The basic unit selection premise is that we can synthesize new naturally sounding utterances by selecting appropriate sub-word units from a database of natural speech.
There are lots of conditions that must be met in order for such a system to work. Let us consider the following basic notion of unit selection. Although this particular instantiation comes from [1] it will be generalized to help illustrate the space of the problems.
In [1] and in later, and earlier unit selection techniques [2], there is a notion of a target cost, how close a database unit is to desired unit, and a join cost, how well two adjacently selected units join together. The unit selection process is designed to optimally minimise both target and join costs.
More formally we can define the target cost ![]() to be the weighted
sum of differences of relevant features.
to be the weighted
sum of differences of relevant features.
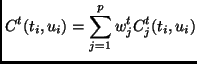
In addition to selecting based on target cost we can define continuity cost as a weighted sum of difference of features

![$\displaystyle C(t_1^n, u_1^n) = \sum_{i=1}^n C^t(t_i, u_i) +
\sum_{i=2}^n C^c(u_{i-1},u_i) +
\makebox[5mm][0mm]{} $](img4.png)
Where
There has been, and will continue to be, a substantial amount of work in looking at what features should be used, and how to weight them. Getting the algorithms, measures and weights right will be key to consistent high quality synthesis. Looking at the amount of work and experiments done in the similarly complex field of speech recognition we can see we have still much to do, in spite of our successes.
It is interesting to note that in comparing current algorithms, theoretic advantages may be identified but it is not clear if these hold up in any reals sense due to the variation in databases, their labelling and the time one spends tuning the parameters. In fact ``tuning the parameters'' seems to be the most important factor in getting good consistent synthesis.
But what if, for now, we assume that we have the perfect features and the best weights. There are still factors outside these that affect the speech quality. It is those factors that will be discussed in the following section.