
Holon Approach to Holistic Database Optimization
Background
Since the development of the first database management systems (DBMSs) over five decades ago, DBMSs have become the foundation of modern data-intensive applications. However, deploying and maintaining a DBMS for these applications is more challenging now than ever. Such applications have more complex workloads (e.g., types of queries, data access patterns) than their predecessors, along with more sophisticated business requirements over disparate objectives (e.g., query latency, ingestion time, storage costs, data freshness). Consequently, with each new version, DBMS vendors expose additional opportunities for end-users to exert fine-grained control over how the DBMS executes their workloads.
Database Tuning
Database tuning is how database administrators (DBAs) optimize a DBMS to meet a specific application’s workload requirements. They perform this by reasoning across the numerous aspects of the DBMS and how these aspects interact with each other and the workload. These aspects include system-wide knobs that control fundamental behavior (e.g., parallelism, memory allocation), physical data layout (e.g., data placement, indexes, partitioning), and query-specific suggestions (e.g., how the DBMS should access specific tables or optimize the query), amongst others. Reasoning over this complex landscape is further exacerbated by the fact that different tunable aspects may interact subtly and unpredictably. In addition, the DBMS’s optimal configuration is not static but changes over time as the workload, data, software, and hardware evolve, necessitating continuous re-optimization.
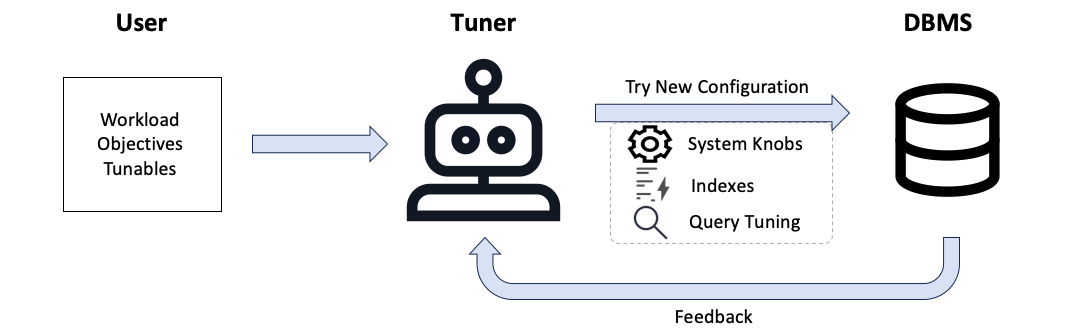
Figure 1, Automated Tuning Pipeline: Illustrates the automated tuning pipeline. A user (e.g., DBA) provides high-level instructions to the tuner (e.g., the workload's SQL queries, aspects of the DBMS to optimize, and the optimization goals). The tuner then repeatedly tries new configurations and receives feedback from the DBMS.
Due to the limits of manual tuning by DBAs, academic researchers and industry practitioners have investigated automated machine learning (ML)-based tuning techniques . These ML tuners receive several inputs from the user: a workload (e.g., list of SQL queries), an objective function (e.g., minimize total workload runtime, maximize transactions per second), and the aspects of the DBMS that the tuner should focus on (e.g., list of indexes, system-wide knobs). These tuners then systematically and methodically explore the landscape of possible configurations. They iteratively deploy suggested configurations, evaluate the workload, and use observed feedback (e.g., query runtimes, system telemetry) to refine future suggestions. This tuning loop happens within a constrained offline environment to mitigate any impact on production systems, as tuners may deploy suboptimal configurations or violate SLA constraints. This iterative process continues until the end of tuning.
Challenges with Automated Holistic Tuning
The multi-dimensional nature of database configurations creates a fundamental challenge for automated holistic optimization. Let us first consider the most intuitive and direct approach: combine all configurable aspects (e.g., system knobs and their valid values, index sets, suggestions for each query of the workload) into a complete (i.e., holistic ) search space of DBMS configurations.

Figure 2, Direct Tuning: Illustrates the direct method of tuning a DBMS across its configurable aspects. The direct method combines each tunable (e.g., buffer pool, indexes, Query 1 of the workload) and each tunable's valid value set (e.g., {1GB, 2GB...} for the buffer pool). Due to the resulting explosion in dimensionality and complexity, tuners struggle to find beneficial configurations.
However, this search space grows combinatorially with each addition, reaching billions to trillions of possible configurations . A further complication is that promising configurations are sparsely scattered throughout. As a result, automated tuners struggle to navigate this space efficiently, often spending excessive time evaluating suboptimal configurations without consistently finding high-quality solutions.
Problem 1: Although possible, combining all configurable aspects of the DBMS results in a high-dimensional space with promising configurations sparsely scattered throughout. This high-dimensional and sparse space is challenging for automated tuners to reason about and explore.
To mitigate the previous problem, the database community has focused on bespoke tuners. These bespoke tuners are highly specialized optimization tools for specific aspects of the DBMS rather than holistically addressing all aspects. For example, PGTune focuses exclusively on tuning system-wide knobs, and Dexter focuses only on index selection. However, their benefit is limited. Figure 3 illustrates the performance of the analytical benchmark Join Order Benchmark ( JOB ) on PostgreSQL 15 after running different tuners for 30 hours. While these bespoke tuners result in improvements, their narrow scope limits their efficacy.
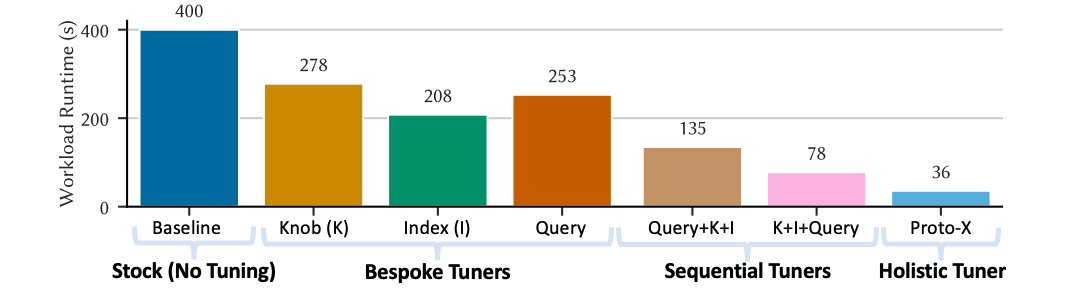
Figure 3, Comparisons of Tuners: Illustrates the JOB workload runtime on PostgreSQL 15 of the best configurations discovered by each tuner. Each bar shows the mean of four 30-hour tuning runs.
Due to the challenge of directly reasoning about all possible configurations (i.e., Problem 1 ), recent work and DBAs have turned to sequential tuning . Assuming an existing pool of bespoke tuners that target disjoint system aspects, sequential tuning finds the best schedule to run the pool’s tuners (e.g., round-robin, select tuner with the highest future benefit) while incrementally combining each tuner’s local optima to obtain a final holistic configuration. Although sequential tuning leads to improvements over singular bespoke tuners, Figure 3 also illustrates a core problem: the order of tuners matters. In this case, tuning queries after selecting indexes (K+I+Query) leads to better configurations than tuning queries first (Query+K+I). Selecting indexes first exposes additional opportunities for query tuning.
This observation is inherently a coordination problem . Each bespoke tuner in the pool operates and optimizes its target DBMS aspect in isolation. Consequently, individual tuners may make locally optimal decisions that may be globally suboptimal when considering the entire system. Figure 4 presents a concrete example of an index and query tuners attempting to optimize Query 26c from the Join Order Benchmark.
 Figure 4, Coordination Challenge:
A grid of the index (X-axis) and query tuning (Y-axis) optimization space for Query 26c from
the Join Order Benchmark. Each grid cell shows the performance of the query under a given
configuration. The top left corner (Hint-0, Index-0) represents the initial configuration of the
DBMS, while the bottom right corner (Hint-1, Index-1) represents the optimal configuration.
Figure 4, Coordination Challenge:
A grid of the index (X-axis) and query tuning (Y-axis) optimization space for Query 26c from
the Join Order Benchmark. Each grid cell shows the performance of the query under a given
configuration. The top left corner (Hint-0, Index-0) represents the initial configuration of the
DBMS, while the bottom right corner (Hint-1, Index-1) represents the optimal configuration.
Given that the DBMS’s initial configuration is in the top left corner, no sequential interleaving of the tuners will discover the optimal configuration. Neither the index nor query tuner will make a suboptimal decision (e.g., move to a square that degrades the query’s performance), even though it may enable a future tuning round to find the optimal configuration. Despite the existence of a globally optimal configuration (Hint-1, Index-1) that achieves 1.0s runtime, sequential tuning becomes trapped in a local optimum ( 1.7s ) at the start (Hint-0, Index-0).
Problem 2: Sequential tuning attempts to mitigate Problem 1 (dimensionality explosion) by interleaving and composing multiple bespoke tuners. However, as bespoke tuners optimize their specific aspect of the DBMS in isolation, they struggle to coordinate and fail to discover high-performing configurations.
Holistic Tuning Intuition
Solving the prior two problems results in a holistic tuner. A holistic tuner reasons across the entire space of configurations rather than just a single aspect (as done by bespoke tuners) or in a piecemeal fashion (as done by sequential tuning). Figure 3 shows that this is possible. The missing piece to realize a holistic tuner is a technique that makes the space of configurations or, more specifically, tuning actions tractable.
Tuning Actions and Holons
Tuning Actions are the concrete operations by which tuners alter the DBMS’s deployment. Tuners obtain these actions through three mechanisms. The first is input from the database administrator (e.g., a list of pre-determined indexes to consider). The second is by querying the DBMS to identify actions (e.g., query PostgreSQL’s pg_settings to identify valid system knobs and their values). The last method is through static workload analysis. For example, index tuners analyze the workload and only consider indexes that use referenced columns.
 Figure 5, Holon:
Illustrates an example holon that contains three distinct tuning actions:
K
changes the buffer pool size,
Q
alters the execution of Query 1 of the workload,
and
I
specifies an index to build.
Figure 5, Holon:
Illustrates an example holon that contains three distinct tuning actions:
K
changes the buffer pool size,
Q
alters the execution of Query 1 of the workload,
and
I
specifies an index to build.
A tuning action is a single atomic unit describing a specific DBMS change. A higher-level abstraction is a holon . Conceptually a container of instructions, a holon encapsulates multiple actions from different system aspects as a unified unit. Figure 5 illustrates a holon composed of several tuning actions: K alters the system’s buffer pool, Q alters the execution of Query 1 of the workload, and I specifies an index to build. A holistic tuner uses this holon abstraction to reason across and understand the interdependencies between all configurable aspects of the DBMS.
Similarity-Centric Structure
Recall that the holistic space (i.e., combining all tunable actions) explodes in dimensionality with additional aspects. However, many holons within this vast space perform similarly under a given workload. For example, setting the buffer pool to 32GB versus 33GB typically yields comparable performance outcomes. Similarly, creating an index on column [a] versus columns [a, b] often produces similar performance impacts for many queries. This insight underlies a core observation:
We can infer an un-explored holon’s impact on the workload from the impacts of similar holons.
With this insight, a holistic tuner no longer needs to potentially try every holon without prior knowledge. Instead, after a tuner observes how a specific holon impacts the workload, the tuner can prioritize or eliminate similar holons without needing to evaluate the workload. There are two measures to identify similarity between holons: performance and structural .
-
Performance Similarity evaluates whether two holons exhibit comparable workload performance when deployed on the DBMS. While theoretically robust, this approach becomes impractical at scale due to the extensive evaluations required. In practice, performance similarity relies on proxy metrics such as optimizer costs or through cheaper machine learning models .
-
Structural Similarity is an alternative approach based on domain knowledge rules that define similarity based on characteristics. These rules can be derived from developer expertise, knowledge bases, or analysis of system telemetry data. For example, a structural rule treats knob values within a certain numerical threshold as similar (e.g., place buffer pool size of 32GB and 33GB into the same bucket) or considers indexes with shared key prefixes as related (e.g., index on column [a] versus columns [a, b]). These rules encode human understanding of how different actions impact the DBMS’s behavior.
Similar to how language models embed text, a holistic tuner infuses these similarity measures into the space by altering the representations of holons such that similar holons have similar (or nearby) representations. By leveraging both similarity measures, a holistic tuner can coarsely cover the space with fewer performance samples and expand points in the space on demand with structural similarity into a larger approximate neighborhood of similar holons.
Creating the Holistic Tuner Proto-X
The holistic tuner prototype Proto-X involves a two-phase process. Following existing tuner deployments, Proto-X is provided a workload (e.g., SQL queries) to tune in an offline environment.
 Figure 6, Architecture Phase I:
Overview of Phase I of Proto-X's architecture. Using samples of holons and their performance impacts
from the DBMS, Proto-X builds a representation model for holons and their similarities.
Figure 6, Architecture Phase I:
Overview of Phase I of Proto-X's architecture. Using samples of holons and their performance impacts
from the DBMS, Proto-X builds a representation model for holons and their similarities.
In Phase I (see Figure 6), Proto-X builds a model to represent holons and capture their similarities. Proto-X repeatedly samples holons, obtains their performance impacts (e.g., from real evaluations, from optimizer costs), and assigns representations (i.e., embeddings) such that similar holons have nearby representations. By doing this, Proto-X creates neighborhoods in the holon space. Even though each neighborhood contains distinct holons, the holons within a neighborhood have similar structural characteristics or performance outcomes. This structure allows Proto-X to generalize over neighborhoods rather than individual holons.
 Figure 7, Architecture Phase II:
Overview of Phase II of Proto-X's architecture. With its representation model from Phase I, Proto-X
then applies standard reinforcement learning techniques to tune the DBMS. Proto-X repeatedly
observes the DBMS, suggests a candidate holon, deploys it, and updates its models with feedback.
Figure 7, Architecture Phase II:
Overview of Phase II of Proto-X's architecture. With its representation model from Phase I, Proto-X
then applies standard reinforcement learning techniques to tune the DBMS. Proto-X repeatedly
observes the DBMS, suggests a candidate holon, deploys it, and updates its models with feedback.
In Phase II (see Figure 7), Proto-X then uses classical reinforcement learning to tune the DBMS. Proto-X repeatedly (1) observes the current DBMS, (2) thinks of a holon to deploy, and (3) evaluates the holon to obtain feedback from the DBMS to refine itself for future steps. Each step of the loop is expanded on below:
(1) Observe : At the start, Proto-X obtains a representation of the current DBMS. Proto-X uses the DBMS’s collected telemetry (e.g., performance counters) from running the user’s workload to represent the current DBMS’s state.
(2) Think : With the DBMS’s state representation, Proto-X first uses its actor model (e.g., neural network) to suggest a point (see X in Figure 7). With its representation model from Phase I, Proto-X can translate these points into deployable holons on the DBMS. Proto-X then constructs an approximate neighborhood through curated rules (leveraging structural similarity) or by sampling points around X (leveraging performance similarity). Last, Proto-X uses its critic (e.g., neural network) to select the best point in this neighborhood and translates it into a holon.
(3) Evaluate : Proto-X then deploys the candidate holon on the DBMS. Proto-X then evaluates the user’s workload to obtain feedback (e.g., the holon’s effectiveness). Proto-X uses this feedback to refine its actor and critic models before moving to the next step.
Experiment with Tuning PostgreSQL
We performed our evaluation on a machine with a dual-socket 20-core Intel Xeon Gold 5218R CPU (20 cores per CPU, 2× HT), 192 GB DDR4 RAM, and a 960 GB NVMe SSD. For illustrative purposes, we use the analytical Decision Support Benchmark from Microsoft. A given instantiation contains 49 queries with complex data distributions, join patterns, and skew.
Competing Tuners
We evaluate against four other state of the art composed tuners:
-
PGTune+Dexter builds upon standard and widely deployed tools. This tuner first invokes its heuristic knob tuner ( PGTune ), followed by its cost-based index tuner ( Dexter ).
-
PGTune+DTA+AS combines the previous heuristics knob tuner ( PGTune ) with a state of the art cost-based index tuner based on Microsoft’s Anytime Database Tuning Advisor ( DTA ) and a state of the art query tuner ( Auto-Steer from TU Munich ). We use the Hyrise index evaluation platform’s implementation of DTA from Hasso Plattner Institute.
-
UDO : (from Cornell) tunes the system knobs and indexes in a hierarchically based on whether an action is expensive (e.g., build an index) or lightweight (e.g., change a knob).
-
UniTune (from PKU) is a sequential tuning framework that selects the next tuner based on estimated future benefits. In the default form, it tunes knobs, single-column indexes, and query rewriting. We also run a variation UniTune+Q , which we augment to consider the same query tuning that Proto-X supports.
Tuning Dimensionality
With the technique described previously, the current prototype Proto-X supports tuning the following aspects of PostgreSQL:
-
Knobs : Proto-X tunes knobs at different granularities of the DBMS. It tunes system-wide knobs (e.g., memory, parallel workers), per-table knobs (e.g., how packed each data page is), and per-index knobs (e.g., how packed each index page is).
-
Indexes : Proto-X suggests indexes of arbitrary width (e.g., number of key columns), the index type (e.g., B-tree index, hash index), and also additional non-key columns (i.e., INCLUDE columns ). Furthermore, Proto-X does not rely on the user’s pre-determined list of indexes.
-
Query Tuning : Proto-X supports tuning at the granularity of individual queries in the workload. For each query, Proto-X tunes query knobs (e.g., optimizer knobs), access methods for each table in the query (e.g., table scan or index scan), and whether to materialize or inline common table expressions (i.e., named result set referenced by the main query).
| Tuner | # Knobs | # Indexes | # Query Tuning Hints |
|---|---|---|---|
| PGTune+DTA+AS | \(15\) | \( 542\) | \(588\) |
| UDO | \(24\) | \(4561\) | N/A |
| UniTune | \(61\) | \( 263\) | N/A |
| Proto-X | \(45\) | \(2^{47}\) | \(1043\) |
Table 1, Configuration Space Size: The number of choices considered by each evaluated tuner for the three major DBMS aspects (knobs, indexes, query tuning). "N/A" indicates that the given tuner does not support those aspects.
Table 1 illustrates the dimensionality of these tunable aspects considered by a holistic tuner against other state of the art tuners. By achieving a dimensionality breakthrough, the holistic approach Proto-X considers orders of magnitude more tunable aspects in quantity and variety than other tuners.
Evaluation
We allow each tuner 30 hours to tune from the stock deployment of PostgreSQL v15 for a given DSB instantiation. As tuners employ different evaluation strategies during tuning (e.g., timing out configurations that are known to be suboptimal), we re-evaluate each discovered configuration: we re-deploy each configuration, empty the page cache, run the workload three times, and report the minimum as the workload runtime for the configuration. We run each tuner four times to account for variation within each tuner and average their results. Figure 8 tracks the mean workload runtime over time, with the bands indicating the best and worst runtime over the four samples.
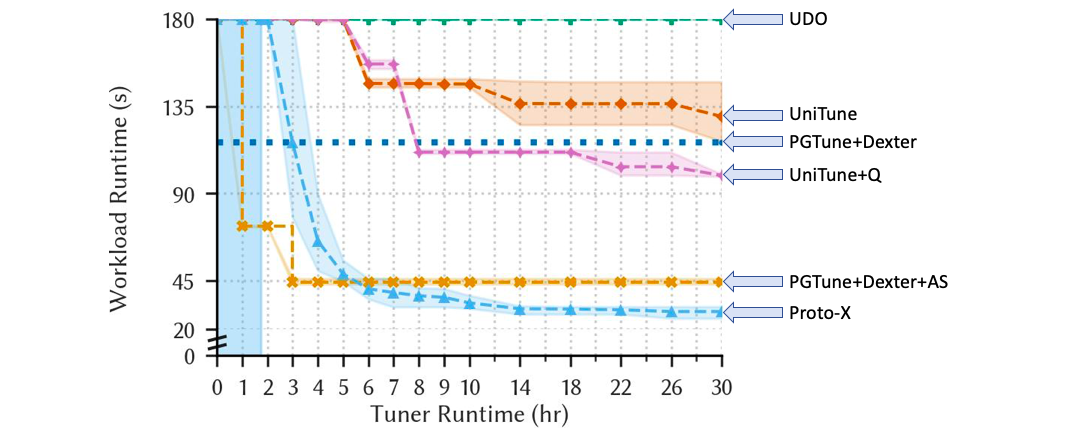
Figure 8, Decision Support Benchmark Experiment: The DBMS's performance achieved using each tuner's best configurations over time. We plot the mean performance obtained by four tuner runs, with the band indicating the best and worst over the four runs. The shaded region for Proto-X is the time spent in Phase I.
Upon closer inspection, Proto-X invests the first two hours in Phase I. It quickly establishes an effective foundation of system knobs and indexes in the initial hours, then incrementally refines the configuration over time. Proto-X ultimately discovers configurations that are more performant than those found by PGTune+Dexter (75%), PGTune+DTA+AS (34%), UDO (>84%), UniTune (77%) and UniTune+Q (71%). Proto-X does this by considering orders of magnitude more tunable aspects, managing the resulting complexity, and reasoning about their interactions with the workload and DBMS.
Conclusion
Optimizing a DBMS for a workload through tuning is a decades-old problem. Recent work has focused on building isolated bespoke tuners for individual DBMS aspects (e.g., knob tuning, index selection) and strategies to coordinate these tuners across aspects. However, these prior attempts have fallen short due to challenges in the tuning space’s dimensionality and in coordinating tuners. We introduce a holistic tuner Proto-X that exploits performance-based and structural-based similarities between tuning actions (or holons). By doing so, Proto-X manages the dimensionality explosion arising from considering orders of magnitude (variety and quantity) more aspects and discovers more performant configurations than existing state of the art tuners.
Based on a paper recently published at VLDB 2024 .