RESEARCH
SAMPLES
PAPERS
PEOPLE
HOME

5. Generating Explanatory Captions
A high level overview of the system divided into functional modules is shown in Figure 17. A brief description of each module is given below. Detailed descriptions follow later in the section.
|
Data attribute |
Graphical element |
Complexity type |
|
temperature |
grapheme, property |
encoding complexity range complexity |
|
troop size |
grapheme, property |
grapheme complexity composition complexity (i) |
|
start-position |
grapheme, property |
grapheme complexity composition complexity (i) |
|
stop-position |
grapheme, property |
grapheme complexity composition complexity (i) |
|
battle city |
grapheme, property |
composition complexity (c) ambiguous mapping |
|
battle date |
grapheme, property |
composition complexity (c) ambiguous mapping |
|
battle location |
grapheme |
composition complexity (c) |
Figure 15
Result of the complexity assignment module for the "Minard Graphic" in Figure 1 ("I" and "c" are used to indicate interfering and cooperating graphemes respectively).
|
Data attribute |
Graphical element |
Complexity type |
|
house |
grapheme, property |
alignment complexity |
|
asking price |
grapheme, property |
grapheme complexity ambiguous mapping composition complexity (i) |
|
selling price |
grapheme, property |
grapheme complexity ambiguous mapping composition complexity (i) |
|
agency estimate |
grapheme, property |
composition complexity (i) |
|
date on market |
grapheme, property |
grapheme complexity (c) ambiguous mapping |
|
date sold |
grapheme, property |
grapheme complexity (c) ambiguous mapping |
|
listing agency |
grapheme |
Figure 16
Result of the complexity assignment module for Figure 6.
Text Planning Module: The text planner takes as input the goal to generate a caption, the picture representation generated by sage (annotated by the complexity module), and generates a partially ordered text plan. The leaves of the text plan represent speech acts about propositions that need to be conveyed.
Ordering Module: The ordering module takes a partially ordered text plan and imposes a total order on the speech acts. This may be based on (i) domain specific knowledge about orderings (for instance, knowledge about temporal order of events), or in the absence of this, (ii) knowledge about graphics (e.g., the left edge of a bar is discussed before the right edge of a bar).
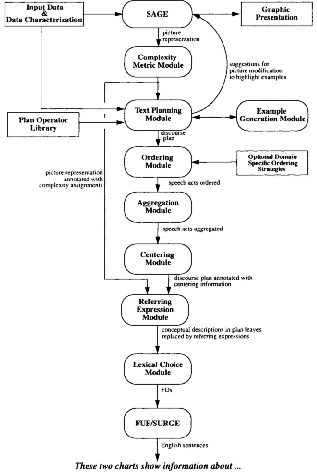
Figure 17
System architecture: A functional-block diagram
Aggregation Module: The output of the ordering module is passed to an aggregation module that can combine multiple propositions into fewer, more complex ones. For instance, the module may combine some propositions regarding a grapheme into one complex proposition for more natural output.
Centering Module: Once clauses are ordered and aggregated, coherence of the generated text can be further improved by selecting appropriate orderings between arguments of each clause. For this task, we have developed a selection strategy based on the centering model.
Referring Expression Module: The referring expression module analyzes the picture representation and uses the discourse plan to determine appropriate referring expressions for the concepts in the speech acts.
Lexical Choice and Realization Modules: This lexical choice module picks lexical items and transforms the speech acts to functional descriptors (FDs) to be processed by FUF/SURGE (Elhadad and Robin, 1992; Elhadad, 1992), the realization module used to generate the English text.
5.1 Text Planning Module
The planner constructs text plans from its library of discourse action descriptions. The representation of communicative action is separated into two types of operators: action operators and decomposition operators. Action operators capture the conditions (preconditions and constraints) under which an action can be executed, and the effects the action achieves if executed under the appropriate conditions. Preconditions specify conditions that the agent should plan to achieve (e.g., the hearer knows a certain term), while constraints specify conditions that the agent should not attempt to plan to change (e.g., facts and rules about the domain). Effects describe the changes that a discourse action is intended to have on the hearer's mental state. If an action is composite, there must be at least one decomposition operator indicating how to break the action down into more primitive steps. Each decomposition operator provides a partial specification for a sub-plan that can achieve the action's effects, provided the preconditions are true at the time the steps in the decomposition are executed.
As an example of how action and decomposition operators are used to encode discourse actions, consider the two operators in Figure 18. These two operators describe the discourse action
describe-space-mappings, whose only effect is achieving the state in which the reader knows all the data to grapheme mappings shown. The first operator is an action operator and it indicates that describe-space-mappings can be used to achieve the state where the reader knows about the mappings.
Figure 18
Sample Plan Operators.
The second operator in Figure 18 is one of the decomposition operators for the
describe-space-mappings action. The decomposition of a non-primitive action can be expressed either in terms of sub-actions (:steps slot), or in terms of sub-goals of one action's effect :rewrite slot), or in terms of both. For instance, the :rewrite slot of the decomposition in Figure 18 specifies that one way to achieve describe-space-mappings 's effect of having the hearer to know all the mappings in one space is to achieve the three sub-goals of having the hearer to know all the interfering, cooperating and vanilla mappings in that space. This example also illustrates how the graphical complexity metrics are used for content selection by the text planner: just as this operator can be used to describe spaces in which all three types of graphemes are present, there are other operators which deal specifically with encoder complexities, compositional complexities, etc.As illustrated by the second operator in Figure 18, decomposition operators may also have constraints, which indicate the conditions under which the decomposition may be applied. Such constraints often specify the type of information needed for particular communicative strategies, and satisfying them causes the planner to find content to be included in explanations. For example, the constraints of the second operator not only check that a single space is being described, but also find the graphemes of the three types used in the explanation, and the anchor-mapping in this space. When the planner attempts to use a decomposition operator, it must try to satisfy all of its constraints. If a constraint contains no unbound variables, it is simply checked against the knowledge source to which it refers. However, if the constraint contains free variables (e.g.,
?int-graphs in the second operator), the system must search its knowledge bases for acceptable bindings for these variables. In this way, satisfying constraints directs the planner to select appropriate content to include in explanations. In the case of the operator shown in Figure 18, the two preconditions that must be satisfied are (i) that the reader must be able to recognize the space (i.e., know which space is being discussed, and the data set being visualized), and (ii) know what the anchor mapping in the space is (if any). Anchor mappings refer to the mapping between a functionally independent attribute (FIA)--usually the key in the database schema--and the axis it is mapped to. Thus, action and decomposition operators specify how information can be combined in a discourse to achieve effects on the hearer's mental state.5.1.1 Generating Discourse Plans Planning begins when a set of communicative goals are posted to the text planner. The system generates a plan by iterating through a loop that refines the current plan (either decompositionally or causally), checking the plan after each refinement to ensure that it has not introduced any errors. Decompositional refinement selects a composite action and creates a sub-plan for that action by adding instances of the steps listed in the decomposition operator to the current plan. Causal refinement selects an unsatisfied precondition of a step in the plan and adds a causal link to establish the needed condition. This is done either by finding a step already in the plan that achieves the appropriate effect, or by using an action operator to create a new step that achieves the needed condition as one of its effects. For a complete definition of the algorithm, its computational properties, and its utility for discourse planning, see (Young, Pollack and Moore, 1994; Young and Moore, 1994).
In the remainder of the section, we present the modules that follow the text planning process and implement tactical decisions. To clarify the discussion, we describe how each module contributes to the generation of clauses (3) to (5) in the sample caption shown in Figure 19.
Sample caption
(1) This chart presents information about house sales from data-set TS-2480.
(2) The y-axis shows the houses.
(3) The house's selling price is shown by the left edge of the bar
(4) whereas the asking price is shown by the right edge.
(5) The horizontal position of the mark shows the agency estimate.)
Figure 19
A representative caption used to illustrate our discussions.
5.2 Ordering Module
The steps in a completed text plan are partially ordered, and thus further processing must be performed in order to generate a caption. The order of execution of steps in the plan may either be explicitly specified by the operator writer or may have constraints imposed on them by causal links. For instance, in the plan operator shown in Figure 18, all the steps corresponding to the goal
recognize-space will be ordered before the steps corresponding to the goal know-all-mappings because recognize-space is a precondition. However, most steps in the plan are not explicitly ordered and do not have causal links between them dictating the ordering. The ordering module takes as input the discourse plan, with links specifying the ordering relations between sub-trees, and orders the leaf nodes--the speech acts--based on a set of heuristics. In our application, for instance, unless otherwise indicated, the system will describe the "left edge of the bar" before the "right edge."The ordering module sorts first based on the space ordering. This is based on the assumption that in the absence of any other discourse strategy (such as the need to emphasize or compare properties of a concept across multiple spaces), the reader will browse the spaces from left to right. After the plan steps have been sorted on a space-by-space basis, the module sorts plan steps based on their graphical mappings, using the following ordering heuristics:
position > color > shape > size > text > others
Finally, within each resulting subset, the module orders steps by grapheme type using the following ordering:
line\ set > bar\ set > mark\ set > text\ set > others
The strategy of ordering first by graphical\ mapping and then by grapheme\ type is based on our analysis of hand generated captions. We found that most captions tended to be structured along the mappings rather than along the graphemes.
Let us now examine how the system's ordering rules determine the ordering among clauses 3-5 of the sample caption shown in Figure 19. First, clauses 3-5 are grouped together because they are all mappings to position. Second, clauses 3-4 precede clause 5 because bar\ set must precede mark\ set. Finally, clause 3 precedes clause 4, because of the conventional preference for left to right ordering between edges of floating bars.
So far, we have examined the ordering strategy that the system will follow by default. However, the ordering module can also take an optional input, a functional specification, which can be used to determine plan step orderings that do not conform with the default ordering. Using this optional specification, the system can take advantage of domain knowledge, such as temporal sequencing, which can play an important role in discourse sequence. For instance, in general it may be preferable to state the mappings of the left and right edges of a bar in that order. However, if the left edge of a bar indicates a house's selling-price and the right edge indicates the house's asking-price, the usual temporal ordering between the events would suggest that one discuss the asking-price before the selling-price, which in turn would lead to mentioning the right edge before the left edge, contrary to the default ordering.
5.3 Aggregation Module
Once the speech acts are ordered they are passed to the aggregation module. In the general case, aggregation in natural language is a very difficult problem (Dalianis, 1996; Shaw 1995; Huang and Fiedler, 1996). Fortunately, our generation task requires a type of aggregation that is relatively straightforward. Our aggregation strategy only conjoins pairs of contiguous propositions about the same grapheme type in the same space. The module checks for grapheme (types) rather than specific graphemes to cover circumstances where, for instance, a chart may have a number of grey and black bars (which are different graphemes of the same type). This enables the system to generate text of the form "The grey bars indicate the selling price of the house, whereas the black bars indicate the asking price."
When two propositions are combinable, namely they are about the same grapheme type in the same space, the system checks to see if the two properties being discussed are contrastive in some way. For instance, whether the two properties under consideration are the opposite edges of a bar, or are the X and Y axes, etc. If so, the system picks a contrastive cue phrase (e.g., "whereas") to merge the clauses resulting from the two propositions, otherwise the system picks the cue phrase "and."
Let us now briefly examine how aggregation affected clauses 3-5 of the sample caption in Figure 19. Clauses 3-4 were conjoined because they are about the same grapheme type, a horizontal bar, in the same space. Moreover, the module placed a "whereas" cue phrase between the two clauses, because the opposite edges of a bar are considered contrastive properties.
5.4 Centering Module
Once clauses are ordered and aggregated, coherence of the generated text can be further improved by selecting appropriate orderings between arguments of each clause. For this task, we have developed a selection strategy based on the centering model. Focus (e.g., (Sidner, 1979, Grosz, 1997)) and centering (e.g., (Grosz, Joshi and Weinstein 1995)) models are attempts at explaining linguistic and attentional factors that contribute to local coherence among utterances. Although focus and centering models were originally developed as foundations for understanding systems, they have frequently been proposed as effective knowledge sources for NLG systems. In particular, for (generating referring expressions) (including pronominalization) (see (Dale, 1992; Appelt, 1985; Maybury, 1991)), for (deciding when to combine clauses) (subordination and aggregation) (see (Derr and McKeown, 1984), and finally for choosing appropriate inter/intra clause orderings, namely, ordering between clauses and between their arguments (see (Maybury, 1991; Hovy and McCoy 1889; McKeown, 1985)).
Details on centering theory and its relation to discourse structure can be found in (Grosz, Joshi and Weinstein 1995, Walker 1993, Walker, Iida, and Cote, 1994, Grosz and Sidner, 1993, Gordon, Grosz, and Gilliom 1993); for lack of space in this paper, we only provide a minimal introduction to the basic terminology of centering theory.
Centers are semantic objects (not words, phrases, or syntactic forms) that link an utterance to other utterances in the same discourse segment. Centering theory provides definitions for three different centers, and for four possible center transitions between two adjacent utterances. It also states two fundamental constraints on center movement and realization.
Basic Center Definitions
- Cf(U): The set of forward-looking centers, which contains all the entities that can link the current utterance to the following one. It is not constrained by features of previous utterances. Elements of Cf(U are ordered; the major determinant of the ranking on the Cf(U) is grammatical role with subject > object > others.
- Cp(U): Highest ranking element of Cf(U)
- Cb(U): The backward-looking center (unique) is the highest ranking Cf(Ui-1) realized in the current utterance UI. Cb(U) is a discourse construct, therefore the same utterance in different discourse segments may have a different Cb.
Center Transitions: The four possible center transitions across pairs of utterances are shown in Table 1.

Table 1
Center transitions
The central tenet in centering theory is that discourse coherence of a text span increases (and a reader's cognitive load decreases) proportionately to the extent that discourse within the span follows two fundamental centering constraints (Grosz, Joshi and Weinstein 1995). These are:
Constraint on realization: If any element in the set of forward looking centers of an utterance (Ui) is realized by a pronoun in the following utterance (Ui+ 1), then the backward looking center of the following utterance (UI+ 1) must also be realized by a pronoun.
Constraint on movement:(i.e. centering transitions) Sequences of CONTINUATIONS are preferred over sequences of RETAININGs; and sequences of RETAININGs are preferred over sequences of SHIFTINGs (and consequently, smooth shifts are preferred over rough shifts).
Grosz and her colleagues suggest that a competent generation system should apply the constraint on movement by planning ahead in an attempt to minimize the number of SHIFTs in a locally coherent discourse segment (Grosz, Joshi and Weinstein 1995).
Our centering-based strategy implements this suggestion by selecting intra-clause orderings that enforce centering transitions consistent with a given discourse structure. The strategy is general and can be applied to any discourse structure, but to be effectively applied to the generation of captions some assumptions not supported in terms of centering theory must be made. The problem is that the NPs generated in the captions are often possessive and have complex syntactic structures (e.g., "the selling price of the house", "the mark's horizontal position") and centering theory is not yet clear on the determination of centers in complex syntactic structures such as possessives and subordinate clauses (Grosz and Sidner 1993). To accommodate for this problem we made two assumptions. First, given possessives of the form "property of grapheme/entity", either the grapheme or the entity is the center, not their properties. Secondly, even when only a property (e.g selling-price, right edge) is mentioned, the corresponding entity or grapheme is the center.
Our centering strategy processes the ordered speech acts sequentially and assumes that text spans describing the mappings from properties of a grapheme to properties of an entity are locally coherent discourse segments. The strategy enforces the constraint on movement within each of these discourse segments by preferring a continuation or a smooth-shifts transition to a retain or a rough-shift transition respectively. This is done by keeping the highest ranking forward-looking center of the first clause of the segment (which is either an entity or a grapheme), as the Cp(U_(i)) of all the following clauses in the same segment. In this way, in all such clauses the Cb(U_(i)) and the Cp(U_(i)) will be the same and, according to Table 1, this corresponds to forcing either continuations or smooth-shifts.
Furthermore, the strategy applies an additional constraint on movement: between segments dealing with different graphemes, the strategy explicitly marks the segment boundaries by rough-shift, smooth-shifts and retain over continuation. This case is not mentioned in (Grosz, Joshi and Weinstein 1995). However, since the system maintains local coherence in a segment by minimizing rough-Shifts and Retain s, it seems intuitive to prefer rough-shifts and retain s to emphasize the change at segment boundaries (i.e. the boundaries between such segments should be maximally incoherent). Thus, in the caption generation application, when a text span describing the mapping for a grapheme (a discourse segment) is followed by a description of a mapping for a different grapheme (another discourse segment), the centering strategy will try to force either a rough-shift or Retain to mark the segment boundary. This is done by moving the Cb(U_(i)) of the clause following the boundary out of the clause front position. That is, if the grapheme is the Cb(U_(i)), the domain entity is placed in front of the clause, and vice versa in the other case.
For example, consider the effect of the centering strategy on clauses 3-5 of the sample caption shown in Figure 19. Since clauses 3-4 are about mappings from properties of the same grapheme--a horizontal bar--they are assumed to belong to the same discourse segment. Therefore, the system keeps the Cp of clause (4) equal to the Cp of clause (3) by placing the possessive "the house's asking price" in front of the clause. In contrast, since clauses (4) and (5) are about mappings from properties of different graphemes, a retain centering transition was enforced (vs. a continuation) by moving the possessive corresponding to the Cb, "the house's agency estimate", out of the front position. Once intra-clause orderings are determined by the centering strategy, the annotated speech acts are passed to the referring expression module.
5.5 Referring Expression Module
The referring expression module is largely based on the algorithm for incremental interpretation described in (Dale and Reiter, 1995). The incremental interpretation algorithm can generate appropriate referring expressions by incrementally constructing a set of attributes that uniquely identify the desired referent. These identifying attributes are selected based on a domain specific default ordering. In our case, the only referential problem is identifying the graphemes, and often the type of the grapheme (e.g., "bar") is sufficient to do so. However, sometimes, a graphic may contain multiple graphemes of the same type. In such cases, the system must utilize additional perceptual properties (e.g., color, saturation, size, shape) to build an appropriate referring expression. For example, the referring expressions for the bars in the caption for the chart shown in Figure 20 use color as an additional identifying attribute.
Since our system generates multi-sentential captions, the referring expression module takes into account what is in focus at a given point in the discourse in order to generate concise and natural expressions. The referring expression module considers in focus all of the forward looking centers (i.e. Cf)computed by the centering module, and simply removes identifying attributes if they are in the Cfat that point in the discourse. This strategy results in the more concise rephrasing:
(3) The house's selling price is shown by the left edge of the bar (4) whereas the asking price is shown by the right edge. The horizontal position of the mark shows the agency estimate.
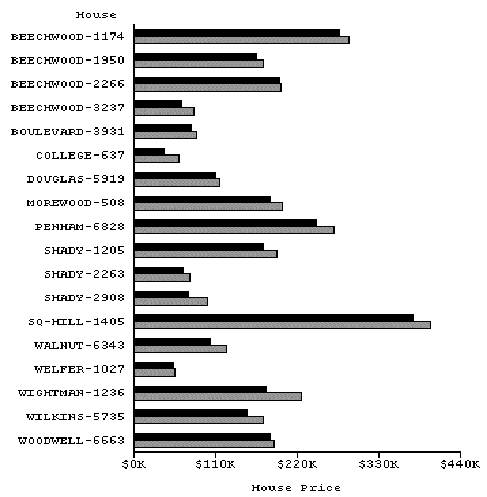
This chart presents informatin about house sales from data-set TS-1742. The Y-axis indicates the houses. The dark gray bar shows the house’s selling price whereas the black bar shows the asking price.
Figure 20
The referring expression module uses color in this case to distinguish between the two types of bars and the attributes mapped to them.
There are other forms of referring expression reduction due to discourse context that require a more sophisticated treatment. Hand written captions often radically simplify descriptions to express facts such as: "the third chart shows the neighborhood." However, the system generated caption would express the underlying proposition, based on the data to grapheme mappings, as: "the position of the mark in the third chart shows the neighborhood." The sequence of reductions shown below could achieve the more natural effect by repeatedly reasoning about the picture and the information being conveyed by each statement
the position of the mark in the third chart shows the neighborhood (1)
- the mark in the third chart shows the neighborhood (2)
- the third chart shows the neighborhood (3)
The system would need to realize that position was the only attribute of the mark being used for a mapping, and position is always clear in a graph and need not explicitly be mentioned; thus resulting in statement (2). However, since the mark is the only grapheme used in the graph, the system could leave off mentioning the mark as well, thus resulting in statement (3). There are two ways of dealing with this issue, (a) the system could apply iterative refinements of the referring expressions generated by the planner, as done in the local brevity algorithm (Reiter, 1990). However, this single case would have substantially increased the computational cost of generating referring expressions in all cases, without significantly improving any of the other (perfectly appropriate) referring expressions generated by the module, (b) the system could recognize this specific situation at a higher level and process the speech acts appropriately to avoid this situation completely. Thus, rather than considering this situation as a problem of generating an appropriate expression for the concept position of the mark in the third chart, we have chosen to push this problem up to the planner level during content selection. (Consequently, there are operators that look specifically for situations such as this--single grapheme in a space, mapping a single property--that are selected by the planner in such situations.) While this does tend to muddy the distinction between the "high-level" planner and the "lower-level" tactical processing--because the planner is now forced to deal with this one situation regarding referring expressions that should arguably be dealt with more properly by the referring-expression module--it does enable the system to generate appropriate texts with a simpler, more efficient approach in this application.
It should be noted that there is one additional type of referring expression that our system is capable of generating. This happens in situations when the graphic being explained is considered complex enough to require an example. In such cases, the system attempts to highlight the grapheme corresponding to the tuple being used in the example. There are a number of ways in which the relevant grapheme can be highlighted: with a graphical annotation, such as an arrow, a circle surrounding the grapheme, a change in color, etc.--with a corresponding number of ways in which the caption can then refer to the grapheme. This is similar to the approaches used for generating cross-modal references discussed in the context of the comet (McKeown et al., l992) and wip (André and Rist, 1994) projects. This will be illustrated in the next subsection which discusses the generation of examples.
5.6 Example Generation Module
If the text planner encounters particularly complex data to grapheme mappings, it can attempt to present an example to clarify the problematic mappings. Our current implementation is designed to trigger the example generation process in the case of interfering grapheme clusters where occlusion can hinder interpretation. Plan operators (described in Section 5.1) contain constraints that check for the appropriate conditions and establish goals for the generation of an example in the caption. In response, the example generation module selects a grapheme shown in the picture, finds the data values associated with the individual grapheme, and constructs an example that can be use by the text planner. Additionally, the example generator also posts a request to sage to highlight the relevant instance in the picture. If the highlighting request succeeds, the example generator annotates the example with this information and the resulting caption mentions the highlighted grapheme. Currently, this is the only case in which the caption generation mechanism can influence the graphic design. A caption fragment which includes an example is shown below:
For example, as shown in the highlighted tuple, 3237 Beechwood Boulevard's asking price is 79900 dollars and its selling price is 65000 dollars. Its agency estimate is 79781.625 dollars. Its neighborhood is Squirrel Hill.
There are a number of issues relevant to the generation of captions that integrate examples and text (Mittal and Paris, 1992; Mittal and Paris, I993). We will not discuss them here in detail because the context in which our current system generates explanations is very restricted (as compared to the general case of expository text in which examples are traditionally used when novel or abstract concepts are being introduced). The main difference between generating examples for purely textual descriptions and our current application is in the selection of values used for illustration: one of constraints in our current situation is the ability of the reader to identify the grapheme in question. Rather than use a strategy that finds and uses either extreme, limiting values or more prototypical values, the current application requires the selection of a grapheme that is easy to identify and interpret values mapped to it. To enable this, the system must be able to reason about individual graphemes as well as the picture as a whole: which graphemes are not crowded by other graphemes, are not too small, thin or otherwise unconventional to make interpretation difficult, have data values mapped to them that can be discussed in the caption , etc.
To next section.
Paper Sections:
To Title pageTo Part 1: Introduction
To Part 2: SAGE: A System for Automatic Graphical Explanations
To Part 3: Discourse Strategies for Generating Captions
To Part 4: Graphical Complexity: The Need for Clarification
To Part 6: System Implementation and Evaluation
To Part 7: Related Work
To Part 8: Conclusions and Future Work
To Appendix A
To Acknowledgements