Quiz Statistics
Quiz Summary
| Average Score | High Score | Low Score | Standard Deviation | Average Time |
|---|---|---|---|---|
| 79% | 100% | 7% | 1.56 | 2 hours and 54 minutes. |
Question Breakdown
Question 1
Which of your quiz scores will be dropped?
| Answer Text | Number of Respondents | Percent of respondents selecting this answer |
|---|---|---|
| No scores will be dropped, (Incorrect answer) | 0 % | |
| Lowest 2 quiz scores, (Correct answer) | 100 % | |
| Lowest 3 quiz scores, (Incorrect answer) | 0 % | |
| Lowest 1 quiz score, (Incorrect answer) | 0 % |
Question 2
Which statements did David Hartley assert or imply in Observations on Man? (select all that apply)
Attempts: 75 out of 75| Answer Text | Number of Respondents | Percent of respondents selecting this answer |
|---|---|---|
| The brain records information as vibrations., (Correct answer) | 95 % | |
| Memories can be stored and can be linked to sensory input., (Correct answer) | 92 % | |
| The brain can receive and process sensory input., (Correct answer) | 92 % | |
| The brain is composed of neurons connected in a network., (Incorrect answer) | 7 % | |
| No Answer, (Incorrect answer) | 3 % |
Question 1
Match the models to their definitions.
1.- The McCulloch and Pitts model
2.- Is one of David Hartley’s Observations 3.- Frank Rosenblatt
4.- Associationism Theory by Aristotle
5.- Alexander Bain
6.- Lawrence Kubie
7.- Hebbian Learning
8.- Marvin Minsky and Seymour Papert
A.___ known for his Connectionism Theories.
B.___ These are his four laws of association: The law of contiguity, The law of frequency, The law of similarity, The law of contrast.
C.___ Their mechanism known as the multilayer Perceptron could perform all Boolean functions including the XOR.
D.___ Modeled the memory as a circular network.
E.___ A proposed mechanism to update weights between neurons in a neural network.
F.___ made the first algorithmically described neural network with a learning algorithm that was provably convergent in some cases.
G.___ Our brain represents compound or connected ideas by connecting our memories with our current senses.
H.___ A Logical Calculus of the Ideas Immanent in Nervous Activity, a mathematical model of a neuron.
Attempts: 110 out of 111| Answer Text | Number of Respondents | Percent of respondents selecting this answer |
|---|---|---|
| (1,H), (2,E), (3,F), (4,B), (5, A), (6,D), (7,G), (8,C), (Incorrect answer) | 3 % | |
| (1,H), (2,G), (3,F), (4,B), (5, A), (6,D), (7,E), (8,C), (Correct answer) | 96 % | |
| (1,A), (2,G), (3,F), (4,B), (5, H), (6,D), (7,E), (8,C), (Incorrect answer) | 0 % | |
| (1,H), (2,G), (3,D), (4,B), (5, A), (6,F), (7,E), (8,C), (Incorrect answer) | 0 % | |
| No Answer, (Incorrect answer) | 1 % |
Question 4
What term does the following sentence describe? "The finding that neurons whose connections form cycles can model memory."
Attempts: 83 out of 83| Answer Text | Number of Respondents | Percent of respondents selecting this answer |
|---|---|---|
| Parallel Distributed Processing., (Incorrect answer) | 1 % | |
| Sanger's Rule., (Incorrect answer) | 2 % | |
| Turing's B-type machines., (Incorrect answer) | 0 % | |
| Lawrence Kubie's Loop Networks, (Correct answer) | 96 % |
Question 6
Suppose you have a neural network with only two inputs I1 and I2, and two output neurons O1 and O2. There are no hidden units. All neuron outputs are Boolean. The network has been trained to model the following function:
| I1 | I2 | O1 | O2 |
| 1 | 0 | 1 | 0 |
| 1 | 1 | 0 | 1 |
| 0 | 0 | Invalid input | Invalid input |
| 0 | 1 | Invalid input | Invalid input |
The vast majority of the data set has I1 = 1, I2 = 0. If we apply Hebbian learning with this trained network on our data set, will the behavior of the network eventually change? If so, what will happen first?
Attempts: 229 out of 231| Answer Text | Number of Respondents | Percent of respondents selecting this answer |
|---|---|---|
| The network will start to map I1 = 1, I2 = 1 to O1 = 1, O2 = 0, (Incorrect answer) | 24 % | |
| The network will start to map I1 = 1, I2 = 1 to O1 = 1, O2 = 1, (Correct answer) | 56 % | |
| The network will start to map I1 = 1, I2 = 0 to O1 = 0, O2 = 1, (Incorrect answer) | 3 % | |
| The network's behavior will not change, (Incorrect answer) | 16 % | |
| No Answer, (Incorrect answer) | 1 % |
Question 6
A majority function is a Boolean function of N variables that produces a 1 if at least N/2 of the inputs are 1. Which of the following are true? (select all that apply)
Attempts: 112 out of 112| Answer Text | Number of Respondents | Percent of respondents selecting this answer |
|---|---|---|
| A fixed-depth Boolean circuit, comprising only AND, OR and NOT gates, will require O(exp(N)) gates to compute the majority function, (Correct answer) | 65 % | |
| The number of gates in the smallest Boolean circuit of AND, OR and NOT gates that computes the majority function is polynomial in N., (Incorrect answer) | 28 % | |
| A single perceptron can compute a majority function., (Correct answer) | 87 % | |
| We will require a multilayer perceptron with O(exp(N)) perceptrons to compute a majority function, (Incorrect answer) | 8 % | |
| No Answer, (Incorrect answer) | 2 % |
Question 1
How many neurons will the smallest (in terms of neurons) network that implements the truth table shown by the following Karnaugh map need?
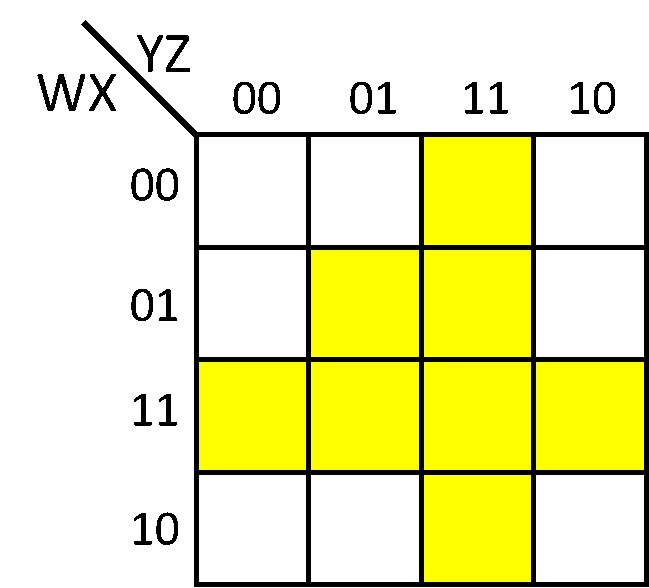
| Answer Text | Number of Respondents | Percent of respondents selecting this answer |
|---|---|---|
| 0.00, (Correct answer) | 0 % | |
| 0.00, (Correct answer) | 0 % | |
| 0.00, (Correct answer) | 0 % | |
| 4.00, (Correct answer) | 71 % | |
| Something Else, (Incorrect answer) | 27 % | |
| No Answer, (Incorrect answer) | 2 % |
Question 8
How does the number of weights in an XOR network with 1 hidden layer grow with the number of inputs to the network?
Attempts: 52 out of 52| Answer Text | Number of Respondents | Percent of respondents selecting this answer |
|---|---|---|
| Linear, (Incorrect answer) | 10 % | |
| Between polynomial and exponential, (Incorrect answer) | 8 % | |
| Exponential or faster, (Correct answer) | 79 % | |
| Polynomial but faster than linear, (Incorrect answer) | 4 % |
Question 9
We would like to compose an MLP that can represent a three-dimensional version of the cross-hash function shown below (the illustration is 2-dimension because it is difficult to depict the 3-D version of the map). The input is now a three-dimensional vector. The output map comprises alternating cuboids of yellow and grey, where yellow represents a region where the function must output 1, and grey cuboids are regions where it must output 0.
If the network is restricted to only two hidden layers (fixed total depth of 3 including output layer), which of the following is true of the number of neurons required to model the function where the network must output a 1 if the input is in the yellow regions, but 0 if it’s in the grey regions?
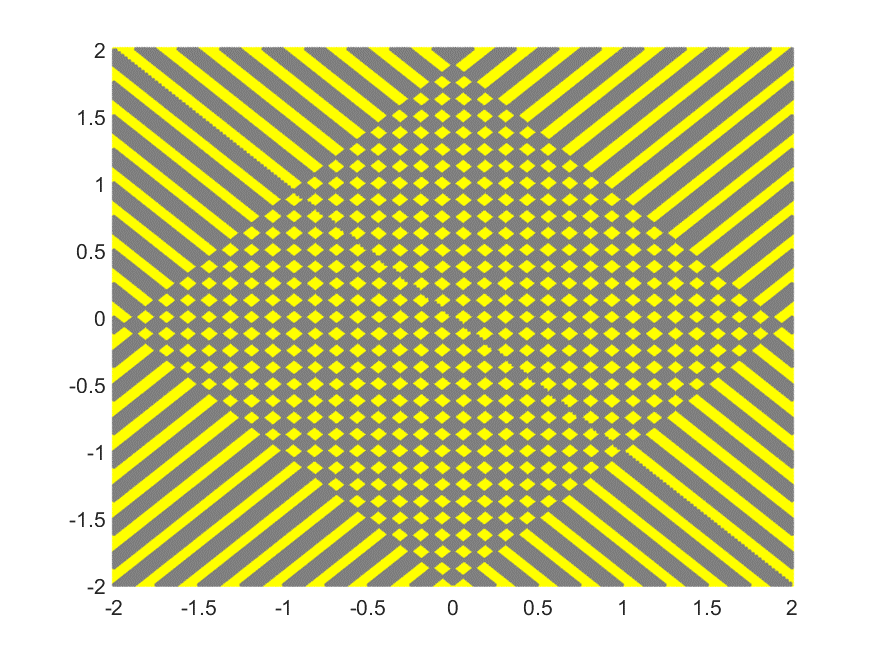
| Answer Text | Number of Respondents | Percent of respondents selecting this answer |
|---|---|---|
| It is exponential in the number of hyperplanes required to form the cross hash, (Incorrect answer) | 18 % | |
| It is polynomial in the number of hyperplanes required to form the cross hash, (Correct answer) | 47 % | |
| It is linear in the number of hyperplanes required to form the cross hash, (Incorrect answer) | 20 % | |
| It is quadratic in the number of hyperplanes required to form the cross hash, (Incorrect answer) | 13 % | |
| No Answer, (Incorrect answer) | 2 % |
Question 10
Suppose you are using a neural network to recognize MNIST handwritten digits in a 28x28 grid of pixels. The neural network contains neurons that input and output REAL values. Almost any activation function would work, but for now assume that all neurons use the sigmoid activation function.
The network architecture contains two parts, an encoder and a decoder. The output of the encoder is passed as the input of the decoder:
Encoder: 784-dimensional input, 1-dimensional output. Contains as many neurons and hidden layers as needed.
Decoder: 1-dimensional input, 10-dimensional output. Contains as many neurons and hidden layers as needed.
This is a horrible architecture in practice because of the 1-dimensional bottleneck in the middle. In theory though, does there exist a network of this form that correctly classifies all the available MNIST digits?
Attempts: 89 out of 90| Answer Text | Number of Respondents | Percent of respondents selecting this answer |
|---|---|---|
| Yes. The encoder can split the 1-dimensional range into 10 regions and classify the input with respect to that, and the decoder extracts the one-hot value from this encoding., (Correct answer) | 94 % | |
| No, (Incorrect answer) | 4 % | |
| No Answer, (Incorrect answer) | 1 % |
Question 4
What term does the following sentence describe? "A modification of Hebbian learning addressing its lack of weight reduction and its instability."
Attempts: 71 out of 73| Answer Text | Number of Respondents | Percent of respondents selecting this answer |
|---|---|---|
| Sanger’s rule, (Correct answer) | 95 % | |
| Lawrence Kubie’s loop networks, (Incorrect answer) | 1 % | |
| Parallel distributed processing, (Incorrect answer) | 1 % | |
| Turing’s A-type machines, (Incorrect answer) | 0 % | |
| No Answer, (Incorrect answer) | 3 % |
Question 1
Under which conditions will the perceptron graph below fire? (select all that apply). In the figure the number within the circle is the threshold. The numbers on the edges are weights. The perceptron fires if the total incoming signal is at least equal to the threshold.

| Answer Text | Number of Respondents | Percent of respondents selecting this answer |
|---|---|---|
| , (Incorrect answer) | 12 % | |
| Never fires, (Incorrect answer) | 0 % | |
| , (Incorrect answer) | 26 % | |
| , (Correct answer) | 100 % | |
| No Answer, (Incorrect answer) | 2 % |
Question 8
Is the following statement true or false?
"For any Boolean function on the real plane, which outputs a 1 within a single connected but NON-CONVEX region in the plane (i.e. not a convex polygon), you need at least three layers (including the output layer) to model the function EXACTLY"
Attempts: 52 out of 53| Answer Text | Number of Respondents | Percent of respondents selecting this answer |
|---|---|---|
| True, (Incorrect answer) | 25 % | |
| False, (Correct answer) | 74 % | |
| No Answer, (Incorrect answer) | 2 % |
Question 1
According to the university’s academic integrity policies, which of the following practices are NOT allowed in this course? Select all that apply.
Attempts: 109 out of 109| Answer Text | Number of Respondents | Percent of respondents selecting this answer |
|---|---|---|
| Discussing concepts from class with another student, (Incorrect answer) | 1 % | |
| Posting code in a public post on piazza, (Correct answer) | 98 % | |
| Asking a TA for help debugging your code, (Incorrect answer) | 13 % | |
| Solving quiz questions with another student, (Correct answer) | 96 % | |
| Helping another student debug their code, (Correct answer) | 90 % |
Question 1
We sometimes say that neural networks are connectionist machines as opposed to Von Neumann machines. Which of the following describe why we make this distinction? (select all that apply)
Attempts: 119 out of 119| Answer Text | Number of Respondents | Percent of respondents selecting this answer |
|---|---|---|
| A Von Neumann machine can be used for general-purpose computing by simply providing a different program, without changing the machine itself. A connectionist machine implements a specific program, and changing the program requires changing the machine., (Correct answer) | 87 % | |
| Because of its flexibility, a Von Neumann machine is capable of computing any Boolean function of a given number of Boolean inputs, whereas connectionist machines, no matter how complex, are fundamentally unable to model certain types of Boolean functions., (Incorrect answer) | 2 % | |
| It is possible to create hardware implementations of Von Neumann machines (e.g. CPU's) as well as software implementations (e.g. virtual machines). However, connectionist machines can only be implemented in software (e.g. neural networks in Python)., (Incorrect answer) | 11 % | |
| A Von Neumann machine has a general purpose architecture with a processing unit that is distinct from the memory that holds the programs and data. A connectionist machine makes no distinction between processing unit and the program., (Correct answer) | 99 % | |
| No Answer, (Incorrect answer) | 1 % |
Question 8
How does the number of weights in an XOR network with 2 hidden layers grow with the number of inputs to the network?
Attempts: 30 out of 30| Answer Text | Number of Respondents | Percent of respondents selecting this answer |
|---|---|---|
| Linear, (Incorrect answer) | 27 % | |
| Between polynomial and exponential, (Incorrect answer) | 27 % | |
| Faster than exponential, (Incorrect answer) | 23 % | |
| Polynomial but faster than linear, (Correct answer) | 23 % |
Question 9
What is the implication of Shannon’s theorem on network size (as a function of input size) for Boolean functions? (select all that apply)
Attempts: 50 out of 50| Answer Text | Number of Respondents | Percent of respondents selecting this answer |
|---|---|---|
| Most functions require polynomial sized networks., (Incorrect answer) | 6 % | |
| Only a relatively small class of functions require exponentially sized inputs, (Incorrect answer) | 6 % | |
| There is no upper bound on the worst size of a network, (Incorrect answer) | 34 % | |
| Nearly all functions require exponential-sized networks, (Correct answer) | 86 % | |
| No Answer, (Incorrect answer) | 2 % |
Question 9
Is the following statement true or false? An activation function must always be a squashing function.
Attempts: 74 out of 75| Answer Text | Number of Respondents | Percent of respondents selecting this answer |
|---|---|---|
| True, (Incorrect answer) | 3 % | |
| False, (Correct answer) | 96 % | |
| No Answer, (Incorrect answer) | 1 % |
Question 10
Suppose the data used in a classification task is 10-dimensional and positive in all dimensions. You have two neural networks. The first uses threshold activation functions for hidden layers, and the second uses softplus activation functions for hidden layers. In both networks, there are 2000 neurons in the first hidden layer, 8 neurons in the second hidden layer, and a huge number of neurons for all later layers. It turns out that the first network can never achieve perfect classification. What about the second network?
Attempts: 66 out of 66| Answer Text | Number of Respondents | Percent of respondents selecting this answer |
|---|---|---|
| It too is guaranteed to be unable to achieve perfect classification., (Incorrect answer) | 5 % | |
| It might fail for some data sets, not only because 8 neurons could bottleneck information in the second layer, but also because the 2000 neurons in the first hidden layer could bottleneck the flow of information if the classification task is sufficiently complex, (Incorrect answer) | 35 % | |
| Assuming that layers 3 and above are so expressive that they never bottleneck the flow of information, the second network will be able to achieve perfect classification., (Incorrect answer) | 6 % | |
| It might fail for some data sets, since the 8 neurons in the second hidden layer could bottleneck the flow of information. In that case, the sizes of layers 3 and above don't matter., (Correct answer) | 55 % |
Question 2
Which are NOT one of Aristotle's laws of association? (select all that apply)
Attempts: 72 out of 72| Answer Text | Number of Respondents | Percent of respondents selecting this answer |
|---|---|---|
| Events or things near the same place and time are associated, (Incorrect answer) | 3 % | |
| Thoughts about one event or thing triggers thoughts about events or things that have opposite qualities, (Incorrect answer) | 6 % | |
| Associations are formed from logical deduction, (Correct answer) | 89 % | |
| Thoughts about one event or thing triggers thoughts about related events or thing, (Incorrect answer) | 3 % | |
| Unrelated events or things can be associated by mental willpower, (Correct answer) | 96 % |
Question 8
How does the number of weights in an XOR network with arbitrarily many hidden layers grow with the number of inputs to the network?
Attempts: 55 out of 56| Answer Text | Number of Respondents | Percent of respondents selecting this answer |
|---|---|---|
| Between polynomial and exponential, (Incorrect answer) | 5 % | |
| Faster than exponential, (Incorrect answer) | 4 % | |
| Polynomial but faster than linear, (Incorrect answer) | 7 % | |
| Linear, (Correct answer) | 82 % | |
| No Answer, (Incorrect answer) | 2 % |
Question 10
Which of the following are impossible in theory? Assume all networks are finite in size, though they can be as large as needed. (select all that apply)
Attempts: 72 out of 72| Answer Text | Number of Respondents | Percent of respondents selecting this answer |
|---|---|---|
| Using a threshold network with one hidden layer to perfectly classify all digits in the MNIST dataset., (Incorrect answer) | 39 % | |
| Using a threshold network, as deep as you need, to calculate the L1 distance from a point to the origin., (Correct answer) | 71 % | |
| Using a threshold network, as deep as you need, to determine if an arbitrary 2D input lies within the square with vertices {(1, 0), (-1, 0), (0, 1), (0, -1)}., (Incorrect answer) | 17 % | |
| Using a threshold network with one hidden layer to determine if an arbitrary 2D input lies within the unit circle., (Correct answer) | 64 % | |
| No Answer, (Incorrect answer) | 4 % |
Question 2
When was the first connectionist network model proposed?
| Answer Text | Number of Respondents | Percent of respondents selecting this answer |
|---|---|---|
| 1957 by Frank Rosenblatt, (Incorrect answer) | 0 % | |
| 1943 by McCulloch and Pitts, (Incorrect answer) | 7 % | |
| 1873 by Alexander Bain, (Correct answer) | 89 % | |
| 1949 by Donald Hebb, (Incorrect answer) | 1 % | |
| 1749 by David Hartley, (Incorrect answer) | 2 % |
Question 4
Is the following statement true or false? Hebbian learning allows reduction in weights and learning is bounded.
Attempts: 75 out of 75| Answer Text | Number of Respondents | Percent of respondents selecting this answer |
|---|---|---|
| True, (Incorrect answer) | 0 % | |
| False, (Correct answer) | 100 % |
Question 1
Under which conditions will the perceptron graph below fire? (select all that apply).
In the figure the number within the circle is the threshold. The numbers on the edges are weights. The perceptron fires if the total incoming signal is at least equal to the threshold.

| Answer Text | Number of Respondents | Percent of respondents selecting this answer |
|---|---|---|
| , (Correct answer) | 97 % | |
| Never fires, (Incorrect answer) | 0 % | |
| , (Incorrect answer) | 0 % | |
| , (Correct answer) | 100 % | |
| No Answer, (Incorrect answer) | 2 % |
Question 9
If the first layer of a network operating on real-valued inputs does not have sufficient neurons to capture all the basic features of the function (map), which of the following activation functions gives subsequent layers the best chance to capture the features missed by the first layer?
Attempts: 59 out of 60| Answer Text | Number of Respondents | Percent of respondents selecting this answer |
|---|---|---|
| Threshold activation, (Incorrect answer) | 0 % | |
| Sigmoid activation, (Incorrect answer) | 7 % | |
| Leaky ReLU activation, (Correct answer) | 85 % | |
| ReLU activation, (Incorrect answer) | 7 % | |
| No Answer, (Incorrect answer) | 2 % |
Question 1
Under which conditions will the perceptron graph below fire? (select all that apply) In the figure the number within the circle is the threshold. The numbers on the edges are weights. The perceptron fires if the total incoming signal is at least equal to the threshold.
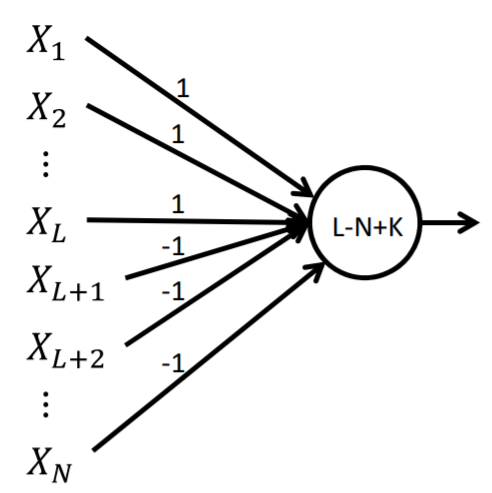
| Answer Text | Number of Respondents | Percent of respondents selecting this answer |
|---|---|---|
| , (Incorrect answer) | 7 % | |
| , (Correct answer) | 96 % | |
| Will never fire, (Incorrect answer) | 0 % | |
| , (Incorrect answer) | 13 % | |
| No Answer, (Incorrect answer) | 2 % |
Question 8
A neural network can compose any function with real-valued inputs (with either Boolean or real-valued outputs) perfectly, given a sufficient number of neurons
Attempts: 38 out of 40| Answer Text | Number of Respondents | Percent of respondents selecting this answer |
|---|---|---|
| True, (Incorrect answer) | 35 % | |
| False, (Correct answer) | 60 % | |
| No Answer, (Incorrect answer) | 5 % |
Question 6
Which of the following statements are true about MLPs? (select all that apply)
Attempts: 116 out of 116| Answer Text | Number of Respondents | Percent of respondents selecting this answer |
|---|---|---|
| The VC dimension of an MLP is bounded by the square of the number of weights in the network, (Correct answer) | 86 % | |
| Deeper networks may require far fewer neurons than shallower networks to express the same function, (Correct answer) | 96 % | |
| A network comprising exactly one layer is a Universal Boolean Machine, (Incorrect answer) | 27 % | |
| To compose arbitrarily complex decision boundaries MLPs need multiple hidden layers depending on the complexity of the boundaries., (Incorrect answer) | 24 % | |
| No Answer, (Incorrect answer) | 1 % |