This section introduces the abstraction of a distributed random-access machine (DRAM). We show how a parallel data structure can be embedded in a DRAM, and we define the load factor of a data structure. We show how the embedding of a data structure in a network can cause congestion in the underlying network when the pointers of the data structure are accessed in parallel, and we also demonstrate that a parallel algorithm can produce substantial congestion in an underlying network, even when there is little congestion implicit in the input data structure. We illustrate how a DRAM accurately models these two phenomena.
A DRAM consists of a set of n processors. All memory in the DRAM is
local to the processors, with each processor holding a small number of
![]() -bit registers. A processor can read, write, and perform
arithmetic and logical functions on values stored in its local memory.
It can also read and write memory in other processors. (A processor
can transfer information between two remote memory locations through
the use of local temporaries.) Each set of memory accesses is
performed in a memory access step, and any of the standard PRAM
assumptions about simultaneous reads or writes can be made. Our
algorithms use only mutually exclusive memory references, however, so
these special cases never arise.
-bit registers. A processor can read, write, and perform
arithmetic and logical functions on values stored in its local memory.
It can also read and write memory in other processors. (A processor
can transfer information between two remote memory locations through
the use of local temporaries.) Each set of memory accesses is
performed in a memory access step, and any of the standard PRAM
assumptions about simultaneous reads or writes can be made. Our
algorithms use only mutually exclusive memory references, however, so
these special cases never arise.
The essential difference between a DRAM and a PRAM is that the DRAM
models communication costs. We presume that remote memory accesses
are implemented by routing messages through an underlying network. We
model the communication limitations imposed by the network by
assigning a numerical capacity ![]() to each cut (subset of
processors) S of the DRAM equal to the number of wires connecting
processors in S with processors in the rest of the network. Thus,
there are many different DRAM's corresponding to the many possible
assignments of capacities to cuts. For a set M of memory accesses,
we define
to each cut (subset of
processors) S of the DRAM equal to the number of wires connecting
processors in S with processors in the rest of the network. Thus,
there are many different DRAM's corresponding to the many possible
assignments of capacities to cuts. For a set M of memory accesses,
we define ![]() to be the number of accesses in M from a
processor in S to a processor in
to be the number of accesses in M from a
processor in S to a processor in ![]() (the rest of the
DRAM), or vice versa. The load factor of M on S is
(the rest of the
DRAM), or vice versa. The load factor of M on S is
![]() , and the load factor of
M on the DRAM is
, and the load factor of
M on the DRAM is ![]() .
.
The basic assumption in the DRAM model is that the time required
to perform a set M of memory accesses is the load factor
![]() . (Local operations take unit time.)
This assumption constitutes the principal difference
between the DRAM and the network it models. We know that the load
factor is a lower bound on the time required in both the network and
the DRAM. If the network's message routing algorithm cannot approach
this lower bound as an upper bound (for example, if the network has
high diameter), then the network is not well modeled by the DRAM. If
the network's routing algorithm can nearly achieve the load factor as
an upper bound, then the analysis of an algorithm in the DRAM model
will reliably predict the actual performance of the algorithm on the
network. Section 8 discusses some networks for which
the DRAM is a reasonable model, including volume-universal networks
such as fat-trees [18].
. (Local operations take unit time.)
This assumption constitutes the principal difference
between the DRAM and the network it models. We know that the load
factor is a lower bound on the time required in both the network and
the DRAM. If the network's message routing algorithm cannot approach
this lower bound as an upper bound (for example, if the network has
high diameter), then the network is not well modeled by the DRAM. If
the network's routing algorithm can nearly achieve the load factor as
an upper bound, then the analysis of an algorithm in the DRAM model
will reliably predict the actual performance of the algorithm on the
network. Section 8 discusses some networks for which
the DRAM is a reasonable model, including volume-universal networks
such as fat-trees [18].
A natural way to embed a data structure in a DRAM is to put one record
of the data structure into each processor, as in the ``data parallel''
model [11]. The record can contain data, including
pointers to records in other processors. We measure the quality of an
embedding by treating the data structure as a set of pointers and
generalizing the concept of load factor to sets of pointers. The load
of a set P of pointers across a cut S, denoted ![]() , is
the number of pointers in P from a processor in S to a processor
in
, is
the number of pointers in P from a processor in S to a processor
in ![]() , or vice versa. The load factor of P on the
entire DRAM is
, or vice versa. The load factor of P on the
entire DRAM is
![]()
The load factor of a data structure is the load factor of the set of its pointers. For many problems, good embeddings of data structures can be found in particular networks for which the DRAM is a good abstraction (see Section 8).
There are generally two situations in which message congestion can arise during the execution of an algorithm on a network, both of which are modeled accurately by a DRAM whose cut capacities correspond to the cut capacities of the network. In the first situation, the embedding of a data structure causes congestion because many of its pointers cross a relatively small cut of the network. A parallel access of the information across those pointers generates substantial message traffic across the cut. In the second situation, the data structure is embedded with few pointers crossing the cut, but the algorithm itself generates substantial message traffic across the cut. We now illustrate these two situations.
As an example of the first situation, consider an embedding of a simple linear list in which alternate list elements are placed on opposite sides of a narrow cut of a network. If each element fetches a value from the next element in the list, the load factor across the cut is large. In the DRAM model, this congestion is modeled by the increase in time required for the memory accesses across the cut. (Observe that in a PRAM model, the congestion is not modeled since any set of memory accesses is assumed to take unit time.) Of course, a list can typically be embedded in a network so that the number of list pointers crossing any cut is small compared to the capacity of the cut, again a situation that can be modeled by a DRAM.
In the second situation, the congestion is produced by an algorithm.
As an example, consider the ``recursive doubling'' or ``pointer
jumping'' technique [30] used extensively by PRAM algorithms
in the literature. The idea is that each element i of a list
initially has a pointer ![]() to the next element in the list. At
each step, element i computes
to the next element in the list. At
each step, element i computes ![]() , doubling
the distance between i and the element it points to, until it points
to the end of the list. This technique can be used, among other
things, to compute the distance
, doubling
the distance between i and the element it points to, until it points
to the end of the list. This technique can be used, among other
things, to compute the distance ![]() of each element i to the end
of the list. Initially, each element i sets
of each element i to the end
of the list. Initially, each element i sets ![]() . At each
pointer-jumping step, each element i not pointing to the end of the
list computes
. At each
pointer-jumping step, each element i not pointing to the end of the
list computes ![]() . In a PRAM model, the
running time on a list of length n is
. In a PRAM model, the
running time on a list of length n is ![]() . Variants of this
technique are used for path compression, vertex numbering, and
parallel prefix computations
[22, 25, 27, 30].
. Variants of this
technique are used for path compression, vertex numbering, and
parallel prefix computations
[22, 25, 27, 30].
We now show that recursive doubling can be expensive even when a data
structure has a good embedding in a network. Figure 1
shows a cut of capacity 3 separating the two halves of a linked list
of 16 elements. In the first step of recursive doubling, the load on
the cut is only 1 because the only access across the cut occurs when
element 8 accesses the data in element 9. In the second step, the
load is 2 because element 7 accesses element 9 and element 8
accesses element 10. In the third step, the load is 4, and in the
fourth step, each of the first eight elements makes an access across
the cut, creating a load of 8. Since the load factor of the cut in
the fourth step is ![]() , this set of accesses requires at least 3
time units. Whereas the capacity of the cut is large enough to
support the memory accesses across it in the first step, by the fourth
step, the cut capacity is insufficient. In a DRAM, this
situation is modeled by the increased time to perform the memory
accesses in the fourth step compared with those in the first step.
, this set of accesses requires at least 3
time units. Whereas the capacity of the cut is large enough to
support the memory accesses across it in the first step, by the fourth
step, the cut capacity is insufficient. In a DRAM, this
situation is modeled by the increased time to perform the memory
accesses in the fourth step compared with those in the first step.
The focus of this paper is avoiding this second cause of congestion. In Section 4, we shall show how a recursive pairing strategy can perform many of the same functions as recursive doubling, but in a communication-efficient fashion.
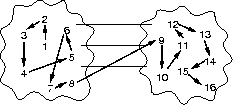
Figure 1: A cut of capacity 3 separating two halves of a linked list.
The load of the list on the cut is 1. At the final step
of recursive doubling, each element on the left side of the cut
accesses an element on the right, which induces a load of 8 on
the cut.