|
Home
Projects
Publications
Resources
Contact |
|
Research Areas
Computer Vision, Graphics, Medical Image Analysis, Biometrics, Machine Learning, Computer Animation, and Augmented Reality.
Research Projects

|
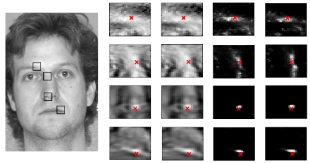
Non-rigid Face Tracking with Local Appearance Consistency Constraint
By utilizing both
spatial and temporal appearance coherence at the patch
level, the proposed approach can reduce ambiguity and increase
accuracy. Recent research demonstrates that feature
based approaches, such as constrained local models
(CLMs), can achieve good performance in non-rigid object
alignment/tracking using local region descriptors and a
non-rigid shape prior. However, the matching performance
of the learned generic patch experts is susceptible to local
appearance ambiguity. Since there is no motion continuity
constraint between neighboring frames of the same sequence,
the resultant object alignment might not be consistent
from frame to frame and the motion field is not temporally
smooth. In this paper, we extend the CLM method into
the spatio-temporal domain by enforcing the appearance
consistency constraint of each local patch between neighboring
frames. More importantly, we show that the global
warp update can be optimized jointly in an efficient manner
using convex quadratic fitting....
[paper:FG'08]
|
|
Enforcing Convexity for Improved Alignment with Constrained Local Models
Constrained local models (CLMs) have recently demonstrated
good performance in non-rigid object alignment/
tracking in comparison to leading holistic approaches
(e.g., AAMs). A major problem hindering the development
of CLMs further, for non-rigid object alignment/tracking, is
how to jointly optimize the global warp update across all
local search responses. Previous methods have either used
general purpose optimizers (e.g., simplex methods) or graph
based optimization techniques. Unfortunately, problems exist
with both these approaches when applied to CLMs. In
this paper, we propose a new approach for optimizing the
global warp update in an efficient manner by enforcing convexity
at each local patch response surface. Furthermore,
we show that the classic Lucas-Kanade approach to gradient
descent image alignment can be viewed as a special
case of our proposed framework....
[paper:CVPR'08]
|
|
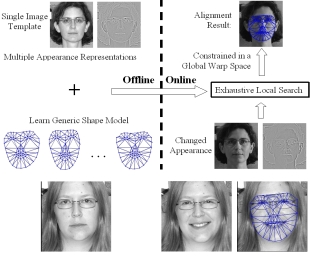
Non-Rigid Object Alignment with a Mismatch Template Based on Exhaustive Local Search
Non-rigid object alignment is especially challenging
when only a single appearance template is available and
target and template images fail to match. Two sources of
discrepancy between target and template are changes in
illumination and non-rigid motion. Because most existing
methods rely on a holistic representation for the alignment
process, they require multiple training images to capture
appearance variance. We developed a patch-based
method that requires only a single appearance template of
the object. Specifically, we fit the patch-based face model
to an unseen image using an exhaustive local search and
constrain the local warp updates within a global warping
space. Our approach is not limited to intensity values or
gradients, and therefore offers a natural framework to integrate
multiple local features, such as filter responses, to
increase robustness to large initialization error, illumination
changes and non-rigid deformations...
[paper:NRTL'07]
|

|
Face Re-Lighting from a Single Image under Harsh Lighting Conditions
We present a new method to change the illumination
condition of a face image, with unknown face geometry and albedo
information. This problem is particularly difficult when there is
only one single image of the subject available and it was taken
under a harsh lighting condition. Recent research demonstrates that
the set of images of a convex Lambertian object obtained under a
wide variety of lighting conditions can be approximated accurately
by a low-dimensional linear subspace using spherical harmonic
representation. However, the approximation error can be large under
harsh lighting conditions thus making it
difficult to recover albedo information. In order to address this
problem, we propose a subregion based framework that uses a Markov
Random Field to model the statistical distribution and spatial
coherence of face texture, which makes our approach not only robust
to harsh lighting conditions, but insensitive to partial occlusions
as well...
[
demo:mov],
[paper:CVPR'07]
|
 |
3D Surface Matching and Recognition Using Conformal Geometry
3D surface matching is a fundamental issue in computer vision
with many applications such as shape registration, 3D object recognition and classification.
However, surface matching with noise, occlusion and clutter is a challenging problem.
In this paper, we analyze a family of conformal geometric maps including harmonic maps,
conformal maps and least squares conformal maps with regards to 3D surface matching.
As a result, we propose a novel and computationally efficient surface matching framework by using least squares conformal maps...
[
demo:avi],
[
Paper:CVPR'06,
ICCV'07,
PAMI
]
|
|
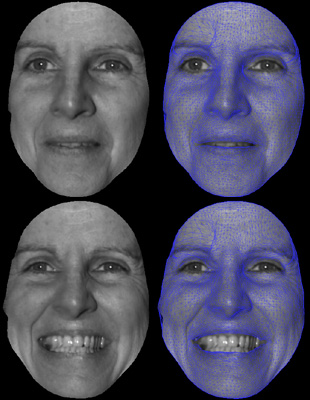
High Resolution Tracking of Non-Rigid 3D Motion of Densely Sampled Data Using Harmonic Maps
We present a novel fully automatic method for high resolution,
non-rigid dense 3D point tracking. The novelty of this paper is the development of an algorithmic framework
for 3D tracking that unifies tracking of intensity and geometric
features, using harmonic maps with added feature correspondence
constraints. While the previous uses of harmonic maps provided only
global alignment, the proposed introduction of interior feature
constraints guarantees that non-rigid deformations will be
accurately tracked as well. The harmonic map between two topological
disks is a diffeomorphism with minimal stretching energy and bounded
angle distortion. The map is stable, insensitive to resolution
changes and is robust to noise. Due to the strong implicit and
explicit smoothness constraints imposed by the algorithm and the
high-resolution data, the resulting registration/deformation field
is smooth, continuous and gives dense one-to-one inter-frame
correspondences. Our method is validated through a series of
experiments demonstrating its accuracy and efficiency...
[demo:avi], [paper:ICCV'05]
|
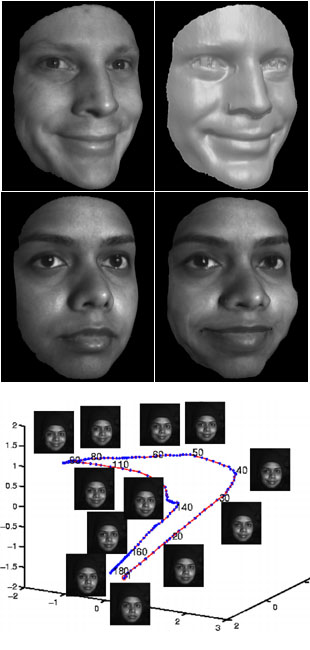 |
High Resolution Acquisition, Learning and Transfer of Dynamic 3-D Facial Expressions
Synthesis and re-targeting of facial expressions is central to
facial animation and often involves significant manual work
in order to achieve realistic expressions, due to the difficulty of
capturing high quality dynamic expression data. We address
fundamental issues regarding the use of high quality dense 3-D data
samples undergoing motions at video speeds, e.g. human facial expressions.
In order to utilize such data for motion analysis and re-targeting,
correspondences must be established between data in different frames of
the same faces as well as between different faces.
We present a data driven approach that consists of four parts:
1) High speed, high accuracy capture of moving faces without the use of markers,
2) Very precise tracking of facial motion using a multi-resolution deformable mesh,
3) A unified low dimensional mapping of dynamic facial motion that can separate expression style,
and 4) Synthesis of novel expressions as a combination of expression styles.
The accuracy and resolution of our method allows us to capture and track
subtle expression details. The low dimensional representation of motion data
in a unified embedding for all the subjects in the database allows
for learning the most discriminating characteristics of each
individual's expressions as that person's "expression style".
Thus new expressions can be synthesized, either as dynamic morphing between individuals,
or as expression transfer from a source face to a target face,
as demonstrated in a series of experiments...
[demo:avi1, avi2], [paper:EG'04]
|
 |
A Hierarchical Framework For High Resolution Facial Expression Tracking
We present a novel hierarchical framework for high resolution,
nonrigid facial expression tracking. The high quality dense point clouds of
facial geometry moving at video speeds are acquired using a phase-shifting
based structured light ranging technique. To use such data for temporal
study of the subtle dynamics in expressions and for face recognition,
an efficient nonrigid facial tracking algorithm is needed to establish
intra-frame correspondences. We propose such an algorithmic framework
that uses a multi-resolution 3D deformable face model,
and a hierarchical tracking scheme...
[paper:ANM'04]
|

|
Estimation of Multiple Directional Light Sources for Synthesis of Augmented Reality Images
We present a new method for the detection and estimation of
multiple directional illuminants, using a single image of any object
with known geometry and Lambertian reflectance. We use the resulting
highly accurate estimates to modify virtually the illumination
and geometry of a real scene and produce correctly illuminated
Augmented Reality images. Our method obviates the need to modify
the imaged scene by inserting calibration objects of any particular
geometry, relying instead on partial knowledge of the geometry of the scene.
Thus, the recovered multiple illuminants can be used both for image-based
rendering and for shape reconstruction. Our method combines information
both from the shading of the object and from shadows cast on the scene by the object...
[paper:
PG'02,
GM
]
|

|
Estimation of Multiple Illuminants from a Single Image of Arbitrary Known Geometry
We present a method for the detection and estimation of multiple illuminants,
using one image of any object with known geometry and Lambertian reflectance.
Our method obviates the need to modify the imaged scene by inserting calibration
objects of any particular geometry, relying instead on partial knowledge of the geometry of the scene...
[paper:ECCV'02]
|

|
Brookhaven National Laboratory (BNL) BME Project
Developing an integrated CCD-based image capture
and motion tracking system, a core research of novel technologies
for Positron Emission Temography (PET) and functional Magnetic
Resonance Imaging (MRI) that will allow imaging of the awake animal
brain in real-time and in natural physiological conditions. Knowing
the brains position at any point in time will make is possible to
compensate for its motion, either during the data acquisition or
reconstruction phase of MRI and MicroPET scans.
|
|
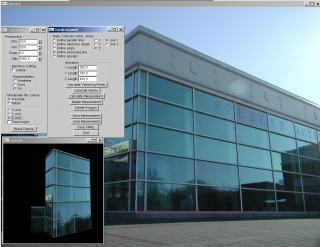
Single View Metrology Project
In the light of the algorithm described in "Single View Metrology"
by Criminisi, Reid, and Zisserman, ICCV 1999,
we developed a system that can reconstruct 3D texture-mapped models
from a single image and user interactions...
more
|
|
