| Assigners/Receivers Set |
Before reading this section, an understanding of the u-model is recommended. The u-model in Nl-Soar is an attribute-value structure that has to be anchored in some way to the problem space state. The anchoring mechanism used here is known as the A/R set (Lewis, 1993). The A/R set provides sufficient discrimination to avoid the expensive chunk problem and yet is functionally adapted to the parsing process so that relevant chunks in the u-model are directly accessible.
Explanation of the theory behind A/R set
The main idea behind the A/R set is the indexing of lexical entries by the potential syntactic relations that they may enter into. We set up potential links in the u-model by directly pairing up assigners and receivers indexed by the same relation. If, for example, we have a potential assigner that can assign a spec-IP relation and a potential receiver that can receive a spec-IP relation, then a potential link is proposed. This link will then undergo constraints checks to ensure that it is legitimate. Once a link is made, the receiving node is removed from the receivers set for all relations, since a node can only have one parent in the tree. However, we have not removed the assigners node from the assigners sets for two reasons. One, they provide an efficient access mechanism for any process that works on partially completed syntactic structures and two, they provide the access to the u-model during interpretation. If both assigners and receivers nodes are removed from the A/R set once after links are etablished, we would not be able access the A/R set for later work.
The REAL A/R set implementation
There is one important constraint on the construction of the A/R set: Each syntactic relation can only be associated with at most two words. If a new word comes in and it can be indexed by the same syntactic relation, then the least recent word to have that relation would on longer be indexed with that relation. This is what is commonly known as the "magic number two". For example, assuming that "square" and "table" have already been parsed (in that order), then the assigners set would contain the two above words for the relation spec-NP. At a later stage of parsing, if NL-Soar encounters a new noun, say "John", then the relation spec-NP will on longer be associated with "square". Instead, spec-NP will have "table" and "John".
In NL-Soar, this "magic number two" idea is currently implemented using two multi-attributes: assigners and receivers . Each time a new word is put on the A/R set during access , the number 2 is checked. If it is exceeded then the access operator will not be reconsidered and the ar-set problem-space will be proposed.
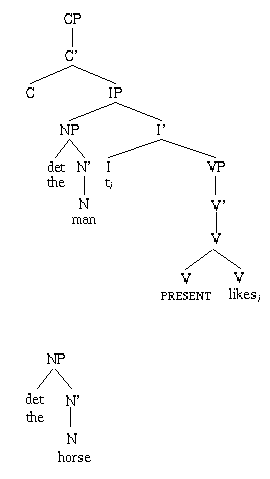
Having said that, let's take a look at the tree formed and the state of the A/R set during the parsing of "the man likes the horse.", just after the [NP the horse] has been formed and just before attaching [NP the horse] in the complement position of [V' likes].
assigners
(A2 ^a A3 ^adv A4 ^c C1 ^det D1 ^i I2 ^n N1 ^p P2 ^v V3)
(A3 ^max A5 ^one A6 ^zero A7)
(A5)
(A6)
(A7)
(C1 ^max C2 ^one C3 ^zero C4)
(C2 ^adjoin C76 ^head C76 ^missing-receiver-relations adjoin
^missing-receiver-relations head ^spec C76)
(C3 ^comp C75 ^missing-receiver-relations comp)
(C4)
(I2 ^max I3 ^one I4 ^zero I5)
(I3 ^adjoin I44 ^head I44 ^missing-receiver-relations adjoin
^missing-receiver-relations head ^spec I44)
(I4 ^adjoin I46 ^comp I46 ^head I46 ^missing-receiver-relations comp
^missing-receiver-relations adjoin ^missing-receiver-relations head)
(I5)
(N1 ^max N2 ^one N3 ^zero N4)
(N2 ^adjoin X4 ^adjoin X10 ^head X4 ^head X10
^missing-receiver-relations adjoin ^missing-receiver-relations spec
^missing-receiver-relations head ^spec X10 ^spec X4)
(N3 ^adjoin X3 ^adjoin X9 ^head X9 ^head X3
^missing-receiver-relations head ^missing-receiver-relations adjoin)
(N4 ^adjoin P138 ^adjoin P40 ^missing-receiver-relations adjoin)
(P2 ^max P3 ^one P4 ^zero P5)
(P3)
(P4)
(P5)
(V3 ^max V4 ^one V5 ^zero V6)
(V4 ^adjoin X6 ^head X6 ^missing-receiver-relations adjoin
^missing-receiver-relations spec ^missing-receiver-relations head
^spec X6)
(V5 ^adjoin X5 ^comp X5 ^head X5 ^missing-receiver-relations adjoin
^missing-receiver-relations head)
(V6 ^adjoin E26 ^missing-receiver-relations adjoin)
(D1 ^max D2 ^one D3 ^zero D4)
(D2 ^adjoin X2 ^adjoin X8 ^head X2 ^head X8
^missing-receiver-relations adjoin ^missing-receiver-relations head
^missing-receiver-relations spec ^spec X8 ^spec X2)
(D3 ^adjoin X1 ^adjoin X7 ^head X7 ^head X1
^missing-receiver-relations adjoin ^missing-receiver-relations head)
(D4 ^adjoin P137 ^adjoin P18 ^missing-receiver-relations adjoin)
(A4 ^max A8 ^one A9 ^zero A10)
(A8)
(A9)
(A10)
Receivers
(R1 ^a A11 ^adv A12 ^c C5 ^det D5 ^i I6 ^n N5 ^p P6 ^v V7)
(A11 ^max A13 ^one A14 ^zero A15)
(A13)
(A14)
(A15)
(C5 ^max C6 ^one C7 ^zero C8)
(C6 ^spec X10)
(C7)
(C8)
(I6 ^max I7 ^one I8 ^zero I9)
(I7 ^adjoin C76 ^head I46 ^missing-assigner-relations head
^missing-assigner-relations adjoin ^spec X10)
(I8)
(I9)
(N5 ^max N6 ^one N7 ^zero N8)
(N6)
(N7 ^adjoin C76 ^comp C76 ^missing-assigner-relations comp
^missing-assigner-relations adjoin)
(N8)
(P6 ^max P7 ^one P8 ^zero P9)
(P7)
(P8 ^comp X10 ^missing-assigner-relations comp)
(P9)
(V7 ^max V8 ^one V9 ^zero V10)
(V8)
(V9 ^comp C76 ^comp X10 ^comp2 C76 ^comp2 X10
^missing-assigner-relations comp2 ^missing-assigner-relations comp)
(V10)
(D5 ^max D6 ^one D7 ^zero D8)
(D6)
(D7)
(D8)
(A12 ^max A16 ^one A17 ^zero A18)
(A16)
(A17)
(A18)
We realize that the above A/R set structure does not look simple but hopefully after the following explanation, things will look clearer. We want to alert the reader that there is a slight difference between the assigners set and receivers set but we will not try to explain this difference now as it will make more sense later on. Also, we will ignore the ^missing-{assigner,receiver}-relations flags in our discussion. These are needed for the bead operator and are discussed there.
We will take a look at the assigners set now. The first level of each set tells us the name of the set in the working memory and the values of seven top level attributes, viz., ^a(djective), ^c(omplement),^i(nflection),^n(oun), ^p(reposition),^v(erb),^det(erminer). Thus, the first level of assigners is
Let's look at what V1, the value of ^V(erb), is:
(V1 ^max V2 ^one V3 ^zero V4)
(V2 ^head X6 ^spec X6 ^adjoin X6)
(V3 ^head X5 ^comp X5 ^adjoin X5)
(V4 ^adjoin E26)
Every value that hangs off V2 is a VP node (knowledge of Chomsky's X-bar theory is assumed). Similarly, every value that hangs off V3 is a V' node and every value that hangs off V4 is a V node. For example, X6 is a VP node and X5 is a V' node. Each attribute hanging off V2, V3 or V4 represents a syntactic relation that the value of the attribute can assign. Thus, X5 is a V' node that can assign a complement position to an appropriate node in the receivers set. Theoritically speaking, X5 is indexed by the syntactic relation comp-V' in the assigners set. If we look at the tree structure above, X5 is the V' projection of the verb [V likes]. It is indeed looking for an appropriate complement.
We will turn our attention to receivers set. The attribute-value pairs on the first level is the same as that of the assigners set. Thus, the first level of receivers is
(R1 ^a A7 ^c C5 ^i I7 ^n N5 ^p P8 ^v V5 ^det D5)
Here is what V5 represents in the working memory:
(V5 ^max V6 ^one V7 ^zero V8)
(V6)
(V7 ^comp X10 ^comp2 X10)
(V8)
In constrast to the assigners set, each value hanging V6 is NOT a VP node; and
each value hanging off V7 and V8 is not a V' and V node respectively. This is
the difference we talked about above. So, a value hanging off V6 means that it can
receive a syntactic relation from an appropriate VP node in the assigners set.
These values can be any node. What is important is NOT what they are but what they
can receive. For example, X10 hangs off V7 and it is the value of the attribute
^comp. Hence, we know that X10 can be the complement of an appropriate
V' node in the assigners set. (It can also be the 2nd complement of a V' node).
Theoritically speaking, X10 is indexed by the syntactic relation comp-V'
in the receivers set. Referring back to our tree structure, X10 is the node
[NP the horse]. Notice what we are building up here is the fact that a potential link can be proposed between X5, [V' likes], and X10, [NP the horse]. In fact, NL-Soar really proposes that link and after being constraints-checked, the link is implemented. This is what the final tree looks like:

Back to the problem-space hierarchy.
This page written by Jill Fain Lehman (jef@cs.cmu.edu) and Han Ming Ong (hanming@cs.cmu.edu)
Note: The ideas behind the A/R set and "the magic number two" come from Rick's thesis (Lewis, An Architecturally-based theory of Human Sentence Comprehension, 1993)