Occlusion Reasoning for Object Detection under Arbitrary Viewpoint
People
Martial Hebert
Description
Occlusions are common in real world scenes and are a major obstacle to robust object detection. Whereas previous approaches primarily modeled local coherency of occlusions or attempted to learn the structure of occlusions from data, we propose to explicitly model occlusions by reasoning about 3D interactions of objects. For a given environment, we compute physical statistics of objects in the scene and represent an occluder as a probabilistic distribution of 3D blocks. The physical statistics need only be computed once for a particular environment and can be used to represent occlusions for many objects in the scene. By reasoning about occlusions in 3D, we effectively provide a unified occlusion model for different viewpoints of an object as well as different objects in the scene. The main contributions of this work are (1) a concise model of occlusions under arbitrary viewpoint without requiring additional training data and (2) a method to capture global visibility relationships without combinatorial explosion.
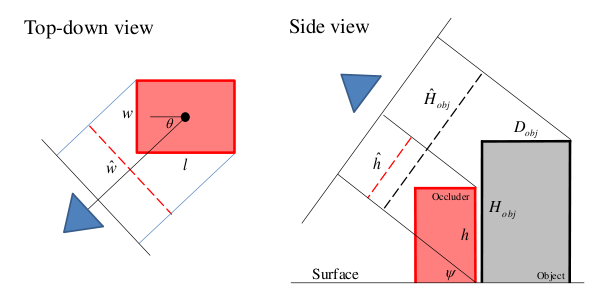 |
| Figure 1. Occlusion model. Given the object viewpoint, an occluder (red) is modeled by its projected width and projected height in the image. |
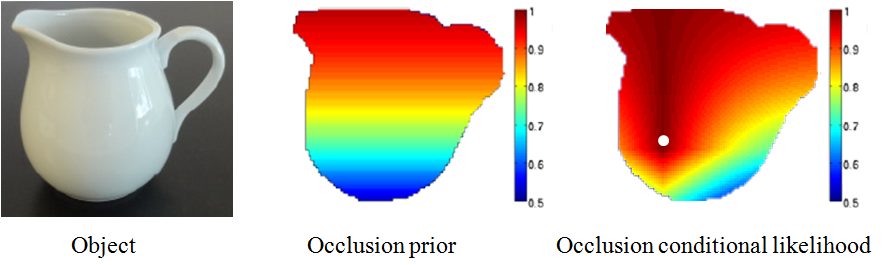 |
| Figure 2. Occlusion probabilities. |
We validate our approach by extending the LINE2D method, a current state-of-the-art system for instance detection under arbitrary viewpoint. Since current datasets for object detection under multiple viewpoints contain either objects on simple backgrounds or have minimal occlusions, we collected our own dataset for evaluation under a more natural setting. Our dataset contains 1600 images of 8 objects in real, cluttered environments and is split evenly into two parts; 800 for a single view of an object and 800 for multiple views of an object. The single-view part contains ground truth labels of the occlusions and contains roughly equal amounts of partial occlusion (1-35%) and heavy occlusions (35-80%) as defined by Dollar et al. Our results on this challenging dataset demonstrate that capturing global visibility relationships is more informative than the typical a priori probability of a point being occluded and that our approach can significantly improve object detection performance.
 |
| Figure 3. Example detection results under severe occlusions in cluttered household environments. |
Dataset
The CMU Kitchen Occlusion Dataset (CMU_KO8) containing 1600 images of 8 objects under severe occlusions in cluttered household environments with ground truth. [ZIP 213MB]References
[1] Edward Hsiao and Martial Hebert. Occlusion Reasoning for Object Detection under Arbitrary Viewpoint. IEEE Conference on Computer Vision and Pattern Recognition (CVPR) , June, 2012.
Funding
This material is based upon work partially supported by the National Science Foundation under Grant No. EEC-0540865.