This is the second article in my three part series on the open research problems for transaction processing database systems. In part one, I discussed non-volatile memory. The next topic is on many-core CPU systems.
The Rise of Multi-Core
In the mid-2000s, the trend in CPU architectures shifted from increasing clock speeds of single-threaded execution to multi-core CPUs. Clock frequencies have increased for decades, but now the growth has stopped because of hard power constraints and complexity issues. Aggressive, out-of-order, super-scalar processors are being replaced with simple, in-order, single issue cores.
Much of the research and development in DBMSs for multi-core has been on adapting existing architectures that assumed a single CPU core to utilize additional cores. Ryan Johnson's dissertation on optimizing Shore-MT is probably the best example of this. Although this work was important, timely, and necessary, the number of cores that it targeted was relatively small compared to what people expect future processors to be able to support. If you look at recent research papers on shared-memory OLTP DBMSs, the number of cores that they use in their evaluation is modest. For example, I consider the current state-of-the-art in high-performance transaction processing to be the Silo system from Eddie Kohler and friends. But in their 2013 SOSP paper they used a machine with 32 cores. Similarly, the latest paper for HyPer in this year's SIGMOD used a 32-core machine. I'll readily admit that both of these systems are actually better at scaling on a single-node than H-Store. Our system doesn't scale past 16 cores per node because of JVM garbage collection issues with JNI (H-Store gets around this limitation by being distributed). Despite being published over two years ago, one of the Shore-MT papers uses an 80-core machine for their experiments. But even 80 cores is still small compared to how we think things will be in the future.
Why Many-Core is Different
We will soon enter the era of the "many-core" machines that are powered by potentially 100s to 1000s of these smaller, low-power cores on a single chip. You may be wondering how future DBMS research for many-core CPUs is going to be different than what was previously done with multi-cores. I believe that the previous systems were all about software approaches that used hardware in a smarter way. But the difference is that with many-cores there seems to be a fundamental barrier into what gains can be achieved with software. Think of it like a speed of light limit. As such, it is my hypothesis that the advancements from the previous decade for running DBMSs on multi-core CPUs will not be enough when the core counts are much greater.
To prove this point, I am working with the always excitable Srini Devadas at MIT and our plucky student Xiangyao Yu to investigate how OLTP DBMSs perform on a CPU with 1000 cores. Such chips obviously do not exist yet, so we have been using a CPU simulator developed by Srini's group called Graphite and using a new DBMS written by Xiangyao called DBx1000 to test different aspects of transaction processing. Graphite's simulated architecture is a tiled chip multi-processor where each tile has a small processor core, two levels of cache, and a 2D-mesh network-on-chip for communication between the cores. This is similar to other commercial CPUs, such as Tilera's Tile64 (64 cores), Intel's SCC (48 cores), and Intel's Knights Landing (72 cores).
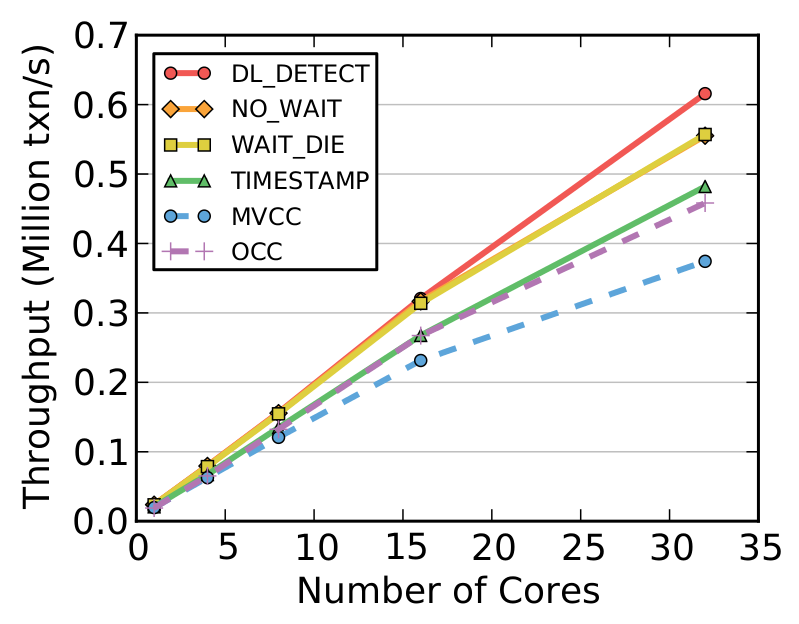
We have conducted initial experiments using DBx1000 to test what happens when executing transactions with high core counts. We started with concurrency control schemes, as this is always the main bottleneck that needs to be addressed first in an OLTP DBMS. DBx1000 supports a pluggable lock manager that allows us swap in different two-phase locking and timestamp-ordering concurrency control schemes. We adapted these schemes from the great Phil Bernstein's seminal paper on concurrency control algorithms and implemented state-of-the-art variants. For example, our MVCC implementation is similar to Microsoft's Hekaton and our OCC implementation is based on Silo. In the graphs below, we compared six of these concurrency control schemes using YCSB. We first execute DBx1000 on a Intel Xeon CPU and then again on our simulator:
 Intel Xeon E7-4830 (Dual Socket) |
 Graphite Simulator |
|
| Figure 1: Comparison of the concurrency control schemes with DBx1000 running in Graphite and a real multi-core CPU using the YCSB workload with medium contention. | ||
These results show that all of the algorithms achieve better performance up to 32 cores with the same relative trends. This corroborates previous findings from the papers discussed above. But now when we crank up the number of cores to 1000 in the Graphite simulator, things look strikingly different when going past 64 cores:
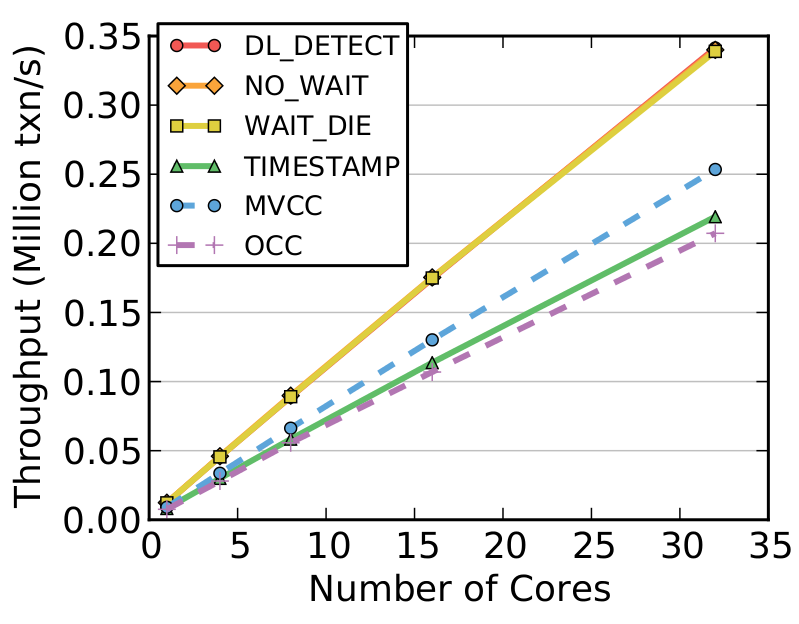
 Graphite Simulator |
||
| Figure 2: Comparison of the concurrency control schemes with DBx1000 running in Graphite using the YCSB workload with medium contention. | ||
The above results show that the two-phase locking variant NO_WAIT is the only scheme that scales past 512 cores, but even it fails to scale up to 1000 cores. Many of the schemes are inhibited by lock thrashing and high transaction abort rates. This is because there are too many concurrent threads trying to access the same set of records. Clearly, no scheme is ideal here.
The next question is how can we overcome this performance barrier. Initially, Xiangyao and I started drinking heavily to ease the pain of knowing that DBMSs won't be able to scale to 1000 cores. I always suspected that this was the case, but something just snapped in my head once I saw the results and it drove me to look for answers in the bottom of the bottle. This was not sustainable (both financially and medically) and thus we needed to come up with a way to actually solve this problem.
Hardware-Software DBMS Co-Design
I believe that the next trend in the many-core era is the development of software-hardware co-design for new DBMS architectures. On the software side, rather than attempting to remove scalability bottlenecks of existing DBMS architectures through incremental improvements, we seek a bottom-up approach where the architecture is designed to target many-core systems from inception. On the hardware side, instead of simply adding more cores to a single chip, we will design new hardware components that can unburden the software system from computationally critical tasks. Other existing technologies that are not fully appreciated in DBMSs yet, such as transactional memory, may also play a key part of this work.
For our work, this will be performed in the context of the DBx1000 and Graphite as part of the Intel Science and Technology Center for Big Data and our recently awarded NSF XPS grant. We will first focus on concurrency control, but will later expand our scope to include both indexing and logging bottlenecks. Others are also pursuing this path, including Ryan Johnson and Ippokratis Pandis with their Bionic DBMSs, and Martha Kim's Q100 accelerator (although that project is focused on OLAP workloads).
Note that one should not label this research as the second coming of "database machines", since it will still be in the context of the prevailing CPU architectures.