PDE Constrained Optimization
Solving Inverse Problems
Arjun Teh
Outline
- What is the Inverse Problem?
- A theoretic framework for solving PDECO
- The eikonal equation
The Forward Problem
Solving a physical problem requires simulation

Given parameters, \(\theta\), what is a configuration, \(x\), that satisfies the above equation?
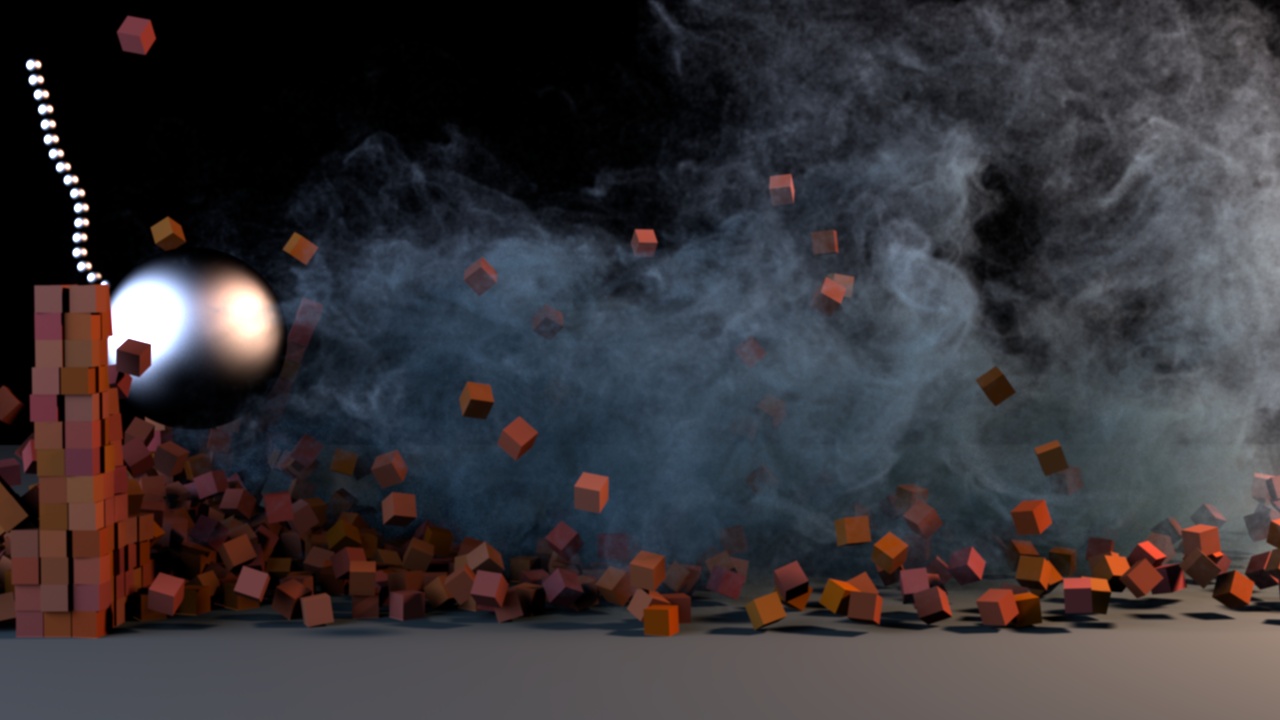
The Forward Problem
Examples of \(\theta\):
- Surface shape for FEM
- Initial conditions for the simulation
- Resistance parameter for traveling waves
Configuration could refer to the heat value at a particular time, or the position at a time value.


The Inverse Problem
"I want to find the parameters, \(\theta\), that will admit the configuration, \(x\), that I observed/desire"
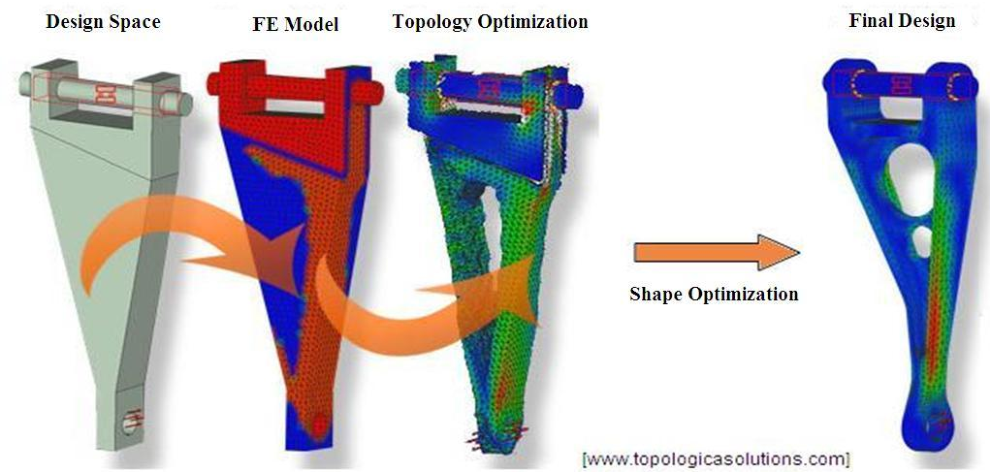
The Inverse Problem
Examples include:
- Shape Optimization
- Stress
- Fluid Control
- etc.
- Seismic Imaging
- Wave modeling
- Traveltime modeling
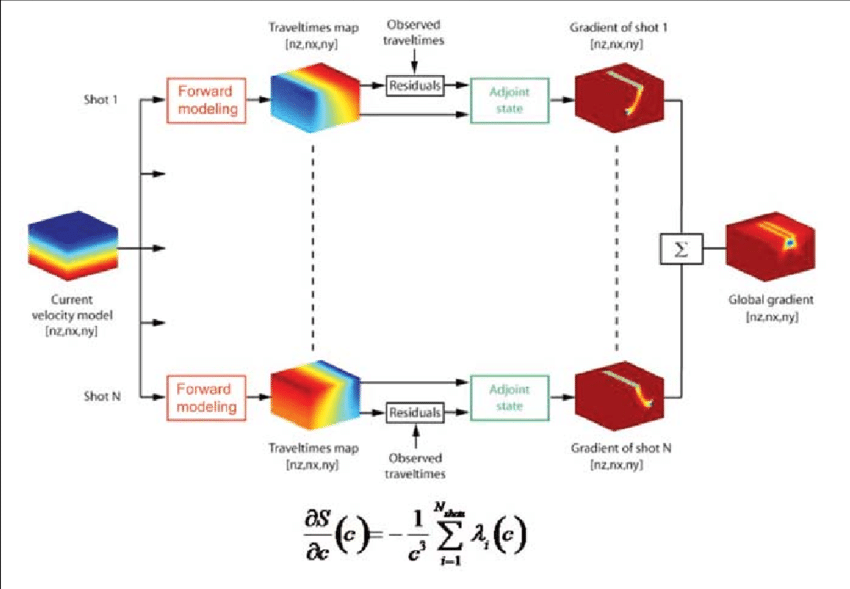
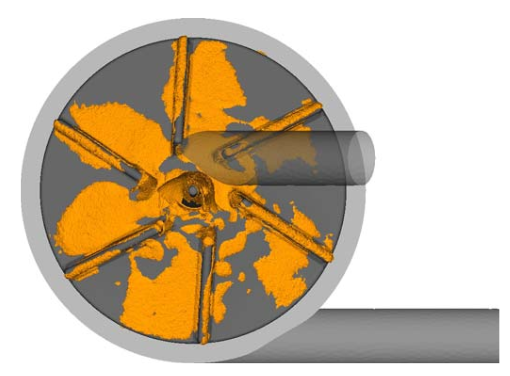
The inverse optimization problem is hard.
Each evaluation of the loss function requires a full simulation. To calculate a gradient, finite difference would require multiple runs of the same simulation.
The inverse optimization problem is functional.
PDEs are described in terms of function spaces. Consequently, the inverse problem is also in terms of function spaces rather than discrete vector spaces

The optimization will be effected by our choice of discretization
How to solve PDECO?
There's no one-size-fits-all solution!


Building a theory
We need \(d_{\theta}f\) in order to do any gradient based optimization
Calculating \(d_\theta f\)
Calculating \(d_\theta f\)
Derivative of dynamics
(application specific)
Derivative of cost functional
(closed form usually)
}
The Adjoint State
\(\lambda\) is known as the adjoint state
\(\lambda\) is the same dimension as the configuration, \(x\).
Solving for the adjoint state is no harder than running the forward simulation; it is often a linear solve
Lagrange Multipliers
The adjoint state can be derived from Lagrange multipliers.

where \(x^*\) and \(\lambda^*\) are critical points.
Lagrange Multipliers
One can view the adjoint state method as an extension of discrete Lagrange multipliers to functionals, where \(\lambda\) is a function instead of a coefficient.

In the PDECO literature, the KKT conditions are referenced a lot in the context of functional analysis.
The eikonal as an example
From images of a volume, and I want to invert the image formation model to obtain the volume. Our equation of interest is the eikonal equation
The eikonal as an example
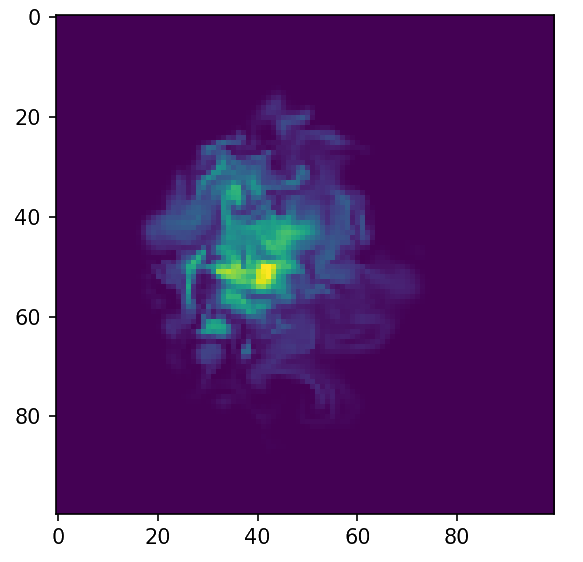
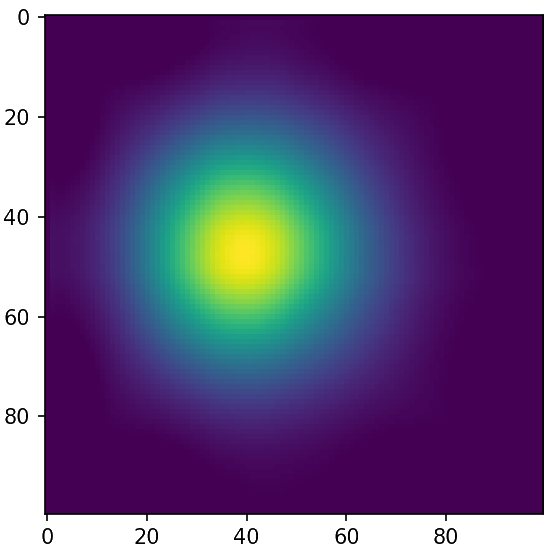
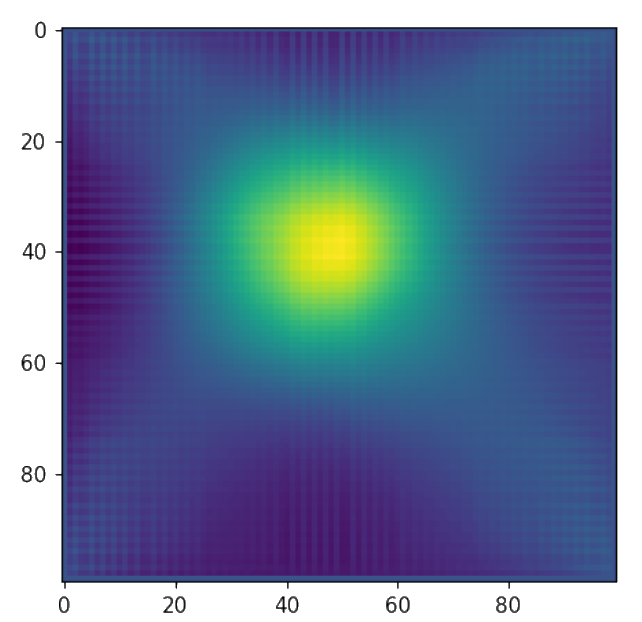
Ground Truth
Initialization
Adjoint
The eikonal as an example
Ground Truth
Initialization
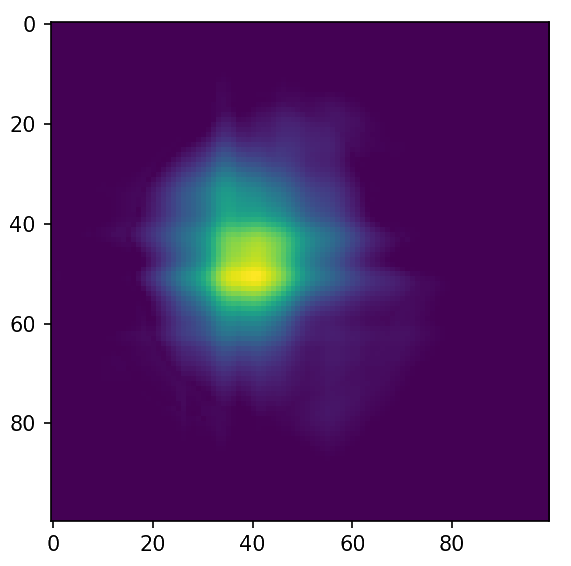
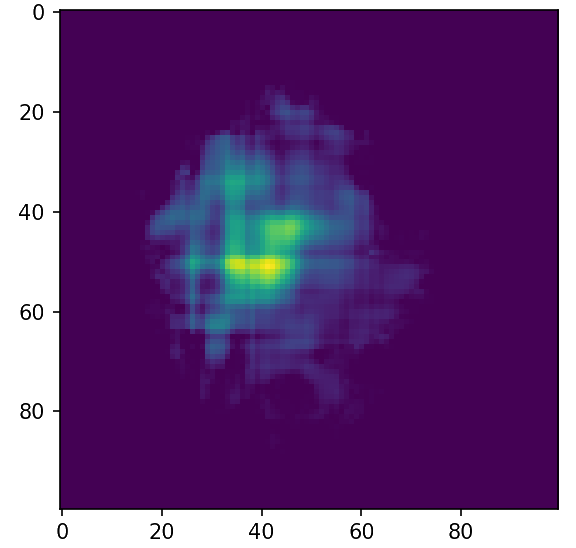
Step 3
Final
Out of the box optimization gives good results!
Conclusion
- PDE Constrained Optimization is Lagrange Multipliers in disguise
- The broad theory for the adjoint state method can be used to tackle inverse problems
- Generally, the adjoint is faster to solve than the forward simulation itself

References and Links
- Nice explanation of the derivation:
- Presentation on Cea's Method for shape optimization:
- Generally, the adjoint is faster to solve than the forward simulation itself