Dynamic Cascades with Bidirectional Bootstrapping for Spontaneous Facial Action Unit Detection
People
- Yunfeng Zhu
- Fernando de la Torre
- Jeffrey F. Cohn
- Yu-Jin Zhang
Abstract
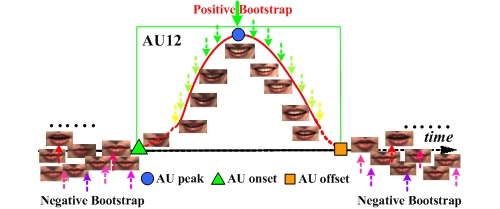
A relatively unexplored problem in facial expression analysis is how to select the positive and negative samples with which to train classifiers for expression recognition. Typically, for each action unit (AU) or other expression, the peak frames are selected as positive class and the negative samples are selected from other AUs. This approach suffers from at least two drawbacks. One, because many state of the art classifiers, such as Support Vector Machines (SVMs), fail to scale well with increases in the number of training samples (e.g. for the worse case in SVM), it may be infeasible to use all potential training data. Two, it often is unclear how best to choose the positive and negative samples. If we only label the peaks as positive samples, a large imbalance will result between positive and negative samples, especially for infrequent AU. On the other hand, if all frames from onset to offset are labeled as positive, many may differ minimally or not at all from the negative class. Frames near onsets and offsets often differ little from those that precede them. In this paper, we propose Dynamic Cascades with Bidirectional Bootstrapping (DCBB) to address these issues. DCBB optimally selects positive and negative class samples in training sets. In experimental evaluations in non-posed video from the RU-FACS Database, DCBB yielded improved performance for action unit recognition relative to alternative approaches.
Citation

|
Yunfeng Zhu,
Fernando de la Torre, Jeffrey F. Cohn, and Yu-Jin
Zhang
Dynamic cascades with bidirectional bootstrapping for spontaneous facial action unit detection Affective Computing and Intelligent Interaction and Workshops, 2009. ACII 2009. 3rd International Conference on, Sept. 2009. [PDF] [BibTex] |
Acknowledgements and Funding
This research was supported in part by NIMH grant MH 51435. The first author was also partially supported by the scholarship from China Scholarship Council. The work was performed when the first author was at Robotics Institute, Carnegie Mellon University. Thanks to Tomas Simon, Feng Zhou, Zengyin Zhang for their valuable suggestions.
Copyright notice
| Human Sensing Lab |