
Today we will learn how to create a Hidden Markov Model (HMM) that can be used to describes word sequences.
Hidden Markov Models (HMMs) are a statistical approach to model time varying observations. An HMM consist of states, transitions with probabilities between these states and conditional probabilities for observations in a given state and inital states (see picture).
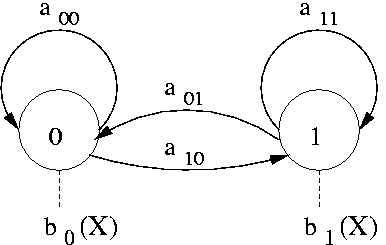
In the paper from Lawrence Rabiner "A Tutorial on Hidden Markov Models with Selected Applications in Speech Recognition" a good introduction to this problems are given and well explained how they are solved. This paper can be found at wiki-pedia under http://en.wikipedia.org/wiki/Hidden_Markov_models. Another good introduction is given in chapter 8 of the Book "Spoken Language Processing" from Xuendong Huand, Alex Acero and Hsiao-Wuen Hon.
Question 4-1: Why is it a bad idea to model words e.g. "cat" and "act" with a single GMM each (= 1-State HMM for each word)?
In the following, we will sketch how an HMM is build from a given transcription:
In an ideal case we know the "meaning" of states in a HMM. In speech recognition the most popular HMM-topologie is the 3-state left-to-right model. It is used to model phonemes. Usual the states are named like Begin, Middle and End. The idea here is that the glide into the phoneme sounds different than the phoneme itself or the transition out of the phoneme. In addition the number of states impose a minimum duration (depending of the topologie). Because we use demi-sylables, which in average consist of more than one phoneme, we use more states for the finals. If we assume that a final e.g. consit of 2 phonems we would model them in a system with phoneme units with 6 states compared to 4 states in this approach. To choose the right topology is an important step, often the less constraining models perform better, because wrong assumtions about constraints hurt often more than a less precise model.
![]()
For the Mandarin recognition system, we want to model Initials with a 3-state left-to-right topology, Finals with a 4-state left-to-right topology and silence with a 1-state topology as indicated in the pictures above.
We start with a Context Independent (CI) Acoustic Model (AM). That means that the GMM assigned to a HMM-state depends only on the current phoneme and the current state.
Janus is a very flexible tool and therefore the creation of an HMM-object is complex. To decide what topology and what acoustic model is assigned to a HMM-state two Decision-Trees are used. The decisions are based on questions about the phonetic context and tags.
The following picture shows the dependencies of the objects involved in creating a HMM-object.

We already know some of the objects: Tags, Phones, PhonesSet, Dictionary, FeatureSet, CodebookSet and DistribSet.
The topologie of the HMM is derived from the folowing janus objects: Dictionary, (AMoldelSet), TopoTree, TopoSet, TmSet Which GMMs are assigned to a certain HMM-state is controlled by the following janus objects: SenoneSet, DistribStream, DistribTree.
# create and load Tags PhonesSet and Dictionary (from homework 2)
Tags tags
tags read tags.desc
PhonesSet phonesSet
phonesSet read phones_set.desc
# phonesSet:PHONES is of type Phones with all the .
Dictionary dict phonesSet:PHONES tags
dict read dictionary.desc
# create FeatureSet and load the feature description file (from homework 3)
FeatureSet fs
fs setDesc @./featDesc
# create the objects for the GMMs
CodebookSet cbs fs
DistribSet dss cbs
# create some (empty) GMM models
foreach p [phonesSet:PHONES] {
if {$p == "@"} continue
foreach s {s1 s2 s3 s4} {
cbs add $p-$s FEAT 1 26 DIAGONAL
dss add $p-$s $p-$s
}
}
# the padPhone is a place holder used to answer context questions
# Tree requires an index in the Phones-object
Tree dssTree phonesSet:PHONES phonesSet tags dss -padPhone [phonesSet:PHONES index @]
# The tree we are building here is only an example!!!
dssTree add -help
#Options of 'add' are:
# <nodeName> name of the node (string:"NULL")
# <question> question string (string:"NULL")
# <noNode> NO successor node (string:"NULL")
# <yesNode> YES successor node (string:"NULL")
# <undefNode> UNDEF successor node (string:"NULL")
# <model> name of the model (string:"NULL")
# -ptree name of the ptree
# for each state we plan to have we need a entry node
# bacause we maintain multiple trees in one data structure
dssTree add ROOT-s1 {} - - - -
dssTree add ROOT-s2 {} - - - -
dssTree add ROOT-s3 {} - - - -
dssTree add ROOT-s4 {} - - - -
dssTree:ROOT-s1 configure
# a leaf node has no question but a model name assigned
dssTree add LEAF-SIL-s1 {} - - - SIL-s1
dssTree add LEAF-SIL-s2 {} - - - SIL-s2
dssTree add LEAF-SIL-s3 {} - - - SIL-s3
dssTree add LEAF-SIL-s4 {} - - - SIL-s4
dssTree add LEAF-a-s1 {} - - - a-s1
dssTree add LEAF-a-s2 {} - - - a-s2
dssTree add LEAF-a-s3 {} - - - a-s3
dssTree add LEAF-a-s4 {} - - - a-s4
dssTree add HOOK-SIL-s1 "0=SIL" LEAF-a-s1 LEAF-SIL-s1 - -
dssTree add HOOK-SIL-s2 "0=SIL" LEAF-a-s2 LEAF-SIL-s2 - -
dssTree add HOOK-SIL-s3 "0=SIL" LEAF-a-s3 LEAF-SIL-s3 - -
dssTree add HOOK-SIL-s4 "0=SIL" LEAF-a-s4 LEAF-SIL-s4 - -
#
# "0=SIL" is a question that asks if the center phoneme is "SIL"
# Instead of tags or phonemes it is also possible to ask for entries from the PhonesSet
# Conjunction: "0=a 0=WB" asks if the center phoneme is "a" and is at the word boundary
# Disjunction: "0=T1 | 0=T2" asks if the center phoneme has tone 2 or 3
#
# display the trees as a tcl list
dssTree list
# This will be our entry nodes for different states
# This means we have multiple trees in one data structure
dssTree add ROOT-s1 {} HOOK-SIL-s1 HOOK-SIL-s1 HOOK-SIL-s1 -
dssTree add ROOT-s2 {} HOOK-SIL-s2 HOOK-SIL-s2 HOOK-SIL-s2 -
dssTree add ROOT-s3 {} HOOK-SIL-s3 HOOK-SIL-s3 HOOK-SIL-s3 -
dssTree add ROOT-s4 {} HOOK-SIL-s4 HOOK-SIL-s4 HOOK-SIL-s4 -
# Adding the same node again will overwrite old settings!
dssTree:ROOT-s1 configure
# List the tree as a TCL-list
dssTree list
# with the method write the tree can be stored
dssTree write distribTree-example.desc.gz
# Please, take a look at the output file
# To query the Tree a phonetic context has to be provided.
#
# Phonetic context are passed to decition trees as a list of tagged phones
# with a start index (left offset) and an end index (right offset) e.g.
# "{SIL WB}" 0 0
# index 0
# "{ z WB} { uo T4} { iong T4 WB}" -1 1
# index -1 0 1 <- the phoneme that get index 0 assigned is the center phoneme
#
# In the tree above the question {0=SIL} asked if the center phoneme is "SIL"
# a question {-2=a} would ask for the phoneme two left of the center phoneme to be "a"
# if the question reach outside the provided context and a padding phone is configured
# the padding phone is used instead to answer the question
# with no padding phone configured the undef-branch is selected.
#
# the method "get" traverse the tree from the given node and returns the index of the leaf-node
dssTree get ROOT-s1 "{SIL WB}" 0 0 -node 1
# uo with tone 4 and a left context of z at the word boundary and a right context iong which has tone 4 and is also a word boundary
# -1 is the index of the forst element 1 the index of the last element
# the element with the index 0 represents the center phone or also the current phone
dssTree get ROOT-s1 "{ z WB} { uo T4} { iong T4 WB}" -1 1 -node 1
# well this is only an example tree (the full tree is part of the home work)
#
# Question 4-2: What happen if we try to add an element that refere to a (distrib-)model that do not exist? (e.g. dummy-s1)
#
# Task 4-1: write a procedure that add a phone to a tree
# dssTree.
# -> modelSet questionSet ptreeSet list
# dssTree.modelSet configure
# dssTree.modelSet type
dssTree -help
# puts displays the contents of a tree object
# add add a new node to the tree
# read read a tree from a file
# write write a tree into a file
# list list a tree contents in TCL list format
# get descend a tree for a given phone sequence
# trace trace a tree for a given phone sequence
# index return the index of a node
# name return the name of an indexed node
# question return best splitting question to ask
# split split node according to a question
# cluster split whole subtree of a given root node
# transform transform tree for modalities
# The Stream is a abstract layer that can answeres which model should be used in a certain context
# and allows the computation of scores (negativ log likelihood)
# With this layer it is possible to combine scores from multiple streams in one score for a given state of an HMM
# The DistribStream is a realisation of a Stream.
DistribStream dsStream dss dssTree
dsStream -help
# puts
# index returns indices of named distributions
# name returns names of indexed distributions
# get returns a distribution given a tagged phone sequence
# score compute distribution score
# accu accumulate sufficient statistic
# update update distributions/codebook
# The SenoneSet combine scores of multiple streams into one score
# we only use one stream (dsStream) and therefor don't have to set weights to mix the scores
SenoneSet sns -help
# Options of 'sns' are:
# <name> name of the senones set (string:"sns")
# <streamArray> list of {stream [-streamType ST] [-weight W]}
# -phones set of phones (Phones:)
# -tags set of tags (Tags:)
SenoneSet sns {dsStream}
#
# The TmSet (transition model set) stores the transitions with probabilties that can be used to build an HMM
#
TmSet tmSet
tmSet -help
# DESCRIPTION
# A TmSet is a set of state transition model objects (Tm)
# METHODS
# puts displays the contents of a transition model
# add add a Tm to the list
# read reads a TmSet from a file
# write writes a TmSet to a file
# index return index of named Tm(s)
# name return the name of indexed Tm(s)
tmSet add -help
set tProb [expr -log(0.5)]
# The transitions are relative
# that means that a 0 referes to a self-look and a 1 jumpes to the next state (index)
# a -1 means a jump backward
tmSet add 01 "{0 $tProb} {1 $tProb}"
tmSet:01
TopoSet topoSet -help
# Options of 'topoSet' are:
# <name> name of the topo set (string:"topoSet")
# <SenoneSet> senone set (SenoneSet:)
# <TmSet> set of transition models (TmSet:)
TopoSet topoSet sns tmSet
topoSet add -help
# Options of 'add' are:
# <name> name of topology (string:"NULL")
# <senoneTag*> sequence to senonic tree nodes
# <tmSet*> sequence to transitions
topoSet add 1-STATE {ROOT-s1} {01}
topoSet add 3-STATE {ROOT-s1 ROOT-s2 ROOT-s3} {01 01 01}
topoSet add 4-STATE {ROOT-s1 ROOT-s2 ROOT-s3 ROOT-s4} {01 01 01 01}
#
# If a state has a transition that reach outside the current HMM topology it points to a virtual state N+1.
# It is assumed that the inital state of an element in the TopoSet is the state with index 0!
# In other HMM tools like e.g. HTK a virtual state 0 exist which allows to have more than one inital state.
#
topoSet:3-STATE
topoSet:3-STATE configure
Tree topoTree -help
# Options of 'topoTree' are:
# <name> name of the tree (string:"topoTree")
# <phones> set of phones (Phones:)
# <phonesSet> set of phone set (PhonesSet:)
# <tags> set of tags (Tags:)
# <modelSet> model set
# -padPhone padding phone index (int:-1)
# the selection of the right toplogy is done by a decition tree (same object as above but different underlying model)
Tree topoTree phonesSet:PHONES phonesSet tags topoSet -padPhone [phonesSet:PHONES index @]

#
# this description creates selects between 1, 3 and 4 state topologies
#
topoTree add LEAF-1-STATE {} - - - 1-STATE
topoTree add LEAF-3-STATE {} - - - 3-STATE
topoTree add LEAF-4-STATE {} - - - 4-STATE
topoTree add HOOK-SILENCE {0=SILENCE} HOOK-FINALS LEAF-1-STATE - -
topoTree add HOOK-FINALS {0=FINALS} HOOK-INITIALS LEAF-4-STATE - -
topoTree add HOOK-INITIALS {0=INITIALS} LEAF-ERROR LEAF-3-STATE - -
topoTree add ROOT {} HOOK-SILENCE HOOK-SILENCE HOOK-SILENCE -
topoTree list
# A Tree-object has some sub-objects
# the Ptree will be explained later during the creation of context dependent models
# the QuestionSet is used to store the questions used in the Tree
topoTree.
# modelSet questionSet ptreeSet item(0..7) list
topoTree.questionSet
# list the questions, with ":" access-method it is possible to see how the questions are stored
# Janus provides the showSTree procedure to plot a tree.
treeDisplay topoTree ROOT
# Question nodes are yellow and leaf are light red
# Click with the left mouse button at a node (left/right beside the text) and the node is expanded/collapsed
# Nodes also have a pull down menue from which allow you to display more information
# treeDisplay can be used for all kind of Tree-objects
# AModelSet is another layer (because of the generic tree)
# It mainly defines the root and queries the decition tree for the HMM for which it provides information
# how many states what transitions and models are needed to build a HMM for a given word sequence
#
AModelSet ams -help
# Options of 'ams' are:
# <name> name of the amodel set (string:"ams")
# <TTree> topology tree (Tree:)
# <TTreeRoot> root name in TTree (string:"NULL")
# -durationTree duration tree (Tree:)
# -durationRoot duration tree root (string:"NULL")
# -contextCache 1 = create context cache (int:0)
AModelSet ams topoTree ROOT
#
# Finaly we can create a janus HMM-object
#
HMM hmm -help
# Options of 'hmm' are:
# <name> name of the HMM (string:"hmm")
# <dictionary> name of the Dictionary object (Dictionary:)
# <amodelset> name of the AmodelSet object (AModelSet:)
HMM hmm dict ams
# Let us create a HMM for the example given above
hmm make "zhao4kai1 can2"
hmm.wordGraph
# {zhao4kai1 can2} { {{1 0.000000}} {{1 0.000000}}} {0}
hmm.phoneGraph
# {zh ao k ai c an} ; mono-phones of the phone-graph the number correspond to the states of the graph
# {32 8 0 33 32 34} ; tag of the phone (bit set) -> the 3 phone has no tag, c has tag with index 4 set (starting with 0)
# { {{1 0.000000}} {{1 0.000000}} {{1 0.000000}} {{1 0.000000}} {{1 0.000000}} {{1 0.000000}}} ; for each phonem a list of transitions with a penalty (transitions are relative!)
# {0} ; list of start phonemes
# {2 3 2 3 2 3} ; index of model in the AModelSet
# {0 0 0 0 1 1} ; for each phone of phone-graph the index of word in word-graph
hmm.stateGraph
# States with the name of models in SenoneSet (not the DistribSet!)
{a-s1 a-s2 a-s3 a-s1 a-s2 a-s3 a-s4 a-s1 a-s2 a-s3 a-s1 a-s2 a-s3 a-s4 a-s1 a-s2 a-s3 a-s1 a-s2 a-s3 a-s4}
# For each state a list of transitions with penalties
{ {{0 0.693147} {1 0.693147}} {{0 0.693147} {1 0.693147}} {{0 0.693147} {1 0.693147}} {{0 0.693147} {1 0.693147}} {{0 0.693147} {1 0.693147}} {{0 0.693147} {1 0.693147}} {{0 0.693147} {1 0.693147}} {{0 0.693147} {1 0.693147}} {{0 0.693147} {1 0.693147}} {{0 0.693147} {1 0.693147}} {{0 0.693147} {1 0.693147}} {{0 0.693147} {1 0.693147}} {{0 0.693147} {1 0.693147}} {{0 0.693147} {1 0.693147}} {{0 0.693147} {1 0.693147}} {{0 0.693147} {1 0.693147}} {{0 0.693147} {1 0.693147}} {{0 0.693147} {1 0.693147}} {{0 0.693147} {1 0.693147}} {{0 0.693147} {1 0.693147}} {{0 0.693147} {1 0.693147}}}
{0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0} ; index of transition model in TmSet used for the corresponding state
{0} ; list of initial states
{0 0 0 1 1 1 1 2 2 2 3 3 3 3 4 4 4 5 5 5 5} ; for each state the index in the phoneGraph
{0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 1 1 1 1 1 1} ; for each state the index in the wordGraph
# Question 4-3: Why is the HMM give above not suitable for our data?
# ony way to solve it is adding a silence-word at the beginnig and the end
hmm make "$ zhao4kai1 can2 $"
hmm.wordGraph
# {{$} zhao4kai1 can2 {$}} { {{1 0.000000}} {{1 0.000000}} {{1 0.000000}} {{1 0.000000}}} {0}
# another is to add an optional silence
hmm make "zhao4kai1 can2" -opt $
hmm.wordGraph
# {{$} zhao4kai1 {$} can2 {$}} { {{1 0.000000}} {{1 0.000000} {2 0.000000}} {{1 0.000000}} {{1 0.000000} {2 0.000000}} {{1 0.000000}}} {0 1}
# Task 4-2: Draw the word/phone graph to the HMM above.
Task 4-3: Create the description (TopoSet, TmSet) for the HMM-topologies shown in the picture below?
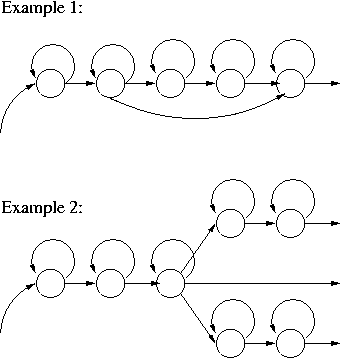
Task 4-4 (Homework): Write a script that creates distribTree and also all distribuions and codebooks required for a context independent speech recognizer using demi-sylables without tone information. Initialize the GMMs with the speech/silence models from the last home work. (Details from Stan)
xQuestion 4-4: What would you want to used different GMMs for different tones of the same demi-sylable.
Last modified: Tue Jan 10 01:36:28 EST 2006
Maintainer: tschaaf@cs.cmu.edu.