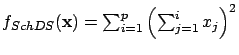Next: Evolutionary Algorithm Up: CIXL2: A Crossover Operator Previous: Crossover Dynamics
That is the reason why, when an algorithm is evaluated, we must look for the kind of problems where its performance is good, in order to characterize the type of problems for which the algorithm is suitable. In this way, we have made a previous study of the functions to be optimized for constructing a test set with fewer functions and a better selection [WMRD95,Sal96]. This allows us to obtain conclusions of the performance of the algorithm depending on the type of function.
Taking into account this reasoning, the test set designed by Eiben and
Bäck [EB97b] is very adequate. The test set has several well
characterized functions that will allow us to obtain and generalize,
as far as possible, the results regarding the kind of function
involved. Nevertheless, we have added two functions to the test set
with the aim of balancing the number of functions of each kind. These
two new functions are the function of Rosenbrock [Ros60]
extended to ![]() dimensions and the function of Schwefel
[Sch81]; both of them have been widely used in evolutive
optimization literature. Table 1 shows the
expression of each function and a summary of its features:
separability, multimodality, and regularity.
dimensions and the function of Schwefel
[Sch81]; both of them have been widely used in evolutive
optimization literature. Table 1 shows the
expression of each function and a summary of its features:
separability, multimodality, and regularity.
A function is multimodal if it has two or more local optima. A function of
![]() variables is separable if it can be rewritten as a sum of
variables is separable if it can be rewritten as a sum of ![]() functions of just one variable [Had64]. The separability is
closely related to the concept of epistasis or interrelation among the
variables of the function. In the field of evolutionary computation,
the epistasis measures how much the contribution of a gene to the
fitness of the individual depends on the values of other genes.
functions of just one variable [Had64]. The separability is
closely related to the concept of epistasis or interrelation among the
variables of the function. In the field of evolutionary computation,
the epistasis measures how much the contribution of a gene to the
fitness of the individual depends on the values of other genes.
Non separable functions are more difficult to optimize as the accurate search direction depends on two or more genes. On the other hand, separable functions can be optimized for each variable in turn. The problem is even more difficult if the function is also multimodal. The search process must be able to avoid the regions around local minima in order to approximate, as far as possible, the global optimum. The most complex case appears when the local optima are randomly distributed in the search space.
The dimensionality of the search space is another important factor in
the complexity of the problem. A study of the
dimensionality problem and its features was carried out by
Friedman [Fri94]. In order to
establish the same degree of difficulty in all the problems, we have
chosen a search space of dimensionality ![]() for all the
functions.
for all the
functions.
Sphere function has been used in the development of the theory of
evolutionary strategies [Rec73], and in the evaluation of
genetic algorithms as part of the test set proposed by De Jong
[De 75]. Sphere, or De Jong's function F1, is a simple and
strongly convex function. Schwefel's double sum function was proposed
by Schwefel [Sch95]. Its main difficulty is that its gradient is not
oriented along their axis due to the epistasis among their variables;
in this way, the algorithms that use the gradient converge very
slowly. Rosenbrock function [Ros60], or De Jong's
function F2, is a two dimensional function with a deep valley with the
shape of a parabola of the form ![]() that leads to the global
minimum. Due to the non-linearity of the valley, many algorithms
converge slowly because they change the direction of the search
repeatedly. The extended version of this function was proposed by
Spedicato [Spe75]. Other versions have been proposed
[Ore74,Dix74]. It is considered by many authors as a
challenge for any optimization algorithm [SV94].
Its difficulty is mainly due to the non-linear interaction among its
variables.
that leads to the global
minimum. Due to the non-linearity of the valley, many algorithms
converge slowly because they change the direction of the search
repeatedly. The extended version of this function was proposed by
Spedicato [Spe75]. Other versions have been proposed
[Ore74,Dix74]. It is considered by many authors as a
challenge for any optimization algorithm [SV94].
Its difficulty is mainly due to the non-linear interaction among its
variables.
Rastrigin function [Ras74] was constructed from Sphere
adding a modulator term
![]() . Its contour is
made up of a large number of local minima whose value increases with
the distance to the global minimum. The surface of Schwefel function
[Sch81] is composed of a great number of peaks and valleys.
The function has a second best minimum far from the global minimum
where many search algorithms are trapped. Moreover, the global minimum
is near the bounds of the domain.
. Its contour is
made up of a large number of local minima whose value increases with
the distance to the global minimum. The surface of Schwefel function
[Sch81] is composed of a great number of peaks and valleys.
The function has a second best minimum far from the global minimum
where many search algorithms are trapped. Moreover, the global minimum
is near the bounds of the domain.
Ackley, originally proposed by Ackley [Ack87] and generalized by Bäck [BS93], has an exponential term that covers its surface with numerous local minima. The complexity of this function is moderated. An algorithm that only uses the gradient steepest descent will be trapped in a local optima, but any search strategy that analyzes a wider region will be able to cross the valley among the optima and achieve better results. In order to obtain good results for this function, the search strategy must combine the exploratory and exploitative components efficiently. Griewangk function [BFM97] has a product term that introduces interdependence among the variables. The aim is the failure of the techniques that optimize each variable independently. As in Ackley function, the optima of Griewangk function are regularly distributed.
The functions of Fletcher-Powell [FP63] and Langerman
[BDL+96] are highly multimodal, as Ackley and Griewangk, but
they are non-symmetrical and their local optima are randomly
distributed. In this way, the objective function has no implicit
symmetry advantages that might simplify optimization for certain
algorithms. Fletcher-Powel function achieves the random distribution
of the optima choosing the values of the matrixes
![]() and
and
![]() , and of the vector
, and of the vector
![]() at random. We have
used the values provided by Bäck [Bäc96]. For Langerman function, we
have used the values of
at random. We have
used the values provided by Bäck [Bäc96]. For Langerman function, we
have used the values of
![]() and
and
![]() referenced by Eiben and
Bäck [EB97b].
referenced by Eiben and
Bäck [EB97b].
Domingo 2005-07-11