This is an interactive tutorial for the NESL parallel programming language. The
emphasis of the tutorial is on features that support parallelism.
The tutorial is organized as an introduction to NESL followed by the following two
examples
The parallel apply-to-each: a construct
for applying any expression to each element of a sequence in parallel.
A set of parallel operations on sequences, such as summing the
elements of a sequence.
A key feature of NESL is the support of nested
parallelism, which allows for the above constructs to be nested.
NESL also supplies a well defined "cost model". In this model, algorithms
can be analyzed in terms of the total work (number of operations) and depth
(longest path of sequential dependencies) they require.
NESL is loosely based on ML, a functional
language, but the reader need not know anything about functional
languages to get through the tutorial.
NESL supports parallelism through operations on sequences. The
sequences are similar to one-dimensional arrays in sequential
languages but on a parallel machine are somehow spread across the
processors. In NESL sequences are specified using square brackets
[2, 1, 9, -3]
and indices are zero based, i.e.a[0] extracts the
first element of the sequence a.
Characters sequences can be written shorthand between double quotes
"this is a sequence of characters"
Elements of a sequence can be of any type including other sequences
The most important parallel feature in NESL is the apply-to-each
construct. This construct uses a set-like notation.
For example, the expression
squares each elements of the sequence [3, -4, -9, 5].
This can be read:
"in parallel, for each a in the sequence
[3, -4, -9, 5],
square a". The idea is that in an implementation on a parallel
machine the elements of the sequence will be spread across the processors
and each processors will work on its share of the data.
The apply-to-each construct can be used with any function, whether
primitive or user defined.
So, for example, we could define a factorial function and then apply
it in parallel:
This differs from many data-parallel languages which only allow a fixed
set of operations to be applied in parallel, such as elementwise adding
two arrays. As we will see shortly, allowing
arbitrary functions to be applied in parallel allows
for nested parallelism, which is a key feature of NESL.
Also the astute reader might note
that the running time of the factorial function depends on its
input and therefore we do not want to spread the parallel calls
to factorial evenly across the processors. The problem is that
one processor might be allocated a set of large numbers and need to do
much more work than the others.
In fact, since we do not necessarily know the cost of user defined code
as a function of their input, implementations of NESL must somehow
load balance work across processors dynamically.
The apply-to-each has two additional important features -- it can be
used over multiple sequences, and it can be used to subselect
elements. The semicolon (;) is used when applying a
function over arguments from multiple sequences. For example, the
expression
adds the two sequences elementwise. The sequences must be of
the same length (NESL will give an error if they are not). The pipe
symbol (|) is used to subselect elements of a sequence
based on a filter. For example, the expression
can be read: "in parallel, for each a in the sequence
[3, -4, -9, 5] such that a is greater than
0, square a". The elements that remain
maintain their relative order. This can be implemented in a
straightforward manner to run in parallel.
In addition to the parallelism supplied by apply-to-each, NESL
provides a set of functions on sequences, each of which can be
implemented in parallel.
Here are examples of some of these functions:
One of the more important function on sequences is the
write function, which supplies a mechanism to modify
multiple values of a sequence in parallel. write takes
two arguments: the first is the sequence to modify and the second is a
sequence of integer-value pairs that specify what to modify. For each
pair (i,v) the value v is inserted into
position i of the destination sequence. For example
inserts the -2, 5 and 9 into the
sequence at locations 4, 2 and 5,
respectively. These modifications are implemented to run in parallel.
If an index is repeated, then one
value is written non-deterministically. For readers familiar with the
variants of the PRAM model, we note that the write function is
analogous to an ``arbitrary'' concurrent write.
Exercise 1
Write a function, that takes two sequences of equal length and takes
their dot product. In particular for two sequences A and B of length
n, it should return:
Sumi=0n-1 Ai * Bi.
The support of nested parallelism is one of the key ideas behind NESL.
Nested parallelism allows one to express a very broad set of
algorithms in a clean and concise way. The term refers to the
property that if we make a set of parallel calls, they in turn can
each make a set of parallel calls, in a nested fashion. We note that
this differs from futures since futures allow for parallelism
that is not nested.
Nested parallelism is supported in NESL by allowing
parallel functions to be used in an apply-to-each.
For example, we could apply the sum function in parallel over a
nested sequence,
In this expression there is
parallelism both within each sum and across the sums.
There are two main uses for such nesting of parallel calls:
implementing nested parallel loops, and
implementing parallel divide-and-conquer.
As an example of nested parallel loops consider the following code for
sorting a sequence of n unique keys.
In this code to generate the rank of each key we make a total of
n2
comparisons in parallel. This is implemented by nesting the parallel
calls so that one apply-to-each is inside another.
Write a function that returns all the primes up to n by checking
for each integer i from 2 through n if it is a multiple
of some integer in the range [2...1+sqrt(i)].
The function isqrt takes the square root of an integer.
Hint: you can use the expression [2:n] to
generate a sequences of integers from 2 to n. The function mod(i,j) takes the modulus of i and j (i.e. the remainder).
Sparse matrices, which are common in scientific applications, are matrices
in which most elements are zero. To save space and running time it is
critical to only store the nonzero elements. A
standard representation of sparse matrices in sequential languages is
to use an array with one element per row each of which contains a
linked-list of the nonzero values in that row along with their column
number. A similar representation can be used in parallel. In NESL
a sparse matrix can be represented as a sequence of rows, each of
which is a sequence of (column-number, value) pairs of the
nonzero values in the row. The matrix
where A is a nested sequence. This representation can be used
for matrices with arbitrary patterns of nonzero elements since each
subsequence can be of a different size.
A common operation on sparse matrices is to multiply them by a dense
vector. In such an operation, the result is the dot-product of each
sparse row of the matrix with the dense vector. The NESL code for
taking the dot-product of a sparse row with a dense vector x is:
sum({v * x[i] : (i,v) in row});
This code takes each index-value pair (i,v) in the sparse
row, multiplies v with the ith value of x,
and sums the results.
The full code for multiplying a sparse matrix A represented as above
by a dense vector x requires that we apply the above code to
each row in parallel, which gives
This example has nested parallelism since
there is parallelism both across the rows and within each row for the
dot products. The total depth of the code is the maximum of the depth
of the dot products, which is the logarithm of the size of the largest
row. The total work is proportional to the total number of nonzero
elements.
Write code that takes a sparse matrix (represented
as shown above) and extracts any column i.
For example, for the matrix example used above,
the function get_column(A,2) should extract column 2
and return
[0.0, -1.0, 2.0, -1.0].
Our next example solves the planar convex hull problem: Given n
points in a plane, find which of them lie on the perimeter of the
smallest convex region that contains all points. This example shows
another use of nested parallelism for divide-and-conquer algorithms.
The algorithm we use is a parallel Quickhull,
so named because of its similarity to the Quicksort algorithm. As
with Quicksort, the strategy is to pick a ``pivot'' element, split the
data based on the pivot, and recurse on each of the split sets. Also
as with Quicksort, the pivot element is not guaranteed to split the
data into equally sized sets, and in the worst case the algorithm
requires O(n2) work, however in practice the algorithm is often
very efficient.
Here is the code for the parallel quickhull algorithm
The algorithm is based on the recursive routine hsplit.
This function takes a set of points in the plane and two points p1 and p2 that are known
to lie on the convex hull and returns all the points that lie on the
hull clockwise from p1 to p2, inclusive of
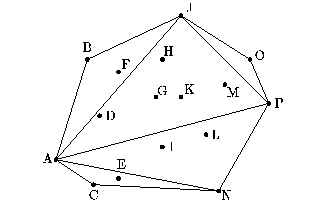
p1, but not of p2. In the example below, given all the points
[A, B, C, ..., P], p1 = A and p2 = P,
hsplit would return the sequence [A, B, J, O]. In
hsplit, the order of p1 and p2 matters,
since if we switch A and P, hsplit would
return the hull along the other direction [P, N, C].
The hsplit function first removes all the elements that
cannot be on the hull because they lie below the line between
p1 and p2 (which we denote by p1-p2). This
is done by removing elements whose cross product with the line between
p1 and p2 is negative. In the case p1 = A
and p2 = P, the points [B, D, F, G, H, J, K, M, O]
would remain and be placed in the sequence packed. The
algorithm now finds the point, pm, furthest from the line
p1-p2. The point pm must be on the hull since as a
line at infinity parallel to p1-p2 moves toward
p1-p2, it must first hit pm. The point pm
(J in the running example) is found by taking the point with
the maximum cross-product. Once pm is found, hsplit
calls itself twice recursively using the points (p1, pm) and
(pm, p2) ((A, J) and (J, P) in the
example). When the recursive calls return, hsplit flattens
the result, thereby appending the two subhulls.
The overall convex-hull algorithm works by finding the points
with minimum and maximum x coordinates (these points must be
on the hull) and then using hsplit to find the upper and
lower hull.
There have been many parallel languages suggested over the past two
decades. A reading list on many of these languages can be found here
(warning: this is a couple years out of date). As compared to most of
these languages, NESL puts much more emphasis on making code very
high-level and concise. This has the obvious benefit (i.e. quicksort
is 10 lines of code in NESL instead of 1700 for an MPI
implementation), but puts much more responsibility on the compiler and
runtime system. This can potentially entail serious loss of
performance. It is hard to make a general statement, however, about
how much performance one loses with a language such as NESL since it
depends highly on
The particular machine. For example, nesl tends to work well
with parallel machines with high communication bandwidth.
The type of application.
The compiler technology, which is changing very rapidly.
In fact, the most interesting research in a language such as NESL
is working on techniques to make the performance approach that of
hand-tuned low-level code.
Here we give a brief comparison of NESL to some other parallel languages.
PVM and MPI
These are not actually languages but library extensions that can be
used with existing sequential languages (currently C and Fortran).
Both supply a set of routines for a sequential task on one processor
to communicate with tasks on other processors. In these language
extensions it is up to the user to partition the data among the tasks,
and handle all communication. MPI (the
Message-Passing Interface) is a follow-up of PVM (the Parallel
Virtual Machine) and is an attempt to develop a standard. MPI
supplies a richer set of utilities for global operations (i.e. summing
a value from each processor) and for partitioning processors into
groups than PVM (although many of these features are appearing in
newer releases of PVM).
So why does it take over 1000 lines of code to express Quicksort
in MPI as compared to 10 in NESL? The problem lies in the management
and partitioning of data. Quicksort is a particular challenge in
message-passing libraries such as PVM or MPI because of the highly
dynamic nature -- the sizes of subproblems is not known until run
time. However, even with more static tasks such as the
O(n2) work sort given above end up requiring
much more code. Here we give an outline of what is required to
implement quicksort in MPI or PVM. We assume the data starts out
evenly distributed across the processors.
Have each processor subselect the lesser and greater
elements from within their portion of the data.
Use various global operations to gather the lesser elements from
different processors together into a subset of the processors (do the
same for the greater elements). Since we don't know ahead of time how
many lesser each processor will have, this communication pattern has
to be determined dynamically.
Put the equal elements off to the side somehow, they have to be
merged in on the way back up the recursion.
Partition the processors into two groups one which will work on
lesser elements and one on the greater elements.
Repeat this process until groups are of size 1. We can now do a local
quicksort on the remaining data. The problem, however, is that the work
among processors might not be properly balanced since we do not know how
much time each local sort will take.
To properly balance the load, requires that we further partition the task even
when a group is of size 1 so that a processor can pass off work if need be.
Coordinate the load among processors while finishing off the
local sorts.
Go back up the recursion in reverse merging the various data from
subgroups.
We have left out many details and we encourage you to look at the
code to appreciate what is involved.
Exercise 1