Abstract
While much work has been done on extracting information from documents there are few example systems that define a generic methodology for grouping the extracted fields into a record structure. Generally, systems assume either that an entire web page is a single record, or that a contiguous block of fields represent a record. These assumptions often fail to correctly model a significant number of interesting extraction problems that occur in practice. For example sometimes fields must be grouped from multiple page, or in another case a common field is only given once for all records on a page.
The contribution of this paper is the definition of a small language that suitably represents the common cases of grouping extracted fields. The grouping language was used to describe two different domains (job postings and product information) from over 500 different web sites. In all cases the rules were expressive enough to accurately represent the relationship between fields in order to correctly group them into records.
1 Introduction
One of the primary goals of information extraction[1] is to transform unstructured (or semi-structured) data into a highly structured format such as a relational database. In order to accomplish this goal an information extraction system must first devise an algorithm for finding the relevant data and applying the appropriate field type. Then the data is usually transferred to a structured representation such as a database or XML document. Often times the extracted fields have relationships to, and dependences with, each other. For example in the case of extracting name-title pairs it is vital that the correct name is matched with the correct title. For this reason (borrowing from the database metaphor) a single name-title pair can be thought of as a record containing two associated fields. In the name-title example it is fairly easy to code a programming rule based upon some criteria, such as proximity of the fields, in order to produce the correct grouping. However, the complexity of a record schema plays a direct relationship to the complexity of the logic for correctly grouping fields into a record. For example if the extracted data includes not just a name and title, but other fields such as office phone number, home phone number, prior work experience, and email address. Additionally, if there are multiple records per document then some sort of segmentation must be conducted[2].
The problem of grouping fields is further complicated by the fact that often times records in a single document contain shared fields. For example a single field at the top of a document might provide the manufacture name for all of the products listed in the document. Additionally, related fields may not even be contained in the document where the majority of the record data is located. These disjoint fields may be in referenced (descendant) documents, or in documents (ancestors) that refer to the document containing the record. An example of this case is a web site that has a page listing links to pages containing job postings. For each link the geographic location of the job is listed. Each of the job posting pages gives the title of the job and a description, but then link to a sub-page that contains the email address of the person to submit resume information to. Taking this a step further there could be a field that needs to be grouped with every record extracted from a web site, or collection of co-referenced documents, that is several levels of indirection away. For example the product support telephone number for a company’s products may be listed on a completely different section of a web site then the actual products themselves.
1.1 Illustrative Example
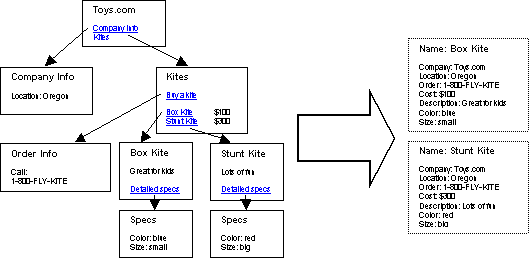
Figure 1 shows a theoretical web site from which product information needs to be extracted. The relevant fields to extract include: Product name, company location, order contact, cost, description, and specific specification fields. The common information extraction task is to correctly identify and label each of these fields. The next step is to correctly group the fields into the records displayed on the left of Figure 1. Since the required fields are scattered across multiple pages grouping the fields becomes a non-trivial problem. For example the company location must be shared with all records extracted from the site. The sales phone number for purchasing kites is different than one for ordering other products and so it must only be grouped with kite records. The product price is not found on the page that contains the main product information, but on the one that links to it. Finally, the detailed specifications are on a secondary page.
The real problem illustrated by this example is not that it is impossible to group disjoint or shared fields, but to come up with a solution that is expressive enough to be used generically across domains. The solution must also be simple enough that it can fit easily into many extraction systems, regardless if system is a rote extraction program, or a fully inductive system.
|
|
|
Figure 1 – Example Web Site |
1.2 Field Grouping Rules
As a solution to the complex field grouping problem this work contributes the definition of a small language for grouping fields into records. This language defines not only how to deal with shared and disjoint fields, but also how to segment records that appear in documents that contain multiple record. It should be noted that this paper is not an attempt to define an extraction system, but to define grouping expressions that can be learned along with extraction rules. The grouping expressions and extraction rules are then used in conjunction with each other to extract data from a corpus of documents into highly structured records. The lack of the definition of an extraction system should not be seen as a disadvantage, but as a key advantage. Being that its utility is not tied to a specific architecture or domain.
1.3 Related Work
Much work has been done in the field of information extraction in general and specifically from the World Wide Web[1]. Generally these systems have some sort of mechanism for handling field grouping. The simplest form of field grouping occurs when there is only one field in a record. This is common in systems trying to solve problems like the MUC named entity task as is shown by the Collins/Singer named entity extractor[3]. The next level of complexity comes from systems trying to compose simple record based upon the field proximity. In systems like this it is often sufficient to either build the segmentation of records and grouping based upon some simple record schema, or to actually use the co-appearance of fields as criteria for extracting fields. This is exemplified by systems such as Brin’s[4] pattern extraction framework that was used to find book titles and authors, or Kushmerick’s wrapper induction technique[5].
Several natural language processing (NLP) systems[10] have been successful at establishing the relationship between fields by using grammatical clues. However, often times, as is the case with web pages, the proper grammatical structure is missing and replaced with formatting and structural clues. Soderland[11] suggested a system called Webfoot for alleviating this problem, but did not to extend the process to include disjoint, or off page, fields.
Other common approaches assume that records are contiguous and therefore can be expressed as hierarchical containers[6][7] [8]. As demonstrated above this assumption does not always hold for many interesting extraction problems.
One wrapper induction system that does relax the assumption that records are contiguous is described by Embley/Xu[9]. They describe a system that begins by segmenting web pages into records, assuming that related fields are nearby, and then incrementally modifies the segmentation by moving extracted information around from references pages and nearby records. This reshuffling process is guided by a metric on record quality based on the database scheme. If the record more closely resembles the expected record schema then the manipulation is accepted. In experiments this procedure found acceptable groupings most (but not all of the time).
Embley/Xu’s efforts are the perhaps most related to the contributions given in this paper. However, their system appears to assume that a relatively rich record scheme is available---a scheme rich enough to guide the reshuffling process. It also does not allow data to moved arbitrarily far across a web site structure. More importantly, their system is different in kind from the one described here. Whereas Embly/Xu propose a general-purpose, site-independent method for grouping records, we propose a specific language for specifying groupings. By allowing a use to provide that site-specific grouping information, it is possible for data from particular sites to be grouped with essentially no errors. The grouping language could also be used to specify site-independent grouping heuristics, although to date we have not explored this possibility in depth.
Another approach to grouping data is to use general-purpose mechanisms for grouping. For instance, in extracting data for the WHIRL system[13], database joins were used to group information in different pages; in the WWKB project [14], arbitrary relations between extracted fields were learned from examples. (For example, the relation “teaches(Professor, Course) “might be learned from examples. These powerful grouping methods have a disadvantage in that they require either programming (in the case of the joins used in WHIRL) or detailed training data across tuples of objects (in the case of the WWBK project’s approach). In comparison to these systems, the main advantage of our system is the simplicity of the language and the ease with which is can be learned. Below we will show that despite the language’s simplicity it has the ability to cover a large assortment of practical grouping problems.
The remainder of this paper explains the details of and experiments conducted with the grouping language. Section 2 defines the grammar and semantics of the language as well as many of its key benefits. Section 3 explains how the grouping language was implemented using an “industrial-strength” wrapper-learning system called Wrapster. The empirical results of using Wrapster in two different domains covering more than 500 web sites are also presented. Finally, section 4 discusses conclusions, limitations, and possibilities for further improvement.
2 Definition of The Grouping Language
Every extracted field may have a single expression associated with it that is derived from the grouping language. An expression defines how to group the field with other fields and how records should be segmented and defined. The grouping languages primary purpose is to define the relationship between fields in the set F and records in the set R. The key to understanding the languages power is to visualize a collection of inter-referenced document, or web site, as an organized tree structure. In this context it can always be said that an ordered traversal of the tree will dictate that field x is either before or after field y. The ordering of the site then enables the ability to define the scope that a field is active in. All fields that share scope are considered to be in the same record.
Scope is defined in several different ways. The field can be grouped either with fields before or after it in the same document, with descendant documents that are referenced either before or after it, or with ancestor documents that directly or indirectly reference the document that contains the field in question. When a field’s scope is defined to extend within the same document then a parameter is given that tells when the field’s scope should end. When fields are grouped with ancestor or descendant documents then the field is grouped with every extracted record in those documents.
The language also provides a mechanism for segmenting multi-record documents. Segmentation is accomplished by specifying as part of the grouping expression that a field is the start of a record. Specifying a field as a starting field of a record causes a new record to be generated that contains all of the fields in the grouping. Have multiple record starts within the same grouping serves to define sub records.
The complexity of the grouping language can be calculated for any given domain. There are 5 different scope operations that act on p page types and f field names. The size of p is dependant on the complexity the document collection and the representation using by the implementation. The size of f is dependant on the record schema for the domain of interest. Additionally, f can be used in a set S thus increasing its complexity to f!. This means that the complexity Clang of the language can be expressed as:
![]()
with the 2 multiplier existing because of the option of having a record start token. In practice the values of p and f is actually quite low. For example in the job postings domain there f was equal to 5, and p was ?. Additionally, in only 15 out of 856 expressions was the size of S larger than one, and in those cases they were always 2. This effectively removes the factorial making the final complexity of the language for the job posting domain 2(5)(?), or .
2.1 Grammar
The formal grouping language grammar has the following syntax as shown below. The semantics of the language are also discussed below and summarized in Table 1.
EXPRESSION ® SCOPE:PARAMETER[:recordstart]
SCOPE ® prev|next|prevlink|nextlink|pagetype
PARAMETER ® FIELDNAMES|PAGETYPE
FIELDNAMES ® FIELDNAME[|FIELDNAME]*
FIELDNAME ® any valid field name
PAGETYPE ® any valid page type
In this language every expression first defines the scope of the field. Since the document collection is defined as a tree structure (with both inter-document references and document structure representing the nodes of the tree), all scope is relative to the field’s location in that tree as an ordered traversal is conducted. The scope can take to forms: 1) inner document scope, or 2) external document scope. Inner document scope is represented by the prev and next tokens. Meaning that the scope of the field extends to other fields that appear before or after the field respectively. External document scope is represented by the prevlink, nextlink, and pagetype tokens. The prevlink and nextlink tokens mean that the scope of field is transferred to all descendant documents whose references (or links) appear before or after the field respectively. The use of the pagetype token means that the scope of this field is transferred to an ancestor or self page type and then to all of that pages descendants. The meaning of a “page type” is defined by the implementing application. Some possible meanings include a specific or generalized URL, or an assigned document classification. However, regardless of the meaning of “page type” the system must somehow keep track of the referrers of a document according to some definition, so that the ancestor relationship can be established.
Each of the scope tokens takes a parameter. This parameter defines how to limit the scope of the grouping. For the prev, next, prevlink, and nextlink tokens the parameter means group this field with all fields up until, and excluding, a field of the name given in the parameter is encountered. For the pagetype token the parameter means that the field scope only extends to, and including, an ancestor document with a page type given by the parameter. Additionally, for all external document scopes the scope extends to all fields found in descendant document. This is important for cases where you want to group a field with every record in a collection. This is done by setting the scope to the page type of the top-most document in the collection.
|
Token |
Purpose |
|
SCOPE |
Scope may be any of the following: · prev – Group
with previous fields. · next – Group
with following fields. · prevlink – Group
with previous documents references. · nextlink – Group
with following document references. · pagetype – Group
with ancestor documents. |
|
PARAMETER |
Defines how
to limit the scope. |
|
FIELDNAME |
Any set of
field name as defined by the record schema. |
|
PAGETYPE |
Ancestor
document classification. |
|
recordstart |
Start a new
record or sub record. |
|
Table 1 – Language Semantics |
|
2.2 Example Grouping Rules
This section provides examples of some possible grouping rules. The examples all extend from the site defined in the illustrative example given in section 1.1.
|
Example 1: This example shows the simple case of handling a contiguous multi-record document. Here the next grouping scope is applied to the product name field in order to group every following field until the next product name field is encountered. Because the recordstart option is also given each instance of a Name field signifies a new record. |
|
|
Example 2: In this example the Name field is alternatively extracted from the Box Kite page and designated as the start of a record. The Cost field from the parent Products page is also pulled down using the prevlink scope. Because the scope is restricted by the Cost field parameter the prices are only grouped with their corresponding products. |
|
|
Example 3: The addition of the pagetype scope for the color and size specification fields promotes their scope pages that are classified as Product pages, which in this example is represent by the Box Kite page. The remaining fields could also be grouped in a similar fashion, as illustrated below, to create a complete record. pagetype:HomePage applied to Company field |
|


2.3 Key Advantages
One of the advantages of the grouping language is its simplicity. As noted above, for a fixed domain, there are a small finite number of legal grouping expressions. One implication of this is that if a user wishes to specify how extracted data is to be grouped together, he or she need only assign the proper grouping expression to each extracted field. Because there are a small number of expressions it is feasible to assign these grouping expressions with a graphical user interface (GUI).
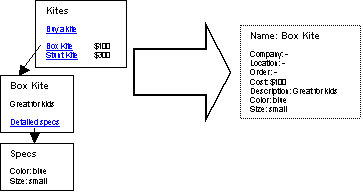
In our work, grouping rules were implemented as part of learning web site wrapping system[12]. The wrapping system includes a GUI that allows a human user label a few training pages on a web site. The highlights the data to be extracted, and specifies not only the field name, but also a grouping rule (if necessary). This was done visually through a simple menu selection for a field as shown in Figure 2.
After labeling, example labels and grouping rules are passed to the learning system, which creates a hypothesis, marks up unseen pages and displays them for user validation. Here again the simplicity of the grouping language is important; since the learner need only assign a label from a fixed set, ordinary classification learning can be used to automatically assign grouping expressions. In our system each extraction rule is associated with a single class label that combines the type of the data extracted (e.g., “product name” or “job title”) with the grouping expression to be associated with that field. To test the correctness of the grouping rules, the user may interactively request that the current hypothesis execute against all or a portion of the site so the completed records may be viewed in their collated (grouped) format.
|
|
|
Figure 2 – Visually Assigning Grouping Rules |

In this system, grouping rules are learned on a site-by-site basis. Another possible approach to grouping would be to construct a site-independent grouping heuristic, such as that proposed by Embley/Xu. One way to construct such a system would be to use the same user labels, but aggregate the training data over many sites, and use this data to train a site-independent classifier that associates extracted fields with the appropriate grouping expressions.
3 Experimental Evaluation
The grouping language described so far is simple, but not very expressive. An important question is the following: to what extent can real-world web sites be wrapped using this set of grouping rules? In other words, is the language expressive enough to handle real grouping problems?
To answer this question, the system was used to wrap 499 corporate web sites in order to extract their job information. Out of the 499 sites wrapped there was only one site that the grouping rules could not express. On this site it was necessary to have a scope overridden if a field with a cardinality constraint is observed multiple times (e.g., location is in Atlanta unless otherwise noted.) This is more of an implementation detail than a flaw in the grouping rules, but does reveal an important consideration. Some interesting statistics from the experiment are shown in Table 2. Figure 3 shows the distribution of rule scopes.
|
|
||||||||||||||||||||||||
|
Table 2 – Job Posting Extraction Statistics |
Figure 3 – Scope Usage |
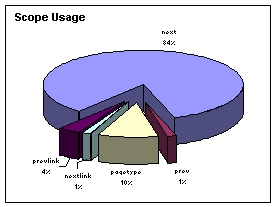
These statistics suggest some interesting information. First of all the high usage of the next scope (84%) indicates that most records are simple, or contiguous in nature and only require simple grouping. However, a full 15% of other fields did require some more complex scope in order to fully express the record. Of these other scope types pagetype was used 10% of the time suggesting the important need to associate fields in some sort of global scope. This is also important because the only other known system[9] that does complex field grouping did not allow for this type of representation.
From the results of the job postings domain suggests that even though grouping rules are fairly simplistic in nature they are expressive enough to cover the vast majority of practical extraction tasks. In order to insure that these results were not specific to the domain of job postings another 10 corporate sites were chosen and examined for extraction of product information. From this smaller sample set it was shown that every site could be expressed with the grouping rules. If fact it appears that in comparison, job postings is a more complex grouping task thus the larger experiment is a good validation of their usefulness.
4 Conclusion
With the demonstrated success[1] of information extraction systems to accurately find and extracted fields it becomes clear that the next step is to develop algorithms for grouping fields into record structures. Currently the most common answers to this problem are to either hard code grouping rules for a particular domain, or make naïve assumptions about the contiguous nature of record fields. The work presented in this paper presents a system capable of accurately describing complex shared and disjoint fields in a simple precise methodology.
There are obvious limitations to the grouping rules presented here. The most obvious one is that it lacks the expressive power of a domain-crafted solution. However, as was shown with the success of the job posting and product information domains it appears that often times a domain specific solution is not necessary. There are other limitations of the grouping rules are discussed below and serve as good candidates for future research:
· Data listed in columns. In some domains tables are used extensively for displaying information. A common paradigm is to display the fields for a record in columnar fashion, with each column represented a distinct record. The current definition of grouping rules uses document order as the criteria for grouping. However, document order in this case would interleave the columnar records. A simple solution to this problem is to extend the grammar to include a column scope that would group all fields in the same column of a table.
· Enforcing a record schema. A simple record schema could be used in conjunction with the extraction and grouping. This would allow for the enforcement of cardinality constraints and field type inclusion. For example if in the schema a field is defined with a cardinality of one and there were two fields of that type in the same grouping then the closest field to the record start could overshadow the other.
· Producing sub records. Sometimes records are not flat in nature and need to contain sub records. For example when a job posting has multiple locations. It is often convenient to express each location as a sub record containing the fields city, state, and country. This should be possible by allowing for multiple record starts with in a single grouping. An additional record start would signify that a sub record was being defined. This could also be done with the record schema as discussed in the previous point. While this functionality was discussed as part of the grammar in section 2.1, it was never implemented as part of the experimental system and therefore left as future research.
References
[1] Line Eikvil. Information Extraction from World Wide Web - A Survey. Report #945, July, 1999. ISBN 82-539-0429-0
[2] Record-Boundary Discovery in Web Documents, by D.W. Embley, Y.S. Jiang, and W.-K. Ng, SIGMOD'99 Proceedings
[3] M. Collins and Y. Singer. 1999. Unsupervised models for named entity classification. In Proceedings of the Joint SIGDAT Coneference on Empirical Methods in Natural Language Processing and Very Large Corpora, pages 100-110.
[4] S. Brin. Extracting patterns and relations from the World Wide Web. In Proceedings of the WebDB Workshop (at EDBT'98), 1998
[5] N. Kushmerick, D. Weld, and R. Doorenbos. Wrapper induction for information extraction. In Proceedings of the 1997 International Joint Conference on Artificial Intelligence, pages 729--735, 1997
[6] Adelberg, B. (1998). NoDoSE - A Tool for Semi-Automatically Extracting Structured and Semistructured Data from Text Documents. In L. Haas, A. Tiwary, eds., Proc. SIGMOD'98,ACM SIGMOD Record, Vol. 25, pp. 283-294, ACM Press.
[7] Kushmerick, N., Weld, D., Doorenbos, R. (1997). Wrapper Induction for Information Extraction. International Joint Conference on Artificial Intelligence 729-735
[8] Ashish, N., & Knoblock, C. (1997). Wrapper generation for semistructured Internet sources. Proceedings of the Workshop on Management of Semistructured Data. Tucson, Arizona: Available on-line from http://www.research.att.com/~suciu/workshop- papers.html
[9] Record Location and Reconfiguration in Unstructured Multiple-Record Web Documents, by D.W. Embley and Li Xu, WebDB'00 Proceedings
[10] NLP assocation of fields paper
[11] Soderland S. Learning to extract text-based information from the World-Wide Web. In Proceedings of the Third International Conference on Knowledge Discovery and Data Mining, KDD-97, pages 251--254, Newport Beach, California, August 1997.
[12] Reference the other wrapster paper here.
[13] William W. Cohen WHIRL:
A Word-based Information Representation Language, submitted for journal
publication. From Artificial Intelligence, 118, page 163-196.
[14] Learning
to Extract Symbolic Knowledge from the World Wide Web.
M. Craven, D. DiPasquo, D. Freitag, A. McCallum, T. Mitchell, K. Nigam and S.
Slattery.
Proceedings of the 15th National Conference on Artificial Intelligence
(AAAI-98).