[This chapter is available as http://www.cs.cmu.edu/~ref/mlim/chapter8.html .]
[Please send any comments to Robert Frederking (ref+@cs.cmu.edu, Web document maintainer) or Ed Hovy or Nancy Ide.]
Chapter 8
Evaluation and Assessment Techniques
Editor: John White
Contributors:
Lynette Hirschman
Joseph Mariani
Alvin Martin
Patrick Paroubek
Martin Rajman
Beth Sundheim
John White
Abstract
Evaluation, one of the oldest topics in language processing, remains difficult. The fact that funding agencies become increasingly involved in language processing evaluation makes the subject even more controversial. Although it cannot be contested that the competitive evaluations held in Speech Recognition, Information Extraction, Machine Translation, Information Retrieval, and Text Summarization in the US over the past fifteen years has greatly stimulated research toward practical, workable systems, it has also focused research somewhat more narrowly than has been in the case in Europe. As techniques in the different areas grow more similar, and as the various areas start linking together, the need for coordinated and reusable evaluation techniques and measures grows. The multilingual portions of the MUC and TREC evaluation conferences, for example, involve issues that are also relevant to MTEval, and vice versa. There is a need for a more coordinated approach to the evaluation of language technology in all its guises.
8.1 Definition of Evaluation
Evaluation is surely one of the oldest traditions in computational language processing. The very early breakthroughs (and apparent breakthroughs) in language processing, especially machine translation, were announced to the world essentially as proof-of-concept evaluations. The proof-of-concept model in software engineering probably owes much to the importance of showing an embryonic language processing capability in such a way that its implications are readily apparent to lay persons. Later, the details of the evaluation were largely forgotten by the world’s computer users, but their significance was profound. More than any other computer application of the time, the early trials of language processing (machine translation especially) created a demand and an expectation about the capability of computers that persists to this day. It is a truism in the field that many fundamentals of software engineering arose from these early experiences with language processing, including software evaluation principles. Robust, everyday language processing itself, though, still largely lies in the realm of expectation.
Evaluation and assessment are implicit aspects of any human activity. As with any scientific or engineering discipline, evaluation is essential for rational development. For any activity, we must have some way of judging whether we are finished or not, whether the work we did meets its intended purpose, and whether a new object we have made strikes those who experience it as something of value.
In defining the research and development processes, it is essential to characterize the fundamental aspects of human activity assessment. In the language technologies, as in most software development enterprises, evaluation measures the state of a particular model (working or conceptual, a prototype or a product) in terms of the expectations it is committed to meet, the general expectations of models of that type, and the place of that model among other models which are equivalent in some respect.
As with any industry, it became apparent early on that two types of evaluation were required: first, the different approaches to particular language processing techniques had to compared, and second, the single approaches needed to be evaluated against their own objectives. The different stakeholders in language processing need different types of evaluation: what an end-user needs to know is rather different from what an investor needs to know, which is turn different from what a research sponsor needs to know. At the core of each, however, is the awareness that the language processing technique or approach must have some applicability in the world. Each of the various technologies and modalities have, naturally, matured at different rates, and as each matures, the ultimate applicability can be evaluated in ways more focused on that central view.
There are several dimensions and roles for natural language processing, and consequently, more than one evaluation metric to be employed. At least the following types of processing differ enough to warrant different treatment: understanding vs. generation, the different language modalities, the choice of language, and end use. For all these classifications, however, evaluation may be divided into formative (development against objectives) and summative evaluations (comparison of different systems, approaches, integration, etc.)
The end-to-end dimensions of evaluation by be characterized by the evaluative focus (black-box/glass-box/gray-box), by its purpose (comparative/diagnostic, predictive/a posteriori), or by the impact of the technology in applications, up to socio-economic or program evaluation. This whole area has been depicted in terms of an "ethnography of evaluation" (Hirschman, 1998b).
In certain areas, the evaluation programs were already robust, with the MUC (information extraction from text) series already at number 4 (Grishman and Sundheim, 1996), and the ATIS (speech recognition) series in its third year (Hirschman, 1998a). In speech recognition/understanding, the RSG10 series on multilingual recognition systems assessment had already been underway since 1979. The US Defense Advanced Research Projects Agency (DARPA) had been developing and evaluating HARPY, HEARSAY and other systems by the mid-70s, but with a non-comparative, non-satisfactory approach. In Europe, the LE-SQALE project was starting, and the EAGLES study on evaluation of Language Processing systems (King et al., 1996), European Network of Excellence in Language and Speech (ELSNET), and LE-Eurococosda were already underway. At the international level, the Coordinating Committee on Speech Databases and Speech I/O Systems Assesment (Cocosda) was initiated at the Eurospeech-91 conference satellite workshop in Chiavari (Italy). More information appears in
Chapter 5.With respect to the understanding of written language, ‘deep’ understanding approaches (parsing, semantic analysis, etc.) were still the primary focus as recently as five years ago. But new techniques were emerging, which were conceptually simpler, involved less reasoning, and took better advantage of new-generation computer processor speeds. These methods, mostly statistical in nature, were applied to various tasks. Statistical MT was achieving a level of R&D maturity (Brown et al. 92), while simpler, ‘shallow’ parsing models were proving their value in information extraction (
Chapter 3). The information retrieval evaluation conference series in the US called TREC (Voorhees and Harman, 1998) was just underway, an enterprise in which empirical retrieval methods would indicate the potential for non-rule-based approaches to large-corpus language processing (see Chapter 2).Evaluation methods responded to these new trends by beginning the dialectic on diversifying evaluation techniques to measure those attributes and tasks for which a particular approach was presumably best suited. As we explain below, diversification did occur in extraction and in speech recognition. The issue was in fact pre-eminent in the beginnings of a new generation of machine translation evaluation sponsored in the US by DARPA as the MT Evaluation initiative (MTEval; (White and O’Connell, 1994)), but the balance of specialization measures vs. comparison measures was (and is) unresolved.
8.2.1 Capabilities Five Years Ago
At the time, the US government sponsored the Message Understanding Conference (MUC) evaluation series (Grishman and Sundheim, 1996), whose methods still presented a single, undifferentiated, task, although multi-lingual applications and the installation of subtasks was not far away (see also
Chapter 3). The scoring methodology was already well developed and reasonably portable across platforms, allowing it to be run independently by each contractor. TREC, started by the U.S. National Institutes for Standards and technology (NIST), was developing a corpus, in concert with the U.S. Government Tipster program, from which other evaluations drew (for example, MTEval). The Penn Treebank was developing a new variety of corpus-tagged parses of English constituents, which would prove to be of use for the smaller DARPA-initiated Parseval. In Europe, the EAGLES study group on machine translation and speech recognition evaluation was established under EU funding (King et al., 1996).With respect to speech recognition, a set of metrics was well-established, e.g., word insertion/deletion/substitution as a black-box evaluation measure. Rates of understanding errors was a well-used measure in ATIS, but still unsatisfactory (for example, a wrong response was simply considered an error twice more important than no response). This period (1992) saw the participation of non-US laboratories in speech recognition evaluations, and the beginning of large-scale multilingual systems evaluation.
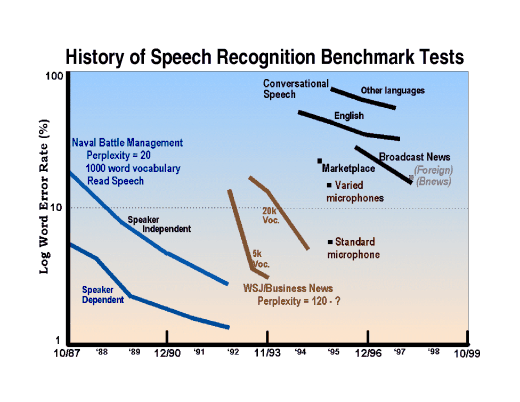
Figure 1. A history of speech recognition benchmarks.
8.2 Major Methods, Techniques, and Approaches Five Years Ago
The pre-eminent evaluation method in the major programs was a corpus-based, automatic scoring approach. When successful, this enabled a comparison among systems, theoretical approaches, and intended functional usage. However, not all language technologies are readily amenable to automatic measurement methods. Machine translation and summarization, to name two, are difficult in this regard, because in each case there is never exactly one "right" answer. Automated text summarization as an evaluable track had not reached maturity at this time, but the issue of the subjectivity of evaluation measures in MT was a known problem. To address this, DARPA developed approaches that took advantage of language intuitions of otherwise disinterested native speakers of the target language, dividing evaluation tasks into small decision points so that, with a sufficient rater sample size, the intuitive judgments could be exploited for generalizations on the fidelity and intelligibility of MT output.
In general, one can divide the evaluation methods of the day into two classes: technology evaluations (MUC, TREC: both off-line and corpus-based), and subject based evaluations (summarization, MTEval: both requiring significant assessor effort). MUC developed automated methods for template alignment and scoring, as well as appropriate evaluation metrics, including an extraction-specific adaptation of the standard IR precision metric. TREC addressed significant issues with ground truth development in a gigantic retrieval corpus. MTEval showed the beginnings of a new evaluation methodology by taking advantage of the very subjectivity that caused it problems in the first place. In speech recognition (ATIS), a corpus-based evaluation of an interactive task, using pre-recorded queries, measured the accuracy of retrievals. Though this method was good for training, it showed little extensibility, and no real-time evaluation capability.
8.3 Major Bottlenecks and Problems Then
Major problems then, and to a large extent today, involved the availability of test corpora. Much use was made of an available Wall Street Journal corpus during the period, as well as the Canadian Parliament Hansard corpus for training. But access to the huge volumes of data required for valid evaluation of the information retrieval task remained a vexing issue. A related issue lay in the incompatibilities of the character sets for non-Roman writing systems (and even European languages, for which wire services at the time routinely omitted diacritics).
Speech evaluation initiatives of the period suffered from a need for infrastructure and standard metrics. In fact, many of the language technologies have not had evaluation paradigms applied to them at all. Many times, such activities have been sporadic in time and place, producing results difficult to compare or derive trends.
8.3 Where We Are Today
In contrast to five years ago, it is probably the case that most language processing technologies today have more than one program for cross-system evaluation. Evaluations of speech processing in Aupelf-Francil (Mariani, 1998), Verbmobil (Wahlster, 1993; Niemann et al., 1997), Cocosda, LE-Sqale, and others demonstrated the growth in interest and capability of evaluation. Several measures have become accepted as standards, such as the MUC interpretations of recall, precision, and over-generation. Other measures still are only used by some communities and not in others, and the usefulness of some measures is still under question.
8.3.1 Capabilities Now
Emerging capabilities have led to evaluation methods and metrics of increased sensitivity. In speech recognition, there are now separate tracks such as the NIST series, which includes HUB 4 (broadcast news), HUB 5 (telephone conversations), speaker recognition, spoken document retrieval, and a new initiative in topic detection and tracking. Each HUB track uses standard scoring packages. Meaningful metrics and scoring algorithms have facilitated the evaluation of the new capabilities.
In the MUC series, text extraction is now divided into multiple tasks, including named entity extraction and co-reference identification.
The first automated text summarization evaluation SUMMAC-98 (Firmin Hand and Sundheim, 1998; Mani et al., 1998) was held in 1998. While two of its three measures (recall and precision) closely paralleled ones used for Information Retrieval, some investigations were made of ways to incorporate measures of text compression (ratio of summary length to full-document length) and measures of specificity/utility of content (informative value of content in addition to indicative value of content).
Most of the more established evaluation series have found that system capabilities begin to asymptote. Speaker Independent Large Vocabulary Continuous Speech recognition rates for read texts dictation, for example, have reached a plateau, and may respond well to a new challenge such as spontaneous speech (see the Switchboard or Call Home results), prosody, dialogue, or noisy environment. MUC information extraction scores seemed to plateau at around 60% recall on the scenario-based extraction (Scenario Template) tasks. It must be noted for both these cases, though, that progress has been made: the evaluation tasks have become much more difficult and varied over the years.
8.3.2 Major Methods, Techniques, and Approaches
It is possible to identify a trend toward standard, human-oriented evaluation methodologies, particularly in the subject-bound evaluation types (Hirschman, 1998b). In MTEval and SUMMAC, subjects are presented with variants of the very familiar reading comprehension test. The difference of course is that what is being evaluated is the thing read, not the reader! However, the form is useful because it requires less familiarization on the part of the subjects, and its parameters are known (e.g., the form and impact of distracters in the multiple-choice format).
One trend over the last three years has been a focus on the user’s business process. The operational requirements of the user’s work are naturally reflected in a process flow, into which new language processing capabilities are inserted. In this context, it is not as useful to evaluate individual systems on performance metrics as it is to measure the improvement they make to the business process as a whole. The US Federal Intelligent Document Understanding Laboratory has developed a set of techniques for making these assessments, both for first-time automation of a particular function to impact of enhancements (White et al., 1999).
8.3.3 Major Current Bottlenecks and Problems
Major problems include the need for rapid evaluations, the size of evaluation efforts, the test data available, and a sentiment in part of the research community that standardized evaluation "may kill innovative ideas".
Technical innovations in the R&D world, as well as rapid release iterations of commercial products, have forced the performance of evaluations as rapidly as possible. This is a problem for evaluations that are strongly subject-based, such as MT, summarization, and dialogue evaluation. Here, implementation of the measurement process involves recruitment of many subjects (raters), large-scale organization of materials, and a very large sample size of decision points to make a valid measurement. The situation is very difficult where assessments is required from users or other experts. Such people can rarely commit the time required for usability testing.
A second pressing problem is the availability of corpora. Although ameliorated in the text-based technologies by the explosion of available text sources on the internet in the last five years, the lack of character-set standards for non-Roman writing systems continues to stymie the development of uniform corpora, and encoding standards such as Unicode have had a slower acceptance rate than was predicted.
A major issue is the expense of assembling subject groups. One potential for breakthroughs is to get thousands of users to participate in an evaluation/experiment. As has been shown by the MIT Galaxy System, people will voluntarily participate if the system they are evaluating provides good enough service (in this case, weather information over the telephone; the evaluation was on Galaxy’s speech recognition).
The cost can also be reduced by following the trend already in place for the subject-based evaluations, namely to use standardized human tests (such as reading comprehension, in MTEval and SUMMAC). The resources saved from developing artificial corpora can then be directed toward building systems. However, there is a difficulty in making the inferential leap from Technology evaluation to User evaluation. In practice, there may be a decrease in measured performance of speech systems when actually fielded, compared with their performance in test-bed evaluation, in one case from 94 to 66% (Haaren et al., 1998). Sufficient Technology-centered performance is not enough: there must be metrics for size of effort, genericity, interest, usability (cf. the Eagles program (King et al., 1996)). However, User-centered evaluation does not tell the whole evaluation story either, if not properly conducted. This is illustrated in the example given by Haaren et al., where two cities that are acoustically similar (Mantes and Nantes) are misrecognized by the railway query dialog system, even while the user continues the dialog (since his goal is not to get a train ticket, but to assess the quality of the dialog system).
At present, no-one would say that the evaluation of any aspect of language processing is a closed issue. For speech recognition, dialogue evaluation remains a difficult and open problem (ATIS, MASK, ARISE, Elsnet Olympics-97). Text summarization has only just completed its very first evaluation. The increasing number of subtask evaluations in TREC and MUC suggest that technological progress can best be measured and achieved by acknowledging the intrinsic complexity of IR and IE as application areas and by breaking out some of the component areas as evaluation focal points. Needed still are methods for evaluating such (notional) components as word sense disambiguation, event argument identification, and textual discourse tracking. Machine Translation evaluation is still searching for a general, easily comprehensible yet comprehensive, methodology, as illustrated by (White and Taylor, 1998; Hovy, 1999).
We must not lose sight of the goals of evaluation: better research and better products. The community needs data to measure progress, and it needs standardization of measures, including of evaluation confidence measures (Chase, 1998).
At this time, evaluation remains difficult not least because of a lack of a clear vision within most of the technologies for the average level of current performance, the commonly recognized best practices, and the most promising new approaches.
8.4 Where We Will Be in 5 Years
The most significant issue facing evaluation over the next five years is the cycle of expectation and demand in software evolution. As capabilities become available to a wider group of people, demand is created for the new capability, and the expectation that many more things will soon be possible becomes palpable. It is difficult for anyone to separate the intractable problems from the routine in software development, except perhaps in one’s own focused area of expertise.
With respect to NL processing, the expectation invariably leads to ingenious solutions to problems, namely, the (loose) integration of language processing functions together in one system. Much of this integration will employ the simplest possible means (e.g., word processing macros) to facilitate the maximally automated passage of data from one language processing system to another. Optical character readers are already integrated with MT systems, as are browsers, detection, and extraction systems. In each case, the goal of the loose integration is saving time and avoiding complexity, which implies trying to eliminate the human from the inter-process loop, usually with disastrous consequences in lost capability. Evaluation must respond to this challenge by facilitating the best possible loose integration in these situations, by assessing the contribution of each processing system to the overall process, but also, by assessing the areas where each system’s output does particular harm to the performance of the downstream system.
At the same time, R&D and software engineering will be in the process of creating deep integration among systems (for example, several of the current experiments in speech translation; see
Chapter 7). In such integration, evaluation will have to change to accommodate the relevant issues that arise.In parallel, the development of semantics as a common foundation of processing requires a push in evaluation of such issues as WordNet (Miller, 1990), lexicon development, knowledge acquisition, and knowledge bases.
8.4.1 Expected Capabilities in Five Years
In five years, there will have been a closer integration of functions in end-to-end language processing systems. Evaluation will have to develop and apply methods which are relevant to the emerging uses of such integration, but which also have two other characteristics: they will have to be sensitive to more open-system implementations (i.e., allow for substitutions of language processing systems within the context of the larger system) while at the same time providing measures that are comparable to the historical measures of recent evaluations. They must also be more heavily user-oriented.
8.4.2 Expected Methods and Techniques
Task-oriented evaluation methodologies will form a significant thrust in evaluation methods in five years. These metrics will assess the usefulness of a system’s output for subsequent tasks. For example, MT systems will be measured by how well their output can be used by certain possible downstream tasks. This, of course, requires that the community develop measures of the tolerance levels of language processing tasks for suitable input quality.
With regard to evaluation processes themselves, we can expect them to become increasingly fast and easy to use. Long before 5 years from now it should be possible to perform a black-box evaluation of particular types of language processing systems in real time over the internet, by accessing scoring algorithms for non-subjective measures and applying them.
In particular, we should hope for evaluation approaches that make use of semi-automatic black-box approaches that are reproducible and confidential. With respect to the integration of different technologies, there should be definable control tasks around which the integrated functions should be organized.
8.4.3 Expected Bottlenecks
User-oriented evaluations will continue to be an issue, for the reasons noted above. However, they will become more commonplace. Some scoring algorithms will be built on captured knowledge gained from valid user samples, reusable automatically. This is, for example, the intended result of the ongoing MT functional proficiency scale measure. In fact, user-based evaluations are already commonplace in some speech recognition development programs, although user acceptance is not the only measure to develop.
The good news for corpus availability is not that everyone will have adopted representation and text encoding standards, but that there will be critical masses of standard forms that production of large corpora will be much simpler process.
8.5 Juxtaposition of this Area with Other Areas and Fields
8.5.1 Related Areas and Fields
As discussed above, the trend toward integration of several language processing functions within a user’s process is ongoing, and will progress toward deeper integration of functions. Evaluation must accommodate the human user component aspect of the introduction of integrated systems, as described in part. At the same time, there should be methods for evaluation of the deeper integration of language processing systems, in which, for example, the different functions share lexical, syntactic, or conceptual knowledge. It is not unreasonable to expect IR, MT, and Summarization systems to share some basic knowledge resources, such as lexicons, as well as some core processing algorithms, such as wordsense disambiguation routines. Along these lines, new tracks in the speech community demonstrate sensitivity to the integration of language processing capabilities. For example, ATIS included not only evaluations based on the speech signal, but also evaluations based on the transcribed speech signal, for laboratories working on NLP, and not on speech. Similarly, evaluation in spoken document retrieval and on topic detection/tracking includes the participation of speech researchers, working directly with the speech signal, as well as NL researchers, either working on the transcription of the speech signal or in cooperation with speech researchers.
Multimodality will increase the complexity of NL processing systems and components, because they will be required at least to be able to collaborate in their task with other communication components, so as to be able to handle several communication channels (e.g., speech and gesture recognition; see
Chapter 9). As the complexity of systems increases the combinatorics of module composition grows and assessing the different combinations becomes more difficult. To harvest the benefits of this combinatoric expansion, evaluation is needed, particularly in cross-domain approaches.8.5.2 Existing Interconnections: Shared Techniques, Resources, Theories
Evaluations are already occurring in ATIS and HUB that deal with multi-function techniques. These in effect merge the measures that exist for each in isolation. On another dimension, individual language processing functions that share certain characteristics may be evaluated alike. This is the case with the conceptually similar approach to evaluating MT and summarization, discussed above. An example of resource sharing is offered by the recent SUMMAC, which re-used parts of the TREC collection (documents, relevance assessments, and even assessment software).
8.5.3 Potential Connections That Have Not Yet Been Made
The emerging multi-modality of information, and thus in the emerging expectations for retrieval and automatic understanding, ultimately will require a multi-directional means of evaluating those techniques that integrate the multi-modality. The MT functional proficiency scale measure mentioned above is a ‘one-way’ connection from MT output to task input downstream. In this case, the other language processing tasks (extraction, detection, gisting, for instance) are all seen as accepting MT output as input. However, the flexible interactions likely to be required in the future will alter the order in which certain processes occur to optimize efficiency and accuracy. There needs to be a manner of evaluating such flexible interactions simply and quickly.
As discussed in
Chapter 9, the increase in multi-modal systems and assumptions will create a combinatory explosion of module interactions; the challenge for evaluation will be to cull the possible combinations into the best.8.5.4 What is Required for Cross-Fertilization
Continuing dialogues on resources and evaluation is an essential means of continuing the cross-fertilization. Of particular usefulness here is the commitment for joint development of generic test-beds for evaluating multi-functional and multi-modal integration. To that end, meetings such as the international LREC conference will continue to be of significant value in fostering cross-fertilization of evaluation processes, methods, and metrics.
8.5.5 What might be the Beneficial Results of Cross-Fertilization
As noted above, most of the language processing technologies that we currently can imagine will be required by the user community to be integrated. The expectation of this and other computer technologies is that the integration should be easy to accomplish (of course, it is not), and so the demand remains high even though promising approaches in the past have often not come to fruition. Given that the successful integration of the various functions is a foregone conclusion, the development of evaluation techniques, both those currently applicable and those that will be sensitive to the deep integration issues of the future, must be pursued jointly by the different language technology communities.
8.6 The Treatment of Multiple Languages in this Area
Multilingual issues are by definition germane to MT, though even here the state-of-practice has been pair-specific (and direction-specific) rather than generally driven by the wider issues of multi-lingual processing. In the other language processing technologies, multilingual issues in evaluation are a natural outgrowth of both the maturation of the technologies and the increasing availability of, and demand for, foreign language materials.
Multilingual issues have been used in evaluation of programs for quite some time. In practice, evaluation techniques have proven to extend quite easily to multiple languages. MUC-5 contained English and Japanese tracks, and MUC 6 and 7 contain a Multilingual entity task called MET (Grishman and Sundheim, 1996). The DARPA Broadcast News evaluation includes Spanish and Mandarin. It is not difficult to see how SUMMAC can be extended to include other languages. In the EU, the NATO RSG10 (1979) speech recognition evaluation employed American English, British English, French, Dutch, and German. Le-Sqale (1993—95) uses American English, British English, French, and German. Call-Home, TDT, Language identification, and Cocosda studies have all focused on multiple language recognition, synthesis and processing.
8.6.1 Need for Multilingual Treatment
Several aspects are apparent in the evaluation of multilingual data. First, given that individual technologies must adapt to handle multilingual issues, glass-box evaluations should have metrics for assessing the extensibility of particular approaches. Second, with respect to the integration issues noted above, evaluation must measure the degradation that ensues upon the introduction of a new language, as either input or output. Third, evaluations should attempt to pinpoint the best areas for ‘deep’ integration that takes into account multilingual, interlingual, or extra-linguistic conceptual models.
It is encouraging that language engineering has become less and less partitioned across nationalities because of the increasing availability of resources, but also because of the increasing movement of professionals and ideas across boundaries.
8.6.2 Bottlenecks: Resources and Techniques
Evaluation methods extend easily to new languages, but corpora do not. Suitable corpora, particularly parallel corpora, are rare. Much progress has been gained from the Hansard parallel corpus and there is promise from the United Nations proceedings. The DARPA MTEval parallel corpora, though small, have already been used to good effect in research of sociolinguistic aspects of the translation problem (Helmreich and Farwell, 1996).
In fact, the limiting factors are resources and multilingual tools for resource development. The expansion of multilingual systems will not be possible without the creation and use of common standards and resources of sufficient quality and quantity across the different languages.
8.7 References
Brown, P., J. Cocke, S. Della Pietra, V. Della Pietra, F. Jelinek, J. Lafferty, R. Mercer, P. Roossin. 1990. A Statistical Approach to Machine Translation. Computational Linguistics 16(2), 79—85.
Chase, L.L. 1998. A Review of the American Switchboard and Callhome Speech Recognition Evaluation Programs. In Proceedings of the First International Conference on Language Resources and Evaluation (LREC), 789—794. Granada, Spain.
Firmin Hand, T. and B. Sundheim. 1998. TIPSTER-SUMMAC Summarization Evaluation. Proceedings of the TIPSTER Text Phase III Workshop. Washington.
Grishman, R. and B. Sundheim (eds). 1996. Message Understanding Conference 6 (MUC-6): A Brief History. Proceedings of the COLING-96 Conference. Copenhagen, Denmark (466—471).
Helmreich, S. and D. Farwell. 1996. Translation Differences and Pragmatics-Based MT. In Proceedings of the Second Conference of the Association for Machine Translation in the Americas (AMTA-96), 43—55. Montreal, Canada.
Van Haaren, L., M. Blasband, M. Gerritsen, M. van Schijndel. 1998. Evaluating Quality of Spoken Dialog Systems: Comparing a Technology-Focused and a User-Focused Approach. In Proceedings of the First International Conference on Language Resources and Evaluation (LREC), 655—662. Granada, Spain.
Hirschman, L. 1998a. (ATIS Series) Evaluating Spoken Language Interaction: Experiences from the DARPA Spoken Language Program 1980—1985. In S. Luperfoy (ed.), Spoken Language Discourse, to appear. Cambridge: MIT Press.
Hirschman, L. 1998b. Language Understanding Evaluations: Lessons Learned from MUC and ATIS. In Proceedings of the First International Conference on Language Resources and Evaluation (LREC), 117—122. Granada, Spain.
Hovy, E.H. 1999. Toward Finely Differentiated Evaluation Metrics for Machine Translation. In EAGLES Handbook, EAGLES Advisory Group. Pisa, Copenhagen, Geneva.
King, M. et al. 1996. EAGLES Evaluation of Natural Language Processing Systems: Final Report. EAGLES Document EAG-EWG-PR.2, Center for Sprogteknologi, Copenhagen.
Mani, I. et al. 1998. The TIPSTER Text Summarization Evaluation: Initial Report.
Mariani, J. 1998. The Aupelf-Uref Evaluation-Based Language Engineering Actions and Related Projects. In Proceedings of the First International Conference on Language Resources and Evaluation (LREC), 123—128. Granada, Spain.
Miller, G.A. 1990. WordNet: An Online Lexical database. International Journal of Lexicography 3(4) (special issue).
Niemann, H., E. Noeth, A. Kiessling, R. Kompe and A. Batliner. 1997. Prosodic Processing and its Use in Verbmobil. Proceedings of ICASSP-97, (75—78). Munich, Germany.
Voorhees, E. and D. Harman. 1998. (TREC series) Overview of the Sixth Text Retrieval Conference (TREC-6). In Proceedings of the Sixth Text Retrieval Conference (TREC-6), in press. See also
http://www.TREC.nist.gov.Wahlster, W. 1993. Verbmobil, translation of face-to-face dialogs. Proceedings of the Fourth Machine Translation Summit (127—135). Kobe, Japan.
White, J.S. and T.A. O’Connell. 1994. (MTEval series) The DARPA MT Evaluation Methodologies: Evolution, Lessons, and Future Approaches. In Proceedings of the First Conference of the Association for Machine Translation in the Americas (AMTA-94). Columbia, Maryland.
White, J.S. and K.B. Taylor. 1998. A Task-Oriented Evaluation Metric for Machine Translation. In Proceedings of the First International Conference on Language Resources and Evaluation (LREC), 21—26. Granada, Spain.
White, J.S., et al. 1999. White, J.S. FIDUL assessment tasks. In prep.