On Aliased Resizing and Surprising Subtleties in GAN Evaluation
Gaurav Parmar1 Richard Zhang2 Jun-Yan Zhu1
1 Carnegie Mellon University 2 Adobe Research
Paper | GitHub | Leaderboard | Slides
Abstract
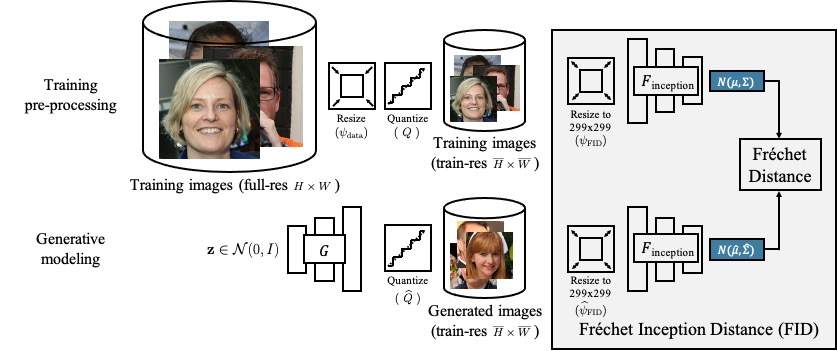
Metrics for evaluating generative models aim to measure the discrepancy between real and generated images. The often-used Frechet Inception Distance (FID) metric, for example, extracts “high-level” features using a deep network from the two sets. However, we find that the differences in “low-level” preprocessing, specifically image resizing and compression, can induce large variations and have unforeseen consequences. For instance, when resizing an image, e.g., with a bilinear or bicubic kernel, signal processing principles mandate adjusting prefilter width depending on the downsampling factor, to antialias to the appropriate bandwidth. However, commonly-used implementations use a fixed-width prefilter, resulting in aliasing artifacts. Such aliasing leads to corruptions in the feature extraction downstream. Next, lossy compression, such as JPEG, is commonly used to reduce the file size of an image. Although designed to minimally degrade the perceptual quality of an image, the operation also produces variations downstream. Furthermore, we show that if compression is used on real training images, FID can actually improve if the generated images are also subsequently compressed. This paper shows that choices in low-level image processing have been an underappreciated aspect of generative modeling. We identify and characterize variations in generative modeling development pipelines, provide recommendations based on signal processing principles, and release a reference implementation to facilitate future comparisons
Leaderboard For Common Tasks
We compute the FID scores using the corresponding methods used in the original papers and using the Clean-FID proposed here. All values are computed using 10 evaluation runs. We also provide an API to query the results directly from the pip package. The arguments model_name, dataset_name, dataset_res, dataset_split, task_name can be used to filter the results.

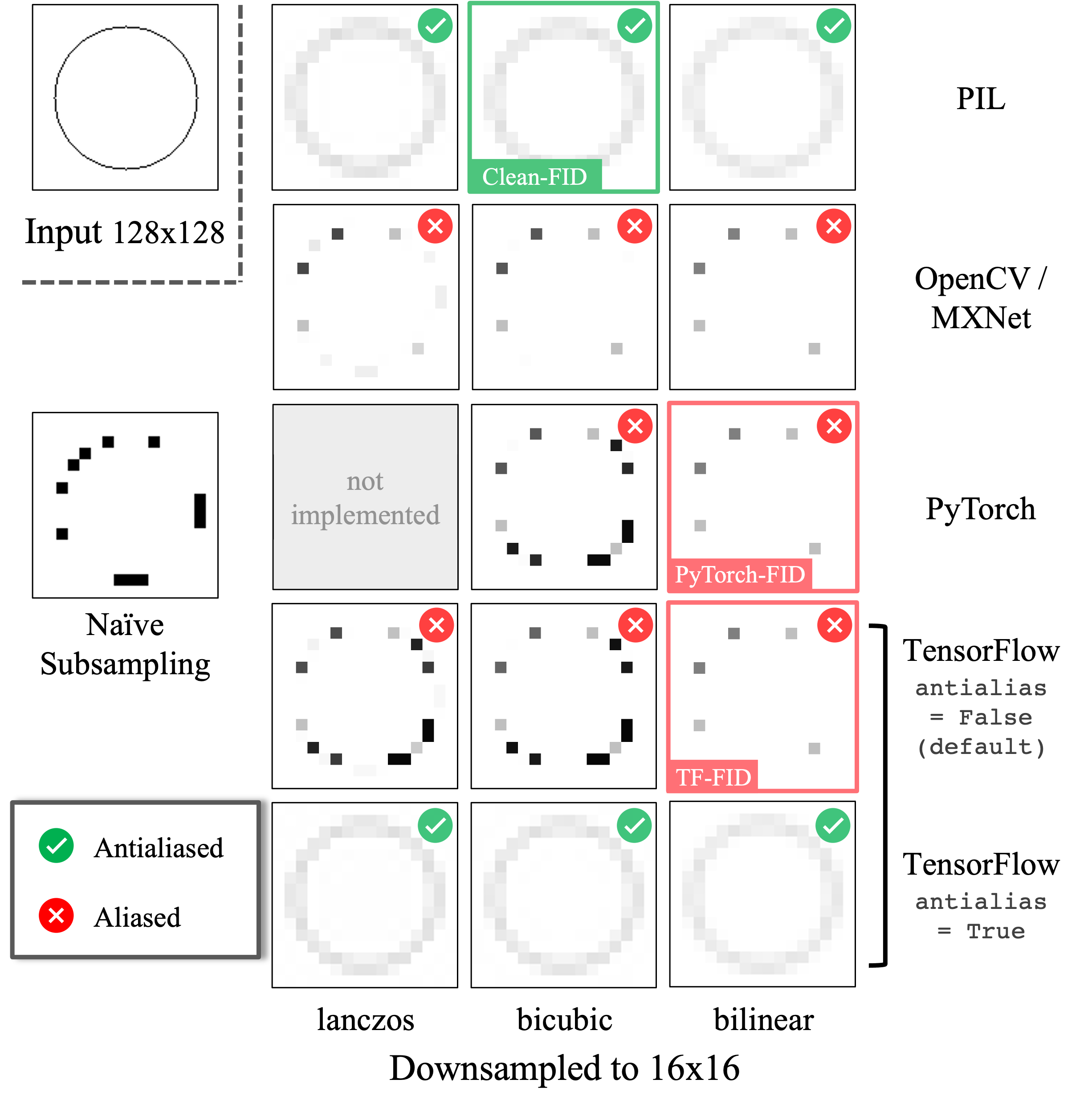
Aliased Resizing in commonly-used libraries
|
We resize an input image (left) by a factor of 8, using different image processing libraries. The Lanczos, bicubic, and bilinear implementations by PIL (top row) adjust the antialiasing filter width by the downsampling factor (marked as ). Other implementations (including those used for PyTorch-FID and TensorFlow-FID) use fixed filter widths, introducing aliasing artifacts and resemble naive nearest subsampling. Aliasing artifacts induce inconsistencies in the calculation of downstream metrics such as FID, KID, IS, and PPL. Note that antialias flag is available in TensorFlow 2, but is set to False (default value) for the FID calculation. |
|
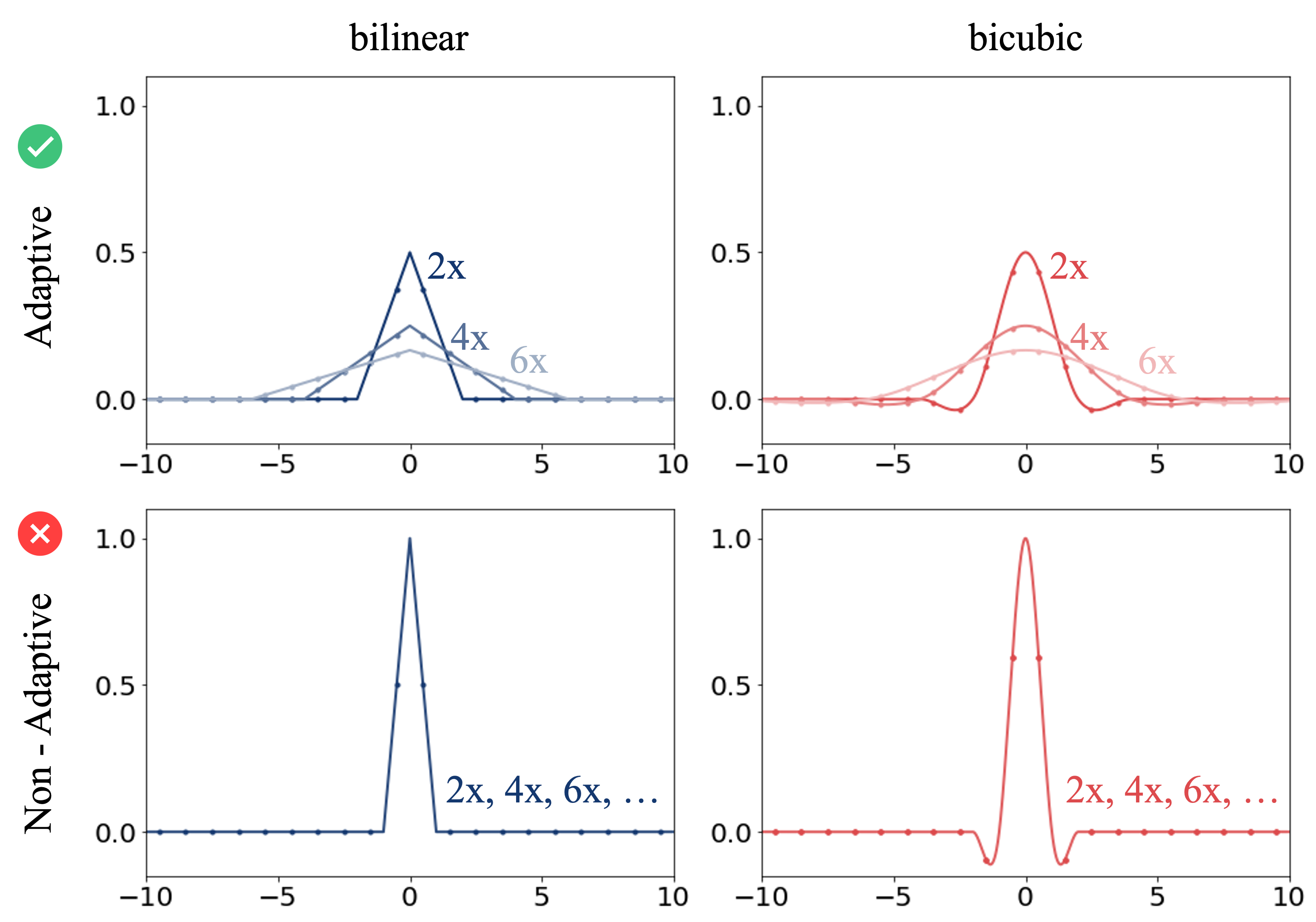
The interpolation filters used by the commonly used libraries are either adaptive (PIL) or non-adaptive (PyTorch, TensorFlow). The existing FID implementations use the fixed-width bilinear interpolation which is independant of the resizing ratio. In contrast, Clean-FID follows standard signal processing principles and adaptively stretches filter to prevent aliasing. |
|
Effects of JPEG compression on FID
|
We show a sample image from the FFHQ dataset, saved with lossless PNG and different JPEG compression ratios. The FID scores under the images are calculated between FFHQ images saved using the corresponding JPEG format and the PNG format. PSNR is computed with 1000 images. While the images are perceptually similar, this induces changes in the Inception-V3 activations, resulting in large FID scores. |

|
|
Below, we study the effect of JPEG compression for StyleGAN2 models trained on the FFHQ dataset (left) and LSUN outdoor Church dataset (right). Note that LSUN dataset images were collected with JPEG compression (quality 75), whereas FFHQ images were collected as PNG. Interestingly, for LSUN dataset, the best FID score (3.48) is obtained when the generated images are compressed with JPEG quality 87. Below, we plot FID as a function of JPEG compression, applied to StyleGAN2 images, trained on LSUN Churches (left) and FFHQ (right) datasets at a resolution of 256 x 256. The blue dashed line shows FID when the generated images are quantized to 8-bit unsigned integers (PNG). Interestingly, when training with JPEG-75 dataset images (left), applying lossy compression artifically improves the FID score by a large margin (4.00 -> 3.48). |

|

Paper
Citation
Gaurav Parmar, Richard Zhang, and Jun-Yan Zhu. "On Aliased Resizing and Surprising Subtleties in GAN Evaluation", To appear in CVPR, 2022.
Bibtex
Acknowledgment
We thank Jaakko Lehtinen and Assaf Shocher for bringing attention to this issue and for helpful discussion. We thank Sheng-Yu Wang, Nupur Kumari, Kangle Deng, and Andrew Liu for useful discussions. We thank William S. Peebles, Shengyu Zhao, and Taesung Park for proofreading our manuscript. We are grateful for the support of Adobe, Naver Corporation, and Sony Corporation.