is to apply the genetic algorithm to
lookup-tables indexed by all possible neighborhoods [MiHraCru94].
But if the cells have just three bits of state and a 3-by-3
neighborhood then the lookup-table would require 192 Mbytes (![]() bits). With RTCG one can mutate
data-structures describing programs (i.e. substitute genetic
programming for the genetic algorithm), and then synthesize loops that
apply these area-operations in efficient (tiled or striped) order.
bits). With RTCG one can mutate
data-structures describing programs (i.e. substitute genetic
programming for the genetic algorithm), and then synthesize loops that
apply these area-operations in efficient (tiled or striped) order.
In summary I believe that metaprogramming in the form of run-time code generation can have significant impact on signal-processing and graphics applications. Specialization promises to give us a practical interface to RTCG. With this we can build systems with high bandwidth and low latency without giving up flexibility. I believe such systems will be very important in a future where our personal communications are mediated by computer networks.