Our ICML papers share a unifying message: it is time to rethink LLM pre‑training . Scaling autoregressive models on ever-larger datasets has driven impressive benchmark gains and real-world deployments, yet these models stumble when asked for more: precise control, safe steering, targeted unlearning, rapid domain adaptation, or the creation of truly novel content. I summarize the limitations we identify, through large-scale empirical studies and clear conceptual examples.
It is appealing to think that we can keep improving our models by scaling up on more data, and if we run out of internet data, we can now fall back on synthetic data. However, the mantra that more data is always better
breaks down in the foundation model setting, where a pre-trained network is almost always adapted before deployment. Beyond a certain point, additional tokens make the model brittle: it fine-tunes more slowly, forgets more easily, and delivers worse downstream accuracy, a phenomenon we call catastrophic overtraining.
A helpful analogy from Vince Conitzer: imagine building card towers on a rock-solid table. As your skill improves, you construct taller, more delicate towers. But when the table is placed on a moving train, those fragile structures topple, whereas simpler early towers survive. Likewise, a heavily overtrained model provides good zero-shot performance on static benchmarks yet collapses when the ``table'' shifts: when adapting to new domains, steering for safety, or unlearning.
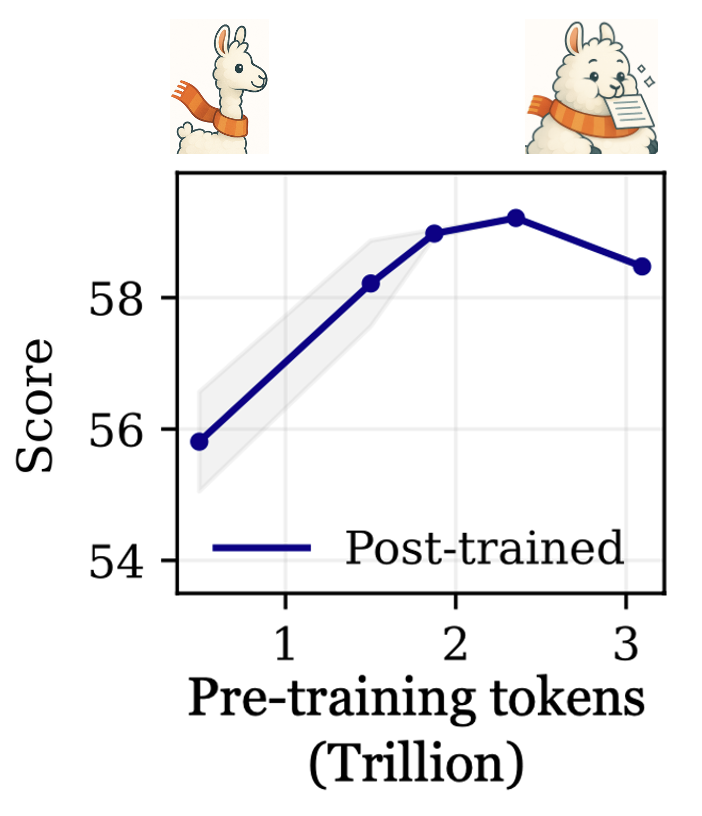
Our large scale experiments confirm that we already hit this catastrophic overtraining with our most latest 1B-parameter models. For example, the instruction-tuned OLMo-1B model pre-trained on 3T tokens leads to over 2% worse performance on multiple standard LLM benchmarks than its 2.3T token counterpart. Check out our paper for more details.
Note: this finding is conceptually similar to a finding from our work on scaling laws for precision. The degradation introduced by post-training quantization increases as models are trained on more data, eventually making additional pretraining data actively harmful.
Dozens of methods promise to erase private or harmful content from LLMs, yet results lag behind effort. Even after unlearning,
the supposedly purged information can often be extracted with a clever attack.
Why is it so hard?
Our empirical and theoretical analysis in our paper suggests a deeper answer: perfect unlearning might be impossible under today’s pre-training paradigm . The inductive bias of standard training encourages the same neurons and circuits to carry both generalization and memorization. Because memorized and generalized representations are entangled, there is no clean “memorization subspace” to target. Any attempt to prune or overwrite it either (i) leaves some memorized facts intact or (ii) damages the model so severely that it is no longer useful.
Intelligence isn't just about getting the right
answer. What also matters is imaginative problem solving: finding novel, unexpected connections to meet loosely defined requests. For example, a request such as Generate a challenging high-school word
problem involving the Pythagoras Theorem . It is messy and challenging to measure this on real-world datasets, and there are already interesting debates and contradictory findings within the community about whether LLMs can generate novel research ideas or write novel content.
To get to the bottom of this and tease out whether the underlying creative ability can emerge, we design and study minimal and controllable tasks that are loose abstractions of creativity, drawing inspiration from cognitive science literature (Boden, 2003) . Check out our extensive experiments and findings in our paper . Key takeaways: next-token learning is too myopic to optimally learn how to generate open-ended solutions when the structure (plan) is latent, and the de facto approach of eliciting randomness, temperature sampling might struggle to elicit structured diversity .
So what can we do differently? Are there scalable practical alternatives that can address the limitations we identify above? We list a few ideas that we are excited about below!
We propose a method that can isolate memorization by design. The key idea is to have designated memorization sinks that accumulate all the memorization, leaving generalization to the remaining neurons. But how do we prevent leakage between these memorization sinks and other neurons? But how do we prevent information from leaking out of these sinks? By consistently activating the same unique set of sinks for each document (or topic) every time it appears in the training data, we keep memorization safely contained. We can then perform close-top-perfect unlearning by simply dropping out these memorization sinks. Read our paper for implementation details, more analysis on why this works, and scaling properties. We believe memorization sinks could pave the way for models that are intrinsically capable of unlearning.
Creative solutions to our open-ended tasks require diversity in the latent plan or leap-of-thought. Intuitively, maximizing diversity at the output-token-level, like in the case of temperature sampling, is computationally burdensome: it requires simultaneously processing a diverse set of leaps of thoughts to compute a marginalized token distribution. It is perhaps easier (and more natural) to first sample single latent leap and then compute the tokens conditioned on that one leap. We instantiate a very simple version of this via seed-conditioning where we train with a random prefix string per example. We find that seed-conditioning achieves algorithmic creativity comparable to and sometimes outperforming temperature sampling.
Note that these random seeds are in fact meaningless, and it should seem surprising that this works at all! While we do not fully unerstand why this method works, we will elaborate on our intuition and conjectures in a future post. In the meantime, please read our paper for more results, analysis and discussion on this.
We advocate multi-token learning approaches such as teacherless training or diffusion as they avoid the Clever hans cheat (Bachman and Nagarajan, 2024) that next-token prediction is susceptible to. We show how this makes multi-token approaches achieve higher algorithmic creativity on our testbed. Furthermore, we identify natural structures where no re-ordering of tokens is friendly towards next-token prediction. These tasks cast doubt on whether recent proposals of fixing the myopia of next-token prediction via pertumations of tokens or partial lookahead can truly enable models to capture the implicit global structure that underlies many creative tasks. Again, we have a forthcoming blog post that dives into this, but for now please check out our paper for various nuanced comparisons between next-token and multi-token learning across tasks and model scales.
While continuing to squeeze performance from today’s best practices makes sense, genuine progress will require fresh architectures and training paradigms that tackle the root shortcomings we have surfaced. To that end, we invite you to experiment with our spherical cow benchmarks, stress test your ideas, and refine the promising approaches sketched in our papers.