KNOWLEDGE TRANSFER FROM WEAKLY LABELED AUDIO USING CONVOLUTIONAL NEURAL NETWORK FOR SOUND EVENTS AND SCENES. pdf
Authors: Anurag Kumar, Maksim Khadkevich, Christian Fügen
DCASE-2016 Dataset
DCASE-2016 [5] is an acoustic scene dataset. It consists of a total of 15 acoustic scenes, namely, Beach, Bus, Cafe/Resturant, Car, City Center, Forest Path, Grocery Store, Forest Path, Home, Library, Metro Station, Office, Park, Residential Area, Train, Tram.
The dataset consists of a total of 1,170 recordings, each of 30 seconds durations.
It comes pre-divided into 4 folds.
The training set consists of 3 out of 4 folds and the remaining 4th fold is used for testing. This is done all 5 ways and average accuracies are reported.
The training set is used for network adaptation as well as for training linear SVMs.
DCASE-16 Results
Acoustic Scenes possess complex acoustic characteristics. Often, they are themselves composed of several sound events meshed together in a complex manner.
Comparison of our proposed method with baseline method is shown is paper
Our method not only outperforms baseline by over 4%
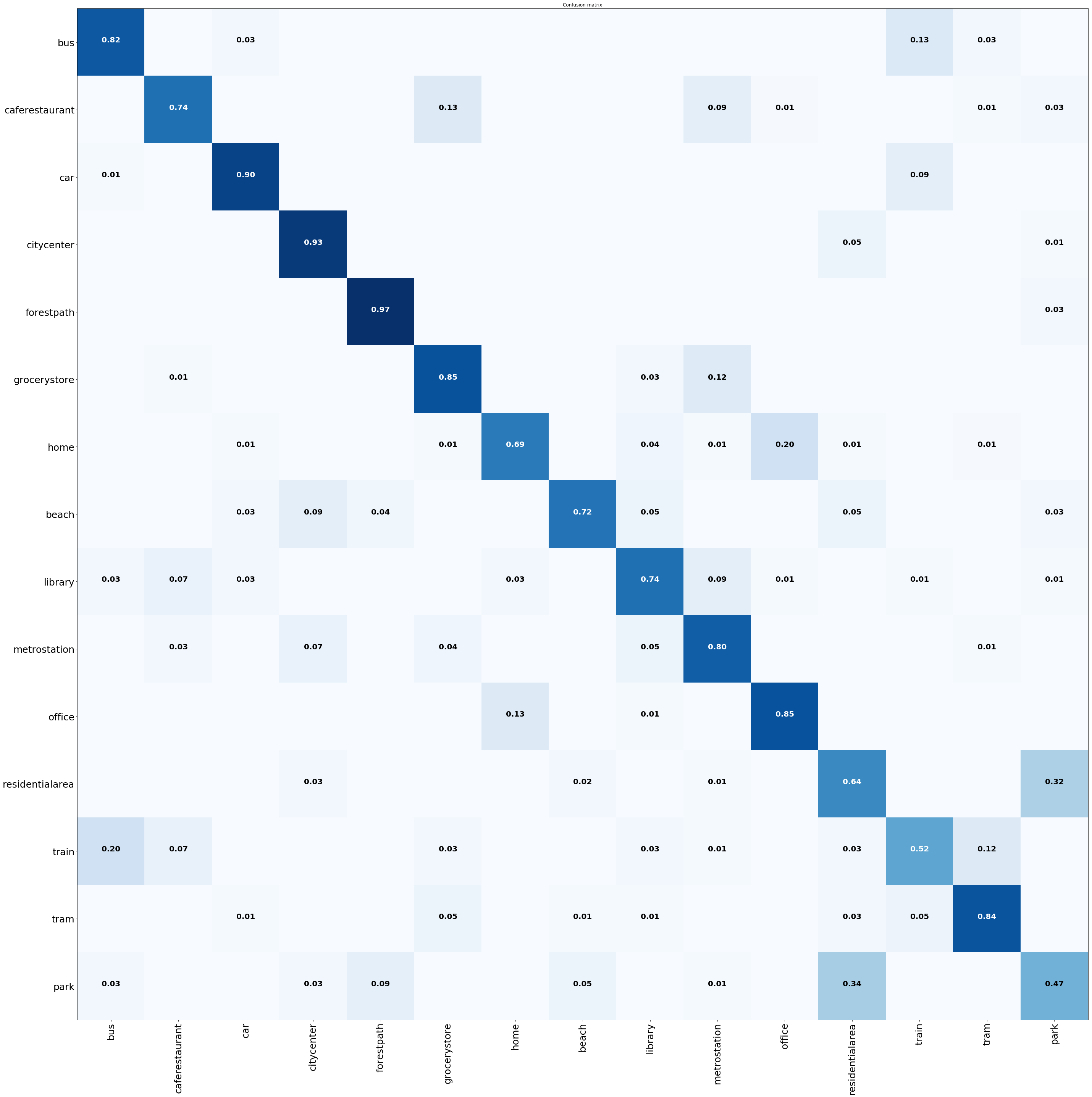
Best accuracy of 76.6.5% is obtained using F1 representations (with \(max()\) mapping), from \(\mathcal{N}_T^{III}\).
Class-wise results - Below we show confusion matrix for the best performance case. Classwise confusion matrix for all cases are available here. The file name clarifies the representation used, e.g dcase16.NT_III.F1.max.png means \(\mathcal{N}_T^{III}\) network, F1 representations and \(max()\) function to map segment level representations to full recording level representations. The figure files here, might be visually more pleasing. All numbers have been rounded to 2 decimal places.
Fig 1. Confusion matrix for F1 representations (\(max ()\) mapping) from \(\mathcal{N}_T^{III}\)