Efficient Spatially Sparse Inference for Conditional GANs and Diffusion Models
Muyang Li1, Ji Lin2, Chenlin Meng3, Stefano Ermon3, Song Han2, and Jun-Yan Zhu1
1CMU, 2MIT, 3Stanford
In NeurIPS 2022
Paper | Code | Slides | YouTube | Bilibili
Try our method with pip install sige or
![]() .
.
Abstract
During image editing, existing deep generative models tend to re-synthesize the entire output from scratch, including the unedited regions. This leads to a significant waste of computation, especially for minor editing operations. In this work, we present Spatially Sparse Inference (SSI), a general-purpose technique that selectively performs computation for edited regions and accelerates various generative models, including both conditional GANs and diffusion models. Our key observation is that users tend to make gradual changes to the input image. This motivates us to cache and reuse the feature maps of the original image. Given an edited image, we sparsely apply the convolutional filters to the edited regions while reusing the cached features for the unedited regions. Based on our algorithm, we further propose Sparse Incremental Generative Engine (SIGE) to convert the computation reduction to latency reduction on off-the-shelf hardware. With about 1%-area edits, our method reduces the computation of DDPM by 7.5×, Stable Diffusion by 8.2×, and GauGAN by 18× while preserving the visual fidelity. With SIGE, we accelerate the inference time of DDPM by 3.0× on NVIDIA RTX 3090, 4.6× on Apple M1 Pro GPU, and 6.6× on M1 Pro CPU, Stable Diffusion by 7.2× on 3090, and GauGAN by 5.6× on 3090, 5.2× on M1 Pro GPU, and 14× on M1 Pro CPU.

Paper
arxiv 2211.02048, 2022.
Citation
Muyang Li, Ji Lin, Chenlin Meng, Stefano Ermon, Song Han and Jun-Yan Zhu.
"Efficient Spatially Sparse Inference for Conditional GANs and Diffusion Models",
in NeurIPS 2022.
Bibtex
Code: PyTorch
Introduction Video
Method
Tiling-based sparse convolution overview. For each convolution Fl in the network, we wrap it into SIGE Convl. The activations of the original image are already pre-computed. When getting the edited image, we first compute a difference mask between the original and edited image and reduce the mask to the active block indices to locate the edited regions. In each SIGE Convl, we directly gather the active blocks from the edited activation Aledited according to the reduced indices, stack the blocks along the batch dimension, and feed them into Fl. The gathered blocks have an overlap of width 2 if Fl is 3×3 convolution. After getting the output blocks from Fl, we scatter them back into Fl(Aloriginal) to get the edited output, which approximates Fl(Aledited).
Performance

With 1.2% edits, SIGE could reduce the computation of DDPM, Progressive Distillation and GauGAN by 7~18×, achieve a 2~4× speedup on NVIDIA RTX 3090, 3~5× speedup on Apple M1 Pro GPU and 4~14× on M1 Pro CPU. When combined with GAN Compression, it further reduces 50× computation on GauGAN, achieving 38× speedup on M1 Pro CPU. Please check our paper for more details and results.
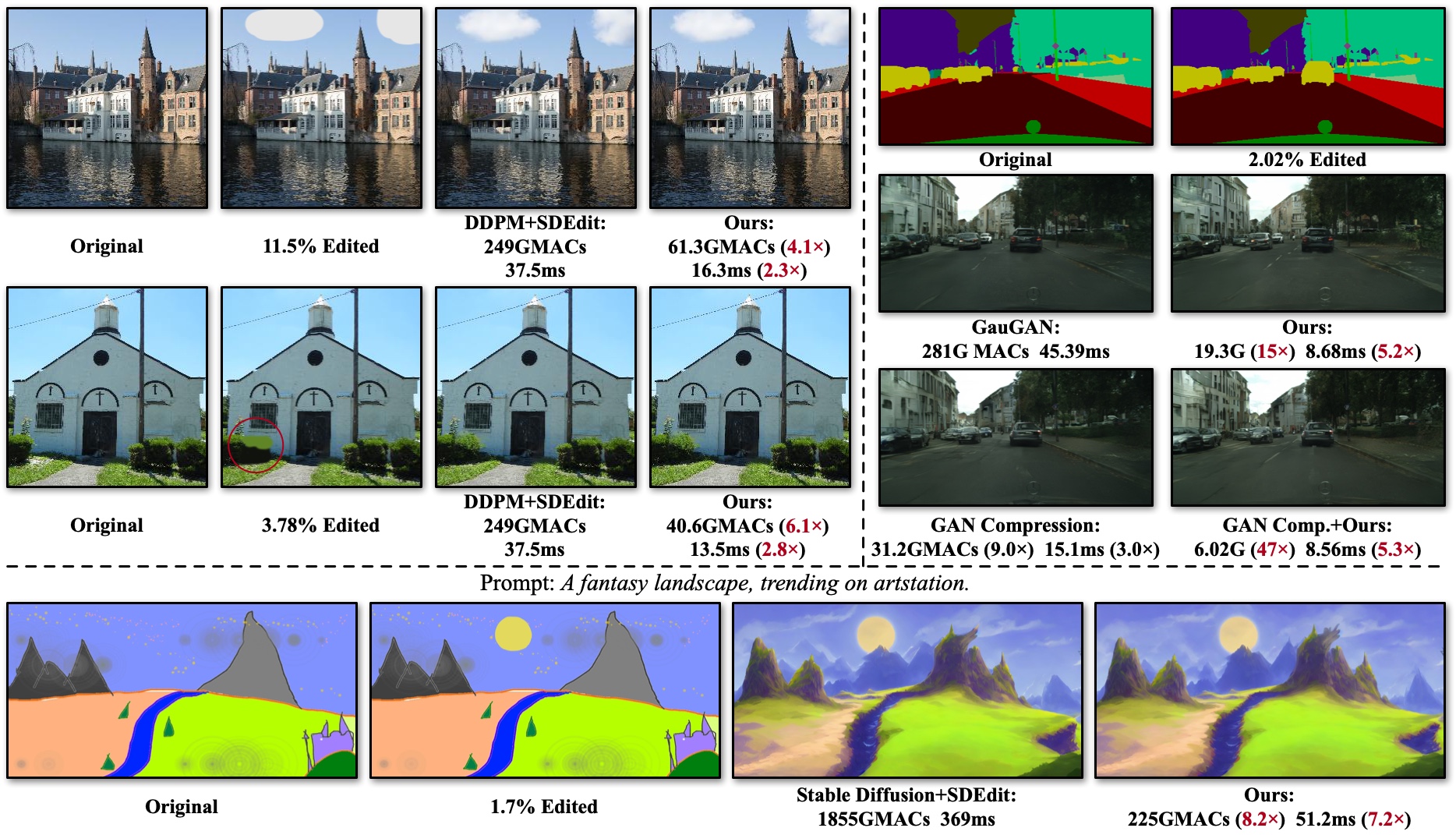
Visual Results

Qualitative results under different edit sizes. PD is Progressive Distillation. Our method well preserves the visual fidelity of the original model without losing global context.

More qualitative results of Stable Diffusion on both image inpainting and editing, measured on NVIDIA RTX 3090.
Related Work
Acknowledgment
We thank Yaoyao Ding, Zihao Ye, Lianmin Zheng, Haotian Tang, and Ligeng Zhu for the helpful comments on the engine design. We also thank George Cazenavette, Kangle Deng, Ruihan Gao, Daohan Lu, Sheng-Yu Wang and Bingliang Zhang for their valuable feedback. The project is partly supported by NSF, MIT-IBM Watson AI Lab, Kwai Inc, and Sony Corporation.
