While generative models produce high-quality images of concepts learned from a large-scale database, a user often wishes to synthesize instantiations of their own concepts (for example, their family, pets, or items). Can we teach a model to quickly acquire a new concept, given a few examples? Furthermore, can we compose multiple new concepts together?
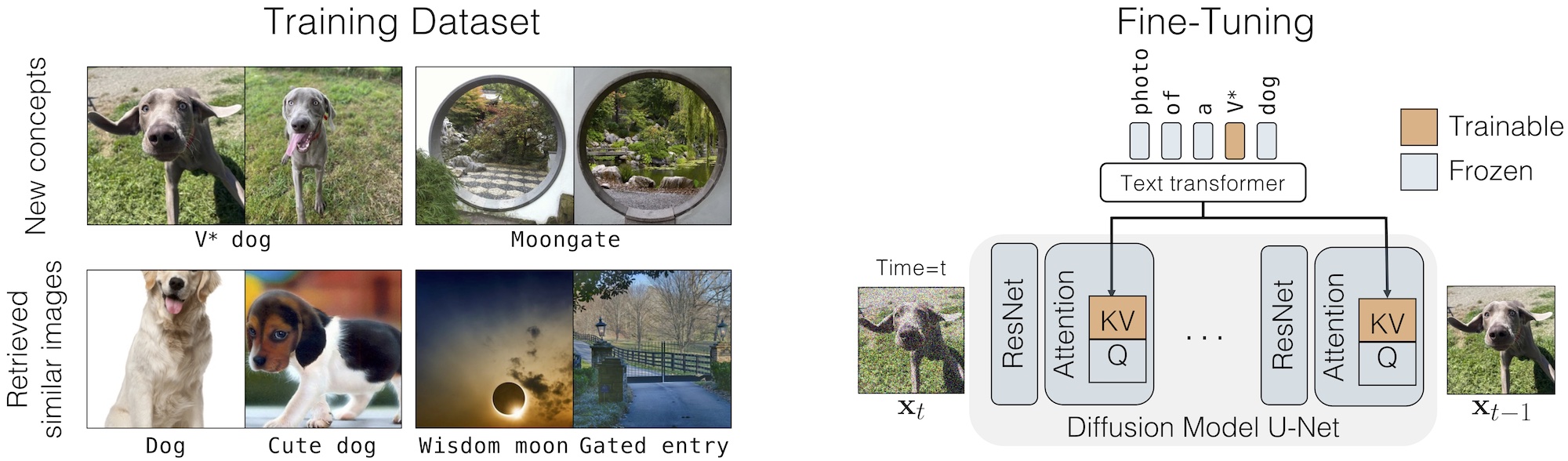
We propose Custom Diffusion, an efficient method for augmenting existing text-to-image models. We find that only optimizing a few parameters in the text-to-image conditioning mechanism is sufficiently powerful to represent new concepts while enabling fast tuning. Additionally, we can jointly train for multiple concepts or combine multiple fine-tuned models into one via closed-form constrained optimization. Our fine-tuned model generates variations of multiple new concepts in novel unseen settings.
Our method is fast (~6 minutes on 2 A100 GPUs) and has low storage requirements (75MB) for each additional concept model apart from the pretrained model. This can be further compressed to 5 - 15 MB by only saving a low-rank approximation of the weight updates.
We also introduced a new dataset of 101 concepts for evaluating model customization methods along with text prompts for single-concept and multi-concept compositions. For more details and results please refer to the dataset webpage and code.

Given a set of target images, our method first retrieves (generates) regularization images with similar captions as target images. The final training dataset is union of target and regularization images. During fine-tuning we update the key and value projection matrices of the cross-attention blocks in the diffusion model with the standard diffusion training loss. All our experiments are based on Stable Diffusion.
We show results of our fine-tuning method on various category of new/personalized concept including scene, style, pet, personal toy, and objects. For more generations and comparison with concurrent methods please refer to our Gallery page.










Target Images
Moongate in snowy ice
Moongate at a beach with a view of seashore










Target Images (Credit: Mia Tang)
Painting of dog in the style of V* art
Plant painting in the style of V* art










Target Images
V* tortoise plushy sitting at the beach with a view of sea
V* tortoise plushy wearing sunglasses










Target Images (Credit: Aaron Hertzmann)
Painting of dog in the style of V* art
Plant painting in the style of V* art










Target Images
V* dog wearing sunglasses
A sleeping V* dog










Target Images
V* cat in times square
Painting of V* cat at a beach by artist claude monet










Target Images
V* table and an orange sofa
V* table with a vase of rose flowers on it










Target Images
V* chair near a pool
A watercolor painting of V* chair in a forest










Target Images
V* barn in fall season with leaves all around
Painting of V* barn in the style of van gogh










Target Images
A vase filled with V* flower on a table
V* flower with violet color petals










Target Images
V* teddybear in grand canyon
V* teddybear swimming in pool










Target Images
V* wooden pot with mountains and sunset in background
Rose flowers in V* wooden pot on a table
In multi-concept fine-tuning we show composition of scene or object with a pet, and composition of two objects. For more generations and comparison with concurrent methods please refer to our Gallery page.






Target Images
V2* chair with the V1* cat sitting on it near a beach
Watercolor painting of V1* cat sitting on V2* chair






Target Images
V2* dog wearing sunglasses in front of moongate
A digital illustration of the V2* dog in front of moongate






Target Images
The V1* cat is sitting inside a V2* wooden pot and looking up
The V1* cat sculpture in the style of a V2* wooden pot






Target Images
Photo of a V1* table and the V2* chair
Watercolor painting of a V1* table and a V2* chair






Target Images
V2* flower in the V1* wooden pot on a table
V2* flower engraving on the V1* wooden pot
Below image shows qualitative comparison of our method with DreamBooth and Textual Inversion on single-concept fine-tuning. DreamBooth fine-tunes all the parameters in the diffusion model, keeping the text transformer frozen, and uses generated images as the regularization dataset. Textual Inversion only optimizes a new word embedding token for each concept. Please see our Gallery page for more sample generations on the complete evaluation set of text-prompts.

Sample generations on multi-concept by our (joint) training method, ours optimization based method, and DreamBooth. For more samples on the complete evaluation set of text-prompts, please see our Gallery page.

We can further reduce the storage requirement for each fine-tuned model by saving the low-rank approximation of the difference between the pretrained model and fine-tuned model updated weights.
Sample generations with different level of compression. The storage requirements of models from left to right are 75MB, 15MB, 5MB, 1MB, 0.1MB, and 0.08MB (to save the optimized V*). Even with 5x compression with top 60% singular values, the performance remains similar.

Our method has still various limitations. Difficult compositions, e.g., a pet dog and a pet cat, remain challenging. In many case, the pre-trained model also faces a similar difficulty, and we believe that our model inherits these limitations. Additionally, composing increasing three or more concepts together is also challenging.
First column shows the sample target images used for fine-tuning the model with our joint training method. Second column shows the failed compositional generation by our method. Third column shows generations from the pretrained model with similar text prompt as input.

@inproceedings{kumari2022customdiffusion,
author = {Kumari, Nupur and Zhang, Bingliang and Zhang, Richard and Shechtman, Eli and Zhu, Jun-Yan},
title = {Multi-Concept Customization of Text-to-Image Diffusion},
booktitle = {CVPR},
year = {2023},
}
We are grateful to Nick Kolkin, David Bau, Sheng-Yu Wang, Gaurav Parmar, John Nack, and Sylvain Paris for their helpful comments and discussion, and to Allie Chang, Chen Wu, Sumith Kulal, Minguk Kang, Yotam Nitzan, and Taesung Park for proofreading the draft. We also thank Mia Tang and Aaron Hertzmann for sharing their artwork. Some of the datasets are downloaded from Unsplash. This work was partly done by Nupur Kumari during the Adobe internship. The work is partly supported by Adobe Inc. The website template is taken from DreamFusion project page.