
SuffixDecoding: Extreme Speculative Decoding for Emerging AI Applications
Snowflake recently unveiled ArcticInference , the fastest speculative decoding solution for vLLM currently available. ArcticInference can reduce the end-to-end latency for LLM agent tasks by up to 4.5 times and can improve open-ended chat completion workloads by as much as 2.8 times . A key breakthrough contributing to these performance enhancements is SuffixDecoding , a model-free speculation technique based on suffix trees, which I developed during my research internship at Snowflake. For more details, check out the Snowflake engineering blog post .
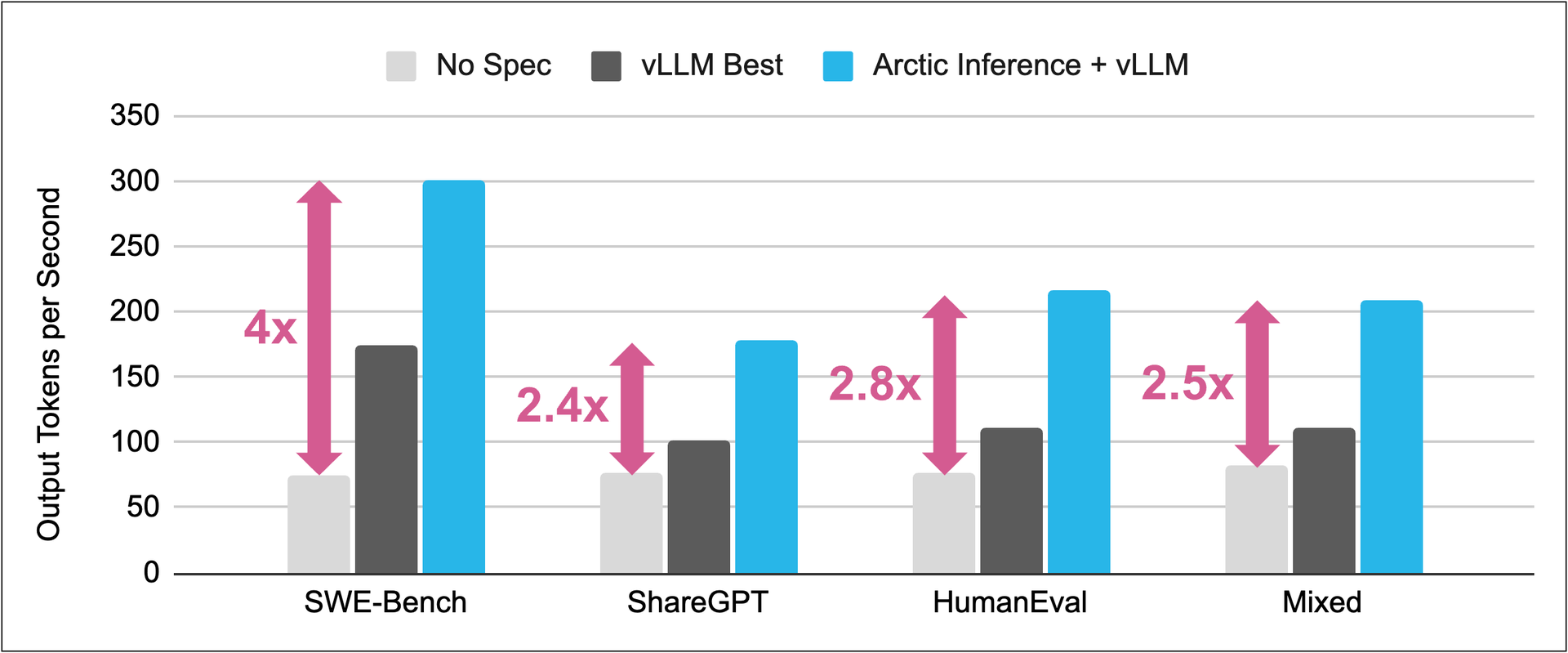 Figure 1 - Speedup of Llama-3.1-70B-Instruct by the ArcticInference Speculator on a 8xH100 GPU node. Illustration courtesy of Snowflake, Inc.
Figure 1 - Speedup of Llama-3.1-70B-Instruct by the ArcticInference Speculator on a 8xH100 GPU node. Illustration courtesy of Snowflake, Inc.
TL;DR
- What is it? SuffixDecoding is a model-free speculative decoding technique that accelerates LLM inference without requiring any auxiliary draft models or additional training.
- How does it work? It uses suffix trees —efficient data structures that index previously generated token sequences—to predict likely continuations. At each decoding step, SuffixDecoding matches recent output tokens against the suffix tree to find candidate sequences, then verifies them in a single LLM forward pass.
- Why does it matter? Traditional speculative decoding requires co-deploying draft models, which adds GPU memory pressure and operational complexity. SuffixDecoding eliminates this overhead by running entirely on CPU memory.
- Performance: Up to 2.8× faster than EAGLE-2/3 on agentic SQL tasks, 1.9× faster than Token Recycling, and 1.8–4.5× end-to-end speedup on SWE-Bench.
- Industry adoption: SuffixDecoding powers Snowflake’s ArcticInference, the fastest speculative decoding solution for agents in vLLM.
Introduction
Large language models (LLMs) are foundational to agentic AI applications—automated coding assistants, multi-agent workflows, and retrieval systems. Unlike basic chatbots, these workloads issue repetitive and predictable inference requests . Multi-agent systems repeatedly perform similar tasks, and reasoning loops regenerate similar token sequences. Despite this predictable repetition, existing methods fail to fully exploit recurring patterns, leaving latency as a bottleneck .
Speculative decoding is a popular strategy for mitigating inference latency. While an LLM can only generate one token per forward pass, it can verify multiple tokens. Speculative decoding methods use small “draft” models to predict multiple candidate tokens, which the LLM then verifies in parallel.
However, existing approaches fall short for agentic workloads. Model-based methods can use significant GPU time when speculating long sequences and incur memory contention. Existing model-free approaches like prompt-lookup decoding achieve low overhead but typically lack adaptivity—they speculate a fixed number of tokens regardless of acceptance likelihood.
SuffixDecoding addresses these limitations by using efficient suffix trees to cache long token sequences from prompts and previous outputs. Draft tokens are generated extremely quickly (~20 microseconds per token) without GPU overhead. At each inference step, SuffixDecoding adaptively limits its number of draft tokens based on the length of the pattern match, maximizing effectiveness on agentic workloads while avoiding computational waste.
How SuffixDecoding Works
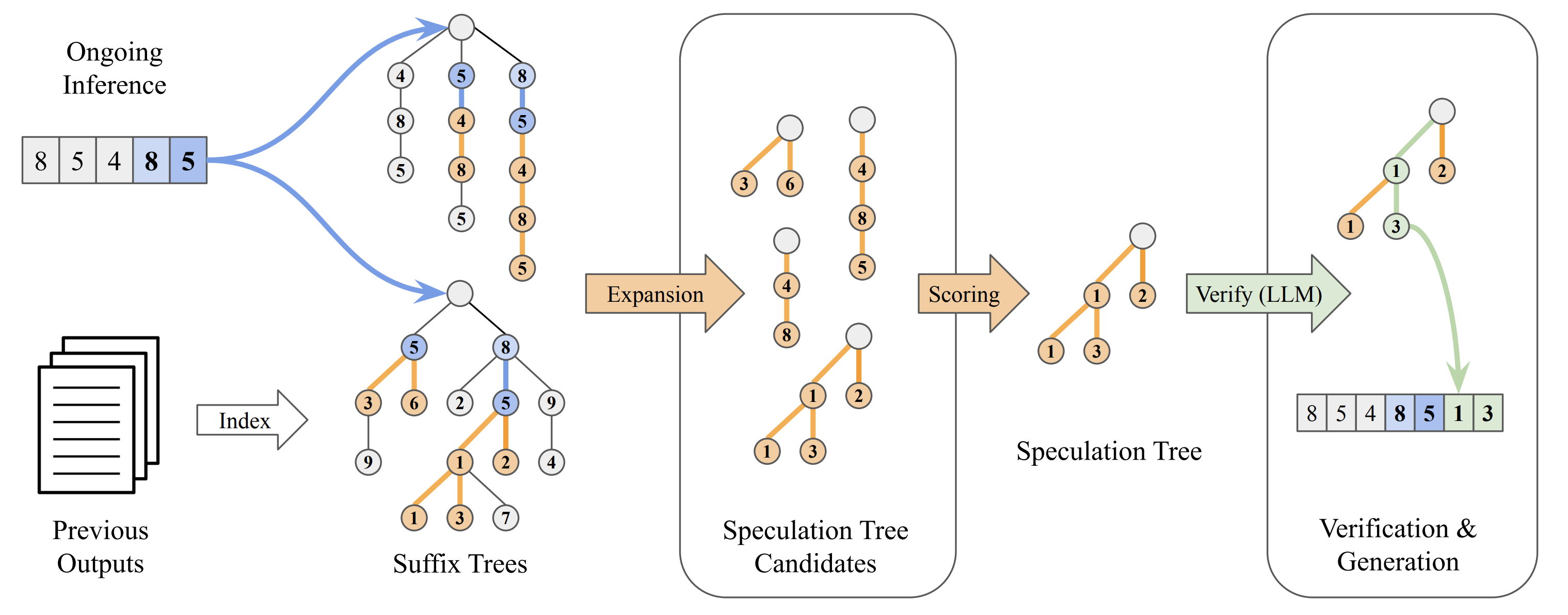 Figure 2 - Overview of SuffixDecoding’s algorithm. Two suffix trees track ongoing inference (top-left) and previous outputs (bottom-left). SuffixDecoding finds matching patterns based on recently generated tokens, constructs a speculation tree by selecting the most likely continuations, and verifies them in a single LLM forward pass.
Figure 2 - Overview of SuffixDecoding’s algorithm. Two suffix trees track ongoing inference (top-left) and previous outputs (bottom-left). SuffixDecoding finds matching patterns based on recently generated tokens, constructs a speculation tree by selecting the most likely continuations, and verifies them in a single LLM forward pass.
Suffix Tree Construction
SuffixDecoding maintains two suffix trees:
- A global suffix tree built from historical outputs (constructed offline or updated online)
- A per-request suffix tree built from the current prompt and partial generation
Each node represents a token, and paths encode previously observed subsequences. This enables rapid pattern matching to identify continuations based on prior occurrences. The trees are stored in CPU memory—AWS p5.48xlarge nodes have 2TB of RAM, easily enough to support millions of historical outputs.
Adaptive Speculation
Given a pattern sequence (the last p tokens), SuffixDecoding walks the suffix tree to find a node whose descending paths are possible continuations. It then builds a speculation tree by greedily expanding nodes with the highest estimated acceptance probability.
The key innovation is
adaptive speculation length
: SuffixDecoding sets
MAX_SPEC = αp
, where
p
is the pattern match length and
α
is a tunable factor. Longer pattern matches enable confident speculation of longer sequences, while shorter matches trigger conservative speculation to avoid wasted compute.
Hybrid Mode
SuffixDecoding can seamlessly integrate with model-based methods like EAGLE-3. The hybrid approach uses SuffixDecoding’s fast speculation whenever the confidence score exceeds a threshold, falling back to model-based speculation otherwise. This achieves the best of both worlds for mixed workloads.
Evaluation
We evaluated SuffixDecoding on both agentic and non-agentic workloads using Spec-Bench, comparing against EAGLE-2/3, Prompt-Lookup Decoding (PLD), and Token Recycling.
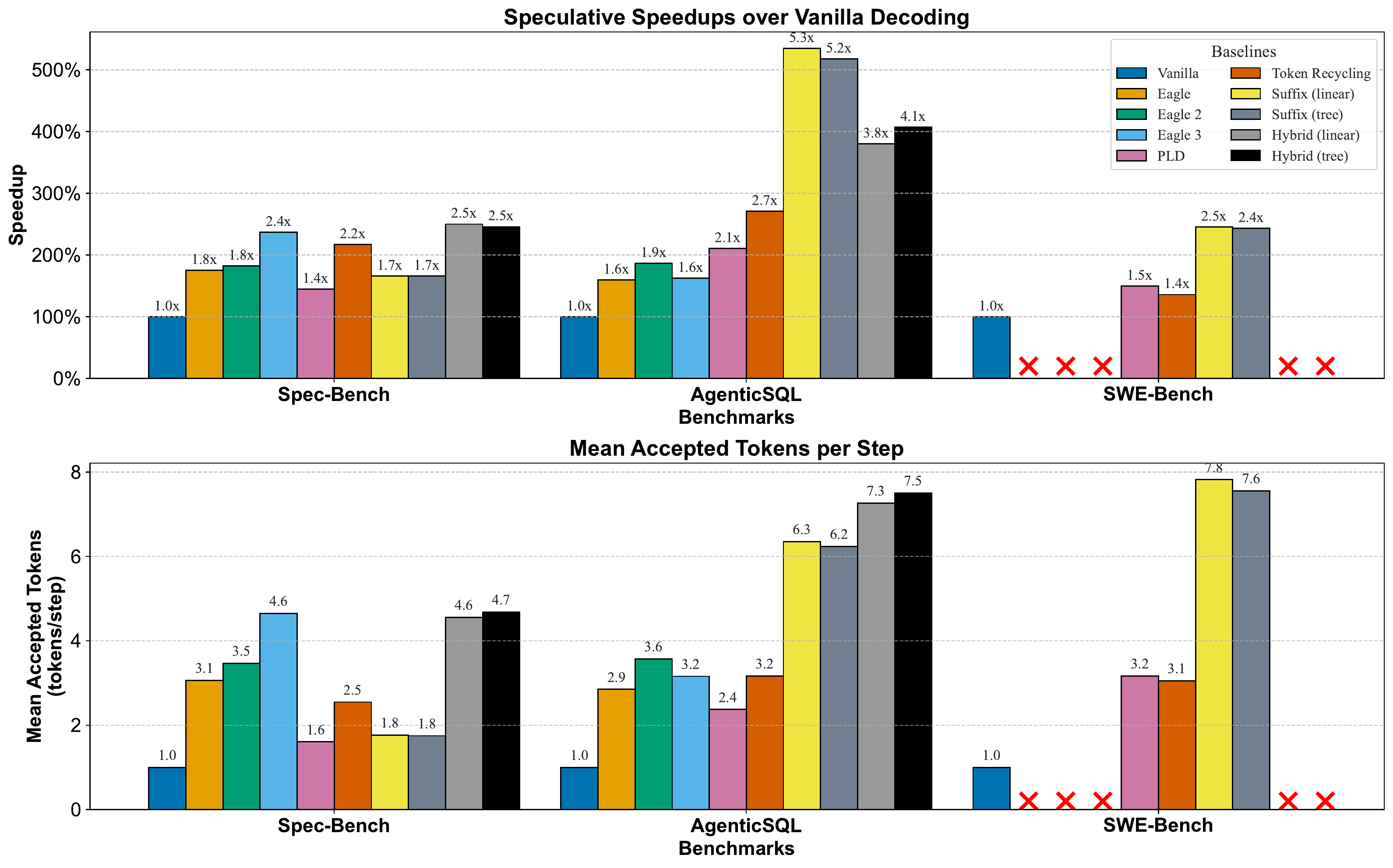 Figure 3 - Speculative speedups (top) and mean accepted tokens per step (bottom) compared to vanilla decoding. Experiments use Llama-3.1-8B-Instruct on a single H100 GPU. The hybrid variants combine SuffixDecoding with EAGLE-3, dynamically selecting between suffix-based and model-based speculation.
Figure 3 - Speculative speedups (top) and mean accepted tokens per step (bottom) compared to vanilla decoding. Experiments use Llama-3.1-8B-Instruct on a single H100 GPU. The hybrid variants combine SuffixDecoding with EAGLE-3, dynamically selecting between suffix-based and model-based speculation.
Agentic Workloads
AgenticSQL (multi-agent SQL generation): SuffixDecoding achieves a mean 5.3× speedup over vanilla decoding— 2.8× faster than EAGLE-2/3 and 1.9× faster than Token Recycling . It reaches 6.3 mean accepted tokens per step, substantially higher than EAGLE-3 (3.6) and Token Recycling (3.2).
SWE-Bench (GitHub issue resolution): SuffixDecoding achieves a mean 2.5× speedup over vanilla decoding, 1.7× faster than PLD . Notably, EAGLE-2/3 fail on several SWE-Bench tasks due to context length limitations (>8192 tokens).
End-to-End SWE-Bench on vLLM
We integrated SuffixDecoding into vLLM and ran OpenHands live on SWE-Bench Verified. SuffixDecoding outperforms PLD by 1.3–3× , achieving 1.8–4.5× speculative speedup over vanilla decoding. Since SuffixDecoding exactly preserves the output distribution, it matches the original model’s 37.2% score on SWE-Bench Verified.
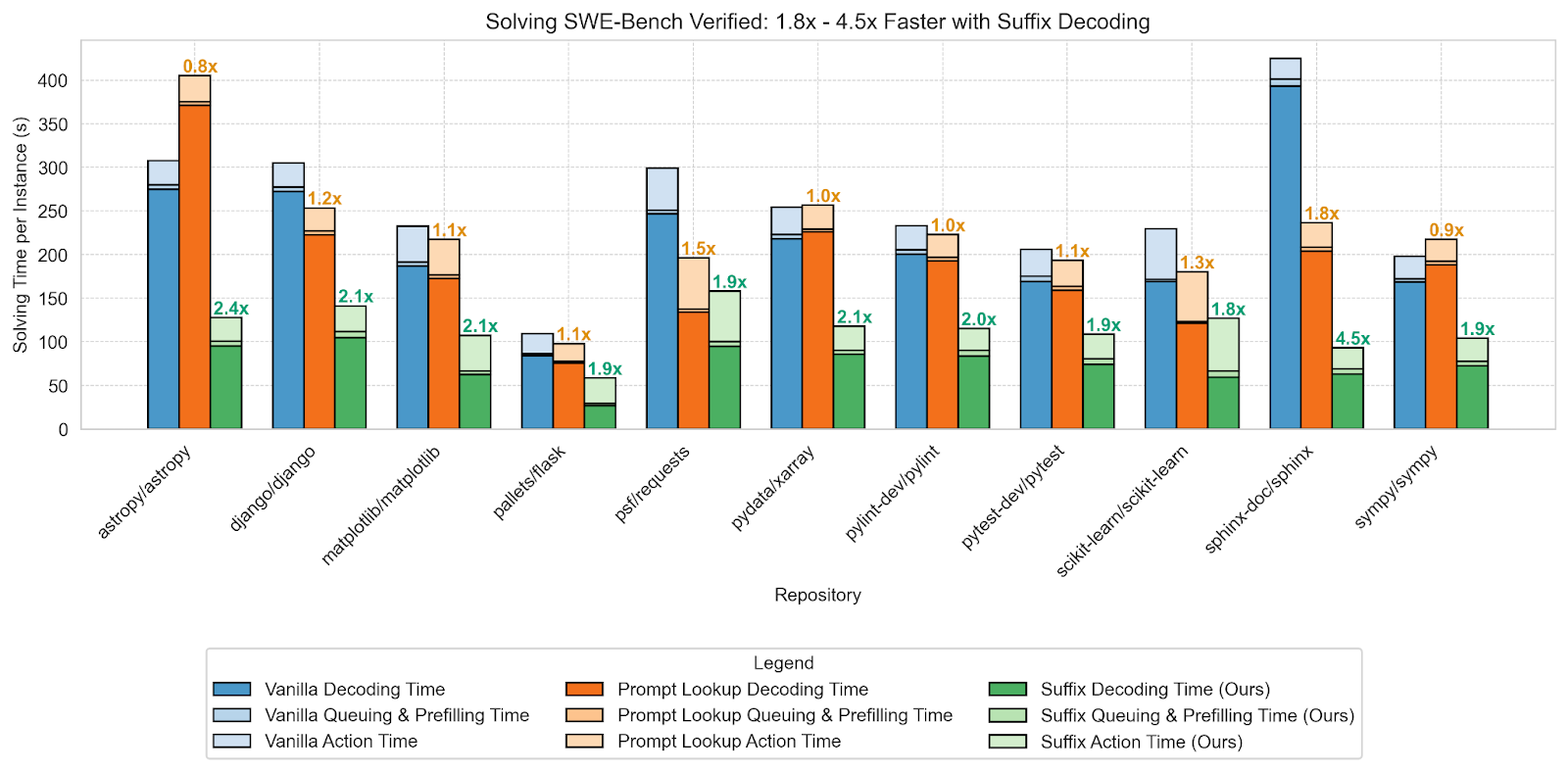 Figure 4 - End-to-end task-completion time of the OpenHands agent on SWE-Bench Verified.
Figure 4 - End-to-end task-completion time of the OpenHands agent on SWE-Bench Verified.
Non-Agentic Workloads
On Spec-Bench (open-ended single-turn tasks), SuffixDecoding alone is outperformed by EAGLE-2/3, as expected for less repetitive scenarios. However, the hybrid approach (SuffixDecoding + EAGLE-3) achieves 2.5× speedup —better than standalone EAGLE-3 (2.4×) or Token Recycling (2.2×).
Key Insights
Why SuffixDecoding Excels at Agentic Tasks
Examining speculation trees reveals the source of SuffixDecoding’s advantage. For structured generation tasks like AgenticSQL’s Extract step, outputs share common characteristics: JSON documents with the same format, keys appearing in similar order, and discrete boolean values. SuffixDecoding’s global suffix tree captures these patterns, enabling speculation trees that branch at each boolean value and advance generation by dozens of tokens in one step.
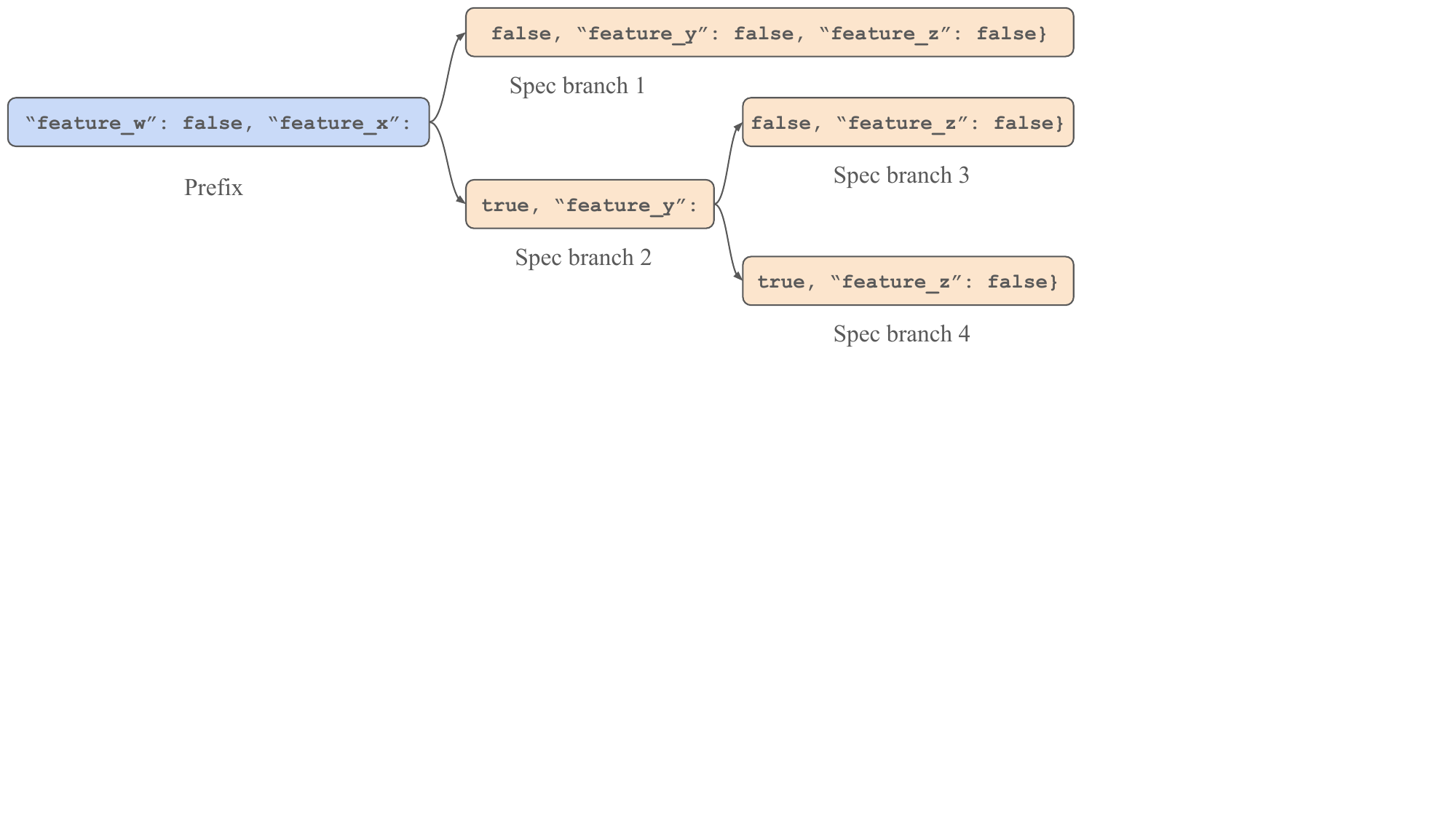 Figure 5 - A SuffixDecoding speculation tree containing 66 tokens for the AgenticSQL Extract task. The tree branches at boolean true/false values, allowing the LLM to verify many possible continuations in a single forward pass.
Figure 5 - A SuffixDecoding speculation tree containing 66 tokens for the AgenticSQL Extract task. The tree branches at boolean true/false values, allowing the LLM to verify many possible continuations in a single forward pass.
Global vs Per-Request Trees
Both trees contribute to performance. The global tree excels at capturing cross-request patterns, while the per-request tree captures prompt reuse (e.g., the Combine step in AgenticSQL heavily reuses SQL solutions from previous steps). Using both trees together achieves the best results.
Scalability
Speedup consistently improves as suffix tree size grows—from 256 to 10,000 examples. Acceptance rate remains stable even as tree size varies across two orders of magnitude, thanks to the adaptive speculation length that adjusts to pattern match confidence.
Conclusion
SuffixDecoding demonstrates that model-free speculative decoding is not only possible but superior to state-of-the-art model-based methods for agentic workloads. By leveraging suffix trees to exploit repetitive patterns in LLM outputs, it achieves:
- 2.8× faster than EAGLE-2/3 on agentic SQL tasks
- Up to 4.5× end-to-end speedup on SWE-Bench
- Zero GPU overhead —all speculation runs on CPU
- Seamless hybrid integration with model-based methods for mixed workloads
SuffixDecoding is now available in vLLM as part of Snowflake’s ArcticInference. For more details, see our NeurIPS 2025 paper and the Snowflake engineering blog .
References
- Cai, T. et al. (2024). Medusa: Simple LLM Inference Acceleration Framework with Multiple Decoding Heads.
- Chowdhury, N. et al. (2024). Introducing SWE-bench Verified.
- Forero, J. et al. (2024). Cortex Analyst: Paving the Way to Self-Service Analytics with AI.
- Fu, Y. et al. (2024). Break the Sequential Dependency of LLM Inference Using Lookahead Decoding.
- Jimenez, C. et al. (2023). SWE-bench: Can Language Models Resolve Real-World GitHub Issues?
- Li, Y. et al. (2024). EAGLE-2: Faster Inference of Language Models with Dynamic Draft Trees.
- Li, Y. et al. (2025). EAGLE-3: Scaling up Inference Acceleration of Large Language Models via Training-Time Test.
- Luo, X. et al. (2024). Turning Trash into Treasure: Accelerating Inference of Large Language Models with Token Recycling.
- Miao, X. et al. (2024). SpecInfer: Accelerating Generative Large Language Model Serving with Tree-based Speculative Inference and Verification.
- Oliaro, G. et al. (2024). SuffixDecoding: A Model-Free Approach to Speeding Up Large Language Model Inference.
- Saxena, A. (2024). Prompt Lookup Decoding.
- Sun, Z. et al. (2023). SpecTr: Fast Speculative Decoding via Optimal Transport.
- Wang, X. et al. (2024). Executable Code Actions Elicit Better LLM Agents.
- Wang, Y. et al. (2025). Fastest Speculative Decoding in vLLM with Arctic Inference and Arctic Training.
- Zhao, Y. et al. (2024). Lookahead: An Inference Acceleration Framework for Large Language Model with Lossless Generation Accuracy.
