 Structure of Horiz and ChemVert Phases
Structure of Horiz and ChemVert Phases In this project, we investigate how applications can be distributed over heterogeneous sets of systems connected by high-speed networks. We are using a particular scientific application, the Urban and Regional Multiscale (URM) Airshed model, to drive our work. We initially distributed the model by hand using PVM (Parallel Virtual Machine), and showed how exploiting a combination of task and data parallelism creates a parallel application that runs efficiently on a variety of parallel architectures. This effort also exposed some of the problems of writing distributed applications using explicit message passing. A variety of problems showed up as a result of different compilation and runtime environments and the need for different performance tradeoffs on each of the systems. We are currently working with the Fx parallelizing compiler group to automate some of these tasks.
The Airshed program spends most of its time in two main computational phases: a horizontal transport phase (Horiz), and a combined chemistry and vertical transport phase (ChemVert). Both phases can be solved using data parallelism, although they distribute the concentration array along different dimensions (see data-parallel speedups). In the case of ChemVert, the parallelism can simply be exploited using a DOALL loop across the grid cells. The nature of the parallelism in HORIZ is more complicated, since for each layer, during the first timestep of each hour, the global stiffness matrix is assembled from inputs (wind fields, geometry, etc.) and factored into LUD (Lower-Upper-Diagonal) components. The LUD factors are then used to perform the advective transport for the different species in the species loop. Since the stiffness matrix only changes once per hour, the same LUD factors are used for each timestep and each species in the layer. Since the two phases access the data structure in different ways, the two phases in the distributed implementation are separated by a global transpose.
Structure of Horiz and ChemVert Phases
The data parallelism in the Horiz and ChemVert routines is the main source of parallelism. However, many other forms of parallelism are available. They fall into two classes: parallelization of ``secondary'' tasks such as IO and communication, and pipelining of various preprocessing tasks with the main computation. None of these optimizations applied in isolation results in much parallel speedup, because each optimization applies to only a relatively small fraction of the sequential computation. However, when the data parallelism inside the Horiz and ChemVert is exploited, their impact is much larger, since their relative contributions to wall-clock time are higher.
The wide range of parallelism present in URM is by no means unique. Many other applications (especially other physical simulations based on multiple time scales or geometries) include different types of parallelism.
The above numbers support a number of observations. First, the two data parallel components have almost linear speed up in each of the environments that they were executed in (e.g. see ChemVert speedup graph, below). However, in an exclusively data-parallel paradigm, tasks that are not data-parallel play the same role that sequential computations play in Amdahl's law - they severely limit the overall application speedup. Some of these tasks have been parallelized using task parallelism in PVM. The results clearly show the need for an environment that exploits both data parallelism and different types of task parallelism.
 Task- and Data-Parallel Program Graph
Task- and Data-Parallel Program Graph
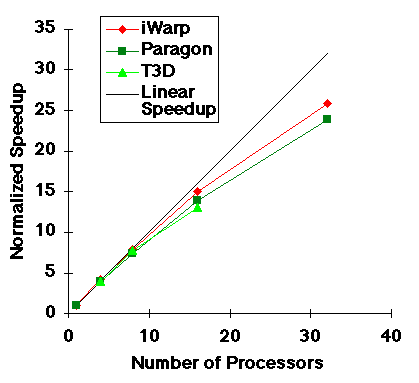 ChemVert Parallel Speedup
ChemVert Parallel Speedup