
KNOWLEDGE TRANSFER FROM WEAKLY LABELED AUDIO USING CONVOLUTIONAL NEURAL NETWORK FOR SOUND EVENTS AND SCENES. pdf
Authors: Anurag Kumar, Maksim Khadkevich, Christian Fügen
We try to draw some semantic inferences from our proposed methods. We first see if the learned representations carries meaning. The figures below shows the well-known tSNE visualization for learned representations for ESC-50 dataset.
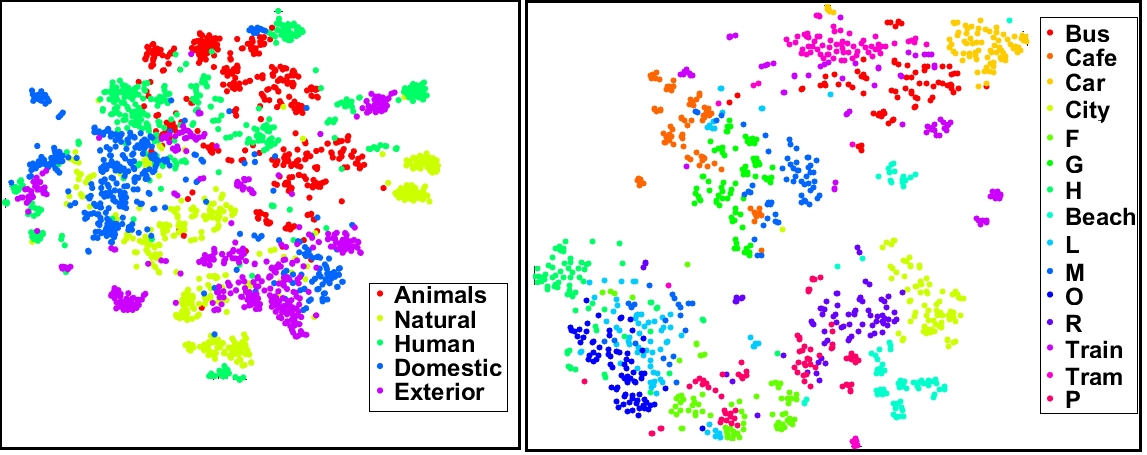
Our proposed methods for transfer learning can be used for drawing semantic relations as well. In particular, we look into acoustic scene and sound event relations. Acoustic scenes are often composed of multiple sound events. In general, there are sound events which you expect to find in an environment or scene. For example, in Park you expect to find sound such as Bird Song, Crow, Wind Noise etc. These scene-sound event relations can be helpful not only for acoustic scene classification task but in general for audio based artificial intelligence. These semantic relations can be used for obtaining higher level semantic information which can further help in human computer interaction and development of audio based context aware systems.
The source model \(\mathcal{N}_S\) has been trained for 527 sound events, a fairly large number of sounds. As explained in the paper, the target specific adaptation of network (\(\mathcal{N}_T^{II}\) and \(\mathcal{N}_T^{III}\)) transitions through the label space before going into the target label space. Hence, one can argue that during adaptive training the network learns a mapping from sound events in F2 to the target label space in final layer. This can be useful in establishing relations between labels in the target space and the sound events in the layer before that.
We show this characteristics for scene-sound event relations. For the acoustic scenes in DCASE-2016, we try to establish which sound events from Audioset are related to it or in other words we try to establish the sound events which might frequently occur in an acoustic scene/environment.
To establish these relations, we look at the sound events which are maximally activated for inputs of a given scene. The neurons of F2 are essentially representing the sound events in Audioset. The activation of these neurons can help understand whether a sound event is expected to occur in a scene or not. For an input of a given scene, we make a list of the events that is outputs of F2 layer, which were maximally activated. We consider the top 5 maximally activated events. Since F2 produces outputs at segment level (~1.5 seconds in our case), these activations are noted at segment level. We do this for all recordings of a given scene and note down the frequency of occurrence of events in the top 5 list. We then note down the sound events with highest (among top 10) frequencies. These sound events are often maxmially activated for the given scene and hence we expect them to be related to the acoustic scene. In other words, one can expect to find these sound events in the corresponding acoustic scene. The Table below shows examples of these often maxmimally activated events.
Note that most of these relations are meaningful, imlying the proposed transferring learning approaches is actually able to relate the sound events with the target labels, acoustic scenes in the present case. This gives a general framework to discover relationships between source and target tasks. One can potentially apply the same methods to other audio tasks such as emotion recognition in audio and see if such relationships can be automatically established. This method of automatically learning relationships using transfer learning can further be used for developing sound ontologies as well.
| Acoustic Scenes | Related Sound Events (Frequent Highly Activated Events) |
|---|---|
| Cafe | Speech, Chuckle- Chortle, Dishes-pots-and-pans, Snicker, Television, Throat Clearing, Singing |
| City Center | Applause, Siren, Emergency Vehicle, Ambulance |
| Forest Path | Stream, Boat Water Vehicle, Squish, Frog, Pour, Clatter |
| Grocery Store | Shuffle, Singing, Speech, Music, Siren, Ice-cream truck |
| Home | Speech, Baby Cry, Finger Snapping, Dishes-pots-and-pans, Cutlery, Sink (filling or washing), Throat Clearing, Writing, Squish |
| Beach | Pour, Stream, Applause, Splash - Splatter, Gush, Wind noise, Squish, Boat- Water vehicle |
| Library | Finger snapping, Squish, Fart, Speech, Snort, Singing |
| Metro Station | Speech, Squish, Singing, Siren, Music |
| Office | Finger Snapping, Snort, Cutlery, Speech, Chirp tone, Shuffling cards |
| Residential Area | Applause, Clatter, Bird, Siren, Emergency Vehicle |
| Park | Bird, Crow, Stream, Rustle, Bee wasp, Wind Noise, Frog |
| Bus | Bus, Motor Vehicle, Car, Vibration, Rustle |
| Car | Car, Motor Vehicle, Rumble, Music, Rustle |
| Train | Heavy Engine, Siren, Car, Motor Vehicle, Music, Rustle |
| Tram | Car, Motor Vehicle, Speech, Throbbing, Rumble |