
Stereo vision is computationally intensive. Fortunately, the spatially repetitive nature of depth recovery lends itself to parallelization. This is especially critical in the case of multibaseline stereo with high image resolution and the practical requirement of timely extraction of data. A number of researchers have worked on fast implementation of stereo (e.g., [11], [13], [14]).
In this report, we describe our implementation of a depth recovery scheme implemented in iWarp for a four-camera multibaseline stereo in a convergent configuration. Our system is capable of image capture at video rate. This is critical in applications that require tracking in three dimensions (an example is [10]). One method to obtain dense stereo depth data is to interpolate between reliable pixel matches [8]. However, the interpolated values may not be accurate. We obtain accurate dense depth data by projecting a light pattern of sinusoidally varying intensity onto the scene, thus increasing the local discriminability at each pixel. In addition, we make the most of the camera view areas by converging them at a volume of interest. Experiments have indicated that we are able to extract stereo depth data that are, on the average, less than 1 mm in error at distances between 1.5 to 3.5 m away from the cameras.
We introduce the notion of an active multibaseline stereo for extraction of dense stereo range data in Section 2. The principle of multibaseline stereo is explained, and in addition, we justify our use of the camera system in a convergent configuration. In this section, we briefly describe our image acquisition system that enables us to capture intensity images at video rate (30 Hz). Before the camera system can be used, it must be calibrated; this procedure is described in Section 3.
Prior to depth recovery, we apply a warping operation called image rectification to the set of images as a preprocessing step for computational reasons; this warping operation is described in Section 4. Our implementation of the depth recovery algorithm is subsequently detailed in this section.
Finally, we present results of our experiments in Section 5, analyze the sources of error in our system in Section 6, and summarize our work in Section 7.
In addition to the camera, we use a projector to cast a pattern of sinusoidal varying intensity (active lighting) onto the scene. This notion of an active multibaseline stereo allows a denser depth map as a result of improved local scene discrimination and hence correspondence.
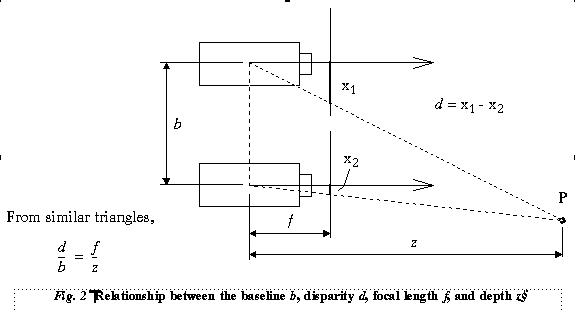
In multibaseline stereo, more than two cameras or camera locations are employed, yielding multiple images with different baselines [12]. In the parallel configuration, each camera is a lateral displacement of the other. From Fig. 2, d=fb/z (we assume for illustration that the cameras have identical focal lengths).
For a given depth, we then calculate the respective expected disparities relative to a reference camera (say, the leftmost camera) as well as the sum of match errors over all the cameras. (An example of a match error is the image difference of image patches centered at corresponding points.) By iterating the calculations over a given resolution and interval of depths, the depth associated with a given pixel in the reference camera is taken to be the one with the lowest error.
The multibaseline approach has the advantage of reducing mismatches during correspondences due to the simultaneous multiple baselines. In addition, it produces a statistically more accurate depth value [12]. However, using multiple cameras alone does not solve the problem of matching ambiguity that occurs with smooth untextured object surfaces in the scene. This is the reason why the idea of using active lighting in the form of a projected pattern on the scene is important. The projected pattern on object surfaces in the scene helps in disambiguiting local matches in the camera images.

The parallel camera configuration is suitable for outdoor applications where accuracy is not of utmost importance while speed is (e.g., [13]). A problem with this configuration is the low percentage of overlap in the field of views of the cameras.
Verging the cameras at a specific volume in space is optimal in an indoor application where maximum utility of the camera visual range is desired and the workspace size is constrained and known a priori. Such a configuration is illustrated in Fig. 3. One such application is the tracking of objects in the Assembly Plan from Observation project [9]. The aim of the project is to enable a robot system observe a human perform a task, understand the task, and replicate that task using a robotic manipulator. By continuously monitoring the human hand motion, motion breakpoints such as the point of grasping and ungrasping an object can be extracted [10]. The verged multibaseline camera system can extend the capability of the system to tracking the object being manipulated by the human. For this purpose, we require fast image acquisition (though processing is not as critical) and accurate depth recovery.

A printed planar dot pattern arranged in a 7x7 equally spaced grid is used in calibrating the cameras; images of this pattern are taken at known depth positions (five in our case). An example set of images taken by the camera system is shown in Fig. 5.




The dots of the calibration pattern are detected using a star-shaped template with the weight distribution decreasing towards the center. The entire pattern is extracted and tracked from one camera to the next by imposing structural constraints of each dot relative to its neighbors, namely by determining the nearest and second nearest distances to another dot. This filters out wrong dot candidates, as shown in Fig. 6.




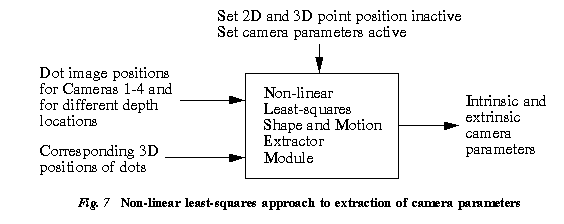
The simultaneous recovery of the camera parameters of all four cameras can be done using the non-linear least-squares technique described by Szeliski and Kang [16]. The inputs and outputs to this module are shown in the simplified diagram in Fig. 7. An alternative would be to use the pairwise-stereo calibration approach proposed by Faugeras and Toscani [7].

A simple rectification method is described in [1]. However, the rectification process described there is a direct function of the locations of the camera optical centers. It is not apparent how the desirable properties of minimal distortion and maximal inclusion can be achieved with their formalism. We have modified their formalism to simplify the rectification mapping and adapt it to our situation.
Let the original 3x4 perspective transforms of two cameras be P1 and P2, where
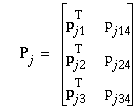
The original perspective transform Pj is constructed from known camera parameters of the form

where the tilde (~) above the vector indicates its homogeneous representation. q is the 3D point, uj the image coordinate vector, fj the focal length, aj the aspect ratio, and Rj and tj the extrinsic camera parameters. It is easy to see that the camera axis vector is rj3, and in the camera image coordinate system, the x- and y-directions are along rj1 and rj2, respectively.
Also, let M and N be the rectified perspective transforms, respectively, where

Since perspective matrices are defined up to a scale factor, we can set both m34 and n34 to be unity. Accordingly, based on the analysis in [1], m3 = n3, m2 = n2, m24 = n24, and from the constraint that c1 and c2 remain the optical centers,

Let d12 = c1 - c2. In a departure from [1], we choose the common rectified camera axis direction not only to be perpendicular to d12, but also to point in the direction between those of the unrectified camera axes (i.e., r13 and r23). This is done by first calculating
g = r13 + r23.
We then find the nearest vector perpendicular to d12:

Thus,

Determining m2 (and hence m24) is similar, with the additional constraint that

Finally, m1 is determined from the relation m1 = tau(m2 cross m3)
Tau (and hence m1 and m14) is calculated based on the constraint
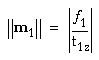
n1 and n14 are calculated in the same way, using the counterpart values of P2.
As in [1], the homographies (or linear projective correspondences) that map the unrectified image coordinates to the rectified image coordinates are
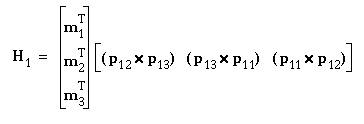
where v1 = H1u1.
u1 and v1 are the homogeneous unrectified and rectified image coordinates, respectively, and

with v2 = H2u2. u2 and v2 are similarly defined.
To recover depth from multibaseline stereo (specifically a 4-camera system) in a convergent configuration, we first rectify pairs of images as shown in Fig. 9.

There are two schemes which allows us to recover depth. The first uses all the homographies between the unrectified images and rectified images (namely H11, H12, H13, H21, H32, and H43 in Fig. 10).

then

since P1c1 = [0 0 0]T. So
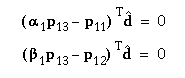
i.e.,
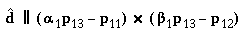
from which we get
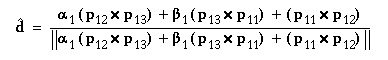
To find the disparity, Delta j = x'j - xj, as a function of the projection transform elements, we first find the expressions for the rectified image coordinates (noting that yj = y'j):
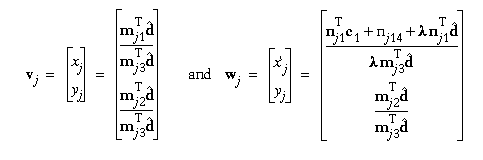
Hence
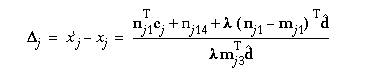
By varying lambda within a specified interval and resolution, we can calculate Delta j's for the pairs of rectified images, and hence calculate the sum of matching errors (as in [13] with multiple parallel cameras.) The depth is recovered by picking the value of lambda associated with the least matching error.
Properties 1 & 2 (which are the necessary conditions for rectification) give rise to
From 3, the homography between rectified planes must then be at most a 2D affine transform, i.e., the last row of the homography matrix must be (0 0 1). This dispenses with the additional division by the z-component in calculating the corresponding matched point for a particular depth.

The scheme now follows that in Fig. 11. The matching is done using the homographies between rectified images K1, K2 and K3 (which we term as rectified homographies). The rectified homographies can be readily determined as follows:
For a known depth plane (z = d), we can "contract" the 3x4 perspective matrix M (to the rectified plane) to a 3x3 homography G. For camera l, we have

where plj is the jth column of Ml and (ul, vl)T is the projected image point in camera l. Similarly, for camera m,
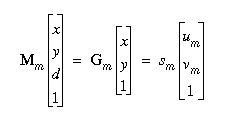
Since the rectified planes are coplanar, sl = sm; hence

Note that, due to rectification, vm = vl, and as explained earlier in this subsection, the bottom row of Klm is (0 0 1). In other words, the projective transformations are reduced to affine transformations, reducing the amount of computation.
Depth recovery then proceeds in a similar manner as the direct approach described in the previous subsection.
In order to avoid the warping operations, we use an approximate depth recovery method. The matching is done with respect to the rectified image of the first pair. However, the rectified images N2 and N3 will not be row preserved relative to M1 (Fig. 12). We warp rectified images N2 and N3 so as to preserve the rows as much as possible, resulting in N'2 and N'3 (Fig. 12). The errors should be tolerably small as long as the vergence angles are small. In addition, this effect should not pose a significant problem as we are using a local windowing technique in calculating the match error.

By comparing Fig. 12 with Fig. 11, we can see that the mapping from M1 to N2 is given by the homography L12 = K13H12H11-1. Similarly, the mapping from M1 to N3 is given by L13 = K14H13H11-1. The matrices A2 and A3 are constructed such that

i.e., the resulting overall mapping is row preserving (r and c are the row and column respectively). In general, this would not be possible, unless all the camera centers are colinear; however, this is a good approximation for small vergence angles and approximately aligned cameras. A2 and A3 are calculated from the following overconstrained relation using the pseudoinverse calculation:

where L1dmin is associated with the minimum depth and L1dmax with the maximum depth, cmin and cmax are the minimum and maximum values of the image column, and rmin and rmax are the minimum and maximum values of the image row, respectively. Xi (i=1,...,8) are don't-care values. The symbol | is used to represent matrix augmentation.
This algorithm has been implemented in parallel using the Fx (parallel Fortran) language developed at Carnegie Mellon [15]. Fx, a variant of High Performance Fortran with optimizations for high-communication applications like signal and image processing, runs on the Carnegie Mellon-Intel Corporation iWarp, the Paragon/XPS, the Cray T3D, and the IBM SP2. The experiments reported in this paper were done on the iWarp.
An example of a set of images (Scene 1) and the extracted depth image is shown in Fig. 13 and Fig. 14 respectively. The large peaks at the borders of the depth map are outliers due to mismatches in the background outside the depth range of interest.





Another example (Scene 2) is shown in Fig. 15 with the recovered elevation map in Fig. 16. As can be seen from the elevation map, except at the edges of the objects on the scene, the data looks very reasonable.





For Scene 3 (Fig. 17), subsequent to depth recovery (Fig. 18), we fit the known models onto the range data using Wheeler and Ikeuchi's 3D template matching algorithm [18] to yield results seen in Fig. 19. Again the data looks very reasonable.








We have also performed some error analysis on some of the range data that were extracted from Scene 2. Fig. 20 show the areas for planar fit; Table 1 shows the numerical results of the planar fit. As can be seen, the average planar fit error is smaller than 1 mm (the furthest planar patch is about 1.7m away from the camera system). Fig. 21 depicts the error distribution of the resulting planar fit across the image (only on pixels on planar surfaces in the scene). The darker pixels are associated with lower absolute error in planar fitting.






We have also obtained stereo range data of a cylinder of known cross-sectional radius and calculated the fit error. In both scenes (with different camera settings), the cylinder is placed about 3.3 m away from the camera system.

As can be seen from Table 2, the mean absolute error of fit is less than 1 mm.

There are a number of sources of error in our system and in stereo generally:
Of these, only the first seems to be a cause of significant error (the second also causes large error, but we deliberately omit it from our error analysis since it is fundamental to stereo). All of the large errors (more than 1 mm) are observed to be in regions where the projected pattern does not provide sufficient texture for a correct match.
We have attempted to reduce these errors by analysis and experimentation. Analysis shows that a frequency-modulated sine wave pattern, as used there, is a good choice since it does not require large dynamic range (our iWarp video interface has manually adjustable gain and offset controls, leading us to limit the dynamic range to avoid clipping). Also, a randomly frequency-modulated sine wave gives the best possible result, since the same pattern occurs twice in the search area with vanishingly small probability, theoretically eliminating the possibility of false matches. Experiments with randomly modulated patterns have shown that
In addition, many of the problems of false matches occur where the limited dynamic range of our video interface plays a role, particularly with dark surfaces or sufaces which lie at an oblique angle to the projector (so that no pattern appears in the image), or surfaces with specularities (so that clipping overwhelms the pattern). In these cases, we believe careful adjustment of the projector, including use of multiple projectors (since there is no particular constraint between the projector and camera in active stereo, this is easy to do), can serve to reduce these effects. The use of multiple patterns, either time-sequenced (taking advantage of our system's ability to capture images at high speed) or color-sequenced (using color cameras) is also promising.
We have also described in detail our implementation of the depth recovery algorithm which involves the preprocessing stage of image rectification. Our approximate depth recovery implementation was designed for reduced computation.
The results that we have obtained from this system indicated that the mean errors (discounting object border areas) are less than a millimeter at distances varying from 1.5 m to 3.5 m from the camera system. The performance of the system is thus comparable to a good structured light system, while allowing data to be captured at full video rate.
Active multibaseline stereo appears to be a promising addition to structured light imaging systems. It allows images to be captured at high speed and still have high spatial resolution. It allows great freedom in the relationship between the camera, the surface, and the light source, making it possible to manipulate these so as to get high accuracy in a wide variety of circumstances.
Many thanks to Bill Ross for his helpful information on setting up a multibaseline camera system. Tom Warfel built the real-time video interface board to the iWarp that made this project possible. We are also grateful to Luc Robert for interesting discussions on image rectification. Mark Wheeler helped in the analysis that led to the decision to verge the cameras.