[This report is available as http://www.cs.cmu.edu/~ref/mlim/index.html .]
[It has now also been published, in Linguistica Computazionale, Volume XIV-XV, by the Insituti Editoriali e Poligrafici Internazionali, Pisa, Italy, ISSN 0392-6907.]
[It is also available as a single [very large] page: http://www.cs.cmu.edu/~ref/mlim/index.shtml .]
[Please send any comments to Robert Frederking (ref+@cs.cmu.edu, Web document maintainer) or Ed Hovy or Nancy Ide.]
Multilingual Information Management:
Current Levels and Future Abilities
A report
Commissioned by the US National Science Foundation
and also delivered to
the European Commission’s Language Engineering Office
and the US Defense Advanced Research Projects Agency
April 1999
Editors
:Eduard Hovy, USC Information Sciences Institute (co-chair)
Nancy Ide, Vassar College (co-chair)
Robert Frederking, Carnegie Mellon University
Joseph Mariani, LIMSI-CNRS
Antonio Zampolli, University of Pisa
Foreword
Gary W. Strong, DARPA and NSF, USA
The Internet is rapidly bringing to the foreground the need for people to be able to access and manage information in many different languages. Even in cases where people have been lucky enough to learn several languages, they will still need help in effectively participating in the global information society. There are simply too many different languages, and all of them are important to somebody.
While machine translation has a long (over 50 year) history, computer technology now appears ready for the next great push in technology for multilingual information access and management, particularly over the World Wide Web. The European Commission and several US agencies are taking bold steps to encourage research and development in multilingual information technologies. The EC and the US National Science Foundation, for example, have recently issued a joint call for Multilingual Information Access and Management research. The US Defense Advanced Research Projects Agency is supporting a new effort in Translingual Information Detection, Extraction, and Summarization research. Both of these efforts are direct results of international planning efforts, and this Granada effort in particular.
No one was more surprised than the Granada workshop participants were at the rapid uptake in interest in Multilingual Information Management research. Attendees of the workshop in Granada, Spain hardly had their bags unpacked when the results were requested to be presented in Washington DC at a National Academy of Sciences workshop on international research cooperation. The US White House expressed interest in the topic as a groundbreaking effort for a new US-EU Science Cooperation Agreement. Now, DARPA has decided to invest in a multi-year, large-scale effort to push the envelope on rapid development of multilingual capability in new language pairs.
The World is surely shrinking as communication and computation advances proceed at a breath-taking pace. On the other hand, there is no doubt that people will continue to hold on to the values and beliefs of their native cultures. This includes holding on to the language of their families and ancestors. This is a treasure, a cultural knowledge base that must not be weakened even as pressures to be able to speak common languages increase. Therefore, efforts in multilingual technology not only allow us to share knowledge and resources of the World, they also allow us to preserve our individual human qualities that have allowed us to progress and solve problems that we all share.
I thank all whose efforts have gone into this workshop report and the resource that it represents for future efforts in the field. Those who proceed to carry on the needed research and development being called for from around the world will surely find this report to be of great value.
Introduction: The Goals of the Report
Over the past 50 years, a variety of language-related capabilities has been developed in machine translation, information retrieval, speech recognition, text summarization, and so on. These applications rest upon a set of core techniques such as language modeling, information extraction, parsing, generation, and multimedia planning and integration; and they involve methods using statistics, rules, grammars, lexicons, ontologies, training techniques, and so on.
It is a puzzling fact that although all of this work deals with language in some form or other, the major applications have each developed a separate research field. For example, there is no reason why speech recognition techniques involving n-grams and hidden Markov models could not have been used in machine translation 15 years earlier than they were, or why some of the lexical and semantic insights from the subarea called Computational Linguistics are still not used in information retrieval.
This picture will rapidly change. The twin challenges of massive information overload via the web and ubiquitous computers present us with an unavoidable task: developing techniques to handle multilingual and multi-modal information robustly and efficiently, with as high quality performance as possible.
The most effective way for us to address such a mammoth task, and to ensure that our various techniques and applications fit together, is to start talking across the artificial research boundaries. Extending the current technologies will require integrating the various capabilities into multi-functional and multi-lingual natural language systems.
However, at this time there is no clear vision of how these technologies could or should be assembled into a coherent framework. What would be involved in connecting a speech recognition system to an information retrieval engine, and then using machine translation and summarization software to process the retrieved text? How can traditional parsing and generation be enhanced with statistical techniques? What would be the effect of carefully crafted lexicons on traditional information retrieval? At which points should machine translation be interleaved within information retrieval systems to enable multilingual processing?
The purpose of this study is to address these questions, in an attempt to identify the most effective future directions of computational linguistics research and in particular, how to address the problems of handling multilingual and multi-modal information. To gather information, a workshop was held in Granada, Spain, immediately following the First International Conference on Linguistic Resources and Evaluation (LREC) at the end of May, 1998. Experts in various subfields from Europe, Asia, and North America were invited to present their views regarding the following fundamental questions:
The experts were invited to represent the following areas:
In a series of ten sessions, one session per topic, the experts explained their perspectives and participated in panel discussions that attempted to structure the material and hypothesize about where we can expect to be in a few years’ time. Their presentations, comments, and notes were collected and synthesized into ten chapters by a collection of chapter editors.
A second workshop, this one open to the general computational linguistics public, was held immediately after the COLING-ACL conference in Montreal in August, 1998. This workshop provided a forum for public discussion and critique of the material gathered at the first meeting. Subsequently, the chapter editors updated and refined the ten chapters.
This report is formed out of the presentations and discussions of a wide range of experts in computational linguistics research, at the workshops and later. We are proud and happy to present it to representatives and funders of the US and European Governments and other relevant associations and agencies.
We hope that this study will be useful to anyone interested in assessing the future of multilingual language processing.
We would like to thank the US National Science Foundation and the Language Engineering division of the European Commission for their generous support of this study.
Eduard Hovy and Nancy Ide, Editorial Board Co-chairs
Contributors
Nuria Bel, GILCUB, Spain
Christian Boitet , GETA, France
Nicoletta Calzolari, ILC-CNR, Italy
George Carayannis, ILSP, Greece
Lynn Carlson, Department of Defense, USA
Jean-Pierre Chanod, XEROX-Europe, France
Khalid Choukri, ELRA, France
Ron Cole, Colorado State University, USA
Bonnie Dorr, University of Maryland, USA
Christiane Fellbaum, Princeton University, USA
Christian Fluhr, CEA, France
Robert Frederking, Carnegie Mellon University, USA
Ralph Grishman, New York University, USA
Lynette Hirschman, MITRE Corporation, USA
Jerry Hobbs, SRI International, USA
Eduard Hovy, USC Information Sciences Institute, USA
Nancy Ide, Vassar College, USA
Hitoshi Iida, ATR, Japan
Kai Ishikawa, NEC, Japan
Frederick Jelinek, Johns Hopkins University, USA
Judith Klavans, Columbia University, USA
Kevin Knight, USC Information Sciences Institute, USA
Kamran Kordi, Entropic, England
Gianni Lazzari, ITC, Italy
Bente Maegaard, Center for Sprogteknologi, Denmark
Joseph Mariani, LIMSI-CNRS, France
Alvin Martin, NIST, USA
Mark Maybury , MITRE Corporation, USA
Giorgio Micca, CSELT, Italy
Wolfgang Minker, LIMSI-CNRS, France
Doug Oard, University of Maryland, USA
Akitoshi Okumura, NEC, Japan
Martha Palmer, University of Pennsylvania, USA
Patrick Paroubek, CIRIL, France
Martin Rajman, EPFL, Switzerland
Roni Rosenfeld, Carnegie Mellon University, USA
Antonio Sanfilippo, Anite Systems, Luxembourg
Kenji Satoh, NEC, Japan
Oliviero Stock, IRST, Italy
Gary Strong, National Science Foundation, USA
Beth Sundheim, SPAWAR/NCCOSC, USA
Nino Varile, European Commission, Luxembourg
Charles Wayne, Departmentof Defense, USA
John White, Litton PRC, USA
Yorick Wilks, University of Sheffield, England
Antonio Zampolli, University of Pisa, Italy
Table of Contents
Chapter 1. Multilingual Resources (lexicons, ontologies, corpora, etc.)
Editor: Martha Palmer
Chapter 2. Cross-lingual and Cross-modal Information RetrievalEditors: Judith Klavans and Eduard Hovy
Chapter 3. Automated Cross-lingual Information Extraction and SummarizationEditor: Eduard Hovy
Chapter 4. Machine TranslationEditor: Bente Maegaard
Chapter 5. Multilingual Speech ProcessingEditor: Joseph Mariani
Chapter 6. Methods and Techniques of ProcessingEditor: Nancy Ide
Chapter 7. Speaker/Language Identification, Speech TranslationEditor: Gianni Lazzari
Chapter 8. Evaluation and Assessment TechniquesEditor: John White
Chapter 9. Multimedia Communication, in Conjunction with TextEditors: Mark Maybury and Oliviero Stock
Chapter 10. Government: Policies and FundingEditors: Antonio Zampolli and Eduard Hovy
[This chapter is available as http://www.cs.cmu.edu/~ref/mlim/chapter1.html .]
[Please send any comments to Robert Frederking (ref+@cs.cmu.edu, Web document maintainer) or Ed Hovy or Nancy Ide.]
Chapter 1
Multilingual Resources
Editor: Martha Palmer
Contributors:
Nicoletta Calzolari
Khalid Choukri
Christiane Fellbaum
Eduard Hovy
Nancy Ide
Abstract
A searing lesson learned in the last five years is the enormous amount of knowledge required to enable broad-scale language processing. Whether it is acquired by traditional, manual, means, or by using semi-automated, statistically oriented, methods, the need for international standards, evaluation/validation procedures, and ongoing maintenance and updating of resources which can be made available through central distribution centers is now greater than ever. We can no longer afford to (re)develop new grammars, lexicons, and ontologies for each new application, and to collect new corpora when corpus preparation is a nontrivial task. This chapter describes the current state of affairs for each type of resource–corpora, grammars, lexicons, and ontologies–and outlines what is required in the near future.
1.1 Introduction
Over the last decade, researchers and developers of Natural Language Processing technology have created basic tools that are impacting daily life. Speech recognition saves the telephone company millions of dollars. Text to speech synthesis aids the blind. Massive resources for training and analysis are available in the form of annotated and analyzed corpora for spoken and written language. The explosion in applications has largely been due to new algorithms that harness statistical techniques to achieve maximal leverage of linguistic insights, as well as to the huge increase in power per dollar in computing machinery.
Yet the ultimate goals of the various branches of Natural Language Processing–accurate Information Extraction and Text Summarization (
Chapter 3), focused multilingual Information Retrieval (Chapter 2), fluent Machine Translation (Chapter 4), robust Speech Recognition (Chapter 5)–still remain tantalizingly out of reach. The principal difficulty lies in dealing with meaning. However well systems perform their basic steps, they are still not able to perform at high enough levels for real-world domains, because they are unable to sufficiently understand what the user is trying to say or do. The difficulty of building adequate semantic representations, both in design and scale, has limited the fields of Natural Language Processing in two ways: either to applications that can be circumscribed within well-defined subdomains, as in Information Extraction and Text Summarization (Chapter 3); or to applications that operate at a less-than-ideal level of performance, as in Speech Recognition (Chapter 5) or Information Retrieval (Chapter 2).The two major causes of these limitations are related. First, large-scale, all-encompassing resources (lexicons, grammars, etc.) upon which systems can be built are rare or nonexistent. Second, theories that enable the adequately accurate representation of semantics (meaning) for a wide variety of specific aspects (time, space, causality, interpersonal effects, emotions, etc.) do not exist, or are so formalized as to be too constraining for practical implementation. At this time, we have no way of constructing a wide-coverage lexicon with adequately formalized semantic knowledge, for example.
On the other hand, we do have many individual resources, built up over almost five decades of projects in Language Processing, ranging from individual lexicons or grammars of a few thousand items to the results of large multi-project collaborations such as ACQUILEX. We also have access to the work on semantics in Philosophy, NLP, Artificial Intelligence (AI), and Cognitive Science, and in particular to the efforts of large AI projects such as CYC on the construction of semantic knowledge bases (see Section 1.3.4 below). Thus one of our major challenges consists of collecting and reusing what exists, rather than in starting yet again.
The value of standards has long been recognized as a way to ensure that resources are not abandoned when their projects end, but that subsequent projects can build upon what came before. Both in Europe and the US, various more or less coordinated standards efforts have existed, for various resources. In the US, these issues with respect to lexicons have been taken up in a series of recent workshops under the auspices of the ACL Special Interest Group on the Lexicon, SIGLEX. Word sense disambiguation, WSD, was a central topic of discussion at the workshop on Semantic Tagging at the ANLP 1997 conference in Washington chaired by Marc Light, (Kilgarriff, 1997), which featured several working groups on polysemy and computational lexicons. This meeting led to the organization of a follow-on series, SIGLEX98-SENSEVAL and subsequent workshops (SIGLEX99), which address WSD even more directly by including evaluations of word sense disambiguation systems and in-depth discussions of the suitability of traditional dictionary entries as entries in computational lexicons. In Europe, the EAGLES standardization initiative has begun an important movement towards common formats for lexicon standardization and towards coordinated efforts towards standardizing other resources. Such standardization is especially critical in Europe, where multilinguality adds another dimension of complexity to natural language processing issues. The EAGLES report can be found at
http://www.ilc.pi.cnr.it/EAGLES96/rep2/rep2.html. Recently, renewed interest in the semi-automated acquisition of resource information (words for lexicons, rules for grammars) has led to a new urgency for the clear and simple formulation of such standards.Though the problem is a long way from being finally solved, the issues are being more clearly defined. In particular there is a growing awareness, especially among younger researchers, that the object is not to prove the truth or correctness of any particular theoretical approach, but rather to agree on a common format that can allow us to merge multiple sources of information. Otherwise we doom ourselves to expending vast amounts of effort in the pursuit of nothing more than duplication. The quickest way to arrive at a common format may be to make very coarse distinctions initially, and then refine the results later–an approach that was anathema some years ago. A common format is required not only so that we can share resources and can communicate information between languages, but to also enable a common protocol for communicating information between different modalities.
Acknowledging two facts is the key to successful future multilingual information processing:
In principle, we consider all of the various major types of information used in Language Processing which includes morphology, parts of speech, syntax, collocations, frequency of occurrence, semantics, discourse, and interpersonal and situational communicative pragmatics. Since there is no way to determine a priori which aspect plays the primary role in a given instance, all of these levels of representation could be equally relevant to a task. In this chapter, however we focus only on the resources currently most critical for continued progress:
Naturally, in parallel to the specification of the nature of elements of each of these entities, the development of semi-automated techniques for acquisition, involving statistical modeling, and efficient and novel algorithms, is crucial. These techniques are discussed in
Chapter 6.1.2 Development of Language Resources: Past, Present and Future
In this section we discuss the role of language resources in a multilingual setting, focusing on the four essentials of Language Resources, distribution, development, evaluation, and maintenance, that pertain equally to all of them. At the beginning of the 1990s, the US was at the vanguard of the production of language resources, having transformed the conclusions of the first workshop on Evaluation of Natural Language Processing Systems into DARPA’s MUC, TREC, and later MT and SUMMAC evaluations. Under DARPA and other (primarily military) agency funding, the Language Processing standardization and dissemination activities included:
Since the formation of the European Language Resources Association ELRA in 1995, however, the leadership role has passed to Europe, which is now well ahead of the US in the recognition of the need for standardization, lexical semantics, and multilinguality. Recognizing the strategic role of Language Resources, the CEC launched a large number of projects in Europe in the last decade, many of them in the recent Language Engineering program. In this vision, the language resource activities essential for a coordinated development of the field included the development, evaluation, and distribution of core Language Resources for all EU languages that conformed to agreed upon standards and formats. The Language Engineering projects that coherently implemented (or started to work towards the implementation of) these types of activity include:
The ever-spreading tentacles of the Internet have revived US interest in multi-lingual information processing, with a corresponding renewed interest in relevant language resources. At this point the community will be well served by a coordinated international effort that merges what has been achieved in North America, especially in the areas of evaluation, with what has been achieved in Europe, especially with respect to development and maintenance.
Development
Efficient and effective development in an area as complex as Language Processing requires close cooperation between various different research groups, as well as frequent integration of diverse components. This makes a shared platform of large-coverage language resources and basic components an absolute necessity as a common infrastructure, to ensure:
Though we address the particular needs of individual resources below, they all have an essential need for international collaborations that specifically collect existing resources and evaluation methods, integrate them into unified practical and not-too-complex frameworks, and deliver them to such bodies as LDC and ELRA. This work will not only facilitate Language Processing projects but will prove invaluable in pinpointing gaps and theoretical shortcomings in the coverage and applicability of the resources and evaluation methods.
Evaluation
The importance of evaluations to assess the current state of the art and measure progress of technologies, as discussed in
Chapter 8, is evident. There is a need for an independent player to construct and manage both the data and the evaluation campaigns. However, performing evaluations has proven to be a rather difficult enterprise, and not only for technical reasons. Evaluations with high inherent overheads are often perceived as an unrewarding and possibly disruptive activity. However, in every endeavor in which an appropriate and systematic program of evaluations has evolved, marked progress has been achieved in practical language engineering terms. This phenomenon is discussed further in Chapter 6.
Despite this fact, many key players, (customers and developers) have historically shown little interest in performing substantial evaluations, since they simply cannot afford the sizeable investments required. Unfortunately, the consumer reports appearing in various computer magazines lack the necessary accuracy and methodological criteria to be considered objective, valid evaluations. A further limitation is the lack of access to laboratory prototypes, so that only systems that have already been fielded are available for testing by the customer community. Furthermore, developers prefer to spend their time on development instead of on assessment, particularly if the evaluation is to be public.
As a result, the only remaining players with the requisite financial resources, infrastructure, and social clout are the funding agencies. When they are potential users of the technology they can perform in-house evaluations; examples include the Service de Traduction (translation services) of the CEC and the US Department of Defense evaluations of information retrieval, text summarization, and information extraction (TREC, SUMMAC, and MUC; see
Chapters 2 and 3). They can also include evaluations as a necessary component of systems whose development they are funding, as a method of determining follow-on funding. In such a case however, it is critical to ensure community consensus on the evaluation criteria lest the issues become clouded by the need for funds.Developing evaluation measures for resources is even more complex than evaluating applications, such as summarization and machine translation. With applications, achievement of tasks can be specified with corresponding evaluation of performance being measured against the desired outcome. With resources such as lexicons, however, the evaluation has to determine, in some way, how well the resource supports the functioning of the application. This can only be done if the contribution of the lexicon can be teased apart from the contribution of the other components of the application system and the performance of the system as a whole. Therefore, evaluation of resources is by necessity secondary or indirect, making them especially difficult to perform. An unfortunate result of this has been the proliferation of unused grammars, lexicons, resource acquisition tools, and word taxonomies that, with appropriate revision, could have provided valuable community resources. Constructive evaluations of resources are fundamental to their reusability.
However, there is an inherent danger in tying funding too directly to short-term evaluation schemes: it can have the unfortunate result of stifling innovation and slowing down progress. It is critical for evaluations to measure fundamental improvements in technology and not simply reward the system that has been geared (hacked) most successfully to a particular evaluation scheme. The SIGLEX workshops mentioned above provide an example of a grassroots movement to define more clearly the role of syntax, lexical semantics, and lexical co-occurrence in word sense disambiguation, and as such it is examining not just system performance but the very nature of word sense distinctions. The next five years should see a major shift in evaluations away from purely task oriented evaluations and towards a hybrid evaluation approach that will further our understanding of the task while at the same time focusing on measurable results.
Distribution
As with the LDC in the US, the role of ELRA in Europe as an intermediary between producers and users of language resources greatly simplifies the distribution process by preventing a great deal of unnecessary contractual arrangements and easing sales across borders. MLCC, ELRA’s multilingual corpus, for example, consists of data from 6 different newspapers in 6 different languages. ELRA has signed contracts with each provider, and the user who wishes to acquire the set of databases only has to sign a single contract with ELRA. Care is taken to ensure that the language resources are clear of intellectual property rights (IPR) restrictions and are available for commercial and research licenses, with a list of key applications associated with them. (The alternative is a bureaucratic nightmare, in which each user has to sign 6 different contracts, negotiate IPR rights for each one, with 6 different producers, in 6 different countries, under 6 different legal systems. Having a few major distribution sites is clearly the only sane method of making this data available. )
In addition to distributing corpora, both raw and annotated, the next few years should see the addition of grammars, lexicons and ontologies as resources that could be made available through such distribution sites.
Maintenance
Many of the resources mentioned above have just been created or are still in the process of being created. Therefore the issue of maintenance has not really been addressed in either the US or in Europe, although it did provide the topic for a panel discussion at the First International Language Resources conference LREC-98. A question that has already arisen has to do with EuroWordNet, which is linked to WordNet 1.5 (because this was the version when EuroWordNet was begun), although version 1.5 has since been replaced by WordNet 1.6. How can EuroWordNet best be updated to reflect the new version?
Anyone having even the briefest acquaintance with software product cycles will expect that the maintenance of language resources will shortly become a central issue.
1.3 Types of Language Resources
1.3.1 Corpora
Before corpora are suitable for natural language processing work, it is necessary for them to be created and prepared (or "annotated"). The term "annotation" is very broadly construed at present, involving everything from identifying paragraph breaks to the addition of information that is not in any way present in the original, such as part of speech tags. In general, one can divide what is now lumped together under the term "corpus annotation" into three broad categories:
In order to enable more efficient and effective creation of corpora for NLP work, it is essential to understand the nature of each of these phases and establish mechanisms and means to accomplish each. Step (1) can be nearly fully automated, but steps (2) and (3) require more processing overhead as well as significant human intervention. In particular, we need to develop algorithms and methods for automating these two steps. This is especially true for step (2), which has received only marginal attention except in efforts such as the TREC name identification task, and this will require funding. Step (3) has received more attention, since algorithms for identifying complex linguistic elements has typically been viewed as a more legitimate area of research. However, as discussed above, appropriate markups for lexical semantic information are at a very rudimentary stage of development. One of the most important directions for corpora annotation is determining a richer level of annotation that includes word senses, predicate argument structure, noun-phrase semantic categories, and coreference.
It is also critical that we devise means to include information about elements in a text in a way that makes the resulting texts maximally processable and reusable. In particular, it is important to ensure that the markup used to identify text elements is:
Therefore, in order to create corpora that are both maximally usable and reusable, it will be necessary to specify clearly the ways in which the corpora will be used and the capabilities of the tools that will process them. This in turn demands that effort be put into the development of annotation software, and above all, that this development be undertaken in full collaboration with developers of the software that will process this data and the users who will access it. In other words, as outlined in (Ide, 1998) there are two major requirements for advancing the creation and use of corpora in NLP:
1.3.2 Grammars
The development of powerful and accurate grammars was seen as a primary necessity for Language Processing in the 1960s and early 1970s. However, the near impossibility of building a complete grammar for any language has been gradually recognized, as well as the tremendous amount of essential lexically-specific information, such as modifier preferences and idiosyncratic expressive details. This has led to a shift in emphasis away from traditional rule-based grammars for broad-coverage applications. The systems developed for the MUC series of Information Extraction tasks (see
Chapter 3) generally employed short-range Finite State matchers that provided eventual semantic-like output more quickly and reliably than purely syntax-based parsers. However, they did not produce a rich enough syntactic structure to support discourse processing such as co-reference, which imposed a limit on their overall performance. The goal being sought today is a combination of linguistic and statistical approaches that will robustly provide rich linguistic annotation of raw text.The issues involved in developing more traditional rule-based grammar resources were thoroughly addressed in a 1996 report commissioned by the National Science Foundation; see
http://www.cse.ogi.edu/CSLU/HLTsurvey/HLTsurvey.html, whose Chapter 3 covers grammars specifically. In addition, recent advances during the last two years have resulted in significant, measurable progress in broad coverage parsing accuracy. Statistical learning techniques have led to the development of a new generation of accurate and robust parsers which provide very useful analyses of newspaper style documents, and noisier, but still usable analyses in other, similar domains (Charniak, 1995; Collins, 1997; Magerman and Rathnaparkhit, 1997; Srinivas, 1997,). Such parsers are trained on a set of (sentence, tree) pairs, and will then output the most likely parse for a new, novel, sentence.One advantage of statistical methods is their ability to learn the grammar of the language automatically from training examples. Thus the emphasis on human effort shifts from handcrafting a grammar to annotating a corpus of training examples. Human annotation can immediately provide coverage for phenomena outside the range of most handcrafted grammars, and the resulting corpus is a re-usable resource which can be employed in the training of increasingly accurate generations of parsers as its annotations are enriched and technology progresses. The handcrafted grammars can play an important role in the bootstrapping of appropriate grammatical structure, as illustrated by the role Fidditch (Hindle, 1983) played in the development of the Penn TreeBank (Marcus, 1993), and the success of the Supertagger, (Joshi and Srinivas, 1994, Srinivas, 1997), developed from corpora to which XTAG parses had been assigned (XTAG, 1995).
An important next major advance has to come from a closer integration of syntax and lexical semantics, namely, the ability to train these parsers to recognize not just syntactic structures, but structures that are rich with semantic content as well, (Hermjakob and Mooney, 1997). In the same way that the existence of the Penn TreeBank enabled the development of extremely powerful new syntactic analysis methods, moving to the stage of lexical semantics will require a correspondingly richer level of annotation that includes word senses, predicate argument structure, noun-phrase semantic categories and coreference.
In order to both produce such a resource, and perhaps more importantly, to utilize it effectively, we need to team our parsing technologies more closely with lexical resources. This is an important part of the motivation behind lexicalized grammars such as TAG (Joshi, Levy and Takahasi, 1975, Joshi, 1985) and CCG (Steedman, 1996). Tightly interwoven syntactic and semantic processing can provide the levels of accuracy that are required to support discourse analysis and inference and reasoning, which forms the foundation of any natural language processing application. This has important implications for the future directions of both corpora and lexicons as resources, as well as ontologies.
1.3.3 Lexicons
Lexicons are the heart of any natural language processing system. They include the vocabulary that the system can handle, both individual lexical items and multi-word phrases, with associated morphological, syntactic, semantic and pragmatic information. In cases of spoken language systems, they also include pronunciation and phonological information. In machine translation systems, the bilingual and multilingual lexicons provide the basis for mapping from the source language to the target language. The EAGLES report on monolingual lexicons in several languages,
http://www.ilc.pi.cnr.it/EAGLES96/rep2/rep2.html, gives a comprehensive description of how morphological and syntactic information should be encoded. Available on-line lexicons for English such as Comlex (Grishman, et al, 1994) and XTAG to a large degree satisfy these guidelines, as do the SIMPLE lexicons being built in Europe for the other language. The EAGLES working group on Lexical Semantics is preparing guidelines for encoding of semantic information.However, to this date these guidelines have not addressed the issue of making sense distinctions. How does the lexicon creator decide to make one, two or more separate entries for the same lexeme? An issue of major concern is the current proliferation of different English lexicons in the computational linguistics community. There are several on-line lexical resources that are being used that make sense distinctions, Longman's, Oxford University Press, (OUP), Cambridge University Press (CUP), Webster's, and WordNet, to name just a few, and they each use very different approaches. In SENSEVAL, the training data and test data was prepared using a set of OUP senses. In order to allow systems using WordNet to compete as well, a mapping from the OUP senses to the WordNet senses was made. The WordNet system builders commented that "OUP and WordNet carve up the world in different ways. It's possible that WordNet is more fine-grained in some instances, but in the map for the words in SENSEVAL, the OUP grain was generally finer (about 240 WN entries for the SENSEVAL words and about 420 OUP entries.) More than anything, the grain is not necessarily uniform -- not within WordNet, not within OUP." This is true of dictionaries in general. They make different decisions about how to structure entries for the same words, decisions which are all equally valid, but simply not compatible. There was quite a bit of concern expressed, both at the workshop, and afterwards, that this makes it impossible to create performance-preserving mappings between dictionaries.
This is an incompatibility with consequences that are for more wide-spread than the comparison of word sense disambiguation systems. Sense inventories, or lexicons, as the core of an information processing application, are critical as well as being one of the most labor intensive components. Many existing natural language processing applications are described as domain-specific, and this primarily describes the lexicon being used, which contains the domain-specific senses for the vocabulary that is relevant to that application. Because of this incompatibility, it is very unlikely that lexicons from two different applications could be readily merged to create a new system with greater range and flexibility. The task of merging the lexicons could be just as labor intensive as the task of building them in the first place. Even more sweeping is the impact on multilingual information processing. All of these tasks require bilingual lexicons that make the mapping from English to French or German or Japanese. Many of these bilingual lexicons are currently being built, but they are all mapping to different English lexicons which are themselves incompatible. The problem of merging two different domain-specific English to French bilingual lexicons is an order of magnitude larger than the problem of merging two English domain-specific lexicons. Then the problem of trying to integrate a bilingual lexicon involving a third language, such as Korean, that was mapped to yet another incompatible English lexicon, requires that it be done all over again. The sooner we can regularize our representation of English computational lexicons, the less work we will have to do in the future.
Regularizing the English computational lexicon is not a trivial task. Creating a consensus on grammatical structure for the TreeBank required posting guidelines that described literally hundreds of distinct grammatical structures. Where lexical entries are concerned the numbers are in the hundreds of thousands. The first step is simply agreeing on criteria for deciding when two different usages should be considered separate senses and when they should not, and should that be allowed to change depending on the context? Once these general principles have been determined, then the business of revising one of the existing on-line lexicons, preferably WordNet since it is being used the most widely, can begin. Only when the criteria for sense distinctions has been agreed upon, can we create reliable sense-tagged corpora for machine learning purposes, and move our information processing systems onto the next critical stage.
Lexicon Development
There is increased recognition of the vital role played by lexicons (word lists with associated information), when fine tuning general systems to particular domains.
Due to the extremely fluid and ever-changing nature of language, lexicon development poses an especially difficult challenge. No static resource can ever be adequate. In addition, as soon as large-scale generic lexicons with different layers of encoded information (morphological, syntactic, semantic, etc.) are created, they will still need to be fine-tuned for use in specific applications.
Generic and domain-specific lexicons are mutually interdependent. This makes it vital, for any sound lexicon development strategy, to accompany core static lexicons with dynamic means for enriching and integrating them–possibly on the fly–with many types of information. This global view eliminates the apparent dichotomy between static vs. dynamically built (or incremental) resources, encompassing the two approaches in a more comprehensive perspective that sees the two as complementary and equally necessary facets of the same problem. In the past few years, steps towards this objective have been taken by a consistent number of groups all over the world, with many varied research and development efforts aimed at acquiring linguistic and, more specifically, lexical, information from corpora. Among the EC projects working in this direction we mention LE SPARKLE (combining shallow parsing and lexical acquisition techniques capable of learning aspects of word knowledge needed for LE applications) and LE ECRAN.
Gaps in Static Lexicons
As Gross clearly stated already in the 1970s (Gross 1984), most existing lexicons contain simple words, while actually occurring texts such as newspapers are composed predominantly of multi-word phrases. Still, however, the phrasal nature of the lexicon has not been addressed properly, and is a major limitation of available resources. Correcting this will require corpora to play a major role, but also methodologies of extraction, and linguistic methods of classification.
As mentioned above, resources for evaluation and the evaluation of resources is a major open problem in lexicon development, validation, and reuse.
While large morphosyntactically annotated corpora exist for many European languages, built for example in MULTEXT and for all the EU languages in PAROLE, and also the production of large-size syntactically annotated corpora has started for some EU languages, semantically tagged corpora do not yet exist. This is rapidly becoming a major requirement for developing application-specific tools.
Critical Priorities in Lexicon Development
Computational lexicons, like human dictionaries, often represent a sort of stereotypical/theoretical language. Carefully constructed or selected large corpora are essential sources of linguistic knowledge for the extensive description of the concrete use of the language in real text. To be habitable and practical, a computational lexicon has to faithfully represent the apparently ‘irregular’ facts (evidenced by corpus analysis), and the divergences by actual usage from what is potentially/in theory acceptable. We need to clearly represent–and separate–what is allowed, but only very rarely instantiated, from what is both allowed and actually used. To this end, more robust and flexible tools are needed for (semi-) automatic induction of linguistic knowledge from texts. This usually implies a bootstrapping method, because extraction presupposes some capability of automatically analyzing the raw text in various ways, which first requires a lexicon. The induction phase must however be followed by a linguistic analysis and classification phase, if the induced data is to be used and merged together with already available resources. Therefore:
The EC-funded projects provide an excellent framework for facilitating these types of interactions, by providing the necessary funding for combining the efforts of different and complementary groups. This complementarity of existing competence should continue to be sought and carefully planned.
1.3.4 Ontologies
Background
As described in
Chapters 2, 3, and 4, semantic information is central in improving the performance of Language Processing systems. Lexical semantic information such as semantic class constraints, thematic roles, and lexical classifications need to be closely coupled to the semantic frameworks used for language processing. Increasingly, such information is represented and stored in so-called ontologies.An ontology can be viewed as an inventory of concepts, organized under some internal structuring principle. Ontologies go back to Aristotle; more recently (in 1852), Peter Mark Roget published his Thesaurus of English Words and Phrases Classified and Arranged so as to Facilitate the Expression of Ideas and Assist in Literary Composition. The organization of the words in a thesaurus follows the organization of the concepts that the words express and not vice versa, as in a dictionary; a thesaurus can therefore be considered to be an ontology. Roget’s thesaurus has been revised (Chapman, 1977), but not significantly altered. However, for computational purposes, a consistently structured ontology is needed for automatic processing, which is over and beyond what is provided by Roget.
The set of concepts definition, however, begs the notoriously difficult question: What is a concept? Over the past decade, two principal schools of thought have emerged on this question. Researchers in Language Processing circles, typically, have simplified the answer to this question by equating concept with lexicalized concept, i.e., a concept that is expressed by one or more words of a language. (The assumption that more than one word may refer to the same concept reflects the familiar phenomenon of synonymy.) Under this view, an ontology is the inventory of word senses of a language–its semantic lexicon. This definition has the advantage that it contains only those concepts that are shared by a linguistic community. It excludes possible concepts like my third cousin’s black cat, which are idiosyncratic to a given speaker and of no interest to psychologists, philosophers, linguists, etc. Relating one’s ontology with the lexicon also excludes potential concepts expressible by ad-hoc compounds like paper clip container, which can be generated on the fly but are not part of the core inventory, as their absence from dictionaries shows. Moreover, we avoid the need to define words by limiting our inventory to those strings found in standard lexical reference works. Thus the Language Processing ontologies that have been built resemble Roget’s thesaurus in that they express the relationships among concepts at the granularity of words. Within Artificial Intelligence (AI), in contrast, a concept has roughly been identified with some abstract notion that facilitates reasoning (ideally, by a system and not just by the ontology builder), and the ontologies that have been built have also been called Domain Models or Knowledge Bases. To differentiate the two styles, the former are often referred to as terminological ontologies (or even just term taxonomies), while the latter are sometimes called conceptual or axiomatized ontologies.
The purpose of terminological ontologies is to support Language Processing. Typically, the content of these ontologies is relatively meager, with only a handful of relationships on average between any given concept and all the others. Neither the concepts nor the inter-concept relationships are formally defined, and are typically only differentiated by name and possibly textual definition. The core structuring relationship is usually called is-a and expresses the rough notion of "a kind of" or conceptual generalization. Very often, to support the wide range of language, terminological ontologies contain over 100,000 entities, and tend to be linked to lexicons of one or more languages that provide the words expressing the concepts. The best-known example of a terminological ontology is WordNet (Miller, 1990; Fellbaum, 1998), which as an on-line resource of reference has had a major impact on the ability of researchers to conceive of different semantic processing techniques. However, before the collection of truly representative large-scale sets of semantic senses can begin, the field has to develop a clear consensus on guidelines for computational lexicons. Indeed, attempts are being made, including (Mel’cuk, 1988; Pustejovsky, 1995; Nirenburg et al., 1992; Copestake and Sanfilippo, 1993; Lowe et al., 1997; Dorr, 1997; Palmer, 1998). Other terminological ontologies are Mikrokosmos (Viegas et al., 1996), used for machine translation, and SENSUS (Knight and Luk, 1994; Hovy, 1998), used for machine translation of several languages, text summarization, and text generation.
In contrast, the conceptual ontologies of AI are built to support logic-based inference, and often include substantial amounts of world knowledge in addition to lexical knowledge. Thus the content of each concept is usually richer, involving some dozens or even more axioms relating a concept to others (for example, a car has-part wheels, the usual-number of wheels being 4, the wheels enabling motion, and so on). Often, conceptual ontologies contain candidates for concepts for which no word exists, such as PartiallyTemporalAndPartiallySpatialThing. Recent conceptual ontologies reflect growing understanding that two core structuring relationships are necessary to express logical differences in generalization, and that concepts exhibit various facets (structural, functional, meronymic, material, social, and so on). Thus a glass, under the material facet, is a lot of glass matter; under the meronymic facet, it is a configuration of stem, foot, and bowl; under the functional facet, it is a container from which one can drink and through which one can see; under one social facet, it is the object that the bridegroom crushes at a wedding; see (Guarino, 1997). Given the complex analysis required to build such models, and the interrelationships among concepts, conceptual ontologies tend to number between 2,000 and 5,000 entities. The largest conceptual ontology, CYC (Lenat and Guha, 1995) contains approx. 40,000 concepts; every other conceptual ontology is an order of magnitude smaller. (In contrast, as mentioned above, WordNet has roughly 100,000 concepts.) Unfortunately, given the complexity of these ontologies, internal logical consistency is an ongoing and serious problem.
Ontologies contain the semantic information that enables Language Processing systems to deliver higher quality performance. They help with a large variety of tasks, including word sense disambiguation (in "he picked up the bench", "bench" cannot stand for judiciary because it is an abstraction), phrase attachment (in "he saw the man with the telescope", it is more likely that the telescope was used to see the man than that it is something uniquely associated with the man, because it is an instrument for looking with), and machine translation (as an inventory of the symbols via which words in different languages can be associated). The obvious need for ontologies, coupled with the current lack of many large examples, leads to the vexing question of exactly how to build useful multi-purpose ontologies.
Unfortunately, ontologies are difficult and expensive to build. To be useful, they have to be large and comprehensive. Therefore, the more an ontology can be shared by multiple applications, the more useful it is. However, it is not so much a matter of designing the ‘right’ ontology (an almost meaningless statement, given our current lack of understanding of semantics), but of having a reasonable one that can serve impelling purposes, and on which some consensus between different groups can be reached. In this light, creating a consensus ontology becomes a worthwhile enterprise; indeed, this is precisely the goal of the ANSI group on Ontology Standards (Hovy, 1998), and is a critical task for the EAGLES Lexicon/Semantics Working Group. Initiatives of this kind must converge and act in synergy to be fruitful for the Language Processing community.
Open Questions in Language Processing Ontologies
WordNet (Miller, 1995; Fellbaum, 1998) is a lexical database organized around lexicalized concepts or synonym sets. Unlike Roget’s largely intuitive design, WordNet was originally motivated by psycholinguistic models of human semantic memory and knowledge representation. Supported by data from word association norms, WordNet links together its synonym sets (lexicalized concepts) by means of a small number of conceptual-semantic and lexical relations. The most important ones are hyponymy (the superclass relation) and meronymy (the part-whole relation) or concepts expressible by nouns, antonymy for adjectives, and several entailment relations for verbs (Miller, 1990; Fellbaum, 1998). Whereas WordNet is entirely hand-constructed, (Amsler, 1980) and (Chodorow et al., 1985) were among those who tried to extract hyponymically related words automatically from machine-readable dictionaries by exploiting their implicit structure. (Hearst, 1998) proposed to find semantically related words by finding specific phrase patterns in texts.
SENSUS (Knight and Luk, 1994; Hovy, 1998) is a derivative of WordNet that seeks to make it more amenable to the tasks of machine translation and text generation. The necessary alterations required the inclusion of a whole new top level of approx. 300 high-level abstractions of English syntax called the Upper Model (Bateman et al., 1986), as well as a concomitant retaxonomization of WordNet (separated into approx. 100 parts) under this top level. To enable machine translation, SENSUS concepts act as pivots between different language words; its concepts are linked to lexicons of Japanese, Spanish, Arabic, and English.
Mikrokosmos (Viegas et al., 1996; Mahesh 1995) is an ontology of approx. 5,000 high-level abstractions, out of which lexical items are defined for a variety of languages, also in the task of machine translation.
The experience of designing and building these and other ontologies all shared the same major difficulties. First among these is the identification of the concepts. The top-level concepts in particular remain a source of controversy, because these very abstract notions are not always well lexicalized and can often be referred to only by phrases such as causal agent and physical object. Second, concepts fall into distinct classes, expressible by different parts of speech: Entities are referred to by nouns; functions, activities, events, and states tend to be expressed by verbs, and attributes and properties are lexicalized by adjectives. But some concepts do not follow this neat classification. Phrases and chunks such as "won’t hear of it" and "the X-er the Y-er"(Fillmore, 1988; Jackendoff, 1995) arguably express specific concepts, but they cannot always be categorized either lexically or in terms of high-level concepts.
Second, the internal structure of proposed ontologies is controversial. WordNet relates all synonym sets by means of about a dozen semantic relations; (Mel’cuk, 1988) proposes over fifty. There is little solid evidence for the set of all and only useful relations, and intuition invariably comes into play. Moreover, it is difficult to avoid the inherent polysemy of semantic relations. For example, (Chaffin et al., 1988) analyzed the many different kinds of meronymy, and similar studies could be undertaken for hyponymy and antonymy (Cruse, 1986). Another problem is the fact that semantic relations like antonymy, entailment, meronymy, and class inclusion are themselves concepts, raising the question of circularity.
Two major approaches currently exist concerning the structure of ontologies. One approach identifies all ‘elemental’ concepts as factors, and then uses concept lattices to represent all factor combinations under which concepts can be taxonomized (Wille, 1992). The more common approach is to taxonomize concepts using the concept generalization relation as structural principle. While the debate concerning the relative merits of both approaches continues, only the taxonomic approach has been empirically validated with the construction of ontologies containing over 10,000 concepts.
Third, a recurrent problem relates to the question of multiple inheritance. For example, a dog can be both an animal and a pet. How should this dual relation be represented in an ontology? WordNet and SENSUS treat both dog and pet as kinds of animals and ignores the type-role distinction, because it seems impossible to construct full hierarchies from role or function concepts such as pet. But clearly, there is a difference between these two kinds of concepts. Casting this problem as one of conceptual facets, Pustejovsky (1995) proposed a solution by creating a lexicon with underspecified entries such as ‘newspaper’ together with structured semantic information about the underlying concept. Depending on the context in which the word occurs, some of its semantic aspects are foregrounded whereas others are not needed for interpreting the context, e.g., the building vs. the institution aspects of newspaper. Guarino (1997) takes this approach a step further, and identifies at least 8 so-called Identity Criteria that each express a different facet of conceptual identity. Such approaches may well offer a satisfactory solution for the representation of the meaning of complex concepts.
Despite their quasi-semantic nature, ontologies based on lexicons do not map readily across languages. It is usually necessary to find shared concepts underlying the lexical classifications in order to facilitate multilingual mappings. Currently, the EuroWordNet project is building lexical databases in eight European languages patterned after WordNet but with several important enhancements (Vossen, et al., 1999). EuroWordNet shows up crosslinguistic lexicalization patterns of concepts. Its interlingual index is the union of all lexicalized concepts in the eight languages, and permits one to examine which concepts are expressed in all languages, and which ones are matched with a word in only a subset of the languages, an important perspective to gain for ontology theoreticians. Multilingual applications are always a good test of one’s theories. EuroWordNet is testing the validity of the original WordNet and the way it structures the concepts lexicalized in English. Crosslinguistic matching reveals lexical gaps in individual languages, as well as concepts that are particular to one language only. Eventually, an inspection of the lexicalized concepts shared by all eight member languages should be of interest, as well as the union of the concepts of all languages. Similar data should be available from the Mikrokosmos project. To yield a clear picture, ontologies from as wide a variety of languages as possible should be compared, and the coverage should be comparable for all languages.
The Special Challenge of Verbs
It is not surprising that WordNet’s noun classification has been used more successfully than the verb classification, or that the majority of the entries in the Generative Lexicon are of nouns. By their very nature verbs involve multiple relationships among many participants which can themselves be complex predicates. Classifying and comparing such rich representations is especially difficult.
An encouraging recent development in linguistics provides verb classifications that have a more semantic orientation (Levin, 1993, Rappaport Hovav and Levin 1998). These classes, and refinements on them (Dang et al., 1998; Dorr, 1997), provide the key to making generalizations about regular extensions of verb meanings, which is critical to building the bridge between syntax and semantics. Based on these results, a distributional analysis of properly disambiguated syntactic frames should provide critical information regarding a verb’s semantic classification, as is being currently explored by (Stevenson & Merlo, 1997). This could make it possible to use the syntactic frames occurring with particular lexical items in large parsed corpora to automatically form clusters that are both semantically and syntactically coherent. This is our doorway, not just to richer computational lexicons, but to a methodology for building ontologies. The more we can rely on semi-automated and automated methods for building classifications, even those tailored to specific domains, the more objective these classifications will be, and the more reliably they will port to other languages.
Recent encouraging results in the application of statistical techniques to lexical semantics lend credence to this notion. There have been surprising breakthroughs in the use of lexical resources for semantic analysis in the areas of homonym disambiguation (Yarowsky, 1995) and prepositional phrase attachment (Stetina and Nagao, 1997). There are also new clustering algorithms that create word classes that correspond to linguistic concepts or that aid in language modeling tasks (Resnik, 1993; Lee et al., 1997). New research projects exploring the application of linguistic theories to verb representation promise to advance our understanding of computational lexicons, FRAMENET (Lowe, et al., 1997) and VERBNET (Dang et al., 1998). The next few years should bring dramatic changes to our ability to use and represent lexical semantics.
The Future
Ontologies are no longer of interest to philosophers only, but also to linguists, computer scientists, and people working in information and library sciences. Creating an ontology is an attempt to represent human knowledge in a structured way. As more and more knowledge, expressed by words and documents, is available to larger numbers of people, it needs to be made accessible easily and quickly. Ontologies permit one to efficiently store and retrieve great amounts of data by imposing a classification and structure on the knowledge in these data.
There is only one way in which progress in this difficult and important question can be made effectively. Instead of re-building ontologies anew for each domain and each application, the existing ontologies must be pooled, converted to the same notation, and cross-indexed, and one or more common, standardized, and maximally extensive ontologies should be created. The semi-automated cross-ontology alignment work reported in (Knight and Luk, 1994; Agirre et al., 1994; Rigau and Agirre, 1995; Hovy, 1996; Hovy, 1998) illustrates the extent to which techniques can be developed to exploit the ontology structure, concept names, and concept definitions.
If this goal, shared by a number of enterprises, including the ANSI Ad Hoc Committee on Ontology Standardization (Hovy, 1998), can indeed be realized, it will constitute a significant advance for semantic-based Language Processing.
1.4 Conclusion
The questions raised here are likely to continue to challenge us in the near future; after all, ontologies have occupied people’s minds for over 2,500 years. Progress and understanding are likely to come not from mere speculation and theorizing, but from the construction of realistically sized models such as WordNet, CYC (Lenat and Guha, 1990), Mikrokosmos (Viegas et al., 1996, Mahesh, 1996), and SENSUS, the ISI multilingual ontology (Knight and Luk, 1994; Hovy, 1998).
One next major technical advance is almost certain to come from a closer integration of syntax and lexical semantics, most probably via the ability to train statistical parsers to recognize not just syntactic structures, but structures that are rich with semantic content as well. In the same way that the existence of the Penn TreeBank enabled the development of extremely powerful new syntactic analysis methods, the development of a large resource of lexical semantics (either in the form of an ontology or a semantic lexicon) will facilitate a whole new level of processing. Construction of such a semantic resource requires corpora with a correspondingly richer level of annotation. These annotations must include word senses, predicate argument structure, noun-phrase semantic categories and coreference, and multilingual lexicons rich in semantic structure that are coupled to multilingual ontologies. Tightly interwoven syntactic and semantic processing can provide the levels of accuracy that are required to support discourse analysis and inference and reasoning–the foundation of any natural language processing application.
The thesis of this chapter is the recognition of the essential role that language resources play in the infrastructure of Language Processing, as the necessary common platform on which new technologies and applications must be based. In order to avoid massive and wasteful duplication of effort, public funding–at least partially–of language resource development is critical to ensure public availability (although not necessarily at no cost). A prerequisite to such a publicly funded effort is careful consideration of the needs of the community, in particular the needs of industry. In a multilingual setting such as today’s global economy, the need for standards is even stronger. In addition to the other motivations for designing common guidelines, there is the need for common specifications so that compatible and harmonized resources for different languages can be built. Finally, clearly defined and agreed upon standards and evaluations will encourage the widespread adoption of resources, and the more they are used the greater the possibility that the user community will be willing to contribute to further maintenance and development.
1.5 References
Agirre, E., X. Arregi, X. Artola, A. Diaz de Ilarazza, K. Sarasola. 1994. Conceptual Distance and Automatic Spelling Correction. Proceedings of the Workshop on Computational Linguistics for Speech and Handwriting Recognition. Leeds, England.
Amsler, R.A. 1980. The Structure of the Merriam-Webster Pocket Dictionary. Ph.D. dissertation in Computer Science, University of Texas, Austin, TX
Bateman, J.A., R.T. Kasper, J.D. Moore, and R.A. Whitney. 1989. A General Organization of Knowledge for Natural Language Processing: The Penman Upper Model. Unpublished research report, USC/Information Sciences Institute, Marina del Rey, CA.
Chaffin, R., D.J. Herrmann, and M. Winston. 1988. A taxonomy of part-whole relations: Effects of part-whole relation type on relation naming and relations identification. Cognition and Language 3 (1—32).
Chapman, R. 1977. Roget’s International Thesaurus, Fourth Edition. New York: Harper and Row.
Charniak, E. 1995. Parsing with Context-Free Grammars and Word Statistics. Technical Report: CS-95-28, Brown University.
Chodorow, M., R. Byrd, and G. Heidorn. 1985. Extracting semantic hierarchies from a large on-line dictionary. Proceedings of the 23rd Annual Meeting of the Association for Computational Linguistics (299—304).
Collins, M. 1997. Three generative, lexicalised models for statistical parsing. Proceedings of the 35th Annual Meeting of the Association for Computational Linguistics. Madrid, Spain.
Copestake, A. and A. Sanfilippo. 1993. Multilingual lexical representation. Proceedings of the AAAI Spring Symposium: Building Lexicons for Machine Translation. Stanford University, California.
Cruse, D.A. 1986. Lexical Semantics. Cambridge: Cambridge University Press.
Dang, H., K. Kipper, M. Palmer, and J. Rosenzweig. 1998. Investigating regular sense extensions based on intersective Levin classes. Proceedings of ACL98. Montreal, Canada.
Dorr, B. 1997. Large-scale dictionary construction for foreign language tutoring and interlingual machine translation. Machine Translation12 (1—55).
Fellbaum, C. 1998. (ed.) WordNet: An On-Line Lexical Database and Some of its Applications. Cambridge, MA: MIT Press
Fillmore, C., P. Kay, and C. O’Connor. 1988. Regularity and idiomaticity in grammatical construction. Language 64 (501—568).
Grishman, R., Macleod C., and Meyers, A. 1994. Comlex Syntax: Building a Computational Lexicon, Proc. 15th Int'l Conf. Computational Linguistics (COLING 94), Kyoto, Japan, August.
Gross, M. 1984.Lexicon-Grammar and the Syntactic Analysis of French, Proceedings of the 10th International Conference on Computational Linguistics (COLING'84), Stanford, California.
Guarino, N. 1997. Some Organizing Principles for a Unified Top-Level Ontology. New version of paper presented at AAAI Spring Symposium on Ontological Engineering, Stanford University, March 1997.
Hearst, M. 1998. Automatic Discovery of WordNet Relations. In C. Fellbaum (ed), WordNet: An On-Line Lexical Database and Some of its Applications (131—151). Cambridge, MA: MIT Press
Hermjakob, U. and R.J. Mooney. 1997. Learning Parse and Translation Decisions from Examples with Rich Context. Proceedings of the ACL/EACL Conference. Madrid, Spain (482—487).
Hindle, D. 1983. User manual for Fidditch. Technical memorandum 7590-142, Naval Research Laboratory.
Hovy, E.H. 1996. Semi-Automated Alignment of Top Regions of SENSUS and CYC. Presented to ANSI Ad Hoc Committee on Ontology Standardization. Stanford University, Palo Alto, September 1996.
Hovy, E.H. 1998. Combining and Standardizing Large-Scale, Practical Ontologies for Machine Translation and Other Uses. Proceedings of the First International Conference on Language Resources and Evaluation (LREC). Granada, Spain.
Jackendoff, R. 1995. The Boundaries of the Lexicon. In M. Everaert, E.J. van den Linden, A. Schenk, and R. Schreuder, (eds), Idioms: Structural and Psychological Perspectives. Hillsdale, NJ: Erlbaum Associates.
Joshi, A.K. 1985. Tree Adjoining Grammars: How much context Sensitivity is required to provide a reasonable structural description. In D. Dowty, L. Karttunen, and A. Zwicky (eds), Natural Language Parsing (206—250). Cambridge: Cambridge University Press.
Joshi, A. and L. Levy, and M. Takahashi. 1975. Tree Adjunct Grammars. Journal of Computer and System Sciences.
Joshi, A.K. and B. Srinivas. 1994. Disambiguation of Super Parts of Speech (or Supertags): Almost Parsing, Proceedings of the 17th International Conference on Computational Linguistics (COLING-94). Kyoto, Japan.
Kilgarriff, A. 1997. Evaluating word sense disambiguation programs: Progress report. Proceedings of the SALT Workshop on Evaluation in Speech and Language Technology. Sheffield, U.K.
Knight, K. and S.K. Luk. 1994. Building a Large-Scale Knowledge Base for Machine Translation. In Proceedings of the AAAI Conference.
Lenat, D.B. and R.V. Guha. 1990. Building Large Knowledge-Based Systems. Reading: Addison-Wesley.
Lowe, J.B., C.F. Baker, and C.J. Fillmore. 1997. A frame-semantic approach to semantic annotation. Proceedings 1997 Siglex Workshop, ANLP97. Washington, D.C.
Mahesh, K. 1996. Ontology Development for Machine Translation: Ideology and Methodology. New Mexico State University CRL report MCCS-96-292.
Marcus, M., B. Santorini, and M. Marcinkiewicz. 1993. Building a large annotated corpus of English: the Penn Treebank. Computational Linguistics Journal, Vol. 19.
Mel’cuk, I. 1988. Semantic description of lexical units in an explanatory combinatorial dictionary: Basic principles and heuristic criteria. International Journal of Lexicography (165—188).
Miller, G.A. 1990. (ed.). WordNet: An on-line lexical database. International Journal of Lexicography 3(4) (235—312).
Nirenburg, S., J. Carbonell, M. Tomita, and K. Goodman. 1992. Machine Translation: A Knowledge-Based Approach. San Mateo: Morgan Kaufmann.
Lee, L., Dagan, I. and Pereira, F. 1997. Similarity-based methods for word sense disambiguation. Proceedings of the 35th Annual Meeting of the Association for Computational Linguistics. Madrid, Spain.
Palmer, M. 1998. Are WordNet sense distinctions appropriate for computational lexicons? Proceedings of Senseval, Siglex98. Brighton, England.
Pustejovsky, J. 1995. The Generative Lexicon. MIT Press
Rappaport Hova, M and B. Levin. 1998. Building Verb Meanings. In M. Butt and W. Geuder (eds.) The Projection of Arguments. Stanford, CA, CSLI Publications.
Ratnaparkhi, A. 1997. A Linear Observed Time Statistical Parser Based on Maximum Entropy Models. Proceedings of the Second Conference on Empirical Methods in Natural Language Processing.
Resnik, P. 1993. Selection and Information: A Class-Based Approach to Lexical Relationships. Ph.D. thesis, University of Pennsylvania, Department of Computer and Information Sciences, 1993.
Rigau, G. and E. Agirre. 1995. Disambiguating Bilingual Nominal Entries against WordNet. Proceedings of the 7th ESSLI Symposium. Barcelona, Spain.
Srinivas, B. 1997. Performance Evaluation of Supertagging for Partial Parsing. Proceedings of Fifth International Workshop on Parsing Technology, Boston.
Steedman, M. 1996. Surface Structure and Interpretation. Cambridge, MA: MIT Press.
Stetina, J. and M. Nagao. 1997. Corpus Based PP Attachment Ambiguity Resolution with a Semantic Dictionary. Proceedings of the Fifth Workshop on Very Large Corpora (66—80). Beijing and Hong Kong.
Stevenson, S. and P. Merlo. 1997. Lexical structure and parsing complexity. Language and Cognitive Processes 12(2/3) (349—399).
Viegas, E., K. Mahesh, and S. Nirenburg. 1996. Semantics in Action. Proceedings of the Workshop on Predicative Forms in Natural Language and in Knowledge Bases, (108—115). Toulouse, France.
Vossen, P., et al. 1999. EuroWordNet. Computers and the Humanities, special issue (in press).
Wille, R. 1992. Concept lattices and conceptual knowledge systems. Computers and Mathematics with Applications 23 (493—515).
The XTAG-Group. 1995. A Lexicalized Tree Adjoining Grammar for English. Technical Report IRCS 95-03, University of Pennsylvania. Updated version available at
http://www.cis.upenn.edu/xtag/tr/tech-report.html.Yarowsky, D. 1995. Three Machine Learning Algorithms for Lexical Ambiguity Resolution. Ph.D. thesis, University of Pennsylvania, Department of Computer and Information Sciences.
[This chapter is available as http://www.cs.cmu.edu/~ref/mlim/chapter2.html .]
[Please send any comments to Robert Frederking (
ref+@cs.cmu.edu, Web document maintainer) or Ed Hovy or Nancy Ide.]
Chapter 2
Multilingual (or Cross-lingual) Information Retrieval
Editors: Judith Klavans and Eduard Hovy
Contributors:
Christian Fluhr
Robert E. Frederking
Doug Oard
Akitoshi Okumura, Kai Ishikawa, and Kenji Satoh
Abstract
The term Multilingual Information Retrieval (MLIR) involves the study of systems that accept queries for information in various languages and return objects (text, and other media) of various languages, translated into the user's language. The rapid growth and online availability of information in many languages has made this a highly relevant field of research within the broad umbrella of language processing research. We ignore here issues pertaining to Machine Translation (Chapter 4) and Multimedia (Chapter 9), and focus on the extensions required of traditional Information Retrieval (IR) to handle more than one language.
2.1 Multilingual Information Retrieval
2.1.1 Definition and Terms
Multilingual Information Retrieval (MLIR) refers to the ability to process a query for information in any language, search a collection of objects, including text, images, sound files, etc., and return the most relevant objects, translated if necessary into the user's language. The explosion in recent years of freely-distributed unstructured information in all media, most notably on the World Wide Web, has opened the traditional field of Information Retrieval (IR) up to include image, video, speech, and other media, and has extended out to include access across multiple languages. Being new, MLIR will probably also include the historically excluded access mechanisms typical of libraries involving structured data, such as MARC catalogue records.
The general field of MLIR has expanded in several directions, focusing on different issues; what exactly is within its purview remains open to discussion. It is generally agreed, however, that Machine Translation proper (see
Chapter 4) and Multimedia processing (see Chapter 9) are not included. Nonetheless, several new terms have arisen around the new IR, each with a slight variation in emphasis, inclusiveness, or historical association with related fields. For example, recent research in multilingual information retrieval, such as (Fluhr et al., 1998) in (Grefenstette, 1998), includes descriptive catalogue data from libraries as well as unstructured data. Hull and Grefenstette (1996) list five uses of the term MLIR:In addition to MLIR, four related terms have been used:
1. Multilingual Information Access (MLIA). The broadest possible term to use is Multilingual Information Access, which refers to query, retrieval, and presentation of information in any language. The term MLIA is used in the NSF-EU working groups (Klavans and Schäuble, 1998). In general, the use of information access rather than retrieval implies a more general set of access functions, including those that have been part of the traditional library, as well as other modalities of access to other media. Access could refer to the use of speech input for video output, where the language component could consist of close-captioned text or text from speech recognition, or catalogue querying to metadata. The term information access came into use recently as a way to broaden the historically narrower use of information retrieval.
2. Multilingual Information Retrieval (MLIR). This term refers to the ability to process a query in any language and return objects, such as text, images, sound files, etc., relevant to the user query in any language. Historically, however, Information Retrieval (IR) as a field involved a group of researchers from the unstructured text data base community who employed statistical methods to match query and document (Salton, 1988). In general, this work was English dominated, given the amount of digital information made available to the research community in the early years in English, and excluded access mechanisms typical of libraries involving structured data, such as MARC catalogue records. Thus MLIR as used in this chapter denotes a significantly wider field of interest than that of traditional IR.
3. Cross-lingual Information Access. The use of the term cross-lingual refers (in this context) to bridging two languages, rather than the ability to access information in any language starting with input any language. Systems with cross-lingual capability can accept a query in language L1 or L2, for example English and French, and are capable of returning documents in either L1 or L2. (In other meetings, the term cross-lingual (or translingual) has been used to distinguish systems that cross a language barrier, as opposed to multiple monolingual systems as in TREC.) This term logically includes access via catalogue record and other structured indexing, as for MLIA.
4. Cross-lingual Information Retrieval (CLIR). CLIR
generally implies a relationship to IR, with all the implications that
apply to MLIR. At the 1997 Cross-language Information Retrieval Spring Symposium of the American Association of Artificial Intelligence (Oard et al., 1997), CLIR was defined with the following research challenge: Given a query in any medium and any language, select relevant items from a multilingual multimedia collection which can be in any medium and any language, and present them in the style or order most likely to be useful to the user, with identical or near-identical objects in different media or languages appropriately identified.
This definition of the requirements of a system gives full recognition to the query, retrieval, presentation requirements of a working system from a user perspective, and encapsulates succinctly the full set of capabilities to be included. However, its breadth makes it fit well with a definition of MLIA, the most general term, rather than CLIR, a more precise term.
2.1.2 MLIR: Linking and Hybridizing IR and MT
Multilingual Information Retrieval is a hybrid subject area, interacting with or encompassing several other fields. Section 2.5 discusses related fields.
How MLIR Relates to Information Retrieval
MLIR is an application of information retrieval. In many respects, as discussed above, the two fields share exactly the same goals; as such, well-known IR techniques such as vector space indexing, latent semantic indexing (LSI), similarity functions for matching documents, and query processing procedures are equally useful in MLIR. However MLIR differs from IR in several significant ways. Most important, IR involves no translation component, since only one language is involved. The related but not identical problems of translating queries and documents are discussed below. Subsidiary problems, such as keeping track of translations across several languages, are also not part of the standard monolingual information retrieval process.
How MLIR Relates to and Uses Machine Translation
The goal in machine translation (MT; see
Chapter 4) is to convert a text, written in language L1, into a coherent and accurate translation in language L2. To do so, most MT systems convert the input text, usually sentence by sentence, into a series of progressively more abstract internal representations, in which sentence-internal relationships are determined and the intended meaning of each word is identified. Armed with this information, the appropriate conversions are made to support the output language, upon which output realization, usually also sentence by sentence, is performed. MT requires that the meaning of each individual word be known (as does accurate IR); without this knowledge, homographs (for example plane, which can refer to an airplane, carpentry tool, geometric surface, the action of skimming over water, and several other meanings) cannot be translated into their intended foreign words. Without word translation, no output is possible.Can MLIR be Achieved by Coupling IR and MT?
Unfortunately, while at first blush it may seem that MLIR is simply a matter of coupling IR and MT engines, the special nature of MLIR places constraints on the input to MT that makes a straightforward coupling infeasible. At one extreme, some recent MLIR research has explored extending IR-based indexing techniques to directly bridge language gaps with no explicit translation step at all; see Sections 2.2.2 and 2.3.1 below. Arguments regarding the special nature of MLIR, contained in the NSF-EU MLIA Working Group White Paper (Klavans and Schäuble, 1998), are summarized here.
Differences between the two types of input submitted by MLIR for translationqueries and documentsnecessitate two different types of Machine Translation. In the case of queries, the input to MT is a set of disconnected words, or possibly multi-word phrases. There is no call for MT to parse the input, since no syntactic sentence structure can be found. More seriously, the MT system cannot apply traditional methods of wordsense disambiguation, since the input is not a semantically coherent text. It will have to employ other (possibly IR-like) methods to determine the sense of each polysemous word in order to furnish accurate translations. On the other hand, there is no need to produce a linear, coherent output, and in fact multiple (correct) translations of a query term can provide a form of query expansion, which can improve IR performance. Finally, the processes of sentence planning and sentence realization are irrelevant when the input is a string of isolated query words. Without accurate queries, IR accuracy falls dramatically (results of recent studies are given later in this chapter).
For the stage of IR after retrieval (that is, in the case of retrieved documents), in contrast, documents can be translated back into the user's language using the normal methods of MT. However, also for this part of MLIR, partial translation, or keyword extraction and translation, is often adequate for the user's needs. In particular, given the computational expense of MT, it may be inefficient to translate a full document that the user later determines is not exactly what was desired. In addition, fully general purpose MT (especially between a wide variety of languages) is a very difficult problem. Translating a few keywords or a summary (see
Chapter 3) is often a wise policy.Several additional differences between monolingual IR and MLIR arise if the user is familiar with more than one language too. In particular, the user interface must provide differential display capabilities to reflect differing language proficiency levels of users. When more than one user receives the results, translation into several languages may have to be provided. Furthermore, depending on the user's level of sophistication, translation of different elements at different stages can be provided to users for a range of information access needs, including keyword translation, term translation, title translation, abstract translation, specific paragraph translation, caption translation, full document translation, etc. Finally, monolingual IR users can also take advantage of the results of MLIR. Simply the knowledge that a particular query will access a certain number of documents in other languages could, in itself, be valuable information, even if translations are not required.
Thus for MLIR much of the typical MT machinery is irrelevant, or at best only partially relevant. The differences with traditional MT mean that MLIR cannot simply employ MT engines as front-end query translators and back-end document translators.
Rather, efficient ways of coupling together the internal processes of IR and MT engines are required, allowing them to employ the results of the other's intermediate results. It is inevitable that second-generation MLIR systems will exhibit some more-than-surface integration of MT and IR modules.
2.1.3 Key Technical Issues for MLIR
We discuss three different positions on what are the key problems in MLIR. Grefenstette (1998) focuses on term choice and filtering. Oard (1998) presents user-centered challenges. Finally, Klavans (1999) outlines a two-part view that accommodates system-directed and user-directed research issues.
Grefenstette (1998) outlines three problems involving the processing of query terms for MLIR:
This problem requires knowing how terms map between languages. Since little or no contextual text is present in the query to help with term disambiguation, this involves knowing the full range of choices of translations, not just one possible translation, coupled with an understanding how different domains affect translation possibilities.
The second problem deals with determining how to filter, from all possible choices, which ones should be retained in the current application. Unlike MT, a MLIR system can retain a wider set of possibilities that can later be automatically filtered, depending on the kinds of variants that are permitted. Thus the MLIR system has to balance the amount of inaccurate translations (noise) that degrade results against the amount of processing performed to disambiguate the terms and ensure accuracy.
Given that it is advisable to retain a set of well-chosen possible terms for the best retrieval performance, a problem new to MLIR arises. The possibility of assigning alternate weights to different translations permits more accurate term choice. For example, in a compound term such as "morphological change", the first word is quite narrow in translation possibilities (e.g., in French, only one translation la morphologie) while the second is more general ("change" could be changement or monnaie). In such cases, more weight could be given to the first word's translation than to the second. This problem is compounded by the fact that some multi-word terms do not decompose, but should be treated as a collocation. Thus, mechanisms for weighing alternatives must consider individual word translation weights as well as multi-word term translation weights.
Grefenstette points out that the first two problems are also found in machine translation, and still require research for fully effective solutions. The third problem is one that clearly distinguishes MLIR from both MT and IR.
Oard (1998), in presentations during the Workshops on MLIR, outlined a historical view of CLIR that is user-centered in nature. He views the overall problem of CLIR as a series of processes, including query formulation and document selection, involving feedback from system to user and from user to system. The system-internal processes of indexing, document processing, and matching are treated as components supporting direct user interaction. He presents three points of historical perspective:
Oard's five challenges for the next five years are given in Section 2.4 below.
Klavans (1999) approaches the central problems in a somewhat different way, focusing on two sets of issues. One set involves three questions relating to the parts of the query-retrieval process, and the other set relates to user needs.
System issues
Usability Issues. IR systems present two main interface challenges: first, how to permit a user to input a query in a natural and intuitive way, and second, how to enable the user to interpret the returned results. A component of the latter encompasses ways to permit a user to comment and provide feedback on results and to iteratively improve and refine results. MLIR brings an added complexity to the standard IR task. Users can have different abilities for different languages, affecting their ability to form queries and interpret results. For example, a user might be proficient in understanding documents in French, but could not produce a query in French. In this case, the user will need to formulate a query in his native language, but will want documents returned only in French, not translated. At the same time, this user may have spotty knowledge of German. In this case, he might request a set of key terms translated to his native language, and not want to view source documents in German at all. Or he may simply want a numerical count, in order to know that for a given query, there are a certain number in German, a certain number in French, a certain number in Vietnamese, and so on. In addition, knowing the specific sources of relevant information may also be very valuable.
Since research and applications in MLIR are so new, a full understanding of user needs has yet to be developed and tested. However, these needs differ from simple MT needs, given the user query production and refinement stages.
2.1.4 Summary of Technical Challenges
MLIR involves at least the following four technical challenges:
2.2 Where We Were Five Years Ago
2.2.1 Capabilities Then
The lure of cross language information retrieval attracted experimentation by the IR community early on. Already in 1971, Salton showed that the use of a transfer dictionary for English and French (a bilingual wordlist with predefined mappings between terms) could be used to translate from a query in one language to another (Salton, 1971). This experiment, although ignoring the realistic and challenging problem of ambiguity, nonetheless served the information retrieval community well in providing a model for a viable approach to cross language IR. However, at the same time, the experiment also illustrated some of the exceedingly difficult problems in the language translation and mapping component of a system, namely one to many mappings, gaps in term translations, and ambiguity. Similarly, in a manual test with a small corpus, Pevzner (1972) showed for English and Russian that a controlled thesaurus can be used effectively for query term translation.
For nearly twenty years, the areas of IR and MT remained separate, leaving MLIR somewhat dormant. Apart from a few forays into refining these early techniques, all significant advances in MLIR have been made in the past five years. This is not surprising, given that increased amounts of information are becoming available in electronic format, and the economy is globalizing.
2.2.2 Major Methods, Techniques, and Approaches Five Years Ago
We discuss the problem within the framework outlined above.
System issues include the following.
Usability issues include the following. Early experiments were performed at such a small scale, more in the nature of proof-of-concept rather than full-fledged large-scale systems. User feedback and user needs were simply not part of what was tested.
2.2.3 Major Bottlenecks and Problems Five Years Ago
The three major bottlenecks of the early part of this decade still persist. They are: limited resources for building domain and language models; limited new technologies for coping with size of collections; and limited understanding of the myriad of user needs.
2.3 Where We Are Today
The burgeoning field of MLIR field is clearly in evidence, as can be seen in the bibliography in the first major review article on the topic (Oard and Dorr, 1996). Papers cited include related work on machine translation, including some research translated from Russian. There are 16 citations prior to 1980, 10 from 1980-89, and 52 from 1990 to early 1996. The first major book to be published on the topic (Grefenstette, 1998) reflects the same temporal bias. This work is slanted towards IR rather than toward MT. It contains 11 citations prior to 1980, 25 from 1980-89, and 101 from 1990 to very early 1998.
2.3.1 Major Methods, Techniques, and Approaches Now
Following the format above, we divide the methods into system-centered and user-centered concerns, although each provides feedback to the other.
System issues include the following:
Usability issues include the following. The development of effective MLIR technology will have no impact if the user's needs and operation patterns are not considered. Since MLIR is a growing field, and since applications are just emerging, formative studies of usability are essential. Currently, there are a limited number of systems in early operation which are providing important data (e.g., EuroSpider, the translate function of AltaVista, multilingual catalogue access). The incorporation of users in the relevance feedback loop is particularly important, since user needs vary greatly. A full review of user needs is found in (Klavans and Schäuble, 1998).
2.3.2 Major Bottlenecks and Problems
Since this is a new field, the bottlenecks listed in Section 2.2.3, evident in earlier years, persist.
2.4 Where We Will Be in Five Years
The growing amount of multilingual corpora is providing a valuable and as yet untapped resource for MLIR. Such corpora are essential to building successful dynamic term and phrase translation thesauri, which is, in turn, key to effective indexing and matching. One of the key challenges is in devising efficient yet linguistically informed methods of tapping these resources, methods which combine the best of what is know about fast statistical techniques along with more knowledge based symbolic methods. Even promising new techniques, such as translingual LSI (Landauer et al., 1998) and related techniques (Carbonell et al., 1997), will most probably still rely on parallel corpora. Such corpora are often difficult to find, and very expensive to prepare. This has been the motivation for the work on comparable corpora. However, more and more are being created electronically, especially to conform to legal requirements for the European Union. The issues surrounding corpora are extensively discussed in
Chapter 1.An important class of techniques involves machine learning, as applied to the cross-language term mapping problem. Since term translation, loosely defined, is at the core of query processing, document processing, and matching, it is an important process to do thoroughly and accurately. Even if multiple translations are retained in the MLIR process, obtaining a sensible set of domain linked terms is an important and central task. One way to obtain these term dictionaries is through parallel corpora, but statistical processing is typically difficult to fine tune. As discussed in
Chapter 6, machine learning techniques are a fundamental enhancement of the power of language processing systems and hold particular promise in this area as well.Finally, it is to be hoped that our understanding of user needs and user interactions with MLIR systems will be significantly better in five years than it is now. As early systems emerge and are tested in the field, a range of flexible and fluid applications that can learn and dynamically adjust to the users' levels of competence, across languages and across domains, should appear. One possible example of this type of flexible application might be human-aided MT systems for producing gisting-quality translations of retrieved documents, which would allow the user to make a personal time/quality tradeoff: the longer the user interacted with the translator, the better the resulting output. Most probably, these systems will incorporate multimedia seamlessly and permit multimodal input and output. Such capabilities will provide maximum usability.
2.4.1 Expected Capabilities
Oard (1998) outlines five challenges for the next five years:
2.4.2 Expected Bottlenecks in Five Years
Four key issues must be overcome in order to achieve effective MLIR. Some of these issues also apply to IR and MT independently.
2.5 Juxtaposition of This Area with Other Areas
Two major classes of technical issues must be addressed when dealing with multilingual data:
First, technical issues involving data exchange, with a set of attendant sub-issues. This includes questions such as character encoding, font displays, browser/display issues, etc. Such issues have implications for metadata for the Internet, international sharing of bibliographic records, and transliteration and transcription systems.
Second, natural language questions, also with a set of attendant research issues. This includes natural language processing technologies (e.g., syntactic or semantic analysis), machine translation, information retrieval (or information discovery) in multiple languages, speech processing, and summarization. Also included are questions of multilingual language resources, such as dictionaries and thesauri, corpora, and test collections.
The new application of MLIR draws on achievements and techniques in several related areas. However, the challenges unique to MLIR must be handled independently. Listing some of the relevant technologies, these include:
Several potentially valuable connections have not yet been made. The Database and Computational Linguistics research and development communities, for example, contain in their members a great deal of relevant expertise. The National Science Foundation PI meeting on Information and Data Management (1998) concluded that closer links between the IR and Database communities would be beneficial to each. Similarly, the human-computer interaction / multimedia community offers important insights into ensuring user-driven design of systems.
In order to facilitate cross-fertilization, a series of small workshops to define new projects, and a series of very small seed projects, would help the specification of prototype systems and the elucidation of complex problem areas. Projects should be interdisciplinary, very limited in scope, with well-defined goals leaving room for exploratory research. The results of such cross-fertilization would depend on the backgrounds of the potential participants. Assembling a group from commerce to assist computer scientists in specifying the needs that MLIR systems must address, or focus groups from high information-needs communities, such as journalism and finance, could be used to specify new projects and prototypes and guide the direction of research in beneficial directions.
2.6 References
Ballesteros, L. and W.B. Croft. 1998. Statistical Methods for Cross-Language Information Retrieval. In G. Grefenstette (ed), Cross-Language Information Retrieval (23-40). Boston: Kluwer.
Carbonell, J., Y. Yang, R. Frederking, R. Brown, Y. Geng, and D. Lee. 1997. Translingual Information Retrieval: A Comparative Evaluation. Proceedings of the Fifteenth International Joint Conference on Artificial Intelligence (IJCAI-97). Nagoya, Japan. Best paper award.
Fluhr, Ch., D. Schmit, Ph. Ortet, F. Elkateb, K. Gurtner, and Kh. Radwan. 1998. Distributed Cross-Language Information Retrieval. In G. Grefenstette (ed), Cross-Language Information Retrieval (41-50). Boston: Kluwer.
Grefenstette, G. (editor) 1998. Cross-Language Information Retrieval. Boston: Kluwer.
Harman, D. (editor) 1995. Proceedings of the 5th Text Retrieval Conference (TREC).
Hull, D. and G. Grefenstette. 1996. Querying across Languages: A Dictionary-Based Approach to Multilingual Information Retrieval. Proceedings of the 19th Annual ACM Conference on Information Retrieval (SIGIR) (49-57).
Klavans and Tzoukermann, 1996. Dictionaries and Corpora: Combining Corpus and Machine-readable Dictionary Data for Building Bilingual Lexicons. Machine Translation 10 (3-4).
Klavans, J. and P. Schäuble. 1998. Report on Multilingual Information Access. Report commissisoned jointly by NSF and EU.
Klavans, J. 1999. Work in progress.
Landauer, T.K, P.W. Foltz, and D. Laham. 1998. An Introduction to Latent Semantic Analysis. Discourse Processes 25(2&3) (259-284).
Leacock, C., G. Towell, and E. Voorhees. 1993. Corpus-Based Statistical Sense Resolution. Proceedings of the DARPA Human Language Technology Workshop (260-265). Princeton, NJ.
Oard, D. and B. Dorr. 1996. A Survey of Multilingual Text Retrieval. Technical Report UMIACS-TR-96-19, University of Maryland Institute for Advanced Computer Studies.
http://www.clis.umd.edu/dlrg/filter/papers/mlir.ps.Oard, D. and B. Dorr. 1998. Evaluating Cross-Language Text Filtering Effectiveness. In G. Grefenstette (ed), Cross-Language Information Retrieval (151-162). Boston: Kluwer.
Oard, D., et al., 1997. Proceedings of the AAAI Spring Symposium on Cross-Language Information Retrieval. San Francisco: Morgan Kaufmann AAAI Press.
Pevzner, B.R. 1972. Comparative Evaluation of the Operation of the Russian and English Variants of the "Pusto-Nepusto-2" System. Automatic Documentation and Mathematical Linguistics 6(2) (71-74). English translation from Russian.
Salton, G. 1971. Automatic Processing of Foreign Language Documents. Englewood Cliffs, NJ: Prentice-Hall.
Salton, G. 1988. Automatic Text Processing. Reading, MA: Addison-Wesley.
Sheridan, P., J.P. Ballerini, and P. Schäuble. 1998. Building a Large Multilingual Test Collection from Comparable News Documents. In G. Grefenstette (ed), Cross-Language Information Retrieval (137-150). Boston: Kluwer.
[This chapter is available as http://www.cs.cmu.edu/~ref/mlim/chapter3.html .]
[Please send any comments to Robert Frederking (ref+@cs.cmu.edu, Web document maintainer) or Ed Hovy or Nancy Ide.]
Chapter 3
Cross-lingual Information Extraction
and Automated Text Summarization
Editor: Eduard Hovy
Contributors:
Ralph Grishman
Jerry Hobbs
Eduard Hovy
Antonio Sanfilippo
Yorick Wilks
Abstract
Information Extraction (IE) and Text Summarization are two methods of extracting relevant portions of the input text. IE produces templates, whose slots are filled with the important information, while Summarization produces one of various types of summary. Over the past 15 years, IE systems have come a long way, with commercial applications being around the corner. Summarization, in contrast, is a much younger enterprise. At present, it borrows techniques from IR and IE, but still requires a considerable amount of research before its unique aspects will be clearly understood.
3.1 Definitions: Information Extraction and Text Summarization
The world of text is huge and expanding. As illustrated by the World Wide Web, important information will continue to become available as text. Two factoids highlight the importance of systems that can accurately and quickly identify the relevant portions of texts automatically: in five years’ time, the major use of computers will be for business and government intelligence, and a large percentage of the data available electronically is in the form of natural language text. A successful information extraction technology therefore has a central role to play in the future of computing.
In this chapter we discuss both Information Extraction (IE) and Automated Text Summarization. At a high level, their goal is the same: find those portion(s) of the given text(s) that are relevant to the user’s task, and deliver that information to the user in the form most useful for further (human or machine) processing. Considering them more closely reveals that IE and Summarization are two sides of a coin, and that a different emphasis of output and techniques results in two quite different-looking branches of technology. In both cases, the input is either a single document or a (huge) collection of documents.
The differences between IE and Summarization lie mainly in the techniques used to identify the relevant information and in the ways that information is delivered to the user. Information Extraction is the process of identifying relevant information where the criteria for relevance are predefined by the user in the form of a template that is to be filled. Typically, the template pertains to events or situations, and contains slots that denote who did what to whom, when, and where, and possibly why. The template builder has to predict what will be of interest to the user and define its slots and selection criteria accordingly. If successful, IE delivers the template, filled with the appropriate values, as found in the text(s). Figure 1 contains three filled templates for the given text.
The Financial Times.
A breakthrough into Eastern Europe was achieved by McDonalds, the American fast food restauranteur, recently through an agreement with Hungary’s most successful agricultural company, Babolna, which is to provide most of the raw materials. Under the joint venture, 5 McDonalds "eateries" are being opened in Budapest which, until now at least, has been the culinary capital of Eastern Europe.
<ENTITY-1375-12> :=
NAME: McDonalds
NATIONALITY: U.S. (COUNTRY)
TYPE: Company
<ENTITY-1375-13> :=
NAME: Babolna
NATIONALITY: Hungary (COUNTRY)
TYPE: Company
<EVENT-12-19007> :=
TYPE: Financial-expansion
PARENT-COMPANY: <ENTITY-1375-12>
SUBSIDIARY-COMPANY: <ENTITY-1375-13>
LOCATION: Hungary (COUNTRY)
SIZE: 5
Figure 1. Example text and templates for Information Extraction.
In contrast, Text Summarization does not necessarily start with a predefined set of criteria of interest; when it does, they are not specified as a template, but at a higher granularity (i.e., expressed in keywords or even whole paragraphs), and hence are less computationally precise. The benefit is that the user can specify dynamically, at run time, what he or she is interested in, but cannot so easily pinpoint exact entities or events or interrelationships. In this, Summarization resembles Information Retrieval (see
Chapter 2). Summarization delivers either an Extract (a verbatim rendition of some portions of the text) or an Abstract (a compressed and reformulated version of the contents of some portions of the text).Generally, from the user’s perspective, IE can be glossed as "I know what specific pieces of information I want–just find them for me!", while Summarization can be glossed as "What’s in the text that is interesting?". Technically, from the system builder’s perspective, the two applications blend into each other. The most pertinent technical aspects are:
Thus, although IE and Summarization blend into one another, the processing performed by IE engines generally involves finite state machines and NLP techniques, while Summarization systems tend to employ IR-like processing.
3.2 Relationships with Other Areas
Both Information Extraction and Text Summarization are related to other language processing applications. For example, Information Retrieval (IR; see
Chapter 2) systems return sets of relevant documents in response to a query; hopefully the answer is contained in the documents. Thus IR can be used to locate strings within fixed corpus windows, producing Summarization (and, in the limit, IE-like) results. This is true mostly for query-based Extract summaries.IE is not the same as Question Answering (QA) by computer, because QA (usually) operates over databases and provides answers to specific queries, one at a time. It is clearly useful in QA applications, however.
Similarly, both Summarization and IE can fruitfully be linked to Machine Translation (MT; see
Chapter 4) to perform multilingual information access. One can, for example, translate a document and then perform IE on it as a whole, or one can first perform IE on it and then just translate the parts that IE returns.Despite such differences, it is becoming apparent that IE, QA, IR, Summarization, and MT form a complex of interrelated information access methods. In a typical application, IR may be performed before IE or summarization, to cut down text search; the database of templates that IE subsequently produces can then be searched with IR or QA, or can be summarized; the results can then be translated by MT. This ordering is not the only one, obviously, but reflects the relative speeds and costs of the different tasks.
Overall, at the present time, Information Extraction and Summarization must be distinguished, on the one hand, from IR (that locates documents or parts of documents, generally using simple keyword techniques), and on the other, from full text understanding (which, if it existed, would be able to process all the information, relevant or not, and determine implicit nuances of meaning and intent, using semantics and inference). Mere document retrieval is inadequate for our needs. Full text understanding does not yet exist. Information extraction and summarization occupy a middle ground, providing needed functionality while at the same time being computationally feasible.
3.3 Where We Were Five Years Ago
3.3.1 Origins and Development of IE
An early instance of what is today called an IE system was FRUMP, the Ph.D. thesis of DeJong at Yale University (DeJong, 1979). Given a newspaper text, its task was to recognize which of approximately seven event templates (earthquake, visit of state, terrorism event, etc.) to employ, and then to fill in the template’s slots with relevant information. Similar work was performed at NYU (Sager, 1970) and other locations. But IE became a serious large-scale research effort in the late 1980s, with the onset of the Message Understanding Conference (MUC) series (MUC, 1996). This series, promoted by the US Department of Defense (through DARPA), has had the beneficial effects of:
As a result, in just under twenty years, an endeavor that was a fledgling dream in 1979 has started coming to market in the late 1990s. Example systems were developed by General Electric and Lockheed.
3.3.2 Origin and Types of Summarization
Automated text summarization is an old dream–the earliest work dates back to the 1950s–that has lain dormant for almost three decades. Only in the last five years has large-scale interest in summarization resurfaced, partly as a result of the information explosion on the Web, but also thanks to faster computers, larger corpora and text storage capacity, and the emergence in Computational Linguistics of statistics-based learning techniques.
Still, little enough is known about summarization per se. Even the (relatively few) studies in Text Linguistics do not provide an exhaustive categorization of the types of summaries that exist. One can distinguish at least the following:
The precise differences between these various types is not yet known, nor the places or tasks for which each is most suitable. The genre-specificity of these types is not known either (for example, biased summaries are probably more relevant to editorials than travel reports). However, as described below, recent research has established some important initial methods, baseline performances, and standards.
3.4 Where We Are Now
3.4.1 IE Today
Information extraction research has been rather successful in the past five or six years. The name recognition components of the leading systems have achieved near-human performance in English and Japanese, and are approaching that in Chinese and Spanish. For the task of event recognition (who did what to whom, when, and where), this technology has achieved about 60% recall and 70% precision, in both English and Japanese (human inter-annotator agreement on this task ranged between 65% and 80% in one study). Both these tasks are approaching human-level performance.
Over the past few years, Information Extraction has developed beyond the initial task, which was simply the extraction of certain types of information from a rather artificial sublanguage of the navy, into a set of distinct subtasks, each one concentrating on one core aspect of IE:
In several of these subtasks, the 60%—70% performance barrier has been notoriously difficult to break through. The scores in the top group in every MUC evaluation since 1993 have been roughly the same (bearing in mind however that the MUC tasks have become more complex). The primary advance has been that more and more sites are able to perform at this level, because the techniques used have converged. Moreover, building systems that perform at this level currently requires a great investment in time and expertise. In addition, the vast bulk of the research so far has been done only on written text and only in English and a few other major languages.
What developments will ensure higher performance? The following aspects deserve further investigation:
Current State and Research Questions for IE
The dominant technology in Information Extraction is finite-state transducers, frequently cascaded (connected in serial) to break a complex problem into a sequence of easier sub-problems; a nice example is provided in (Knight and Graehl, 1997), the transliteration of proper names from Japanese to English. Such transducers have shown their worth in recognizing low-level syntactic constructions, such as noun groups and verb groups, and identifying higher-level, domain-relevant, clausal patterns. A key feature of these transducers is their automatic trainability; they do not require hand-crafted rules, which are difficult and expensive to produce, only enough training examples on which to learn input-output behaviors.
Present-day Information Extraction systems are far from perfect. A deep question is whether system performance (measured, say, by Recall and Precision rates) can be made good enough for serious investment. A second question is whether new applications can be found for which template-like relevance criteria are appropriate; the fact that templates have to be constructed by the system builder, prior to run-time, remains a bottleneck. An important issue is scalability–if the cost of producing templates flexibly and fast for new domains cannot be made acceptable, IE will never enjoy large-scale use. Further questions pertain to improving the effectiveness of results by employing models of the user’s likes and dislikes and tuning lexicons to domains. Finally, although much of the research on IE has focused on scanning news articles and filling templates with the relevant event types and participants, this is by no means the only application. This core technology could be applied to a wide range of natural language applications.
3.4.2 Summarization Today
Before the recent TIPSTER program, North America and Europe combined had fewer than ten research efforts, all small-scale, devoted to the problem. A notable exception was the pioneering experiments of (Jacobs and Rau, 1990). Three of them were part of larger commercial efforts, namely the systems of Lexis-Nexis, Oracle, and Microsoft. No system was satisfactory, and no measures of evaluation were commonly recognized.
Given the youth of summarization research, the past five years has witnessed some rapid growth. Most systems developed today perform simple extraction of the most relevant sentences or paragraphs of a given (single) document, using a variety of methods, many of them versions of those used in IR engines. Where IR systems identify the good documents out of a large set of documents, Extraction Summarizers identify the good passages out of a single document’s large set of passages. Various methods of scoring the relevance of sentences or passages and combining the scores are described in (Miike et al., 1994; Kupiec et al., 1995; Aone et al., 1997; Strzalkowski et al., 1998; Hovy and Lin, 1998).
Naturally, however, there is more to summarization than extraction. Some concept fusion techniques are explored in (Hovy and Lin, 1998) and in (Hahn, 1999). Since they require significant world knowledge (the system requires knowledge not explicitly in the text in order to be able to decide how to fuse selected concepts into a more general, abstract, or encompassing concept), it is not likely that practical-use Abstraction Summarizers will be built in the near future.
Evaluation of Summarization Systems
We focus here on the developments in summarization evaluation, since they express current capabilities. Not counting the evaluation of three systems in China in 1996 and the work at Cambridge University in recent years (Sparck Jones, 1998), there has been one formal Text Summarization evaluation of competing systems performed by a neutral agency, to date. The SUMMAC evaluation (Firmin Hand and Sundheim, 1998; Mani et al., 1998), part of the TIPSTER program in the USA, announced its results in May 1998.
The SUMMAC results show that it is hard to make sweeping statements about the performance of summarization systems, (a) because they are so new; (b) because there are so many kinds of summaries; and (c) because there are so many ways of measuring performance. Generally speaking, however, one must measure two things of a summary: the Compression Ratio (how much shorter is the summary than the original?) and the Omission Ratio (how much information have you retained)? Measuring length is easy, but measuring information (especially relevant information) is hard. Several approximations have been suggested (Hovy and Lin, 1999):
More work is required to understand the best ways of implementing these measures.
The SUMMAC evaluations were applied to 16 participating systems, unfortunately without humans to provide baselines. All systems produced Extracts only. SUMMAC was no small operation; it took some systems over a full day to produce the several thousand summaries, and it took a battery of assessors over two months to do the judgements. The SUMMAC measures were selected partly because they followed the use of IR measures (Recall and Precision). It has been argued that this biased the proceedings toward IR-like systems.
In the Ad Hoc Task (one variant of the classification game), 20 topics were selected, and for each topic, 50 texts had to be summarized, with respect to the topic. This test was supposed to measure how well the system can identify in the originals just the material relevant to the user. To evaluate, human assessors read the summaries and decided if they were relevant to the query topic or not. The more relevant summaries the system produced, the better it was considered to be. It occurred that relevant summaries were produced out of non-relevant originals, a fact not surprising post hoc but something no-one quite knows how to interpret.
In the Categorization Task (another variant of the classification game), 10 topics were selected, and 100 texts per topic. Here the systems did not know the topics, and simply had to produce a generic summary, which human assessors then classified into one of the 10 topic bins. The more its summaries classified in the same bins as their originals, the better the system was considered to be.
In the Q&A Task, 3 topics were selected, and systems received 90 articles per topic to summarize. Of these, 30 summaries were read by assessors, who answered a predefined question set of 4 or 5 (presumably) relevant questions (the same questions for each summary, in each topic) for each summary. The more questions the assessors could answer correctly, the better the system’s summaries were considered.
The Ad Hoc results partitioned the systems into three classes, ranging from F-score (average Recall and Precision) of 73% down to 60%. The Categorization results showed no significant difference between systems, all at approx. 53%. The Q&A results were very length-sensitive, with systems scoring between 45% and 20% (scores normalized by summary length).
Unfortunately, since the evaluation did not include human summaries as baselines, it is impossible to say how well the systems fared in a general way. One can say though that:
3.5 Where We Will Be in Five Years
The current state of affairs for IE and Summarization indicates that we must focus on seven critical areas of research in the near future.
1. Multilinguality (Going beyond English): The IE and Summarization technology must be extended to other languages. As illustrated in MUC-5, the success of the approach in languages as different as English and Japanese is strongly suggestive of the universality of the approach. In the EU, the current Language Engineering projects ECRAN, AVENTINUS, SPARKLE, TREE, and FACILE all address more than one language, while in the US, the MUC-7 task of named entity recognition addressed English, Chinese, Japanese, and Spanish.
Additional work is required on other languages to see which unique problems arise. For example, fundamentally different techniques may be required for languages that make very heavy use of morphology (e.g., Finnish) or have a much freer word order than English. It should not be difficult to get a good start in a large number of languages, since our experience with English and other larger European languages is that a significant level of performance can be gained with rather small grammars for noun groups and verb groups augmented by sets of abstract clause-level patterns. A giant stride toward translingual systems could be achieved by supporting many small projects for doing just this for a large number of languages.
To support such work, it would be useful to develop an automated extraction architecture that works across languages. It should have the following features:
Initial work in this regard is promising; for example, experiments on multilingual extraction have been an excellent basis for international cooperative efforts for NYU, working with other universities on extraction of Spanish, Swedish, and Japanese (Grishman, 1998).
Initial experiments on multilingual text summarization at USC/ISI are also highly promising. To the extent that the summarization engines employ language-neutral methods derived from IR, or to the extent that language-specific methods can be simplified and easily ported to other languages (for example, simple part of speech tagging), it appears that a summarizer producing Extracts for one language can fairly quickly be adapted to work in other languages. The capability to produce extract summaries of Indonesian was added to ISI’s SUMMARIST system in less than two person-months (Lin, 1999), given the fortunate facts that online dictionaries were already at hand and Bahasa Indonesia is not a highly inflected language.
Two possibilities exist for configuring multilingual IE systems. The first is a system that does monolingual IE in multiple languages, one evocation of the system for each language. Here translation occurs twice: once of the template patterns into their language-specific forms, and once after extraction of the extracted information back into the user’s language. The second is a system that does monolingual IE, operating over the documents once they (or some portion of them) have been translated into the user’s language. The tradeoffs here, between translation time/effort, accuracy, and coverage, are exactly the same as those of cross-language Information Retrieval, discussed in
Chapter 2.An additional benefit of multilingual Information Extraction and Summarization is their utility for other applications, such as Machine Translation. Machine Translation is very hard because it is so open-ended. But an IE engine could be applied to the source language text to extract only relevant information, and then only the relevant information would need to be translated. Such an MT system would be much more tractable to build, since its input would be pre-filtered, and in many instances would provide exactly the required functionality; see
Chapter 4.2. Cross-Document Event Tracking (Going beyond Single Documents): Most research in Information Extraction and Summarization has focused on gleaning information from single documents at a time. This has involved recognizing the coreference of entities and events when they are described or referred to in different areas of the text. These techniques could be used to identify the same entities or events when they are talked about in different documents as well. This would allow analysts to track the development of an event as it unfolds across a period of time. Many events of interest–revolutions, troop buildups, hostile takeovers, lawsuits, product developments–do not happen all at once, and if the information from multiple documents can be fused into a coherent picture of the event, the analyst’s job of tracking the event is made much easier. Recent work (the SUMMONS system, (Radev, 1998)) provides some valuable heuristics for identifying cross-document occurrences of the same news, and for recognizing conflicts and extensions of the information at hand.
3. Adaptability (Going beyond Templates): One of the major limitations of current IE systems is that template slots and their associated filling criteria must be anticipated and encoded by the system builder. Much IE research in the past has focused on producing templates that encode the structure of relevant events. This was a useful focus since the kind of information encoded in templates is central in many applications, and the task is easily evaluated. Similarly, the need for run-time user specification of importance criteria was underlined in the SUMMAC Ad Hoc summarization task. But we must shift our focus now more specifically to the ways the technology is to be embedded in real-world applications, useful also to non-Government users.
One approach is to develop methods that recognize internal discourse structure and partition text accordingly. Ongoing work on discourse-level analysis (Marcu, 1997) and text segmentation (Hearst, 1993) holds promise for the future.
Going beyond structural criteria, one can begin to address text meaning itself. A simple approach has been developed for IR and adapted for Summarization systems. Lexical cohesion is one of the most popular basic techniques used in text analysis for the comparative assessment of saliency and connectivity of text fragments. Extending this technique to include simple thesaural relations such as synonymy and hyponymy can help to capture word similarity in order to assess lexical cohesion among text units, although they do not provide thematic characterizations of text units. This problem can be addressed by using a dictionary database providing information about the thematic domain of words (e.g., business, politics, sport). Lexical cohesion can then computed with reference to discourse topics rather than (or in addition to) the orthographic form of words. Such an application of lexical cohesion makes it possible to detect the major topics of a document automatically and to assess how well each text unit represents these topics. Both template extensions for IE and query-based indicative summaries can then be obtained by choosing one or more domain codes, specifying a summary ratio and retrieving the wanted portion of the text that best represents the topic(s) selected. Deriving and storing the required world knowledge is a topic addressed under Ontologies in
Chapter 1.4. Portability and Greater Ease of Use (Going beyond Computational Linguists): We need to achieve high levels of performance with less effort and less expertise. One aspect of this is simply building better interfaces to existing systems, both for the developer and for the end-user. But serious research is also required on the automatic acquisition of template filler patterns, which will enable systems for much larger domains than is typical in today’s MUC evaluations. An underlying ontology and a large library of common, modifiable patterns in the business news and the geopolitical domains would be very useful for analysts seeking to make specially tailored information extraction systems
Several means exist by which such large libraries of patterns can be acquired. Obviously, an analysis of a user’s annotations of texts, performed using a suitable interface, is one way. The recent application of statistical learning techniques to several problems in Computational Linguistics (see
Chapter 6) is another. For such methods, we need ‘smarter’ learning techniques–ones that are sensitive to linguistic structures and semantic relations, and so can learn from a smaller set of examples. In order not to have to learn everything anew, it is important that the systems be able to build upon and adapt prior knowledge.5. Using Semantics (Going beyond Word-Level Processing): Ultimately, we have to transcend the 60%—70% level of performance for IE. As the amount of information available expands, so will the demands for greater coverage and greater accuracy. There are several reasons for this barrier. On the one hand, there are a large number of linguistic problems that must be solved which are infrequent enough that solving any one of them will not have a significant impact on performance. In addition, several problems are pervasive and require general methods going beyond the finite-state or, in some cases, ad hoc approaches that are in use today. These problems include the MUC tasks of entity and event coreference.
More generally, significantly better performance on natural language tasks will require us to tackle seriously the problem of (semantic) inference, or knowledge-based NLP. The primary problem with this as a research program is that there is a huge start-up time, with no immediate payoffs: a very large knowledge base encoding commonsense knowledge must be built up. In order to have a viable research program, it will be necessary to devise a sequence of increments toward full knowledge-based processing, in which each increment yields improved functionality. One possibility for getting this research program started is to experiment with the construction and extension of knowledge bases such as WordNet, SENSUS, and CYC to enable serious natural language processing problems, such as resolving ambiguities, coreference, and metonymies. Some exploratory work has been done in this area as well; see
Chapter 1.The lack of semantic knowledge is a serious shortcoming for Text Summarization. Almost every Text Summarization system today produces Extracts only. The problem is that to produce Abstracts, a system requires world knowledge to perform concept fusion: somewhere it must have recorded that menu+waiter+order+eat+pay can be glossed as visit a restaurant and that he bought apples, pears, bananas, and oranges can be summarized as he bought fruit. The knowledge required is obviously not esoteric; the problem simply is that we do not yet have adequately large collections of knowledge, appropriately organized.
While the query expansion lists of IR are a beginning in this direction, effort should be devoted to the (semi-automated) creation of large knowledge bases. Such knowledge can serve simultaneously to help disambiguate word meanings during semantic analysis, expand queries accurately for IR, determine correct slot filling during IE, enable appropriate concept fusion for Summarization, and allow appropriate word translation in MT.
6. Standardized Evaluation of Summarization (Going beyond IR Measures): While no-one will deny the importance of text summarization, the current absence of standardized methods for evaluating them is a serious shortcoming. Quite clearly, different criteria of measurement apply in the different types of summary; for example, an adequate Extract is generally approximately three 3 times as long as its equivalent Abstract for newspaper texts (Marcu, 1999); and a Query-based summary might seem inadequately slanted from the author’s perspective.
Much NLP evaluation makes the distinction between black-box and glass-box evaluation. For the former, the system–however it may work internally, and whatever its output quality–is evaluated in its capacity to assist users with real tasks. For the latter, some or all of the system’s internal modules and processing are evaluated, piece by piece, using appropriate measures.
A similar approach can obviously be taken for text summarization systems. Jones and Galliers (1996), for example, formulate a version of this distinction as intrinsic vs. extrinsic, the former measuring output quality (only) and the latter measuring assistance with task performance. Most existing evaluations of summarization systems are intrinsic. Typically, the evaluators create a set of ideal summaries, one for each test text, and then compare the output of the summarization engine to it, measuring content overlap in some way (often by sentence or phrase recall and precision, but sometimes by simple word overlap). Since there is no single ‘correct’ ideal summary, some evaluators use more than one ideal per test text, and average the score of the system across the set of ideals. Extrinsic evaluation, on the other hand, is much easier to motivate. The major problem is to ensure that the metric applied does in fact correlate well with task performance efficiency.
Recognizing the problems inherent to summary evaluation, Jing et al. (1998) performed a series of tests with very interesting results. Instead of selecting a single evaluation method, they applied several methods, both intrinsic and extrinsic, to the same (extract only) summaries. Their work addressed two vexing questions: the agreement among human summarizers and the effect of summary length on summary rating. With regard to inter-human agreement, Jing et al. found fairly high consistency in the news genre, but there is some evidence that other genres will deliver less consistency. With regard to summary length, Jing et al. found great sensitivity for both recall and precision, and concluded that precision and recall are not ideal measures, partly due to the interchangeability of some sentences. They find no correlation between summary length and task performance, and recommend that mandating a fixed length can be detrimental to system performance.
The complexity of the problem and the bewildering variety of plausible evaluation measures makes the topic an interesting but far from well-understood one.
7. Multimedia (Going beyond Written Text): Information Extraction and Text Summarization techniques must be applied to other media, including speech, OCR, and mixed media such as charts and tables. Corresponding information must be extracted from visual images, and the information in the various media must be fused, or integrated to form a coherent overall account.
Chapter 9 discusses the cross-relationships of information in different media.With respect to speech and OCR, the input to the Information Extraction or Summarization system is more noisy and more ambiguous. But it could be that extraction technology could be used to reduce this ambiguity, for example, by choosing the reading that is richest in domain-relevant information.
Speech lacks the capitalization and punctuation that provide important information in written text, but it has intonation that provides similar or even richer information. We need to learn how to exploit this to the full.
In analyzing broadcast news, a wide variety of media come into play. A scene of men in suits walking through a door with flash bulbs going off may be accompanied by speech that says Boris Yeltsin attended a meeting with American officials yesterday, over a caption that says "Moscow". All of this information contributes to an overall account of the scene, and must be captured and fused.
The creation of non-text summaries out of textual material, such as the tabulation of highly parallel information in lists and tables, is a research topic for Text Summarization with high potential payoff.
3.6 Conclusion
IE and Summarization technologies, even at the current level of performance, have many useful applications. Two possibilities are data mining in large bodies of text and the improvement of precision in document retrieval applications such as web searches. The strong influence of the US Department of Defense on IE development has somewhat obscured the fact that commercial IE will have to be automatically adaptable to new domains. Important IE application areas include searching patents, searching shipping news, searching financial news, searching for terrorist or drug related news reports, searching entertainment information, searching (foreign) Internet material (see
Chapter 2). Applications for Summarization include handling of specialized domains and genres (such as legal and medical documents), summarization for educational purposes, news watch for business (say, for tracking competition) or intelligence (for tracking events in foreign countries), and so on.In both cases, more work will greatly improve the utility of current technology. Although early IE and Summarization systems can be found on the market, they do not yet perform at levels useful to the average person, whether for business or education. The ability to tailor results to the user’s current purpose is central, as well as the ability to merge information from multiple languages and multiple sources. A longer-term goal is the ability to merge and fuse information into abstractions, generalizations, and possibly even judgments.
At present, funding for IE and Summarization is at an all-time low. The US umbrella for IE and summarization, TIPSTER, ended in 1998. The joint NSF-EU call for cross-Atlantic collaboration on Natural Language Processing issues holds some hope that research will commence again in 2000. Given the importance of these applications, the progress made in the past five years, and the many unanswered questions remaining about IE and Text Summarization, further research on these topics is likely to be highly beneficial.
3.7 References
Aone, C., M.E. Okurowski, J. Gorlinsky, B. Larsen. 1997. A Scalable Summarization System using Robust NLP. Proceedings of the Workshop on Intelligent Scalable Text Summarization, 66—73. ACL/EACL Conference, Madrid, Spain.
DeJong, G.J. 1979. FRUMP: Fast Reading and Understanding Program. Ph.D. dissertation, Yale University.
Firmin Hand, T. and B. Sundheim. 1998. TIPSTER-SUMMAC Summarization Evaluation. Proceedings of the TIPSTER Text Phase III Workshop. Washington.
Grishman, R. and B. Sundheim (eds). 1996. Message Understanding Conference 6 (MUC-6): A Brief History. Proceedings of the COLING-96 Conference. Copenhagen, Denmark (466—471).
Hovy, E.H. and C-Y. Lin. 1998. Automating Text Summarization in
SUMMARIST. In I. Mani and M. Maybury (eds), Advances in Automated Text Summarization. Cambridge: MIT Press.Hovy, E.H. and C-Y. Lin. 1999. Automated Multilingual Text Summarization and its Evaluation. Submitted.
Jing, H., R. Barzilay, K. McKeown, and M. Elhadad. 1998. Summarization Evaluation Methods: Experiments and Results. In E.H. Hovy and D. Radev (eds), Proceedings of the AAAI Spring Symposium on Intelligent Text Summarization (60—68).
Jones, K.S. and J.R.Galliers. 1996. Evaluating Natural Language Processing Systems: An Analysis and Review. New York: Springer.
Knight, K. and J. Graehl. 1997. Machine Transliteration. Proceedings of the 35th ACL-97 Conference. Madrid, Spain, (128—135).
Lin, C-Y. 1999. Training a Selection Function for Extraction in S
UMMARIST. Submitted.Marcu, D. 1997. The Rhetorical Parsing, Summarization, and Generation of Natural Language Texts. Ph.D. dissertation, University of Toronto.
Marcu, D. 1999. The Automatic Construction of Large-scale Corpora for Summarization Research. Forthcoming.
Jacobs, P.S. and L.F. Rau. 1990. SCISOR: Extracting Information from On-Line News. Communications of the ACM 33(11): 88—97.
Kupiec, J., J. Pedersen, and F. Chen. 1995. A Trainable Document Summarizer. In Proceedings of the 18th Annual International ACM Conference on Research and Development in Information Retrieval (SIGIR), 68—73. Seattle, WA.
Mani, I. et al. 1998. The TIPSTER Text Summarization Evaluation: Initial Report.
Miike, S., E. Itoh, K. Ono, and K. Sumita. 1994. A Full-Text Retrieval System with Dynamic Abstract Generation Function. Proceedings of the 17th Annual International ACM Conference on Research and Development in Information Retrieval (SIGIR-94), 152—161.
Radev, D. 1998. Generating Natural Language Summaries from Multiple On-Line Sources: Language Reuse and Regeneration. Ph.D. dissertation, Columbia University.
Reimer, U. and U. Hahn. 1998. A Formal Model of Text summarization Based on Condensation Operators of a Terminological Logic. In I. Mani and M. Maybury (eds), Advances in Automated Text Summarization. Cambridge: MIT Press.
Sager, N. 1970. The Sublanguage Method in String Grammars. In R.W. Ewton, Jr. and J. Ornstein (eds.), Studies in Language and Linguistics (89—98).
Sparck Jones, K. 1998. Introduction to Text Summarisation. In I. Mani and M. Maybury (eds), Advances in Automated Text Summarization. Cambridge: MIT Press.
Strzalkowski, T. et al., 1998. ? In I. Mani and M. Maybury (eds), Advances in Automated Text Summarization. Cambridge: MIT Press.
[This chapter is available as http://www.cs.cmu.edu/~ref/mlim/chapter4.html .]
[Please send any comments to Robert Frederking (ref+@cs.cmu.edu, Web document maintainer) or Ed Hovy or Nancy Ide.]
Chapter 4
Machine Translation
Editor: Bente Maegaard
Contributors:
Nuria Bel
Bonnie Dorr
Eduard Hovy
Kevin Knight
Hitoshi Iida
Christian Boitet
Bente Maegaard
Yorick Wilks
Abstract
Machine translation is probably the oldest application of natural language processing. Its 50 years of history have seen the development of several major approaches and, recently, of a new enabling paradigm of statistical processing. Still, today, there is no dominant approach. Despite the commercial success of many MT systems, tools, and other products, the main problem remains unsolved, and the various ways of combining approaches and paradigms are only beginning to be explored.
4.1 Definition of MT
The term machine translation (MT) is normally taken in its restricted and precise meaning of fully automatic translation. However, in this chapter we consider the whole range of tools that may support translation and document production in general, which is especially important when considering the integration of other language processing techniques and resources with MT. We therefore define Machine Translation to include any computer-based process that transforms (or helps a user to transform) written text from one human language into another. We define Fully Automated Machine Translation (FAMT) to be MT performed without the intervention of a human being during the process. Human-Assisted Machine Translation (HAMT) is the style of translation in which a computer system does most of the translation, appealing in case of difficulty to a (mono- or bilingual) human for help. Machine-Aided Translation (MAT) is the style of translation in which a human does most of the work but uses one of more computer systems, mainly as resources such as dictionaries and spelling checkers, as assistants.
Traditionally, two very different classes of MT have been identified. Assimilation refers to the class of translation in which an individual or organization wants to gather material written by others in a variety of languages and convert them all into his or her own language. Dissemination refers to the class in which an individual or organization wants to broadcast his or her own material, written in one language, in a variety of language to the world. A third class of translation has also recently become evident. Communication refers to the class in which two or more individuals are in more or less immediate interaction, typically via email or otherwise online, with an MT system mediating between them. Each class of translation has very different features, is best supported by different underlying technology, and is to be evaluated according to somewhat different criteria.
4.2 Where We Were Five Years Ago
Machine Translation was the first computer-based application related to natural language, starting after World War II, when Warren Weaver suggested using ideas from cryptography and information theory. The first large-scale project was funded by the US Government to translate Russian Air Force manuals into English. After a decade of initial optimism, funding for MT research became harder to obtain in the US. However, MT research continued to flourish in Europe and then, during the 1970s, in Japan. Today, over 50 companies worldwide produce and sell translations by computer, whether as translation services to outsiders, as in-house translation bureaux, or as providers of online multilingual chat rooms. By some estimates, MT expenditure in 1989 was over $20 million worldwide, involving 200—300 million pages per year (Wilks 92).
Ten years ago, the typical users of machine translation were large organizations such as the European Commission, the US Government, the Pan American Health Organization, Xerox, Fujitsu, etc. Fewer small companies or freelance translators used MT, although translation tools such as online dictionaries were becoming more popular. However, ongoing commercial successes in Europe, Asia, and North America continued to illustrate that, despite imperfect levels of achievement, the levels of quality being produced by FAMT and HAMT systems did address some users’ real needs. Systems were being produced and sold by companies such as Fujitsu, NEC, Hitachi, and others in Japan, Siemens and others in Europe, and Systran, Globalink, and Logos in North America (not to mentioned the unprecedented growth of cheap, rather simple MT assistant tools such as PowerTranslator).
In response, the European Commission funded the Europe-wide MT research project Eurotra, which involved representatives from most of the European languages, to develop a large multilingual MT system (Johnson, et al., 1985). Eurotra, which ended in the early 1990s, had the important effect of establishing Computational Linguistics groups in a several countries where none had existed before. Following this effort, and responding to the promise of statistics-based techniques (as introduced into Computational Linguistics by the IBM group with their MT system CANDIDE), the US Government funded a four-year effort, pitting three theoretical approaches against each other in a frequently evaluated research program. The CANDIDE system (Brown et al., 1990), taking a purely-statistical approach, stood in contrast to the Pangloss system (Frederking et al., 1994), which initially was formulated as a HAMT system using a symbolic-linguistic approach involving an interlingua; complementing these two was the LingStat system (Yamron et al., 1994), which sought to combine statistical and symbolic/linguistic approaches. As we reach the end of the decade, the only large-scale multi-year research project on MT worldwide is Verbmobil in Germany (Niemann et al., 1997), which focuses on speech-to-speech translation of dialogues in the rather narrow domain of scheduling meetings.
4.3 Where We Are Today
Thanks to ongoing commercial growth and the influence of new research, the situation is different today from ten years ago. There has been a trend toward embedding MT as part of linguistic services, which may be as diverse as email across nations, foreign-language web searches, traditional document translation, and portable speech translators with very limited lexicons (for travelers, soldiers, etc.; see
Chapter 7).In organizations such as European Commission, large integrated environments have been built around MT systems; cf. the European Commission Translation Service’s Euramis (Theologitis, 1997).
The use of tools for translation by freelancers and smaller organizations is developing quickly. Cheap translation assistants, often little more than bilingual lexicons with rudimentary morphological analysis and some text processing capability, are making their way to market to help small companies and individuals write foreign letters, email, and business reports. Even the older, more established systems such as Globalink, Logos, and Systran, offer pared-down PC-based systems for under $500 per language pair. The Machine Translation Compendium available from the International Association of MT (Hutchins, 1999) lists over 77 pages of commercial MT systems for over 30 languages, including Zulu, Ukrainian, Dutch, Swahili, and Norwegian.
MT services are offered via the Internet, often free for shorter texts; see the websites of
Systran and Lernout and Hauspie. In addition, MT is increasingly being bundled with other web services; see the website of Altavista, which is linked to Systran.4.3.1 Capabilities Now
General purpose vs. Domain-specific: Most (commercial) systems are meant to be general purpose. Although the performance is actually not always very good, the systems are used anyway. However, if the systems were better, MT would be used a whole lot more--given the explosion of information in the world, the demand for translation is booming, and the only possible answer to this demand is MT (in all its forms).
Domain-specific systems deliver better performance, as they can be tailor-made to specific text types. TAUM-METEO, for example, contains a lexicon of only 220 words, and produces translations of weather reports at 98% accuracy; PaTrans (Maegaard and Hansen, 1995) translates abstracts of chemical reports at high quality. However, domain specific systems exhibit two drawbacks: they are only cost-effective in large-volume domains, and maintaining many domain-specific systems may not be manageable; cf. Section 4.3.3 below.
4.3.2 Major Methods, Techniques and Approaches
Statistical vs. Linguistic MT
One of the most pressing questions of MT results from the recent introduction of a new paradigm into Computational Linguistics. It had always been thought that MT, which combines the complexities of two languages (at least), requires highly sophisticated theories of linguistics in order to produce reasonable quality output.
As described above, the CANDIDE system (Brown et al., 1990) challenged that view. The DARPA MT Evaluation series of four MT evaluations, the last of which was held in 1994, compared the performance of three research systems, more than 5 commercial systems, and two human translators (White et al., 1992—94). It forever changed the face of MT, showing that MT systems using statistical techniques to gather their rules of cross-language correspondence were feasible competitors to traditional, purely hand-built ones. However, CANDIDE did not convince the community that the statistics-only approach was the optimal path; in developments since 1994, it has included steadily more knowledge derived from linguistics. This left the burning question: which aspects of MT systems are best approached by statistical methods, and which by traditional, linguistic ones?
Since 1994, a new generation of research MT systems is investigating various hybridizations of statistical and symbolic techniques (Knight et al., 1995; Brown and Frederking, 1995; Dorr , 1997; Nirenburg et al., 1992; Wahlster, 1993; Kay et al., 1994). While it is clear by now that some modules are best approached under one paradigm or the other, it is a relatively safe bet that others are genuinely hermaphroditic, and that their best design and deployment will be determined by the eventual use of the system in the world. Given the large variety of phenomena inherent in language, it is highly unlikely that there exists a single method to handle all the phenomena--both in the data/rule collection stage and in the data/rule application (translation) stage--optimally. Thus one can expect all future non-toy MT systems to be hybrids. Methods of statistics and probability combination will predominate where robustness and wide coverage are at issue, while generalizations of linguistic phenomena, symbol manipulation, and structure creation and transformation will predominate where fine nuances (i.e., translation quality) are important. Just as we today have limousines, trucks, passenger cars, trolley buses, and bulldozers, just so we will have different kind of MT systems that use different translation engines and concentrate on different functions.
One way to summarize the essential variations is as follows:
Feature Symbolic Statistical
robustness/coverage: lower higher
quality/fluency: higher lower
representation: deeper shallower
How exactly to combine modules into systems, however, remains a challenging puzzle. As argued in (Church and Hovy, 1993), one can use MT function to identify productive areas for guiding research. The `niches of functionality’ provide clearly identifiable MT goals. Major applications include:
assimilation tasks: lower quality, broad domains – statistical techniques predominate
dissemination tasks: higher quality, limited domains – symbolic techniques predominate
communication tasks: medium quality, medium domain – mixed techniques predominate
Ideally, systems will employ statistical techniques to augment linguistic insights, allowing the system builder, a computational linguist, to specify the knowledge in the form most convenient to him or her, and have the system perform the tedious work of data collection, generalization, and rule creation. Such collaboration will capitalize on the (complementary) strengths of linguist and computer, and result in much more rapid construction of MT systems for new languages, with greater coverage and higher quality. Still, how exactly to achieve this optimal collaboration is far from clear.
Chapter 6 discusses this tradeoff in more detail.Rule-based vs. Example-based MT
Most production systems are rule-based. That is, they consist of grammar rules, lexical rules, etc. More rules lead to more sophistication and more complexity, and may in the end develop into systems that are quite difficult to maintain. (Typical commercial MT systems contain between a quarter and a half million words and 500—1000 grammar rules for each of the more complex languages.) Consequently, alternative methods have been sought.
Translation by analogy, usually called memory-based or example-based translation (EBMT), see (Nagao, 1984), is one answer to this problem. An analogy-based translation system has pairs of bilingual expressions stored in an example database. The source language input expression is matched against the source language examples in the database, and the best match is chosen. The system then returns the target language equivalent of this example as output, i.e., the best match is based only on the source database, different translations of the source are not taken into account. Just as for translation memories, the analogy-based translation builds on approved translations, consequently the quality of the output is expected to be high.
Unfortunately, however, purely analogy-based systems have problems with scalability: the database becomes too large and unmanageable for systems with a realistic coverage. Consequently, a combination of the rule-based approach and the analogy-based approach is the solution. We are seeing many proposals for such hybrid solutions and this is certainly one of the areas that will bring practical MT further.
Transfer vs. Interlingual MT
Current rule-based MT uses either the Transfer architecture or the Interlingua architecture. These approaches can be diagrammed as:
Interlingua approach:
Source text --[analysis]-- Interlingua --[synthesis]-- Target text
Transfer approach:
Source text --[analysis]-- IntermediateStructure(source) --[transfer]--
IntermediateStructure(target) --[synthesis]-- Target text
The IntermediateStructure is a (usually grammatical) analysis of the text, one sentence at a time. The Interlingua is a (putatively) language-neutral analysis of the text. The theoretical advantage of the Interlingua approach is that one can add new languages at relatively low cost, by creating only rules mapping from the new language into the Interlingua and back again. In contrast, the Transfer approach requires one to build mapping rules from the new language to and from each other language in the system.
The Transfer approach involves a comparison between just the two languages involved. The transfer phase exactly compares lexical units and syntactic structures across the language gap and uses mapping rules to convert the source IntermediateStructure into the target IntermediateStructure representation (Tsujii, 1990). These rules, plus any additional semantic or other information, are stored in dictionaries or knowledge bases. In the transfer approach, nothing is decided a priori about the depth of analysis, i.e., the depth of analysis can depend on the closeness of the languages involved--the closer the languages, the shallower the analysis.
However, for high quality translations, syntactic analysis or shallow semantic analysis is often not enough. Effective translation may require the system to ‘understand’ the actual meaning of the sentence. For example, "I am small" is expressed in many languages using the verb "to be", but "I am hungry" is often expressed using the verb "to have", as in "I have hunger". For a translation system to handle such cases (and their more complex variants), it needs to have information about hunger and so on. Often, this kind of information is represented in so-called case frames, small collections of attributes and their values. The translation system then requires an additional analysis module, usually called the semantic analyzer, additional (semantic) transfer rules, and additional rules for the realizer. The semantic analyzer produces a case frame from the syntax tree, and the transfer module converts the case frame derived from the source language sentence into the case frame format of the target language.
Going to the limit, the Interlingual approach requires a full analysis leading to an abstract representation that is independent of the source language, so that the synthesis of the target sentence can be made without any knowledge of what the source language was. This step may require adding a considerable amount of information, even some that is not present in the input text explicitly. For example, since in Arabic paired entities are pluralized differently from other multiples, the system must be told whether a multiple entity in a sentence is (likely to be) a pair: "her eyes flashed" and "all eyes were on the speaker" differ in this regard. Such addition information improves output quality, but at what price? The addition of information, in particular semantic and extra-linguistic information, can be complex and time-consuming. Semantic knowledge is generally stored in a knowledge base or an ontology or concept lexicon (see
Chapter 1). In the system KBMT-89 (Nirenburg et al., 1992) such knowledge is used to obtain an unambiguous interlingual representation, but in fact a knowledge base of this type can also be used to augment transfer systems. Generally, the interlingual representation is reached via a number of steps. KBMT-89 first performs syntactic analysis using a Lexical Functional Grammar, translates lexical entries into their interlingual counterparts using the concept dictionary, performs structural changes from the LFG structures into interlingual structures, and finally executes sentence planning and synthesis in the target language.As mentioned above, the Interlingua approach requires less work to add a new language than the Transfer approach. However, to date no convincing large-scale Interlingua notation has yet been built. All interlingual MT systems to date have operated at the scale of demonstration (a few hundred lexical items) or prototype (a few thousand). Though a great deal has been written about interlinguas, but no clear methodology exists for determining exactly how one should build a true language-neutral meaning representation, if such a thing is possible at all (Whorf, 1956; Nirenburg et al., 1992; Hovy and Nirenburg, 1992; Dorr, 1994).
In practical systems, the transfer approach is often chosen simply because it is the simplest and scales up the best. This is an important virtue in the development of production systems. However, researchers will continue to pursue the Interlingual approach for a variety of reasons. Not only does it hold the promise of decreasing the cost of adding a new language, but it also encourages the inclusion of deeper, more abstract levels of representation, including discourse structure and interpersonal pragmatics, than are included in transfer structures.
Multi-Engine MT
In recent years, several different methods of performing MT–transfer, example-based, simple dictionary lookup, etc.–have all shown their worth in the appropriate circumstances. A promising recent development has been the attempt to integrate various approaches into a single multi-engine MT system. The idea is very simple: pass the sentence(s) to be translated through several MT engines in parallel, and at the end combine their output, selecting the best fragment(s) and recomposing them into the target sentence(s).
This approach makes admirable use of the strengths of each type of MT. For example, since Example-Based Translation is very effective in handling a wide variety of natural speech expressions and incomplete sentences, it is best employed when phrases or fixed subphrases are translated. However, for fully formed, complex grammatical sentences, the analysis stages typically included in the Transfer and Interlingual approaches is still required. The ATR Cooperative Integrated Translation project has constructed a multi-engine mechanism by an analytical method via a bottom-up chart parser mechanism (Maegaard and Hansen, 1995). Using this mechanism the project has realized a prototype system for multilingual translation by preparing language patterns of source language expression examples and translation examples for each language pair. The system characterized as ‘chat translation’ performs two kind of two-way translation, namely Japanese-English and Japanese-Korean, and moreover, one-way Japanese to German. It outputs the synthesized speech in these four languages. It has been designed for translating travel arrangement dialogues between an information service and tourists.
Another example of multi-engine MT is Pangloss (Frederking et al., 1994). This MT system combined a multilingual dictionary, an Example-Based engine, and a full-fledged KBMT-style Interlingua system into one framework. During translation, each engine assigned a score to each fragment of its output. After normalizing these scores, the post-translation integrator module placed all output fragments in a chart, in parallel. In early versions, the system then employed a dynamic programming algorithm to traverse the chart, select the best-scoring set of fragments (of whatever size), and combine the fragments into the resulting output sentences. Later versions employed statistical language modeling, as used in speech recognition, to combine the scores with the a priori likelihood of the resulting sequence of words (Brown and Frederking, 1995).
Speech-to-Speech Translation
Current commercially available technology makes speech to speech translation already possible and usable. The Verbmobil project (Niemann et al., 1997) and others are discussed in
Chapter 7.4.3.3 Major Bottlenecks and Problems
Some bottlenecks have already been mentioned above, especially in Section 4.3.2.
A rather depressing (for researchers) fact that we do know today can be stated as follows: generally, the older a system, the better its performance, regardless of the modernity of its internal operations. Why is this?
MT, as all NLP applications, deals with language. Language requires a lot of information: lexical, grammatical, translation equivalences, etc. Whatever way this knowledge is used (and the differences constitute the basis for the different approaches to MT), this knowledge must be instantiated (in dictionaries, in rules, in repository of examples, in collections of parallel texts) and processed. These two factors--knowledge collection and effective knowledge use--form the major bottlenecks faced nowadays not only for MT but for all NLP systems.
One approach is to talk of performant MT and NLP, rather than of MT (and NLP) in the abstract. Although systems are sometimes designed as to cope with general, unrestricted language, in the end it usually turns out that in order to make them performant some customization is required. This gives rise to problems of coverage, because it seems unlikely that either linguistic or statistical approaches alone can actually cope with all the possibilities of a given language. Where statistical systems can collect, sort, and classify large volumes of data, and can perhaps filter out uncommon or strange usage, linguistic insights are required to guide the statistical processing in order to operate at effective levels of abstraction. One does not, for example, build a statistical NLP system to consider all the words of four letters, or all the words beginning with the letter t. The ways one limits the statistics, and the linguistic levels at which one chooses to operate, both circumscribe the coverage of the system, and ultimately determine where (and if) it will be performant in practice.
Much more experience is needed in the question of statistics-based MT before it will be clear where the performance limits lie. It is clear that statistical techniques can be used effectively to overcome some of the knowledge acquisition bottlenecks–to collect words and phrases, for example. But can it be used to find concepts, those Interlingual units of meaning that are essential for high-quality translation? It is also clear that statistical methods help with some of the basic processes of MT–word segmentation, part of speech tagging, etc. But can they help with analysis, that process of sentence decomposition without which non-trivial MT is impossible?
A second bottleneck is partially addressed by the multi-engine approach. One can quite confidently assume that no single MT technique is going to provide the best answer in all cases, for all language styles. Furthermore, for applications such as text scanning, a rough translation is quite sufficient, and so a more detailed, but slower and more expensive, translation is not required. How can one best combine various MT engines, weaving together their outputs into the highest quality sentences? How can one combine experimental research systems (that may produce output only in some cases, but then do very well) with tried and true commercial systems (that always produce something, though it might be of low quality)? These questions are not necessarily deep, but they are pressing, and they should be investigated if we are to achieve true general-purpose FAMT.
For speech-to-speech translation, evaluation (Carter et al., 1997) shows that fundamental research is still badly needed to improve overall quality and increase usability, in particular on:
Current research focuses on almost fully automatic systems, leading to extremely specific, task-dependent systems. While they can be useful, we should not repeat the errors of the 1970s. We should focus on computerized assistance for interpreters (to help several conversations partially conducted directly in some common language or indirectly through some imperfect spoken translation system) for active listeners wanting to better understand speech in a foreign language (conversation, radio, TV).
4.3.4 Breakthroughs
Several applications have proven to be able to work effectively using only subsets of the knowledge required for MT. It is possible now to evaluate different tasks, to measure the information involved in solving them, and to identify the most efficient techniques for a given task. Thus, we must face the decomposition of monolithic systems, and to start talking about hybridization, engineering, architectural changes, shared modules, etc. It is important when identifying tasks to evaluate linguistic information in terms of what is generalizable, and thus a good candidate for traditional parsing techniques (argument structure of a transitive verb in active voice?), and what is idiosyncratic (what about collocations?). Besides, one cannot discard the power of efficient techniques that yield better results than older approaches, as illustrated clearly by part of speech disambiguation, which has proved to be better solved using Hidden Markov Models than traditional parsers. On the other hand, it has been proven that good theoretically motivated and linguistically driven tagging label sets improve the accuracy of statistical systems. Hence we must be ready to separate the knowledge we want to represent from the techniques/formalisms that have to process it.
In order to cope with hybrid architectures, the role of the lexicon is fundamental. As discussed in
Chapter 1, the lexicon(s) must supply all the modules with the relevant information, and, in order to detect when and where to supply information to one or another module, all the information must be interrelated and structured. Exhaustive information about both idiosyncratic and general issues must be encoded in an application independent way. Only then can we start talking about reusability of resources. In addition, the lexicon must incorporate generative components to overcome redundancy and to foresee productivity. However, as mentioned, exhaustivity creates problems of data overkill, requiring (for example) sophisticated word sense disambiguation techniques. One could also try to reduce the complexity of MT by organizing information under multilingual or cross-lingual generalizations, in the way it was tried in the Eurotra research program (Johnson et al., 1985). In summary, we should be concerned with identifying what techniques can lead to better results under separation of phenomena: transfer vs. interlingua (including ontologies), grammar-based vs. example-based techniques, and so on. We should be willing to view alternatives not as competing approaches but as complementary techniques, the key point being to identify how to structure and to control the combination of all of them.4.4 Where We Will Be in Five Years
4.4.1 Expected Capabilities
One important trend, of which the first instances can be seen already, is the availability of MT for casual, one-off, use via the Internet. Such services can either be standalone MT (as is the case for
Lernout and Hauspie and Systran) or bundled with some other application, such as web access (as is the case with website of Altavista and Systran), multilingual information retrieval in general (see Chapter 2), text summarization (see Chapter 3), and so on.A second trend can also be recognized: the availability of low-quality portable speech-to-speech MT systems. An experimental system constructed at Carnegie Mellon University in the USA was built for use in Bosnia. Verbmobil handles meeting scheduling in spoken German, French, and English. It is expected that these domains will increase in size and complexity as speech recognition becomes more robust; see
Chapter 5 and Chapter 7.As analysis and generation theory and practice becomes more standardized and established, the focus of research will increasingly turn to methods of constructing low-quality yet adequate MT systems (semi-)automatically. Methods of automatically building multilingual lexicons and wordlists involve bitext alignment and word correspondence discovery; see (Melamed, 1998; Wu, 1995; Fung and Wu, 1995;
Chapter 1).4.4.2 Expected Methods and Techniques
It is clear from the discussion above that future developments will include highly integrated approaches to translation (integration of translation memory and MT, hybrid statistical-linguistic translation, multi-engine translation systems, and the like). We are likely to witness the development of statistical techniques to address problems that defy easy formalization and obvious rule-based behavior, such as sound transliteration (Knight and Graehl, 1997), word equivalence across languages (Wu, 1995), wordsense disambiguation (Yarowsky, 1995), etc. The interplay between statistical and symbolic techniques is discussed in
Chapter 6.Two other ongoing developments do not draw much on empirical linguistics. The first is the continuing integration of low-level MT techniques with conventional word processing to provide a range of aids, tools, lexicons, etc., for both professional and occasional translators. This is now a real market, assisting translators to perform, and confirms Martin Kay’s predictions (Kay,1997; reprint) about the role of machine-aided human translation some twenty years ago. Kay’s remarks predated the more recent empirical upsurge and seemed to reflect a deep pessimism about the ability of any form of theoretical linguistics, or theoretically motivated computational linguistics, to deliver high-quality MT. The same attitudes underlie (Arnold et al., 1994), which was produced by a group long committed to a highly abstract approach to MT that failed in the Eurotra project; the book itself is effectively an introduction to MT as an advanced form of document processing.
The second continuing development, set apart from the statistical movement, is a continuing emphasis on large-scale handcrafted resources for MT. This emphasis implicitly rejects the assumptions of the empirical movement that such resources could be partly or largely acquired automatically by, e.g., extraction of semantic structures from machine readable dictionaries, of grammars from treebanks or by machine learning methods. As described in
Chapter 1, efforts continue in a number of EC projects, including PAROLE/SIMPLE and EuroWordNet (Vossen et al., 1999), as well as on the ontologies WordNet (Miller et al., 1995), SENSUS (Knight and Luk, 1994; Hovy, 1998), and Mikrokosmos (Nirenburg, 1998). This work exemplifies something of the same spirit expressed by Kay and Arnold et al., as it has been conspicuous in parts of the Information Extraction community (see Chapter 3): the use of very simple heuristic methods, while retaining the option to use full scale theoretical methods (in this case knowledge-based MT).4.4.3 Expected Bottlenecks
One step in the integration of MT in broader systems is to determine how different modules can be integrated using common resources and common representation formats. A number of research projects are studying how to define the format in which information can be collected from different modules in order to have the right information at the right time. This will surely imply defining standard interchange formats, underspecification as a general philosophy, and highly structured lexicons where all information (grammatical features as well as collocational and multiword unit patterns, frequency of use and contextual information, conceptual identification, multilingual equivalences, links to synonyms, hypernyms, etc) are all interrelated. The issues of large-coverage resources–collection, standardization, and coordination–are discussed in
Chapter 1.Second, the problem of semantics is perennial. Without some level of semantic representation, MT systems will never be able to achieve high quality, because they will never be able to differentiate between cases that are lexically and syntactically ambiguous. The abovementioned work on semantics in lexicons and ontologies will benefit MT (as it will other applications such as Summarization and Information Extraction).
Third, an increasingly pressing bottleneck is the fact that essentially all MT systems operate at the single-sentence level. Except for a few experimental attempts, no systems have explored translating beyond the sentence boundary, using discourse representations. Typically, their only cross-sentence record is a list of referents for pronominalization. Yet many phenomena in language span sentence boundaries:
Fortunately, recent developments in Text Linguistics, Discourse Study, and computational text planning have led to theories and techniques that are potentially of great importance for MT. Using a paragraph structure, one can represent and manipulate cross-sentence groupings of clauses and sentences. Marcu (1997) describes a method of automatically producing trees representing paragraph structure. Two studies report the effects of output quality using a very simple paragraph structure tree to treat multi-sentence quotes (Hovy and Gerber, 1997) and to break up overlong sentences (Gerber and Hovy, 1998).
Fourth, the treatment of so-called low-diffusion languages requires additional attention. Not all languages are equally well covered by MT; even some of the most populous nations in the world are not yet represented in the commercial (or even research) MT sphere: Indonesia, various languages of India, and others. The so-called major languages are reasonably well covered at present, and will certainly be well covered in the future, but users of less spoken languages need MT and other tools just as much or even more than users of English, Spanish, French and Japanese. For some languages the market is not sufficiently large, which means that users of those language will lack the tools which are otherwise available. This lack of tools will have an obvious economic effect, but also a cultural effect by excluding some languages from participating in an otherwise flourishing multilinguality.
4.5 Juxtaposition of this Area with Other Areas
It is probably safe to say that Machine Translation is a central area in the emerging world of multifunctional language processing. While not everyone will use more than one language, many people will have occasion to call on MT at least a few times in their lives. The language processing tasks most closely linked to MT include cross-language Information Retrieval (
Chapter 2), Speech Translation (Chapter 7), and multilingual Text Summarization (Chapter 3).4.6 Conclusion
The future of MT is rosy. Thanks largely to the Internet and the growth of international commerce, casual (one-off) and repeated MT is growing at a very fast pace. Correspondingly, MT products are coming to market as well. The Machine Translation Compendium (Hutchins, 1999) lists commercial products in over 30 languages (including Zulu, Ukrainian, Dutch, Swahili, and Norwegian) in 83 language pairs. Comparative studies of MT systems, including the OVUM Report (OVUM, 1995) and the ABS Study (ABS, 1999), continue to become available, although they tend to cost upward of US$1,000.
In tandem with this growth, it is imperative to ensure that research in MT begins again. At this time, neither the EU nor the North American funding agencies support coordinated, or even large separate, research projects in MT. Without research, however, the difficult problems endemic to MT will not be solved; MT companies do not have enough financial leeway or in many cases the technical expertise required to make theoretical breakthroughs. Since market forces alone cannot solve the problem, governments and funding agencies have to take an active role in the protection and reinforcement of MT.
4.7 References
ABS Study. 1999. Allied Business Intelligence, Inc. Oyster Bay, NY. See
http://www.infoshop-japan.com/study/ab3365_languagetranslation_toc.html.Arnold, D.J. et al. 1994. An Introduction to Machine Translation. Oxford: Blackwell.
Brown, P.F., J. Cocke, S. Della Pietra, V. Della Pietra, F. Jelinek, J. Lafferty, R. Mercer, P. Roossin. 1990. A Statistical Approach to Machine Translation. Computational Linguistics 16(2) (79—85).
Brown, R., and R. Frederking. 1995. Applying Statistical English Language Modeling to Symbolic Machine Translation. Proceedings of the Conference on Theoretical and Methodological Issues in MT (TMI-95), (221—239).
Carter, D., R. Becket, M. Rayner, R. Eklund, C. MacDermid, M. Wirén, S. Kirchmeier-Andersen, and C. Philp. 1997. Translation Methodology in the Spoken Language Translator: An Evaluation. Proceedings of the Spoken Language Translation Meeting, (73—81). ACL/ELSNET, Madrid.
Church, K.W. and E.H. Hovy. 1993. Good Applications for Crummy Machine Translation. Journal of Machine Translation 8 (239—258).
Dorr, B.J. 1994. Machine Translation Divergences: A Formal Description and Proposed Solution. Computational Linguistics 20(4) (597—634).
Dorr, B. 1997. Large-Scale Acquisition of LCS-Based Lexicons for Foreign Language Tutoring. Proceedings of the Fifth ACL Conference on Applied NLP (ANLP), (139—146). Washington, DC.
Frederking, R., S. Nirenburg, D. Farwell, S. Helmreich, E. Hovy, K. Knight, S. Beale, C. Domanshnev, D. Attardo, D Grannes, R. Brown. 1994. Integrating Translations from Multiple Sources within the Pangloss Mark III Machine Translation System. Proceedings of the First AMTA Conference, Columbia, MD (73—80).
Fung, P. and D. Wu. 1995. Coerced Markov Models for Cross-Lingual Lexical-Tag Relations. Proceedings of the Conference on Theoretical and Methodological Issues in MT (TMI-95), (240—255).
Gerber, L. and E.H. Hovy. 1998. Improving Translation Quality by Manipulating Sentence Length. In D. Farwell, L. Gerber, and E.H. Hovy (eds), Machine Translation and the Information Soup: Proceedings of the Third AMTA Conference, Philadelphia, PA. Heidelberg: Springer (448—460).
Hovy, E.H. and S. Nirenburg. 1992. Approximating an Interlingua in a Principled Way. Proceedings of the DARPA Speech and Natural Language Workshop. Arden House, NY.
Hovy, E.H. and L. Gerber. 1997. MT at the Paragraph Level: Improving English Synthesis in SYSTRAN. Proceedings of the Conference on Theoretical and Methodological Issues in MT (TMI-97).
Hutchins, J. 1999. Compendium of Machine Translation Software. Available from the International Association of Machine Translation (IAMT).
Johnson, R.L, M. King, and L. Des Tombe. 1985. EUROTRA: A Multi-Lingual System under Development. Computational Linguistics 11, (155—169).
Kay, M., J.M. Gawron, and P. Norvig. 1994. Verbmobil: A Translation System for Face-to-Face Dialog. CSLI Lecture Notes No. 33, Stanford University.
Kay, M. 1997. The proper place of men and machines in translation. Machine Translation 23.
Knight, K., I. Chander, M. Haines, V. Hatzivassiloglou, E.H. Hovy, M. Iida, S.K. Luk, R.A. Whitney, and K. Yamada. 1995. Filling Knowledge Gaps in a Broad-Coverage MT System. Proceedings of the 14th IJCAI Conference. Montreal, Canada.
Knight, K. and J. Graehl. 1997. Machine Transliteration. Proceedings of the 35th ACL-97 Conference. Madrid, Spain, (128—135).
Maegaard, B. and V. Hansen. 1995. PaTrans, Machine Translation of Patent Texts, From Research to Practical Application. Proceedings of the Second Language Engineering Convention, (1—8). London: Convention Digest.
Marcu, D. 1997. The Rhetorical Parsing, Summarization, and Generation of Natural Language Texts. Ph.D. dissertation, University of Toronto.
Melamed, I.D. 1998. Empirical Methods for Exploiting Parallel Texts. Ph.D. dissertation, University of Pennsylvania.
Nagao, M. 1984. A Framework of a Machine Translation between Japanese and English by Analogy principle, (173—180). In Elithorn and Banerji (eds.), Artificial and Human Intelligence, North Holland.
Niemann, H., E. Noeth, A. Kiessling, R. Kompe and A. Batliner. 1997. Prosodic Processing and its Use in Verbmobil. Proceedings of ICASSP-97, (75—78). Munich, Germany.
Nirenburg, S., J.C. Carbonell, M. Tomita, and K. Goodman. 1992. Machine Translation: A Knowledge-Based Approach. San Mateo: Morgan Kaufmann.
Nirenburg, S., 1998. Project Boas: "A Linguist in the Box" as a Multi-Purpose Language Resource. Proceedings of the First International Conference on Language Resources and Evaluation (LREC), (739—745). Granada, Spain.
OVUM 1995. Mason, J. and A. Rinsche. Translation Technology Products. OVUM Ltd., London.
Theologitis, D. 1997. Integrating Advanced Translation Technology. In the 1997 LISA Tools Workshop Guidebook, (1/1—1/35). Geneva.
Tsujii, Y. 1990. Multi-Language Translation System using Interlingua for Asian Languages. Proceedings of International Conference organized by IPSJ for its 30th Anniversary.
Vossen, P., et al. 1999. EuroWordNet. Computers and the Humanities, special issue (in press).
White, J. and T. O’Connell. 1992—94. ARPA Workshops on Machine Translation. Series of 4 workshops on comparative evaluation. PRC Inc., McLean, VA.
Whorf, B.L. 1956. Language, Thought, and Reality: Selected Writings of Benjamin Lee Whorf, J.B. Carroll (ed). Cambridge: MIT Press.
Wilks, Y. 1992. MT Contrasts between the US and Europe. In J. Carbonell et al. (eds), JTEC Panel Report commissioned by DARPA and Japanese Technology Evaluation Center, Loyola College, Baltimore, MD.
Wu, D. 1995. Grammarless Extraction of Phrasal Translation Examples from Parallel Texts. Proceedings of the Conference on Theoretical and Methodological Issues in MT (TMI-95), (354—372).
Yamron, J., J. Cant, A. Demedts, T. Dietzel, Y. Ito. 1994. The Automatic Component of the LINGSTAT Machine-Aided Translation System. In Proceedings of the ARPA Conference on Human Language Technology, Princeton, NJ (158—164).
Yarowsky, D. 1995. Three Machine Learning Algorithms for Lexical Ambiguity Resolution. Ph.D. thesis, University of Pennsylvania, Department of Computer and Information Sciences.
[This chapter is available as http://www.cs.cmu.edu/~ref/mlim/chapter5.html .]
[Please send any comments to Robert Frederking (ref+@cs.cmu.edu, Web document maintainer) or Ed Hovy or Nancy Ide.]
Chapter 5
Multilingual Speech Processing (Recognition and Synthesis)
Editor: Joseph Mariani
Contributors:
Kamran Kordi
Roni Rosenfeld
Khalid Choukri
Ron Cole
Giorgio Micca
Abstract
Speech processing involves recognition, synthesis, language identification, speaker recognition, and a host of subsidiary problems regarding variations in speaker and speaking conditions. Notwithstanding the difficulty of the problems, and the fact that speech processing spans two major areas, acoustic engineering and computational linguistics, great progress has been made in the past fifteen years, to the point that commercial speech recognizers are increasingly available in the late 1990s. Still, problems remain both at the sound level, especially dealing with noise and variation, and at the dialogue and conceptual level, where speech blends with natural language analysis and generation.
5.1 Definition of Area
Speech processing comprises several areas, primarily speech recognition and speech synthesis, but also speaker recognition, language recognition, speech understanding and vocal dialog, speech coding, enhancement, and transmission. A panorama of techniques and methods may be found in Cole et al. (1998) or Juang et al. (1998).
Speech recognition is the conversion of acoustic information into linguistic information that may result in a written transcription, or that has to be understood. Speech synthesis is the conversion of linguistic information for human auditory consumption. The starting point may be a text or a concept that has to be expressed.
5.2 The Past: Where We Come From
5.2.1 Major Problems in Speech Processing
Many of the problems that have been addressed in the history of speech processing concern variability:
Noise and channel distortions are difficult to handle, especially when there is no a priori knowledge of the noise or of the distortion. These phenomena directly affect the acoustics of the signal, but may also indirectly modify the voice at the source. This is known as the Lombard effect, where noise modifies the utterance of the words (as people tend to speak louder), but may also be reflected in voice changes due to the psychological awareness of speaking to a machine.
The fact that, contrary to written texts, speech is continuous and has no silence to separate words, adds extra difficulty. But continuous speech is also difficult to handle because linguistic phenomena of various kinds may occur at the junctions between words, or within words which are often used, and which are usually short and therefore much affected by coarticulation.
5.2.2 History of Major Methods, Techniques, and Approaches
Regarding speech synthesis, the origins may be placed very early in time. The first result in that field may be placed in 1791, when W. von Kempelen demonstrated his speaking machine, which was built with a mechanical apparatus mimicking the human vocal apparatus. The next major successful attempt may be placed at the New York World Fair in 1939, when H. Dudley presented the Voder, based on electrical devices. In this case, the approach was rather based on an analysis-synthesis approach. The sounds where first analyzed and then replayed. In both cases, it was necessary to learn how to play those very special musical instruments (one week in the case of the Voder), and the human demonstrating the systems probably used the now well-known trick of announcing to the audience what they would hear, and thus inducing the understanding of the corresponding sentence. Since then, major progress may be reported in that field, with basically two approaches still reflecting the Von Kempelen/Dudley dichotomy on "Knowledge-Based" vs "Template-Based" approaches. The first approach is based on the functioning of the vocal tract, which often goes together with formant synthesis (the formants are the resonances of the vocal tract). The second is based on the synthesis of pre-analyzed signals, which leads to diphone synthesizers, and more generally to signal segment concatenation. A speech synthesizer for American English was designed based on the first approach at MIT (Klatt, 1980), and resulted in the best synthesizer available at that time. Several works may also be reported in the field of articulatory synthesis, which aims at mimicking more closely the functioning of the vocal apparatus. However, the best quality is presently obtained by diphone based approaches or the like, using simply PCM encoded signals, especially illustrated by the Psola system designed at CNET (Moulines and Charpentier, 1990).
In addition to the phoneme-to-sound levels, Text-to-Speech synthesis systems also contain a Grapheme-to-Phoneme conversion level. This operation initially used a large set of rules, including morpho-syntactic tagging and even syntactic parsing to solve some difficult cases. Several attempts to perform this operation by automatic training on large amounts of texts or directly on the lexicon, using stochastic approaches or even Neural Nets, resulted in encouraging results, and even claims that machine "able to learn reading" have been invented. However, rule-based approaches still produce the best results. Specific attention has recently been devoted to the grapheme-to-phoneme conversion of proper names, including acronyms. Prosodic markers are generated from the texts using rules and partial parsing.
Regarding speech recognition, various techniques were used in the 60s and 70s. Researchers here also found their way between knowledge based approaches for "analytic recognition" and template matching approaches for "global recognition". In the first case, the phonemes were first recognized and then linguistic knowledge and AI techniques helped reconstruct the utterance and understand the sentence, despite the phoneme recognition errors. An expert systems methodology was specifically used for phoneme decoding in that approach. In the second approach, the units to be recognized were the words. Template matching systems include a training phase, in which each word of the vocabulary is pronounced by the user and the corresponding acoustic signal is stored in memory. During the recognition phase, the same speaker pronounces a word of the vocabulary and the corresponding signal is compared with all the signals that are stored in memory. This comparison employs a pattern matching technique called Dynamic Time Warping (DTW), which accommodates differences between the signals for two pronunciations of the same word (since even the same speaker never pronounces words exactly the same way, with differences in the duration of the pronunciation of the phonemes, the energy, and the timber). This approach was first successfully used for speaker-dependent isolated word recognition for small vocabularies (up to 100 words). It was then extended to connected speech, to speaker independent isolated words, or to larger vocabularies, but independently on each of those 3 dimensions, by improving the basic technique.
The next major progress was made on the introduction of a statistical approach called Hidden Markov Models (HMMs) by researchers at IBM (Baker, 1975, Jelinek, 1976). In this case, instead of storing in the memory the signal corresponding to a word, the system stores an abstract model of the units to be recognized, which are represented as finite state automata, made up of states and links between states. The parameters of the model are the probability to traverse a link between two states, and the probability of observing a speech spectrum (acoustic vector) while traversing that link. Algorithms were proposed in the late 60s that find those parameters (that is, train the model) (Baum, 1972), and match in an optimal way a model with a signal (Viterbi, 1967), similarly to DTW. The interesting features of this approach is that it is possible to include in a given model parameters which represent different ways of pronouncing a word for different speaking styles of the same speaker, or for different speakers, and different pronunciations of the words, with different probabilities, or, even more interestingly, that it is possible to train phoneme models instead of word models. The recognition process may then be expressed as finding the word sequence which maximizes the probability that the word sequence produced the signal. This can be simply rewritten as the product of the probability that the signal was produced by the word sequence (Acoustic Model) and the probability of the word sequence (Language Model). This latter probability can be obtained by computing the frequency of the succession of two (bigrams) or three (trigrams) words in texts or speech transcriptions corresponding to the kind of utterances which will be considered in the application. It is also possible to consider the probabilities of grammatical category sequences (biclass and triclass models).
The HMM approach requires very large amounts of data for training, both in terms of signal and in terms of textual data, and the availability of such data is crucial for developing technologies and applications, and evaluating systems.
Various techniques have been proposed for the decoding process (depth-first, breadth-first, beam search, A* algorithm, stack algorithm, Tree Trellis, etc.). This process is very time consuming, and one research goal is to accelerate the process without losing quality.
This statistical approach was proposed in the early 70s. It was developed throughout the early 80s in parallel with other approaches, as there was no quantitative way of comparing approaches on a given task. The US Department of Defense DARPA Human Language Technology program, which started in 1984, fostered an evaluation-driven comparative research paradigm, which clearly demonstrated the advantages of the statistical approach (DARPA, 1989—98). Gradually, the HMM approach became more popular, both in the US and abroad.
In parallel, the connectionist, or neural network (NN), approach was experimented in various fields, including speech processing. This approach is also based on training, but is considered to be more discriminative than the HMM one. However, it is less adequate than HMM to model the time information. Hybrid systems that combine HMMs and NNs have therefore been proposed. Though they provide interesting results, and, in some limited cases, even surpass the pure HMM approach, they have not proven their superiority.
This history illustrates how problems were attacked and in some cases partly solved by different techniques: acoustic variability through the use of Template-Matching using DTW in the 70s, followed by stochastic modeling in the 80s, speaker and speaking variability through clustering techniques followed by stochastic modeling, differential features and more data in the 80s, linguistic variability through N-grams and more data, in the 70s and 80s. It is an example of the ‘classic’ paradigm development and hybridization for Language Processing, as discussed in
Chapter 6. Currently, the largest efforts are presently devoted to address improved language modeling, phonetic pronunciation variability, noise and channel distortion through signal processing techniques and more data, up to multilinguality, through more data and better standards, and to multimodality, through multimodal data, integration and better standards and platforms (see also Chapter 9).5.3 The Present: Major Bottlenecks and Problems
In speech recognition, basic research is still needed in the statistical modeling approach. Some basic statements are still very crude, such as considering the speech signal to be stationary, or the acoustic vectors to be uncorrelated. How can HMM capabilities be pushed? Progress continues, using HMMs with more training data, or considering different aspects of the data for different uses: understanding or dialog handling, through the use of corpus containing semantically labeled words or phrases. At the same time, the availability of large quantities of data for a given application is not always possible, and the adaptation of a system to a new application is often very costly. Techniques have been proposed, such as tied mixtures for building acoustic models or backing off techniques for building language models, but progress is still required. It is therefore important to develop methods that enable easy application adaptation, even if little or no data is available beforehand.
Using prosody in recognition is still an open issue. Still today, very few operational systems consider prosodic information, as there is no clear evidence that taking into account prosody results in better performances, given the nature of the applications being addressed at present. It seems likely however that some positive results have been obtained on the German language within the Verbmobil program (Niemann et al., 1997).
Addressing spontaneous speech is still an open problem, and difficult tasks such as DARPA’s SwithBoard and CallHome projects still achieve poor results, despite the efforts devoted to the development of systems in this area.
Recognizing voice in noisy conditions is also important. Two approaches are conducted in parallel, either using noise robust front-ends or using a model based approach. The second will probably provide the best results in the long run.
Systems are now getting more speaker-independent, but commercial systems are still "speaker adaptive": they may recognize a new user with low performance, and improve during additional spoken interaction with the user. Speaker adaptation will stay as a research topic for the future, with the goal to make it more natural and invisible. The systems will thus become more speaker-independent, but will still have a speaker adaptation component. This adaptation can also be necessary for the same speaker, if his or her voice changes due to illness conditions for example
In speech synthesis, the quality of text-to-speech synthesis is better, but still not good enough for replacing "canned speech" (constructed by concatenating phrases and words). The generalization of the use of Text-to-Speech synthesis for applications such as reading aloud email messages will however probably help making this imperfect voice familiar and acceptable. Further improvement should therefore be obtained on phoneme synthesis itself, but attention should be placed on improving the naturalness of the voice. This involves prosody, as it is very difficult to generate a natural and acceptable prosody from the text, and it may be somehow easier to do it in the speech generation module of an oral dialogue system. This also involves voice quality, allowing the TTS synthesis system to change its voice to interpret the right meaning of a sentence. Voice conversion (allowing a TTS synthesis system to speak with the voice of the user, after analysis of this voice) is another area of R&D interest (Abe et al., 1990).
Generally speaking, the research program for the next years should be "to put back Language into Language Modeling", as proposed by F. Jelinek during the MLIM workshop. It requires taking into account that the data which has to be modeled is language, not just sounds, and that it therefore has some specifics, including an internal structure which involves more than a window of two or three words. This would suggest going beyond Bigrams and Trigrams, to consider parsing complete sentences.
In the same way, as suggested by R. Rosenfeld during the MLIM workshop, it may be proposed "to put Speech back in Speech Recognition", since the data to be modeled is speech, with its own specifics, such as having been produced by a human brain through the vocal apparatus. In that direction, it may be mentioned that the signal processing techniques for signal acquisition were mostly based on MFCC (Mel Frequency Cepstral Coefficients) in the 80s (Davis and Merlmelstein, 1980), and are getting closer to perceptual findings with PLP (Perceptually weighted Linear Prediction) in the 90s (Hermansky, 1990).
Several application areas are now developing, including consumer electronics (mobile phones, hand-held organizers), desktop applications (Dictation, OS navigation, computer games, language learning), telecommunications (auto-attendant, home banking, call-centers). These applications require several technological advances, including consistent accuracy, speaker-independence and quick adaptation, consistent handling of Out-Of-Vocabulary words, easy addition of new words and names, automatic updating of vocabularies, robustness to noise and channel, barge-in (allowing a human to speak over the system’s voice and interrupt it), and also standard software and hardware compatibility and low cost.
5.4 The Future: Major Breakthroughs Expected
Breakthroughs will probably continue to be obtained through sustained incremental improvements based on the use of statistical techniques on ever larger amounts of data and differently annotated data. Every year from the mid-80s we can identify progress and better performances on more difficult tasks. Significantly, results obtain within DARPA’s ATIS task (Dahl et al., 1994) showed that the performance on understanding obtained on written data transcribed from speech was achieved on actual speech data only one year later.
Better pronunciation modeling will probably enlarge the population that can get acceptable results on a recognition system, and therefore strengthen the acceptability of the system.
Better language models are presently a major issue, and could be obtained by looking beyond N-Grams. This could be achieved by identifying useful linguistic information, and incorporating more Information Theory in Spoken Language Processing systems.
In five years, we will probably have considerably more robust speech recognition for well defined applications, more memory-efficient and faster recognizers to support integration with multi-media applications, speech I/O embedded in client server architecture, distributed recognition to allow mass telephony applications, efficient and stable multilingual applications, better integration of NLP in well-defined areas, and much more extensible modular toolkits to reduce the lifecycle of application development. While speech is considered nowadays as a communication means, it will be considered, with the research progress, as a material comparable to text, that you can easily index, access randomly, sort, summarize, translate, and retrieve. This view will drastically change our relationship with the vocal media.
Multimodality is an important area for the future, as discussed in
Chapter 9. It can intervene for the processing of a single media, such as speech recognition using both the audio signal and the visual signal of the lips, which results in improved accuracy, especially in noisy conditions. But it can also address different media, such as integrating speech, vision and gesture in multimodal multimedia communication, which includes the open issue of sharing a common reference for the human and the machine. Multimodal training is another dimension, based on the assumption that humans learn to use one modality by getting simultaneous stimuli coming from different modalities. In the long run, modeling speech will have to be considered in tandem with other modalities.Transmodality is another area of interest. It addresses the problem of providing an information through different media, depending on which media is more appropriate to the context in which the user stands when requesting the information (sitting in front of his computer, in which case a text + graphics output may be appropriate, or driving his car, in which case, a speech output of a summarized version of the textual information may be more appropriate, for example).
5.5 Juxtaposition of this Area with Other Areas
Over the years, speech processing is getting closer to natural language processing, as speech recognition is shifting to speech understanding and dialogue, and as speech synthesis becomes increasingly natural and approaches language generation from concepts in dialogue systems. Speech recognition would benefit from better language parsing, and speech synthesis would benefit from better morpho-syntactic tagging and language parsing.
Speech recognition and speech synthesis are used in Machine Translation (
Chapter 4) for spoken language translation (Chapter 7).Speech processing meets Natural Language Processing, but also computer vision, computer graphics, gestural communication in multimodal communication systems, with open research issues on the relationship between image, language and gesture for example (see
Chapter 9).Even imperfect speech recognition meets Information Retrieval (
Chapter 2) in order to allow for multimedia document indexing through speech, and retrieval of multimedia documents (such as in the US Informedia (Wactlar et al., 1999) and the EU Thistle or Olive projects). This information retrieval may even be multilingual, extending the capability of the system to index and retrieve the requested information, whatever the language spoken by the user, or present in the data. Information Extraction (Chapter 3) from spoken material is a similar area of interest, and work has already been initiated in that domain within DARPA’s Topic Detection and Tracking program. Here also, it will benefit from cooperation between speech and NL specialists and from a multilingual approach, as data is available on multiple sources in multiple languages worldwide.Speech recognition, speech synthesis, speech understanding and speech generation meet in order to allow for oral dialogue. Vocal dialogue will get closer to research in the area of dialogue modeling (indirect speech acts, beliefs, planning, user models, etc.). Adding a multilingual dimension empowers individuals and gives them a universal access to the information world.
5.6 The Treatment of Multiple Languages in Speech Processing
Addressing multilinguality is important in speech processing. A system that handles several languages is much easier to put on the market than a system that can only address one language. In terms of research, the structural differences across languages are interesting for studying any one of them. Rapid deployment of a system to a large market, which necessitates the handling of several languages, is challenging, and several companies offer speech recognition or speech synthesis systems that handle different languages in their different versions, less frequently different languages within a single version. Addressing multilinguality not only includes getting knowledge on the structures and elements of a different language, but also requires accommodating speakers who speak that language with accents that may differ and who use words and sentence structures that may be far away from the canonical rules of the language.
As discussed in
Chapter 7, language identification is part of multilingual speech processing. Detecting the language spoken enables selecting the right Acoustic and Language Models. An alternative could be to use language-independent Acoustic Models (and less probably even language-independent Language Models). However, present systems will get into trouble if someone shifts from one language to another within one sentence, or one discourse, as humans sometimes do.Similarly, a speech synthesis system will have to be able to identify the language spoken in order to pronounce it correctly, and systems aiming at the pronunciation of email will have to shift most often between the user’s language and English, which is used for many international exchanges. Here also, some sentences may contain foreign words or phrases that must be pronounced correctly. Large efforts may be required to gather enough expertise and knowledge on the pronunciation of proper names in various countries speaking different languages, as in the European project Onomastica (Schmidt et al., 1993). Also, successful attempts to quickly train a speech synthesis system by using a large enough speech corpus in that language have been reported (Black and Campbell, 1995). In this framework, the synthesis is achieved by finding in the speech corpus the longest speech units corresponding to parts of the input sentence. This approach requires no extended understanding of the language to be synthesized. Another aspect of multilingual speech synthesis is the possibility of using voice conversion in spoken language translation. In this case, the goal is to translate the speech uttered by the speaker in the target language and to synthesize the corresponding sentence to the listener, using the voice that the speaker would have if he would be speaking that language. Such attempts were conducted in the Interpreting Telephony project at ATR (Abe et al., 1990).
Complete multilingual systems therefore require language identification, multilingual speech recognition and speech synthesis, and machine translation for written and spoken language. Some spoken translation systems already exist and work in laboratory conditions for well-defined tasks, including conference registration (Morimoto et al., 1993) and meeting appointment scheduling (Wahlster , 1993).
With respect to multilinguality, there are two important questions. First, can data be shared across languages (if a system is able to recognize one language, will it be necessary to conduct the same effort to address another one? Or is it possible to reuse for example the acoustic models of the phonemes that are similar in two different languages)? Second, can knowledge be shared across language? (Could the scientific results obtained in studying one language be used for studying another language? As the semantic meaning of a sentence remains the same, when it is pronounced in two different languages, it should be possible to model language-independent knowledge independently of the languages used)?
5.7 Conclusion
Notwithstanding the difficulty of the problems facing speech processing, and despite the fact that speech processing spans two major areas, acoustic engineering and computational linguistics, great progress has been made in the past fifteen years. Commercial speech recognizers are increasingly available today, complementing machine translation and information retrieval systems in a trio of Language Processing applications. Still, problems remain both at the sound level, especially dealing with noise and variations in speaker and speaking condition, and at the dialogue and conceptual level, where speech blends with natural language analysis and generation.
5.8 References
Abe, M., S. Nakamura, K. Shikano, and H. Kuwabara. 1990. Voice conversion through vector quantization. Journal of the Acoustical Society of Japan, E-11 (71—76).
Baker, J.K. 1975. Stochastic Modeling for Automatic Speech Understanding. In R. Reddy (ed), Speech Recognition (521—542). Academic Press.
Baum, L.E. 1972. An Inequality and Associated Maximization Technique in Statistical Estimation of Probabilistic Functions of Markov Processes. Inequalities 3 (1—8).
Black, A. W. and N. Campbell. 1995. Optimising selection of units from speech databases for concatenative synthesis. Proceedings of the fourth European Conference on Speech Communication and Technology (581—584). Madrid, Spain.
Cole, R., J. Mariani, H. Uszkoreit, N. Varile, A. Zaenen, A. Zampolli, V. Zue. 1998. Survey of the State of the Art in Human Language Technology. Cambridge: Cambridge University Press (or see
http://www.cse.ogi.edu/CSLU/HLTsurvey/HLTsurvey.html.)Dahl, D.A., M. Bates, M. Brown, W. Fisher, K. Hunicke-Smith, D. Pallett, C. Pao, A. Rudnicky, and E. Shriberg.. 1994. Expanding the Scope of the ATIS Task: the ATIS-3 Corpus. Proceedings of the DARPA Conference on Human Language Technology (43—49). San Francisco: Morgan Kaufmann.
DARPA. 1989—1998. Proceedings of conference series initially called Workshops on Speech and Natural Language and later Conferences on Human Language Technology. San Francisco: Morgan Kaufmann.
Davis, S. B. and P. Mermelstein. 1980. Comparison of parametric representations for monosyllabic word recognition in continuously spoken sentences. IEEE Transactions on Acoustics, Speech and Signal Processing, ASSP-28 (357—366).
Hermansky, H. 1990. Perceptual linear predictive (PLP) analysis for speech. Journal of the Acoustical Society of America, 87(4) (1738—1752).
Jelinek, F. 1976. Continuous speech recognition by statistical methods. Proceedings of the IEEE, 64 (532—556).
Juang, B.H., D. Childers, R.V. Cox, R. De Mori, S. Furui, J. Mariani, P. Price, S. Sagayama, M.M. Sondhi, R. Weishedel. 1998. Speech Processing: Past, Present and Outlook. IEEE Signal Processing Magazine, May 1998.
Klatt, D.H. 1980. Software for a cascade/parallel formant synthesizer. Journal of the Acoustical Society of America 67 (971—995).
Morimoto, T., T. Takezawa, F. Yato, S. Sagayama, T. Tashiro, M. Nagata, and A. Kurematsu,. 1993. ATR’s speech translation system: ASURA. In Proceedings of the third European Conference on Speech Communication and Technology (1295—1298). Berlin, Germany.
Moulines, E. and F. Charpentier. 1990. Pitch-synchronous waveform processing techniques for text-to-speech synthesis using diphones. Speech Communication. 9 (453—467).
Niemann, H., E. Noeth, A. Kiessling, R. Kompe and A. Batliner. 1997. Prosodic Processing and its Use in Verbmobil. Proceedings of ICASSP-97 (75—78). Munich, Germany.
Schmidt, M.S., S. Fitt, C. Scott, and M.A. Jack. 1993. Phonetic transcription standards for European names (ONOMASTICA). Proceedings of the third European Conference on Speech Communication and Technology (279—282). Berlin, Germany.
Viterbi, A.J. 1967. Error Bounds for Convolutional Codes and an Asympotically Optimum Decoding Algorithm. IEEE Transactions on Information Theory IT-13(2), (260—269).
Wactlar, H.D., M.G. Christel, Y. Gong, A.G. Hauptmann. 1999. Lessons learned from building a Terabyte Digital Video Library. IEEE Computer-32(2), (66—73).
Wahlster, W. 1993. Verbmobil, translation of face-to-face dialogs. Proceedings of the Fourth Machine Translation Summit (127—135). Kobe, Japan.
[This chapter is available as http://www.cs.cmu.edu/~ref/mlim/chapter6.html .]
[Please send any comments to Robert Frederking (
ref+@cs.cmu.edu, Web document maintainer) or Ed Hovy or Nancy Ide.]
Chapter 6
Methods and Techniques of Processing
Editor: Nancy Ide
Contributors:
Jean-Pierre Chanod
Jerry Hobbs
Eduard Hovy
Frederick Jelinek
Martin Rajman
Abstract
Language Processing in almost all its subareas has experienced research in two major paradigms. The symbolic and statistical approaches to language processing are often regarded as (at best) complementary and (at worst) at odds with one another, although the line between them can be blurry. This chapter outlines the nature and history of the two methodologies, and shows why and how they necessarily complement one another.
5.1 Statistical vs. Symbolic: Complementary or at War?
In the history of Language Processing, two principal paradigms came into conflict during some period in almost every major branch–Information Retrieval (see
Chapter 2) in the 1960s, Automated Speech Recognition (Chapter 5) in the 1970s, Machine Translation (Chapter 4) in the 1990s. In all cases, this time was rather traumatic, sometimes leading to completely separate professional organizations, journals, and conference series. The two paradigms can be called the "symbolic" and the "statistical" approaches to automatic language processing (see, for example, Klavans and Resnik, 1997). This distinction is made roughly on the following basis:One can view Language Processing as a process of transformation between input (the language sample, in speech or text) and output (the desired result–translation, summary, query result, etc., depending on the application). In this view, the symbolic approach is primarily concerned with how to decompose the transformation process into stages: which stages are to be created, and what notations are to be invented for them? Traditional answers to these questions include morphology, syntactic analysis (parsing), semantic analysis, discourse analysis, text planning, and so on. In contrast, the statistical approach is primarily concerned with how automatically to construct systems (or rules for systems) that effect the necessary transformations among stages. Traditional techniques include vector spaces, collecting alternatives and then ranking them using various metrics, counting frequencies, and measuring information content in various ways.
The common wisdom is that the symbolic approach, based upon deep analysis of the phenomena in question, is superior for its high quality, over the statistical approach, which considers only somewhat superficial phenomena. Furthermore, symbolic methods do not require massive amounts of data and the often intensive human effort required to create appropriately annotated data. On the other hand, statistics-based methods are generally considered superior because they tend to be more robust in the face of unexpected types of input, where rule-based systems simply break down. Furthermore, since statistics-based systems use automated methods to identify common patterns and create transformations or rules for them, they are well suited to phenomena that do not exhibit fairly simple and clear regularity, and can produce many rules rapidly. In contrast, symbolic approaches are limited by slow manual analysis and rule-building, which is generally costly, difficult, and often incomplete.
A good example is provided by grammars of languages, one of the most obvious candidates for human analysis and rule construction, and a favorite subject of syntacticians for four decades. But even for grammars, the tendency of natural language toward exceptions and complexity bedevils the symbolic rule-building approach–no complete or even fully adequate grammar of any human language has yet been built, despite decades (or even centuries) of effort! Typically, for example, it requires about 2 person-years to build an adequate grammar for a commercial-quality machine translation system, and eventually involves approximately 500—800 grammar rules, giving roughly 80% coverage of arbitrary input sentences. In contrast, recent automated grammar learning systems produce on the order of 2000—25000 grammar rules after a few months of human-guided training, and produce results with over 90% coverage (Collins, 1996, 1997; Hermjakob and Mooney, 1997; Hermjakob, 1999). While the latter set of rules is rarely as elegant as the humans’ rules, one cannot argue with the results.
One cannot conclude that statistics wins, however. Rather, this example uncovers a more subtle relationship between the two approaches, one that illustrates their necessary complementarity. Without some knowledge of syntactic categories and phenomena, no automated rule-learning system would be able to learn any grammar at all. The learning systems have to be told what it is that they must learn: their training corpora have to be annotated according to some theory. The better the theory, the more powerful the eventual result, and the more elegant and parsimonious, generally speaking, the learned rules. This example highlights a harmonious and productive balance between human analyst and learning system: it is the human’s job (possibly aided by automated tools that discover patterns) to decide on the appropriate level(s) of representation and the appropriate representational notations and terms; it is the learning system’s job to learn the rules that transform the input into the desired notation as accurately as possible.
This view leads to the fundamental questions surrounding the supposed dichotomy between the two approaches: Can statistics tell us anything about language? Can it contribute to the development of linguistic models and theories? On the other hand, do we need linguistic theory to do language processing, or, like Orville and Wilbur Wright, can we build an airplane that flies with little or no understanding of aerodynamics?
5.2 Where We Are Coming From
The history of natural language processing research dates back most conveniently to efforts in the early 1950s to achieve automatic translation. Although quantitative/statistical methods were embraced in the early machine translation work, interest in statistical treatment of language waned among linguists in the mid-60s, due to the trend toward generative linguistics sparked by the theories of Zellig Harris (1951) and bolstered most notably by the transformational theories of Noam Chomsky (1957). In Language Processing, attention then turned toward deeper linguistic analysis and hence toward sentences rather than whole texts, and toward contrived examples and artificially limited domains instead of general language.
As described in more detail in
Chapter 5, the history of Automated Speech Recognition was a typical example. After a considerable amount of research based on phonemes, word models, and the human articulatory channel, a new paradigm involving Hidden Markov Models (HMMs) was introduced by F. Jelinek and others in the 1970s (Baker, 1975). This paradigm required data to statistically train an Acoustic Model to capture typical sound sequences and a Language Model to capture typical word sequences, and produced results that were far more accurate and robust than the traditional methods. This work was heavily influenced by the information theoretic tradition of Shannon and Weaver (1949). The US Department of Defense DARPA Human Language Technology program, which started in 1984, fostered an evaluation-driven comparative research program that clearly demonstrated the advantages of the statistical approach (DARPA, 1989—94). Gradually, the HMM statistical approach became more popular, both in the US and abroad. The problem was seen as simply mapping from sound sequences to word sequences.During this time, the speech community worked almost entirely independently of the other Language Processing communities (machine translation, information retrieval, computational linguistics). The two communities’ respective approaches to language analysis were generally regarded as incompatible: the speech community relied on training data to induce statistical models, independent of theoretical considerations, while computational linguists relied on rules derived from linguistic theory.
In the machine translation community, the so-called Statistics Wars occurred during the period 1990—1994. Before this time, machine translation systems were exclusively based on symbolic principles (
Chapter 4), including large research efforts such as Eurotra (Johnson et al., 1985). In the late 1980s, again under the influence of F. Jelinek, the CANDIDE research project at IBM took a strictly non-linguistic, purely statistical approach to MT (Brown et al., 1990). Following the same approach as the speech recognition systems, they automatically trained a French-English correspondence model (the Translation Model) on 3 million sentences of parallel French and English from the Canadian Parliamentary records, and also trained a Language Model for English production from Wall Street Journal data. To translate, CANDIDE used the former model to replace French words or phrases by the most likely English equivalents, and then used the latter model to order the English words and phrases into the most likely sequences to form output sentences. DARPA sponsored a four-year competitive research and evaluation program (see Chapter 8 for details on MTEval (White and O’Connell, 1992—94)), pitting CANDIDE against a traditional symbolic MT system (Frederking et al., 1994) and a hybrid system (Yamron et al., 1994). The latter system was built by a team led by the same J. Baker who performed the 1975 speech recognition work.Unlike the case with speech recognition, the evaluation results were not as clear-cut. Certainly, CANDIDE’s ability to produce translations at the same level as SYSTRAN’s (one of the oldest and best commercial systems for French to English) was astounding. Yet CANDIDE was not able to outperform SYSTRAN or other established MT systems; its main contribution was recognized to be a method for rapidly creating a new MT system up to competitive performance levels. The reasons for this performance ceiling are not clear, but a certain amount of consensus has emerged. As discussed in the next section, it has to do with the fact that, unlike speech recognition, translation cannot operate adequately at the word level, but must involve more abstract constructs such as syntax.
The introduction of statistical processing into machine translation was paralleled by its introduction into the Computational Linguistics community. In the late 1980s, the situation changed quite rapidly, due largely to the increased availability of large amounts of electronic text. This development enabled, for the first time, the full-scale use of data-driven methods to attach generic problems in computational linguistics, such as part-of-speech identification, prepositional phrase attachment, parallel text alignment, word sense disambiguation, etc. The success in treating at least some of these problems with statistical methods led to their application to others, and by the mid-1990s, statistical methods had become a staple of computational linguistics work.
The timing of this development was fortuitous. The explosion in the 1990s of the Internet created opportunities and needs for computational searching, filtering, summarization, and translation of real-world quantities of online text in a variety of domains. It was clear that the purely symbolic approach of the previous 30 years had not produced applications that were robust enough to handle the new environments. As a result, computational linguists began mining large corpora for information about language in actual use, in order to objectively evaluate linguistic theory and provide the basis for the development of new models. Instead of applications that worked very well on domain specific or "toy" data, computational linguists began working on applications that worked only reasonably well on general text, using models that incorporated notions of variability and ambiguity.
While symbolic methods continue to hold their own, in some areas the balance has clearly shifted to statistical methods. For example, as described in
Chapter 3, the information extraction community largely abandoned full-sentence parsing in the early 1990s in favor of "light parsing", generally using a cascade of finite-state transducers. This was a result of an inability to resolve syntactic ambiguities using previously available methods with any reliability. In the last few years, apparently significant advances have been made in statistical parsing, particularly in the work of Magerman (1995), Collins (1996, 1997), Hermjakob (1997, 1999), and Charniak (1997). Charniak reports a labeled bracketing recall scores of 87% on sentences shorter than 40 words. By contrast, in the Parseval evaluation of September 1992, the second and last evaluation for hand-crafted grammars, the best system’s labeled bracketing recall rate was 65% on sentences that were all shorter than 30 words. These results led to a general impression that statistical parsing is the clearly superior approach. As a result, research on handcrafted grammars in computational linguistics has virtually ceased in the US.6.3 Where We Are Now
6.3.1 Current Status for Parsing
Despite the recent success of statistical methods in areas such as parsing, doubts remain about their superiority. One of the major objections arises from the lack of means to compare results directly between symbolic and statistical methods. For example, in the case of parsing, it has been noted that correctly labeled and bracketed syntax trees are not in and of themselves a useful product, and that full-sentence parsing becomes feasible only when a large percentage of complete sentences receive a correct or nearly correct parse. If, for example, incorrect labeled brackets are uniformly distributed over sentences, then the percentage of complete sentences parsed entirely correctly is very low indeed. Thus systems that tend to produce fully correct parses some o f the time, and fail completely when they don’t, may outperform systems that succeed partway on all sentences. Unfortunately, papers on statistical parsing generally do not report the percentage of sentences parsed entirely correctly; in particular, they typically do not report the number of sentences parsed without any crossings. A crossing occurs when the TreeBank correct key and the parser’s output bracket strings of words differently, so that they overlap but neither is fully subsumed by the other, as in
Correct key: [She [gave [her] [dog biscuits]]]
Parser output: [She [gave [her dog] biscuits]]].
Charniak reports a zero-crossing score of 62%, again on sentences of 40 words or fewer. No precisely comparable measure is available for a hand-crafted grammar, but Hobbs et al. (1992) determined in one evaluation using a hand-crafted grammar that 75% of all sentences under 30 morphemes parsed with three or fewer attachment mistakes, a measure that is at least related to the zero crossings measure. In that same analysis, Hobbs et al. found that 58% of all sentences under 30 morphemes parsed entirely correctly. To compare that with Charniak’s results, Hobbs obtained a printout of the labeled bracketings his system produced and inspected 50 sentences by hand. The sentences ranged in length between 6 and 38 words with most between 15 and 30. Of these 50 sentences, the TreeBank key was correct on 46. Irrespective of the key, Charniak’s parser was substantially correct on 23 sentences, or 46%. If these results were to stand up under a more direct comparison, it would cast serious doubt on the presumed superiority of statistical methods.
An analysis of the errors made by Charniak’s parser shows that about one third of the errors are attachment and part-of-speech mistakes of the sort that any hand-crafted parser would make; these ironically are just the ones we would expect statistical parsing to eliminate. About a third involve a failure to recognize parallelisms, and consequently conjoined phrases are bracketed incorrectly; a richer treatment of parallelism would help statistical and handcrafted grammars equally. The remaining third are simply bizarre bracketings that would be filtered out by any reasonable handcrafted grammar. This suggests that a hybrid of statistical and rule-based parsing, augmented by a lexically-based treatment of parallelism, could greatly improve on parsers using only one of the two approaches, and thereby bring performance into a range that would make robust full-sentence parsing feasible.
6.3.2 Current Status for Wordsense Disambiguation
Statistical methods now dominate other areas as well, such as word sense disambiguation. In the 1970s and 1980s, several researchers attempted to handcraft disambiguation rules tailored to individual lexical items (e.g., Small and Rieger, 1982). Although their results for individual words were impressive, the sheer amount of effort involved in creating the so-called "word experts" prevented large-scale application to free text. Since the late 1980s, statistical approaches to word sense disambiguation, typically relying on information drawn from large corpora and other sources such as dictionaries, thesauri, etc. (see, for example, Wilks et al., 1990; Ide and Véronis, 1990) have dominated the field. The recent Senseval evaluation for sense disambiguation (Kilgarriff and Palmer, forthcoming) demonstrated that statistics-based systems, with or without the use of external knowledge sources, top out at about 80% accuracy. Although most systems in the competition were strictly statistics-based, the "winner" used a hybrid system including both statistics and rules handcrafted for individual words in the evaluation exercise. This suggests that statistical methods alone cannot accomplish word sense disambiguation with complete accuracy. Some hybrid of methods, taking into account the long history of work on lexical semantic theory, is undoubtedly necessary to achieve highly reliable results.
6.3.3 Current Status for Machine Translation
Except for the speech translation system Verbmobil (Niemann et al., 1997), no large-scale research project in machine translation is currently being funded anywhere in the EU or the US. Smaller projects within the EU are devoted to constructing the support environment for machine translation, such as lexicons, web access, etc.; these include the projects Otello, LinguaNet, Aventinus, Transrouter, and others. Within the US, small research projects are divided between the purely symbolic approach, such as UNITRAN (Dorr et al., 1994), the symbolic tools-building work at NMSU, and Jelinek’s purely statistical approach at the Johns Hopkins University Summer School.
It is, however, instructive to consider what transpired during the years 1990—94 in the competitive DARPA MT program. The program’s two flagship systems started out diametrically opposed, with CANDIDE (Brown et al., 1990) using purely statistical training and Pangloss (Frederking et al., 1994) following the traditional symbolic rule Interlingua approach. Three years and four evaluations later, the picture had changed completely. Both systems displayed characteristics of both statistics and linguistics, and did so in both the overall design philosophy and in the approach taken when constructing individual modules.
For CANDIDE, the impetus always was the drive towards quality–coverage and robustness the system had from the outset. But increasing quality can be gained only by using increasingly specific rules, and (short of creating a truly massive table of rules that operates solely over lexemes, and eventually has to contain all possible sentences in the language) the rules have to operate on abstractions, which are represented by symbols. The questions facing CANDIDE’s builders were: which phenomena to abstract over, and what kinds of symbol systems to create for them? Every time a new phenomenon was identified as a bottleneck or as problematic, the very acts of describing the phenomenon, defining it, and creating a set of symbols to represent its abstractions, were symbolic (in both senses of the word!). The builders thus were forced to partition the whole problem of MT into a set of relatively isolated smaller problems or modules, each one circumscribed in a somewhat traditional/symbolic way, and then to address each module individually. By December 1994, CANDIDE was a rather typical transfer system in structure, whose transfer rules require some initial symbolic/linguistic analysis of source and target languages, followed by a period of statistical training to acquire the rules.
For Pangloss, the development path was no less easy. Pangloss was moved by the drive toward coverage and robustness. Although the Pangloss builders could always theorize representations for arbitrary new inputs and phenomena, Pangloss itself could not. It always needed more rules, representations, and lexical definitions. The Pangloss builders had to acquire more information than could be entered by hand, and so, in the face of increasingly challenging evaluations, were compelled to turn toward (semi-)automated information extraction from existing repositories, such as dictionaries, glossaries, and text corpora. The extracted rules were more general, providing not just the correct output for any input but a list of possible outputs for a general class of inputs, which were then filtered to select the best alternative(s). By the twin moves of extracting information from resources (semi-)automatically and of filtering alternatives automatically, Pangloss gradually took steps toward statistics.
6.3.4 Differences in Methodology and Technology
It is instructive to compare and contrast the methodologies of the two paradigms. Though good research in either paradigm follows the same sequence of five stages, the ways in which they follow them and the outcomes can differ dramatically.
The five stages of methodology:
Problems with the symbolic paradigm are most apparent in stage 3, since manual rule building and data item collection is slow, and in stage 5, since there is a natural aversion to evaluation if it is not enforced. Problems with the statistical paradigm are apparent in stage 2, since parametric models tend to require oversimplification of complex phenomena, and in stage 1, since the sparseness (or even total unavailability) of suitable training data may hamper development.
It is also instructive to compare and contrast the technology built by the two paradigms.
Four aspects of technology:
Method: The symbolic paradigm tends to develop systems that produce a single output per transformation step, while the statistical paradigm tends to produce many outputs per step, often together with ratings of some kind. Later filtering stages then prune out unwanted candidates.
Rules: Symbolic rules tend to have detailed left hand sides (the portions of the rules that contain criteria of rule application), containing detailed features conforming to arbitrarily abstract theories. Statistical rules tend to have left hand sides that are either underspecified or that contain rather surface-level features (i.e., features that are either directly observable in the input or that require little additional prior analysis, such as words or parts of speech).
Behavior: Symbolic systems tend to produce higher quality output when they succeed, but to fail abjectly when their rules or data items do not cover the particular input at hand. In contrast, statistical systems tend to produce lower quality output but treat unexpected input more robustly.
Methods: Symbolic methods include Finite State Algorithms, unification, and other methods of applying rules and data items in grammars, lexicons, etc. Statistical methods include Hidden Markov Models, vector spaces, clustering and ranking algorithms, and other methods of assigning input into general parametric classes and then treating them accordingly.
6.3.5 Overall Status
While it is dangerous to generalize, certain general trends do seem to characterize each approach. With respect to processing, two types of modules can be identified:
With respect to data and rules, creation (whether symbolic or statistical) proceeds as follows. For each linguistic phenomenon / translation bottleneck, system builders:
In symbolic systems, data preparation is mostly done by hand (which is why older systems, with the benefit of years’ worth of hard labor, generally outperform younger ones) while in statistical systems data collection is done almost exclusively by computer, usually using the frequency of occurrence of each datum as the basis from which to compute its reliability (probability) value.
In general, phenomena exhibiting easily identified linguistic behavior, such as grammars of dates and names, seem to be candidates for symbolic approaches, while phenomena with less apparent regular behavior, such as lexically-anchored phrases, require automated rule formation. What constitutes sufficient regularity is a matter both of linguistic sophistication and of patience, and is often legitimately answered differently by different people. Hence, although many phenomena will eventually be treated in all MT systems the same way (either symbolically or statistically), many others will be addressed both ways, with different results.
Experience with statistical and symbolic methods for parsing, word sense disambiguation, and machine translation, then, suggests that neither the symbolic nor the statistical approach is clearly superior. Instead, a hybrid paradigm in which the human’s analysis produces the target for the machine to learn seems to be the most productive use of the strengths of both agencies. This observation may quite likely generalize to all areas of Language Processing. However, at present there is virtually no research into ways of synthesizing the two approaches in the field of computational linguistics. Even among statistics-based approaches, there is little understanding of how various statistical methods contribute to overall results. Systematic consideration of ways to synthesize statistical and symbolic approaches, then, seems to be the next step.
6.4 Where We Go from Here
In order to move toward synthesis of statistical and symbolic approaches to Language Processing, it is first necessary to consider where past experience with both has brought us to date.
What have we learned from theory-based approaches? One of the important (though quite simple) lessons from research in Linguistics is that language is too complex a phenomenon to be accurately treated with simple surface-based models. This fact is acknowledged by the general trend in current linguistic theories toward lexicalization (which is a way to recognize that simple abstract models are not able to represent language complexity without the help of extremely detailed lexical entries), and by the recent turn in computational linguistics to the lexicon as a central resource for sentence and discourse analysis.
Statistical approaches have generally provided us with a clever way to deal with the inherent complexity of language by taking into account its Zipfian nature. In any corpus, a small number of very frequent cases represent a large proportion of occurrences, while the remaining cases represent only a small fraction of occurrences and therefore correspond to rare phenomena. By taking into account the occurrence frequency (which is what probabilities essentially do), a system can quickly cover the most frequent cases and thereby achieve reasonable levels of performance. However, there remains a lot of work to be done to get the remaining cases right; in other words, even the most sophisticated statistical approaches can never achieve 100% accuracy. Furthermore, to the extent they address complex applications, statistical approaches rely on linguistic analysis for guidance. For example, as Speech Recognition research begins to grapple with the problems of extended dialogues, it has to take into the account the effects of pragmatic (speaker- and hearer-based) variations in intonation contour, turn taking noises, and similar non-word-level phenomena.
While it is coming to be widely acknowledged in both the statistical and symbolic Language Processing communities that synthesis of both approaches is the next step for work in the field, it is less clear how to go about achieving this synthesis. The types of contribution of each approach to the overall problem, and even the contribution of different methods within each approach, is not well understood. With this in view, we can recommend several concrete activities to be undertaken in order to move toward synthesis of symbolic and statistical approaches:
(1) A systematic and comprehensive analysis of various methods, together with an assessment of their importance for and contribution to solving the problems at hand, should be undertaken. This is not an easy task. Perhaps more importantly, it is not a task for which funding is likely to be readily forthcoming, since it leads only indirectly to the production of results and is not an end in itself. The trend toward funding for applications rather than basic research is a problem for the entire field–one which, hopefully, can be addressed and rectified in the future.
It will be necessary to develop a precise methodology for an in-depth analysis of methods. Simplistically, one can imagine a "building block" approach, where methods are first broken into individual components and then combined one by one to gain a better understanding of the nature of the contribution of each to a given task. Such an analysis would have to be done over a wide range of samples of varying language types and genres.
In the end, tradeoffs between the two approaches will certainly be recognized, in terms of, for example, precision vs. efficiency. There exist some analyses of such tradeoffs in the literature, but they are neither comprehensive across fields nor, for the most part, systematic enough to be generalizable.
(2) Similarly, resources, including corpora and lexicons, should also be evaluated for their contribution to Language Processing tasks. Recognition of the importance of the lexicon is increasing, but the amount and kind of information in existing lexicons varies widely. We need to understand what kinds of information are useful for various tasks, and where tradeoffs between information in the lexicon (primarily symbolic) and its use by both symbolic and statistical methods can be most usefully exploited. It is also essential to profit from the existence of large corpora and statistical methods to create these resources. In addition, data-driven systems need to be improved to take into account higher level knowledge sources (without losing computational tractability (which is essential in order to train systems on large volumes of data).
For corpora, the current situation may be even more critical (see also
Chapter 1). While large amounts of corpus data exist, current resources are lacking in two significant ways:(3) Multilinguality is key. There has been almost no study of the applicability of methods across languages or attempts to identify language-independent features that can be exploited in NLP systems across languages. Data-driven techniques are often language-independent, and once again, systematic analysis of what works in a multilingual environment is required. Data annotation, on the other hand, is largely language-dependent, but has to be produced in a standardized way in order to enable both system improvement and evaluation. The standardization of annotation formats (as in, for instance, the European EAGLES effort) and international collaboration are crucial here.
(4) Application technology push. Each of the four major application areas should be stimulated to face its particular challenges. Automated Speech Recognition should continue its recently begun move to dialogue, as evinced in DARPA’s COMMUNICATOR program and others, putting more language in the language models (syntax) and more speech in the speech models (speech acts)–see
Chapter 5. Machine Translation (Chapter 4) should pursue coverage and robustness by putting more statistics into symbolic approaches and should pursue higher quality by putting more linguistics into statistical approaches. Information Retrieval (Chapter 2) should focus on multilinguality, which will require new, statistical, methods of simplifying traditional symbolic semantics. Text Summarization and Information Extraction (Chapter 3) should attack the problems of query analysis and sentence analysis in order to pinpoint specific regions in the text in which specific nuances of meaning are covered, mono- and multilingually, by merging their respective primarily statistical and primarily symbolic techniques.6.5 Conclusion
Natural language processing research is at a crossroads: both symbolic and statistical approaches have been explored in-depth and the strengths and limitations of each are beginning to be well understood. We have the data to feed the development of lexicons, term banks, and other knowledge sources, and we have the data to perform large-scale study of statistical properties of both written and spoken language in actual use. Coupled with this is the urgent need to develop reliable and robust methods for retrieval, extraction, summarization, and generation, due in large part to the information explosion engendered by the development of the Internet. We have the tools and methods, yet we remain far from a solid understanding a general solution to the problem.
What is needed is a concerted and coordination of researchers across the spectrum of relevant disciplines, and representing the international community, to come together and shape the bits and pieces into a coherent set of methods, resources, and tools. As noted above, this involves, in large part, a systematic and pains-taking effort to gain a deep understanding of the contributing factors and elements, from both a linguistic and a computational perspective. However this may best be accomplished, one thing is clear: it demands conscious effort. The current emphasis on the development of applications may or may not naturally engender the sort of work that is necessary, but progress will certainly be enhanced with the appropriate recognition and support.
6.6 References
Abney, S. 1996. Statistical Methods and Linguistics. In J. Klavans and Ph. Resnik (eds.), The Balancing Act. Cambridge, MA: MIT Press.
Brown, P.F., J. Cocke, S. Della Pietra, V. Della Pietra, F. Jelinek, J. Lafferty, R. Mercer, P. Roossin. 1990. A Statistical Approach to Machine Translation. Computational Linguistics 16(2) (79—85).
Charniak, E. 1997. Statistical Parsing with a Context-Free Grammar and Word Statistics. Proceedings of Fourteenth National Conference on Artificial Intelligence (AAAI-97). Providence, RI (598—603).
Chomsky, N. 1957. Syntactic Structures. The Hague, The Netherlands: Mouton.
Church, K.W. and R. Mercer. 1993. Introduction to the Special Issue on Computational Linguistics Using Large Corpora. Computational Linguistics 19(1) 1—24.
Collins, M.J. 1996. A New Statistical Parser Based on Bigram Lexical Dependencies. Proceedings of the 34th Annual Meeting of the Association for Computational Linguistics (ACL). Santa Cruz, CA (184—191).
Collins, M.J. 1997. Three Generative, Lexicalised Models for Statistical Parsing. Proceedings of the35th Annual Meeting of the Association for Computational Linguistics (ACL). Madrid, Spain (16—23).
DARPA. 1989—1994. Proceedings of conference series initially called Workshops on Speech and Natural Language and later Conferences on Human Language Technology. San Francisco: Morgan Kaufmann.
Dorr, B.J. 1994. Machine Translation Divergences: A Formal Description and Proposed Solution. Computational Linguistics 20(4) (597—634).
Frederking, R., S. Nirenburg, D. Farwell, S. Helmreich, E. Hovy, K. Knight, S. Beale, C. Domanshnev, D. Attardo, D Grannes, R. Brown. 1994. Integrating Translations from Multiple Sources within the Pangloss Mark III Machine Translation System. Proceedings of the First AMTA Conference, Columbia, MD (73—80).
Harris, Z.S. 1951. Methods in Structural Linguistics. Chicago: University of Chicago Press.
Hermjakob, U. and R.J. Mooney. 1997. Learning Parse and Translation Decisions from Examples with Rich Context. Proceedings of the35th Annual Meeting of the Association for Computational Linguistics (ACL). Madrid, Spain (482—489).
Hermjakob, U. 1999. Machine Learning Based Parsing: A Deterministic Approach Demonstrated for Japanese. Submitted.
Hobbs, J.R., D.E. Appelt, J. Bear, M. Tyson, and D. Magerman. 1992. Robust Processing of Real-World Natural-Language Texts. In P. Jacobs (ed), Text-Based Intelligent Systems: Current Research and Practice in Information Extraction and Retrieval. Hillsdale, NJ: Lawrence Erlbaum Associates (13—33).
Ide, N. 1998. Corpus Encoding Standard: SGML Guidelines for Encoding Linguistic Corpora. Proceedings of the First International Language Resources and Evaluation Conference (LREC). Granada, Spain (463—470).
Ide, N. and J. Véronis. 1990. Very large neural networks for word sense disambiguation. Proceedings of the 9th European Conference on Artificial Intelligence (ECAI’90). Stockholm, Sweden (366—368).
Ide, N. and J. Véronis. 1998. Introduction to the Special Issue on Word Sense Disambiguation: The State of the Art. Computational Linguistics 24(1) 1—40.
Johnson, R.L, M. King, and L. Des Tombe. 1985. EUROTRA: A Multi-Lingual System under Development. Computational Linguistics 11, (155—169).
Kilgarriff, A. and M. Palmer. forthcoming. The Senseval Word Sense Disambiguation Exercise Proceedings. Computers and the Humanities (special issue), forthcoming.
Klavans, J.L. and Ph. Resnik. 1997. The Balancing Act: Combining Symbolic and Statistical Approaches to Language. Cambridge, MA: MIT Press.
Magerman, D.M. 1995. Statistical Decision-Tree Models for Parsing. Proceedings of the 33rd Annual Meeting of the Association for Computational Linguistics (ACL). Cambridge,MA (276—283).
Niemann, H., E. Noeth, A. Kiessling, R. Kompe and A. Batliner. 1997. Prosodic Processing and its Use in Verbmobil. Proceedings of ICASSP-97, (75—78). Munich, Germany.
Pendergraft, E. 1967. Translating Languages. In H. Borko (ed.), Automated Language Processing. New York: John Wiley and Sons.
Shannon, C.E. and W. Weaver. 1949. The Mathematical Theory of Communication. Urbana, IL: University of Illinois Press.
Small, S.L. and Ch. Rieger. 1982. Parsing and comprehencing with word experts (a theory and its realization). In W. Lehnert and M. Ringle (eds.), Strategies for Natural Language Processing. Hillsdale, NJ: Lawrence Erlbaum and Associates (89—147).
White, J. and T. O’Connell. 1992—94. ARPA Workshops on Machine Translation. Series of 4 workshops on comparative evaluation. PRC Inc., McLean, VA.
Wilks, Y., D. Fass, Ch-M. Guo, J.E. MacDonald, T. Plate, and B.A. Slator. 1990. Providing Machine Tractable Dictionary Tools. In J. Pustejovsky (ed.), Semantics and the Lexicon. Cambridge, MA: MIT Press.
Yamron, J., J. Cant, A. Demedts, T. Dietzel, Y. Ito. 1994. The Automatic Component of the LINGSTAT Machine-Aided Translation System. In Proceedings of the ARPA Conference on Human Language Technology, Princeton, NJ (158—164).
[This chapter is available as http://www.cs.cmu.edu/~ref/mlim/chapter7.html .]
[Please send any comments to Robert Frederking (ref+@cs.cmu.edu, Web document maintainer) or Ed Hovy or Nancy Ide.]
Chapter 7
Speaker-Language Identification
and Speech Translation
Editor: Gianni Lazzari
Contributors:
Gianni Lazzari
Robert Frederking
Wolfgang Minker
Abstract
Significant progress has been made in the various tasks of speaker identification, speaker verification, and spoken and written language identification--the last being a completely solved problem. The translation of spoken language, however, remains a significant challenge. Progress in speaker identification and verification is hampered by problems in speaker variability due to stress, illness, etc. Progress in spoken language translation is hampered not only by the traditional problems of machine translation (see Chapter 4), but also by ill-formed speech, non-grammatical utterances, and the like. It is likely to remain a significant problem for some time to come.
7.1 Definitions
Automatic Speaker Identification (Speaker ID) is the ability of a machine to determine the identity of a speaker given a closed set of speakers. It is therefore is an n-class task. Speaker Verification (Speaker VE), on the other hand, is a single-target open set task, since it is the ability of a machine to verify whether a speaker is who he or she claims to be. Both problems can be seen as instance of a more general speaker recognition (Speaker RE) problem. Speaker recognition can be text-dependent or text-independent. In the former case the text is known, i.e., the system employs a sort of password procedure. Knowledge of the text enables the use of systems that combine speech and speaker recognition, whereby the customer is asked to repeat one or more sentences randomly drawn from a very large set of possible sentences. In the case of text-independent speaker recognition, the acceptance proced! ure should work for any text. Traditionally this problem is related to security applications. More recent application areas include broadcast news annotation and documentation.
Automatic Spoken Language Identification (Language ID) is the ability of a machine to identify the language being spoken from a sample of speech by an unknown speaker (Muthusamy et al., 1994a). The human is by far the best language ID system in operation today. If somebody knows the language being spoken, they are able to positively identify it within a few seconds. Even if they don't know the language, people can often make ‘sounds like French' statements. Several important applications already exist for language ID. A language ID system can be used as a front-end system to a telephone-based international company, routing the caller to an appropriate operator fluent in the caller's language to serve business, the general public, and police departments handling 911 emergency calls.
Automatic Text Language Identification is a solved problem. Several techniques exist, and it is possible to get near 100% accuracy on just ten words of input. For large sets of languages, this should surpass human abilities. The best technique seems to be training a classifier on documents in the different languages (a machine learning technique).
Spoken Language Translation (SLT) is the ability of a machine to interpret a multilingual human-human spoken dialog. The feasibility of spoken language translation is strongly related to the scope of application, which ranges from interpretation of the speaker's intent in a narrow domain to unrestricted, fully automatic simultaneous translation. The latter is not feasible in the foreseeable future. Historically Machine Translation (MT) applications (see
Chapter 4) have been divided into two classes:Spoken Language Translation seems to belong to a different class of applications, the communication between two individuals (see also
Chapter 5). Often a narrow domain may be sufficient, but it is hard to control style. Bidirectional, real-time operation is necessary, but fairly low quality is acceptable if communication is achieved. An MT system does not necessarily need to give an absolutely correct solution, if it produces a sufficient expression in the Target Language satisfying the dialogue situation.7.2 Where We Were Five Years Ago -- Speaker ID
7.2.1 Capabilities
The field of speaker recognition shows considerable activity in research institutions and industry, including AT&T, BBN, NTT, TI, the Dalle Molle Institute, ITC-IRST, MIT Lincoln Labs, Nagoya University, National Tsing Hua University of Taiwan. In the US, NIST and NSA have conducted speaker recognition systems evaluation and assessment. (Campbell, 1997).
As discussed in
Chapter 5, speech is a very complex signal occurring as a result of several transformations at different levels: semantic, linguistic, articulatory and acoustic. Differences in these transformations appear as differences in the spectral properties of the speech signal. Speaker-related differences are a result of a combination of anatomical differences inherent in the vocal tract and the learned speaking habits of different individuals. In speaker recognition, all these differences can be used to discriminate between speakers.The general approach to Speaker RE consists of four steps: digital speech data acquisition, parameter extraction, and pattern matching (this implies an enrollment phase to generate reference models). In the case of Speaker VE, a fifth step concerns the decision to accept or reject the claimed speaker.
7.2.2 Major Methods, Techniques, and Approaches
Speech information is primarily conveyed by the short-time spectrum, the spectral information contained in an interval of 10—30 ms. While the short-term spectra do not completely characterize the speech production process, the information carried by it is basic to many speech processing systems, including speech and speaker recognition. There are so many methods to characterize a short-time spectrum, but the dominant features used in previous and current systems are cepstral and delta cepstral parameters derived by filterbank analysis.
Different features often found in literature are based on computation of the Linear Prediction Coefficients, from which different parameters can be derived, i.e., LPC cepstrum, reflection coefficient, log area ratios, etc. Prosodic features, such as pitch and duration, have been proposed in the past and also methods based on nonlinear discriminant analysis (NLDA) (Gnanadesikan and Kettenring, 1989) have been evaluated.
While the past seven years have seen no great change in the features selection component of speaker recognition systems, the pattern matching component followed the trend taken in the speech recognition area. As a matter of fact, the methods of VQ (Vector Quantization), DTW (Dynamic Time Warping), and NN (Nearest Neighbors) are now less common than HMM (Hidden Markov Models) and ANN (Artificial Neural Networks). In general, statistical modeling seems to deliver the best results when robustness and adaptation are mandatory, i.e., in almost all real applications: over the telephone, with a target of a high number of speakers (Gish and Schmidt, 1994).
A very popular technique adopts an unsupervised representation of target. Two models are used; the first, which is dominant in speaker recognition, is called Adapted Gaussian Mixture Models. In this case the background model is a speaker independent Gaussian Mixture Model (GMM) (Reynolds, 1995; Reynolds and Rose, 1995), while the target model is derived from the background by Bayesian adaptation. The latter is based on the use of Unadapted Gaussian Mixture Models; in this case the target model is trained using ML (Maximum Likelihood) estimation. Other diffused techniques include ergodic HMM, unimodal Gaussian, and auto-regressive vectors. Mixture modeling is similar to VQ identification in that voices are modeled by components or clusters. Model components may be "phonetic units" learned with a supervised labeling by a continuous speech recognizer. Speaker-independent and speaker-dependent likelihood scores are then compared. Model component! s could also be "broad phonetic class", obtained by a suitable recognizer. Target and background label matches are then compared.
Temporal decomposition plus neural nets have also been exploited: MLPs are trained to discriminate target and non-target VQ-labeled training data. This technique has not benefited speaker recognition, but has proven useful in language recognition.
Two other techniques--normalization and fusion--have been pursued in order to improve robustness. Normalization with respect to speaker and handset is very important in order to overcome the mismatch between training and test conditions. In particular, handset type mapping (electricity to carbon-button speech or vice-versa) has great importance, given the degree of mismatch caused by this kind of handset.
Fusion is also very important in order to increase system performance, especially in the case of secure speaker verification. The most important methods, used in typical pattern recognition systems are linear combinations of systems, voting systems, and MLP-based fusion.
7.2.3 Major Bottlenecks and Problems
The major bottlenecks and problems are related to the same factors that occur in speech recognition.
A large numbers of people could be potential users of these systems. There is a high intra-speaker variability over time due to health (respiratory illness, laryngitis, etc.) stress, emotional factors, speech effort and speaking rate, aging, gender, etc. Moreover, the telephone channel variability and noise and the microphone/handset differences have to be taken into account. Difficulties arise also when dealing with the effects of the communication channel through which speech is received. The variability essentially distorts their pattern in the features space, increasing confusion. Crosstalk is another type of event that increases variability.
7.3 Where We Will Be in Five Years -- Speaker ID
7.3.1 Expected Capabilities
Speaker recognition is adopted because other technology demands it. Limited performance may be acceptable in some applications; in other situations, Speaker RE can be used with other technologies, such as biometrics (Brunelli and Falavigna, 1995) or word recognition. The performance of current speaker recognition systems is suitable for many practical applications. Existing products already on the market (Campbell, 1997) are mainly used for speaker verification applications such as access control, telephone credit cards, and banking. The number of speaker verification applications will grow in the next five years and this will drive the research towards more robust modeling in order to cover as much as possible unexpected noise and acoustic events and to reduce (at best) the number of high-tech thieves.
Two new classes of applications seem to increase in demand: speech archiving and broadcast news documentation, including wire tapping and multimodal interaction. In the first case the problem is to identify and track, in batch mode or in real-time, a speaker in a radio, video or generally a multimedia archive. In the latter, knowing who is interacting will not only log on the user to some service but also help the system to provide better user modeling. For more details, see
Chapter 9.In general, as a matter of fact, speaker identification will be a value-added function when a spoken communication channel is available.
7.3.2 Expected Methods and Techniques (Breakthroughs)
Progress has generally been gradual. Comparing different systems presented in the literature is a hard problem, given the different kind and amount of data used for test and different types of tests, e.g., the binary-choice verification task or the multiple-choice identification task. Nevertheless, the general trend shows accuracy improvements over time, from seven years ago, with larger data set. The size in the last five years has increased by a factor of ten or even more. The error rate ranges from 0.3% recognition error, for both speaker verification or identification in text dependent mode, non-telephone speech with a minimum amount of 2 second speech data, to 16% speaker verification error in text independent mode, telephone quality speech, mismatched handset with at least 3 seconds of speech. In the last case, the verification error drops to 5% after 30 seconds of speech. For a detailed analysis of recent results see
http://www.nist.gov/speech/spkrec98.htm and (Martin and Przybocki, 1998).From the point of view of new techniques and approaches adopted, novel training and learning methods devoted to a broader coverage of different and unexpected acoustic events will be necessary. New features selection methods and stochastic modeling will grow in importance, taking account the better performance that can be offered when more flexibility is required. Stochastic modeling, as known in speech recognition, also offers a more theoretically meaningful probabilistic score.
Moreover, if new applications are envisaged, methodologies for data fusion will be necessary.
7.3.3 Expected Bottlenecks
A major bottleneck for the future is data availability and data collection, both for training and for testing. Fast adaptation methods and efficient training will be critical in near future; if such methods become available, a great development of real word application will occur, especially in the field of speaker verification.
7.4 Where We Were Five Years Ago -- Language ID
7.4.1 Capabilities
Advances in the spoken language understanding area and the need of global communication have increased the importance of Language Identification, making feasible the availability of multilingual information services, such as checking into a hotel, arranging a meeting, or making travel arrangements, which are difficult actions for non native speakers. Telephone companies can handle foreign language calls when a Language ID system is available; this is particularly important for routing (emergency) telephone calls.
This research subject flourished in the last four, five years. In the past, language ID was a niche research topic, with few studies in an incoherent picture (Muthusamy et al., 1994a).
In March 1993, the OGI_TS (Muthusamy et al., 1992) database was designated as the standard for evaluating Language ID research and algorithms by the NIST. Since that time, many institutions have contributed to this field and are participating in evaluations. Although Language ID has become a major interest only recently, since then it has been able to build some objective comparisons among various approaches.
7.4.2 Major Methods, Techniques, and Approaches
Before going into description of methods and techniques, it is necessary to define the sources of information useful for Language ID. It is also very important to understand how humans are able to identify languages.
Generally, in speech recognition acoustic unit modeling is sufficient for decoding the content of a speech signal. The problem here is that in text independent Language ID phonemes or other subword units are not sufficient cues to determine the ‘acoustic signature' of a language. Different sources of information are necessary to identify a language, the most important obviously being the vocabulary. Above all languages are distinct because they use different set of words. Non-native speakers of a language, e.g., German, can use the phonetic inventory and prosodic features of their native language and be identified as German speakers. Second, Acoustic Phonetic and Phonotactics differ from language to language. Finally, duration of phones, intonation, and speech rate are typical language cue, making Prosody an important source of information for language ID.
Perceptual studies provide benchmarks for evaluating machine performance. It is known that humans use very short selected speech events, where the choice is based on several different sources of information. While many experiments have provided interesting results (Muthusamy, et al., 1994b), the difference of subjects and languages makes it difficult to determine the features that human would use to distinguish among unfamiliar languages.
Language ID is highly related to speech recognition and speaker ID in many ways. Both acoustic modeling (AM) and language modeling (LM) in speech recognition have strong relations with AM and LM in Language ID.
The basic architecture of a Language ID system (Zissman, 1996) is based on a cascade of the following components: acoustic representation (parameter extraction), followed by a pattern recognition component which exploits an alignment, taking account two sources of knowledge, an acoustic model and a language model. The alignment procedure will produce a language score. The approaches differ first in their acoustic representation (are prosodic features used?), and second in acoustic modeling (is it a single stochastic model for language involved, more acoustic unit models per language, more stochastic grammar of unit sequences?) (Nakagawa et al., 1994).
Finally, another important distinction is whether the system is text dependent or not. When text independent systems are involved, front-end systems for services like 911, in which a Language ID connects the user with the ‘right' human translator, it is generally not feasible to build word models in each of the target language. When text dependent systems are developed, a front-end Language ID for multilingual information systems such as flight or train information, an implicit identification can be obtained. Indeed, the trained recognizers of the languages to be recognized, the lexicon, and the language models are combined in one multilingual recognizer. Each hypothesized word chain is only made of words from one language and language identification is an implicit by-product of a speech recognizer (Noeth et al., 1996).
7.4.3 Major Bottlenecks and Problems
The major bottlenecks and problems are related to the same factors that occur in speech recognition. A major problem is the mismatch due to the communication channel features of the training and the test condition. Another bottleneck is represented by the type of system to be created. When text independent features are needed and acoustic units (e.g., phoneme like) are to be trained, or the training phase is to be booted, a large amount of phonetically labeled data in each of the target language is needed. On the other hand, when text dependent system are needed, a multilingual speech recognizer has to be built and this is feasible in the near future only for subsets of languages.
Of the main sources of variability across languages, prosodic vocabulary information has not been successfully incorporated into a Language ID system. This is also true in speech recognition. Only recently, in the framework of Verbmobil (Niemann et al., 1997), has prosody been integrated in a spoken language system successfully.
Performances are not adequate for managing a large number of languages, whereas it is acceptable in the case of restricted class of languages (e.g., English, German, Spanish, Japanese) with clearly different cues (Corredor-Ardoy et al. 1997).
7.5 Where We Will Be in Five Years -- Language ID
7.5.1 Expected Capabilities
Following the trends of multilinguality in speech recognition, Language ID capabilities will increase in the next years. Multilingual information systems need Language ID as a front end, for both technological reasons (performance will be not acceptable) and multilinguality requirements. More difficult will be the development of a general purpose Language ID system for special Telecom services, such as 911 in the USA or 113 in Italy. Difficulties came from the high number of languages and time constraints.
7.5.2 Expected Methods and Techniques (Breakthroughs)
Progress has generally been gradual. A comparison with different systems presented in literature is hard, given the different kind and amount of data used for the test, different type of test, e.g., pairwise classification task or multiple-choice (e.g., 12 closed set) identification task. Nevertheless the general trend shows accuracy improvements over time, with larger data-test and improving acoustic and phonotactics modeling. The error rate depends on many factors, first on the duration of the utterance (15 seconds vs 30 minutes), then on the architecture, a single acoustic model or more acoustic models, and finally on the type of classifier, pairwise or multiple choice. Results of NIST 1996 are reported in (Zissman, 1996).
Methods and techniques for Language ID processing will follow the trends in speech recognition and spoken language understanding. The integration of prosodic information, both at the feature extraction and decoding level, will be the next important milestone. A potential improvement is expected from perceptual studies. Knowing the human strategies will suggest suitable machine strategies (e.g., keywords, key phrases to be decoded in a particular level). The biggest difficulty is and will be the statistical modeling of such information, i.e., how to add such knowledge in a probabilistic framework. For text independent Language ID, an improvement in the statistics modeling or adaptation of phones (Zissman, 1997) is very important, given its dependence on the manner (monologue, dialogue, etc.) of speech data collection.
7.5.3 Expected Bottlenecks
A major bottleneck, also for the future, will be data availability and data collection both for training and testing. Fast adaptation methods for channel normalization and efficient training will be critical in near future. When such methods become available, great development of real word applications will occur, especially in the field of Language ID.
Another bottleneck will be represented by the short period of time available for critical services, i.e., less than 30 seconds.
7.6 Where We Were Five Years Ago -- Spoken Language Translation
Early speech translation systems implemented in the eighties mainly had the purpose to demonstrate the feasibility of the concept of speech translation. Their main features included restricted domains, severe limitations on fixed speaking style, grammatical coverage, and limited size vocabulary. System architecture was usual strictly sequential, involving speech recognition, language analysis and generation, and speech synthesis in the target language. Developed at industrial and academic institutions like NEC, AT&T, ATR, Carnegie Mellon University, Siemens AG, University of Karlsruhe, and SRI and consortia, they represented a significant first step and demonstrated that multilingual communication by speech might be possible.
The VEST system (Roe et al., 92), successfully demonstrated at EXPO'92 in Seville, was developed in a collaboration between AT&T and Telefonica in Spain. It used a vocabulary of 374 morphological entries and a finite state grammar used for both language modeling and translation of English and Spanish in the domain of currency exchange.
NEC's Intertalker system, successfully demonstrated at GlobCom'92, allowed utterances in the domain of reservation of concert tickets and travel information. A finite state grammar was used also in this system for processing input sentences.
An interesting attempt to extend spontaneous multilingual human-machine dialogues to translation is represented by a system developed at SRI in collaboration with Telia (Rayner et al., 1993). It is based on previously developed system components from SRI's air travel information system (ATIS) and is interfaced with a generation component. The system's input language is English and it produces output in Swedish.
Speech translation encourages international collaborations. Prominent among these, the C-STAR I Consortium for Speech Translation Research has been set up as a voluntary group of institutions. Its members, ATR Interpreting Telephony Laboratories (now Interpreting Telephony Laboratories) in Kyoto, Japan; Siemens AG in Munich and University of Karlsruhe (UKA) Germany; and Carnegie Mellon University (CMU) in Pittsburgh, PA, USA, have developed prototype systems that accept speech in each of the members' languages (English, German, and Japanese), and produce output text in all the others (Morimoto et al., 1993; Waibel et al., 91; Woszczyna et al., 1994).
Another prominent collaboration is Verbmobil phase I, a large new research effort sponsored by the BMFT, the German Ministry for Science and Technology (Wahlster, 1993; Kay et al., 1994; Niemann, 1997). Launched in 1993, the program sponsored over 30 German industrial and academic partners who work on different aspects of the speech translation problem and are delivering system components for a complete speech translation system. Verbmobil is aimed at face-to-face negotiations, rather than telecommunication applications, and assumes that two participants have some passive knowledge of a common language, English. It aims to provide translation on demand for speakers of German and Japanese, when they request assistance in an otherwise English conversation. Verbmobil is an eight-year project with an initial four-year phase.
7.6.1 Capability Now
The feasibility of speech translation depends mainly on the extent of the application. Applications such as voice-activated dictionaries are already feasible, while unrestricted simultaneous translation will remain impossible for the foreseeable future. Current research goals therefore range within these extremes. The language and discourse modeling in these systems restrict the user in what he or she can talk about, and hence constrain the otherwise daunting task of modeling the world of discourse. There are no commercial speech translation systems on the market to date, but a number of industrial and government projects are exploring their feasibility.
Spoken language translation systems could be of practical and commercial interest when used to provide language assistance in some critical situations, such as between medical doctor and patient, in police assistance situations, or in foreign travel interactions such as booking hotels, flights, car rentals, getting directions, and so on.
Spoken language translation, even in limited domains, still presents considerable challenges, which are the object of research in several large research undertakings around the world.
7.6.2 Major Methods, Techniques, and Approaches
The translation of spoken language (unlike text) is complicated by ill-formed speech, human noise (coughing, laughter, etc.) and non-human noise (door-slams, telephone rings, etc.), and has to cope with speech recognition errors. The spoken utterance is not segmented in words like text and often contains information that is irrelevant with respect to the given application and that should not be translated. In the everyday person-to-person dialogues, even simple concepts are spoken in quite different ways. A successful system should therefore be capable to interpret the speaker's intent, instead of literally translating the speaker's utterances, to produce an appropriate message in the target language.
There are many approaches to spoken language translation; some of them are also mentioned in
Chapter 5. They can roughly be divided in two classes: direct approaches that try to link speech recognition and machine translation techniques, and interlingual approaches that try to decode both recognition and understanding into a common consistent framework. Both have many different instantiations. An example of the first case is followed at ATR (Iida, 1998). The recognizer outputs a word graph that is directly accepted by an MT system using a chart parser mechanism with an integrated translation method. This framework can be called a cooperative integrated translation, simultaneously executing both example-based translation and dependency structure analysis. In this context, the basic technologies would include the calculation of logical forms instead of syntactic parsing, abduc! tion instead of deduction, ‘chart' structure under graph connection instead of a structure under linear connection, maximally partial understanding, translation instead of definitive understanding, creating and roughly handling images that correspond to object representations with feature properties (frame representations), and flexible generation adaptable to situations (courteous conversation, customer-clerk conversation, conversation for persuasion, etc.). Other approaches include Example Based Translation (EBMT) (Iida, 1998), that improves portability and reduces development cost through the use of large parallel corpora. Robust Transfer Approaches are also explored, with robust and stochastic analysis to account for fragmentary input.An example of the second case is followed in the framework of Verbmobil phase II and C-STAR II. Present activity has shifted toward a greater emphasis on interpretation of spoken language, i.e., the system's ability to extract the intent of a speaker's utterance (Bub and Schwinn, 1996). Several institutions involved in C-STAR therefore stress an interlingual representation and the development of generation component from the given interlingual representation (CMU, UKA, ETRI, IRST, and CLIPS) (Angelini et al., 1997). Each C-STAR II partner builds a complete system that at the very least accepts input in one language and produces output in another language of the consortium. In a multinational consortium, building full systems thereby maximizes the technical exchange between the partners while minimizing costly software/hardware interfacing work.
Discourse and domain knowledge and prosodic information are being explored, for more robust interpretation of ambiguous utterances.
7.6.3 Major Bottlenecks and Problems
Speech translation involves aspects of both person-to-person and person-machine dialogues. Person-to-person speech contains more dysfluencies, more speaking rate variations, and more coarticulation, resulting in lower recognition and understanding rates than person-machine speech, as indicated by experiments over several speech databases in several languages. Further technological advances are required based on a new common speech and language processing strategy, resulting in a closer integration between the acoustic and linguistic levels of processing.
To develop more practical spoken language translation systems, greater robustness is needed in the modeling and processing of spontaneous ill-formed speech. The generation of an interlingua representation requiring an underlying semantic analysis is typically done in a specific context. As long as a speaker stays within the expected bounds of the topic at hand (such as appointment or train schedules, for instance), a system which can process topic-related utterances will be satisfactory, even if it fails when given more general input.
In response to these general constraints, approaches applied to generate interlingua representations are typically those that allow semantic (that is, topic-related) and syntactic information to be captured simultaneously in a grammar (Fillmore, 1968; Bruce, 1975). These robust semantic grammars are very popular, as they provide a convenient method for grouping related concepts and features while allowing syntactic patterns that arise repeatedly to be shared easily. Semantic grammars are usually parsed using some method that allows a subset of the input words to be ignored or skipped.
However, the achieved robustness may turn out into a drawback. A grammar formalism that is based on a purely semantic analysis may ignore important information which is propagated by syntactic relations. Ignoring syntax information prevents from a sufficiently detailed interlingua presentation, which is necessary for a smooth translation.
A number of research activities aiming at the translation of spontaneous speech are under way. Several industrial and academic institutions, as well as large national research efforts in Germany and in Japan, are now working on this problem. The goals are oriented to removing the limitation of a fixed vocabulary and requiring the user to produce well-formed (grammatical) spoken sentences, accepting spontaneous spoken language in restricted domains. One example system that aims to integrate both the robustness of semantic analysis and smoothness of the translation is Janus, a speech translation system that processes spontaneous human-to-human dialogs in which two people from different language groups negotiate to schedule a meeting (Waibel et al., 1996). The system operates in a multilingual appointment scheduling task. It focuses on the translation of spontaneous conversational speech in a limited domain in different languages. Janus explores sev! eral approaches for generating the interlingua, including a robust version of the Generalized Left-Right parser, GLR* (Lavie, 1993), which is similar to Lexical Functional Grammar based parsers, and an extension of the CMU-Phoenix parser (Ward et al., 1995) that uses a robust semantic grammar formalism. This integration is to provide high fidelity translation, whenever possible and robust parsing, facing ill formed or misrecognized input.
Evaluation in spoken language translation is a bottleneck, both with regard to methodology and effort required.
Generation and synthesis are also topics of interest. Current concatenative speech synthesis technology is reasonably good; at least, it works better than the SR and MT components do.
7.7 Where We Will Be in Five Years -- Spoken Language Translation
7.7.1 Expected Capabilities
A major target of the future is the Portable Translator Application. The desiderata of this helpful device include physical portability, real-time operation, good human factors design, and management of as many (minor) languages as possible. Rapid development will also be a necessary key feature for the success of such a device, as is being investigated by the DIPLOMAT project (Frederking et al. 97). The spoken input has to be managed as well as possible in order to deal with degraded input, due mainly to spontaneous speech dysfluencies and speech recognizer errors.
7.7.2 Expected Methods and Techniques (Breakthroughs)
To achieve greater portability across domains it is mandatory to improve language component reusability. Most state-of-the-art translation systems apply rule-based methods and are typically well-tuned to limited applications. However, the manual development is costly as each application requires its own adaptation or, in the worst case, a completely new implementation. More recently there has been interest in extending statistical modeling techniques from the acoustic and syntactic levels of speech-recognition systems to other levels such as the modeling of the semantic content of the sentence. As discussed in
Chapter 1, most language work still requires a great amount of resources; for example, language models and grammar development require large amounts of transcribed data within each domain. On the other hand, acoustic models can be reused to a certain extent ! across domains and multilingual acoustic models are promising.The limitation to restricted domains of discourse must be relaxed for real applications. Intermediate goals might be given by large domains of discourse that involve several subdomains. Integration of subdomains will need to be studied. The C-STAR II and Verbmobil II projects are aiming to demonstrate the feasibility of integration of subdomains by merging into a big travel planning domain appointment scheduling, hotel reservation tasks, transport information management, and tourist information delivery.
Finally, better person-computer communication strategies have to be developed, if the purpose is to interpret the speaker's aim rather than the straightforward translation of the speaker's words. A useful speech translation system should be able to inform the user about misunderstandings, offerings, and negotiating alternatives, handling interactive repairs. As a consequence an important requirement is a robust model of out of domain utterances.
7.7.3 Expected Bottlenecks
Optimum translation systems need to integrate and to counterbalance four issues that are sometimes contradictory. These are the robustness of the translation system versus the correctness and smoothness of the translation, and the application-specific tuning versus portability of the system to new applications.
An expected bottleneck is evaluation, including the appropriate corpora required.
A second bottleneck, more complex than the first, is the development of the Interlingua approach, mainly for different languages and heritage, including Western and Asian.
7.8 Juxtaposition of this Area with Other Areas and Fields
The areas discussed in this chapter relate closely to several other areas of Language Processing, in fairly obvious ways. Language and speaker recognition may be used together to route messages. Language recognition may be front end for further speaker or speech processing. Speaker recognition may assist speech recognition. Speaker and speech recognition may be used together for access control. Routing (emergency) telephone calls is important language application.
7.9 The Treatment of Multiple Languages in this Area
Multilingual applications are the aim of this research area. To meet the challenges in developing multilingual technology, an environment and infrastructure must be developed. Contrary to research fostered and supported at the national level, multilingual research tends to involve cooperations across national boundaries. It is important to define and support efficient, international consortia that agree to jointly develop such mutually beneficial technologies. An organizational style of cooperation with little or no overhead is crucial, involving groups who are in a position to build complete speech translation systems for their own language. There is a need for common multilingual databases and data involving foreign accents. Moreover, better evaluation methodology over common databases is needed to assess the performance of speech translation systems in terms of accuracy and usability. Research in this direction needs to! be supported more aggressively across national boundaries.
7.10 References
Angelini, B., M. Cettolo, A. Corazza, D. Falavigna, and G. Lazzari. 1997. Person to Person Communication at IRST. Proceedings of ICASSP-97 (91—94). Munich, Germany.
Bruce, B. 1975. Case Systems for Natural Language. Artificial Intelligence vol. 6 (327—360).
Brunelli R., and D. Falavigna. 1994. Person identification using multiple cues. IEEE Transactions on Pattern Analysis and Machine Intelligence, 17(10) (955—966). Also IRST-Technical Report, 1994.
Bub, W.T. and J. Schwinn. 1996. Verbmobil: The Evolution of a Complex Large Speech-to-Speech Translation System. Proceedings of ICSLP (2371—2374).
Campbell, J.P. 1997. Speaker Recogntion: a tutorial. Proceedings of the IEEE 85(9) (1437—1462).
Corredor-Ardoy, C., J.L. Gauvain, M.Adda-Decker, L.Lamel. 1997. Language Identification with Language-Independent Acoustic Models. Proceedings of EUROSPEECH, vol. 1 (55-58). Rhodes, Greece.
Fillmore, Ch. J. 1968. The Case for Case. In E. Bach and R.T. Harms (eds.), Universals in Linguistic Theory. Holt, Rinehart and Winston Inc. (1—90).
Frederking, R., Rudnicky, A., and Hogan, C.
Gish, H. and M. Schmidt. 1994. Text-independent speaker identification. IEEE Signal Processing Magazine 11 (18—32).
Gish, H., M. Schmidt, A. Mielke. 1994. A robust segmental method for text-independent speaker identification. Proceedings of ICASSP-94, vol. 1 (145—148). Adelaide, South Australia.
Gnanadesikan, R. and J.R. Kettenring. 1989. Discriminant analysis and clustering. Statistical Science 4(1) (34—69).
Iida, H. 1998. Speech Communication and Speech Translation. Proceedings of the Workshop on Multilingual Information Management: Current Levels and Future Abilities. Granada, Spain.
Kay, M., J.M. Gawron, and P. Norvig. 1994. Verbmobil: A Translation System for Face-to-Face Dialog. CSLI Lecture Notes No. 33, Stanford University.
Lavie, A. and M. Tomita. 1993. GLR*--An Efficient Noise Skipping Parsing Algorithm for Context Free Grammars. Proccedings of IWPT-93 (123—134).
Martin A. and M. Przybocki 1998. NIST speaker recognition evaluation. Proceedings of the First International Conference on Language Resources and Evaluation (331-335). Granada, Spain.
Minker, W. 1998. Semantic Analysis for Automatic Spoken Language Translation and Information Retrieval. Proceedings of the Workshop on Multilingual Information Mangament : Current Levels and Future Abilities. Granada, Spain.
Morimoto, T., T. Takezawa, F. Yato, S. Sagayama, T. Tashiro, M. Nagata, A. Kurematsu. 1993. ATR speech translation system: ASURA. Proceedings of the Third Conference on Speech Communication and Technology (1295—1298). Berlin, Germany.
Muthusamy, Y.K., E. Barnard, and R.A. Cole. 1994. Reviewing Automatic Language Identification. IEEE Signal Processing Magazine.
Muthusamy, Y.K., R.A. Cole, B.T. Oshika. 1992. The OGI Multi-Language Telephone Speech Corpus. Proceedings of the International Conference on Spoken Language Processing.
Muthusamy, Y.K., N. Jain, R.A. Cole. 1994. Perceptual Benchmarks For Natural Language Identification. Proceedings IEEE International Conference on Acoustics, Speech and Signal Processing.
Nakagawa, S., T. Seino, Y. Ueda. 1994. Spoken Language Identification by Ergodic HMMs and its State Sequences. Electronic Communications of Japan part 3, 77(6), (70—79).
Niemann, H., E. Noeth, A. Kiessling, R. Kompe and A. Batliner. 1997. Prosodic Processing and its Use in Verbmobil. Proceedings of ICASSP-97 (75—78). Munich, Germany.
Noeth, E., S. Harbeck, H. Niemann, V. Warnke. 1996. Language Identification in the Context of Automatic Speech Understanding. Proceedings of the 3rd Slovenian-German Workshop Speech and Image Understanding (59—68). Ljubljana, Slovenia.
Rayner, M. et al. 1993. A speech to speech translation system built from standard components. Proceedings of the 1993 ARPA Human Language Technology Workshop. Princeton, New Jersey.
Reynolds, D.A. 1995. Speaker identification and verification using Gaussian mixture speaker models. Speech Communications 17 (91—108).
Reynolds, D.A. and R. Rose. 1995. Robust text-independent speaker identification using Gaussian mixture speaker models. IEEE Transactions on Speech Audio Processing 3(1) (72—83).
Roe, D.B., F.C. Pereira, R.W. Sproat, M.D. Riley. 1992. Efficient grammar processing for a spoken language translation system. Proceedings of ICASSP-92, vol. 1 (213—216). San Francisco.
Wahlster, W. 1993. Verbmobil, translation of face-to-face dialogs. Proceedings of the Fourth Machine Translation Summit (127—135). Kobe, Japan.
Waibel, A., A. Jain, A.Mc Nair, H. Saito, A. Hauptmann, J. Tebelskis. 1991. JANUS: a speech-to-speech translation system using connectionist and symbolic processing strategies. Proceedings of ICASSP-91, vol .2 (793—796). Toronto, Canada.
Waibel, A., M. Finke, D. Gates, M. Gavaldà, T. Kemp, A. Lavie, M. Maier, L. Mayfield, A. McNair, I. Rogina, K. Shima, T. Sloboda, M. Woszczyna, T. Zeppenfeld, and P. Zahn. 1996. JANUS-II-Translation of Spontaneous Conversational Speech. Proceedings of ICASSP (.409—412).
Ward, W. and S. Issar. 1995. The CMU ATIS System. Proceedings of the ARPA Workshop on Spoken Language Technology ( 249—251).
Woszczyna, M., N. Aoki-Waibel, F.D. Buo, N. Coccaro, K. Horiguchi, T. Kemp, A. Lavie, A. McNair, T. Polzin, I. Rogina, C.P. Rose, T. Schultz, B. Suhm, M. Tomita, and A. Waibel. 1994. Towards spontaneous speech translation. Proceedings of ICASSP-94, vol. 1 (345—349). Adelaide, South Australia.
Zissman, M.A. 1996. Comparison of Four Approaches to Automatic Language Identification of Telephone Speech. IEEE Transactions on Speech and Audio Processing 4(1).
Zissman, M.A. 1997. Predicting, Diagnosing and Improving Automatic Language Identification Performance . Proceedings of EUROSPEECH, vol. 1 (51—54). Rhodes, Greece.
Websites
Projects
C-STAR: http://www.is.cs.cmu.edu/cstar/
SQEL: http://faui56s1.informatik.unierlangen.de:8080/HTML/English/Research/Projects/SQEL/SQEL.htm
VERBMOBIL: http://www.dfki.de/verbmobil/
[This chapter is available as http://www.cs.cmu.edu/~ref/mlim/chapter8.html .]
[Please send any comments to Robert Frederking (ref+@cs.cmu.edu, Web document maintainer) or Ed Hovy or Nancy Ide.]
Chapter 8
Evaluation and Assessment Techniques
Editor: John White
Contributors:
Lynette Hirschman
Joseph Mariani
Alvin Martin
Patrick Paroubek
Martin Rajman
Beth Sundheim
John White
Abstract
Evaluation, one of the oldest topics in language processing, remains difficult. The fact that funding agencies become increasingly involved in language processing evaluation makes the subject even more controversial. Although it cannot be contested that the competitive evaluations held in Speech Recognition, Information Extraction, Machine Translation, Information Retrieval, and Text Summarization in the US over the past fifteen years has greatly stimulated research toward practical, workable systems, it has also focused research somewhat more narrowly than has been in the case in Europe. As techniques in the different areas grow more similar, and as the various areas start linking together, the need for coordinated and reusable evaluation techniques and measures grows. The multilingual portions of the MUC and TREC evaluation conferences, for example, involve issues that are also relevant to MTEval, and vice versa. There is a need for a more coordinated approach to the evaluation of language technology in all its guises.
8.1 Definition of Evaluation
Evaluation is surely one of the oldest traditions in computational language processing. The very early breakthroughs (and apparent breakthroughs) in language processing, especially machine translation, were announced to the world essentially as proof-of-concept evaluations. The proof-of-concept model in software engineering probably owes much to the importance of showing an embryonic language processing capability in such a way that its implications are readily apparent to lay persons. Later, the details of the evaluation were largely forgotten by the world’s computer users, but their significance was profound. More than any other computer application of the time, the early trials of language processing (machine translation especially) created a demand and an expectation about the capability of computers that persists to this day. It is a truism in the field that many fundamentals of software engineering arose from these early experiences with language processing, including software evaluation principles. Robust, everyday language processing itself, though, still largely lies in the realm of expectation.
Evaluation and assessment are implicit aspects of any human activity. As with any scientific or engineering discipline, evaluation is essential for rational development. For any activity, we must have some way of judging whether we are finished or not, whether the work we did meets its intended purpose, and whether a new object we have made strikes those who experience it as something of value.
In defining the research and development processes, it is essential to characterize the fundamental aspects of human activity assessment. In the language technologies, as in most software development enterprises, evaluation measures the state of a particular model (working or conceptual, a prototype or a product) in terms of the expectations it is committed to meet, the general expectations of models of that type, and the place of that model among other models which are equivalent in some respect.
As with any industry, it became apparent early on that two types of evaluation were required: first, the different approaches to particular language processing techniques had to compared, and second, the single approaches needed to be evaluated against their own objectives. The different stakeholders in language processing need different types of evaluation: what an end-user needs to know is rather different from what an investor needs to know, which is turn different from what a research sponsor needs to know. At the core of each, however, is the awareness that the language processing technique or approach must have some applicability in the world. Each of the various technologies and modalities have, naturally, matured at different rates, and as each matures, the ultimate applicability can be evaluated in ways more focused on that central view.
There are several dimensions and roles for natural language processing, and consequently, more than one evaluation metric to be employed. At least the following types of processing differ enough to warrant different treatment: understanding vs. generation, the different language modalities, the choice of language, and end use. For all these classifications, however, evaluation may be divided into formative (development against objectives) and summative evaluations (comparison of different systems, approaches, integration, etc.)
The end-to-end dimensions of evaluation by be characterized by the evaluative focus (black-box/glass-box/gray-box), by its purpose (comparative/diagnostic, predictive/a posteriori), or by the impact of the technology in applications, up to socio-economic or program evaluation. This whole area has been depicted in terms of an "ethnography of evaluation" (Hirschman, 1998b).
In certain areas, the evaluation programs were already robust, with the MUC (information extraction from text) series already at number 4 (Grishman and Sundheim, 1996), and the ATIS (speech recognition) series in its third year (Hirschman, 1998a). In speech recognition/understanding, the RSG10 series on multilingual recognition systems assessment had already been underway since 1979. The US Defense Advanced Research Projects Agency (DARPA) had been developing and evaluating HARPY, HEARSAY and other systems by the mid-70s, but with a non-comparative, non-satisfactory approach. In Europe, the LE-SQALE project was starting, and the EAGLES study on evaluation of Language Processing systems (King et al., 1996), European Network of Excellence in Language and Speech (ELSNET), and LE-Eurococosda were already underway. At the international level, the Coordinating Committee on Speech Databases and Speech I/O Systems Assesment (Cocosda) was initiated at the Eurospeech-91 conference satellite workshop in Chiavari (Italy). More information appears in
Chapter 5.With respect to the understanding of written language, ‘deep’ understanding approaches (parsing, semantic analysis, etc.) were still the primary focus as recently as five years ago. But new techniques were emerging, which were conceptually simpler, involved less reasoning, and took better advantage of new-generation computer processor speeds. These methods, mostly statistical in nature, were applied to various tasks. Statistical MT was achieving a level of R&D maturity (Brown et al. 92), while simpler, ‘shallow’ parsing models were proving their value in information extraction (
Chapter 3). The information retrieval evaluation conference series in the US called TREC (Voorhees and Harman, 1998) was just underway, an enterprise in which empirical retrieval methods would indicate the potential for non-rule-based approaches to large-corpus language processing (see Chapter 2).Evaluation methods responded to these new trends by beginning the dialectic on diversifying evaluation techniques to measure those attributes and tasks for which a particular approach was presumably best suited. As we explain below, diversification did occur in extraction and in speech recognition. The issue was in fact pre-eminent in the beginnings of a new generation of machine translation evaluation sponsored in the US by DARPA as the MT Evaluation initiative (MTEval; (White and O’Connell, 1994)), but the balance of specialization measures vs. comparison measures was (and is) unresolved.
8.2.1 Capabilities Five Years Ago
At the time, the US government sponsored the Message Understanding Conference (MUC) evaluation series (Grishman and Sundheim, 1996), whose methods still presented a single, undifferentiated, task, although multi-lingual applications and the installation of subtasks was not far away (see also
Chapter 3). The scoring methodology was already well developed and reasonably portable across platforms, allowing it to be run independently by each contractor. TREC, started by the U.S. National Institutes for Standards and technology (NIST), was developing a corpus, in concert with the U.S. Government Tipster program, from which other evaluations drew (for example, MTEval). The Penn Treebank was developing a new variety of corpus-tagged parses of English constituents, which would prove to be of use for the smaller DARPA-initiated Parseval. In Europe, the EAGLES study group on machine translation and speech recognition evaluation was established under EU funding (King et al., 1996).With respect to speech recognition, a set of metrics was well-established, e.g., word insertion/deletion/substitution as a black-box evaluation measure. Rates of understanding errors was a well-used measure in ATIS, but still unsatisfactory (for example, a wrong response was simply considered an error twice more important than no response). This period (1992) saw the participation of non-US laboratories in speech recognition evaluations, and the beginning of large-scale multilingual systems evaluation.
Figure 1. A history of speech recognition benchmarks.
8.2 Major Methods, Techniques, and Approaches Five Years Ago
The pre-eminent evaluation method in the major programs was a corpus-based, automatic scoring approach. When successful, this enabled a comparison among systems, theoretical approaches, and intended functional usage. However, not all language technologies are readily amenable to automatic measurement methods. Machine translation and summarization, to name two, are difficult in this regard, because in each case there is never exactly one "right" answer. Automated text summarization as an evaluable track had not reached maturity at this time, but the issue of the subjectivity of evaluation measures in MT was a known problem. To address this, DARPA developed approaches that took advantage of language intuitions of otherwise disinterested native speakers of the target language, dividing evaluation tasks into small decision points so that, with a sufficient rater sample size, the intuitive judgments could be exploited for generalizations on the fidelity and intelligibility of MT output.
In general, one can divide the evaluation methods of the day into two classes: technology evaluations (MUC, TREC: both off-line and corpus-based), and subject based evaluations (summarization, MTEval: both requiring significant assessor effort). MUC developed automated methods for template alignment and scoring, as well as appropriate evaluation metrics, including an extraction-specific adaptation of the standard IR precision metric. TREC addressed significant issues with ground truth development in a gigantic retrieval corpus. MTEval showed the beginnings of a new evaluation methodology by taking advantage of the very subjectivity that caused it problems in the first place. In speech recognition (ATIS), a corpus-based evaluation of an interactive task, using pre-recorded queries, measured the accuracy of retrievals. Though this method was good for training, it showed little extensibility, and no real-time evaluation capability.
8.3 Major Bottlenecks and Problems Then
Major problems then, and to a large extent today, involved the availability of test corpora. Much use was made of an available Wall Street Journal corpus during the period, as well as the Canadian Parliament Hansard corpus for training. But access to the huge volumes of data required for valid evaluation of the information retrieval task remained a vexing issue. A related issue lay in the incompatibilities of the character sets for non-Roman writing systems (and even European languages, for which wire services at the time routinely omitted diacritics).
Speech evaluation initiatives of the period suffered from a need for infrastructure and standard metrics. In fact, many of the language technologies have not had evaluation paradigms applied to them at all. Many times, such activities have been sporadic in time and place, producing results difficult to compare or derive trends.
8.3 Where We Are Today
In contrast to five years ago, it is probably the case that most language processing technologies today have more than one program for cross-system evaluation. Evaluations of speech processing in Aupelf-Francil (Mariani, 1998), Verbmobil (Wahlster, 1993; Niemann et al., 1997), Cocosda, LE-Sqale, and others demonstrated the growth in interest and capability of evaluation. Several measures have become accepted as standards, such as the MUC interpretations of recall, precision, and over-generation. Other measures still are only used by some communities and not in others, and the usefulness of some measures is still under question.
8.3.1 Capabilities Now
Emerging capabilities have led to evaluation methods and metrics of increased sensitivity. In speech recognition, there are now separate tracks such as the NIST series, which includes HUB 4 (broadcast news), HUB 5 (telephone conversations), speaker recognition, spoken document retrieval, and a new initiative in topic detection and tracking. Each HUB track uses standard scoring packages. Meaningful metrics and scoring algorithms have facilitated the evaluation of the new capabilities.
In the MUC series, text extraction is now divided into multiple tasks, including named entity extraction and co-reference identification.
The first automated text summarization evaluation SUMMAC-98 (Firmin Hand and Sundheim, 1998; Mani et al., 1998) was held in 1998. While two of its three measures (recall and precision) closely paralleled ones used for Information Retrieval, some investigations were made of ways to incorporate measures of text compression (ratio of summary length to full-document length) and measures of specificity/utility of content (informative value of content in addition to indicative value of content).
Most of the more established evaluation series have found that system capabilities begin to asymptote. Speaker Independent Large Vocabulary Continuous Speech recognition rates for read texts dictation, for example, have reached a plateau, and may respond well to a new challenge such as spontaneous speech (see the Switchboard or Call Home results), prosody, dialogue, or noisy environment. MUC information extraction scores seemed to plateau at around 60% recall on the scenario-based extraction (Scenario Template) tasks. It must be noted for both these cases, though, that progress has been made: the evaluation tasks have become much more difficult and varied over the years.
8.3.2 Major Methods, Techniques, and Approaches
It is possible to identify a trend toward standard, human-oriented evaluation methodologies, particularly in the subject-bound evaluation types (Hirschman, 1998b). In MTEval and SUMMAC, subjects are presented with variants of the very familiar reading comprehension test. The difference of course is that what is being evaluated is the thing read, not the reader! However, the form is useful because it requires less familiarization on the part of the subjects, and its parameters are known (e.g., the form and impact of distracters in the multiple-choice format).
One trend over the last three years has been a focus on the user’s business process. The operational requirements of the user’s work are naturally reflected in a process flow, into which new language processing capabilities are inserted. In this context, it is not as useful to evaluate individual systems on performance metrics as it is to measure the improvement they make to the business process as a whole. The US Federal Intelligent Document Understanding Laboratory has developed a set of techniques for making these assessments, both for first-time automation of a particular function to impact of enhancements (White et al., 1999).
8.3.3 Major Current Bottlenecks and Problems
Major problems include the need for rapid evaluations, the size of evaluation efforts, the test data available, and a sentiment in part of the research community that standardized evaluation "may kill innovative ideas".
Technical innovations in the R&D world, as well as rapid release iterations of commercial products, have forced the performance of evaluations as rapidly as possible. This is a problem for evaluations that are strongly subject-based, such as MT, summarization, and dialogue evaluation. Here, implementation of the measurement process involves recruitment of many subjects (raters), large-scale organization of materials, and a very large sample size of decision points to make a valid measurement. The situation is very difficult where assessments is required from users or other experts. Such people can rarely commit the time required for usability testing.
A second pressing problem is the availability of corpora. Although ameliorated in the text-based technologies by the explosion of available text sources on the internet in the last five years, the lack of character-set standards for non-Roman writing systems continues to stymie the development of uniform corpora, and encoding standards such as Unicode have had a slower acceptance rate than was predicted.
A major issue is the expense of assembling subject groups. One potential for breakthroughs is to get thousands of users to participate in an evaluation/experiment. As has been shown by the MIT Galaxy System, people will voluntarily participate if the system they are evaluating provides good enough service (in this case, weather information over the telephone; the evaluation was on Galaxy’s speech recognition).
The cost can also be reduced by following the trend already in place for the subject-based evaluations, namely to use standardized human tests (such as reading comprehension, in MTEval and SUMMAC). The resources saved from developing artificial corpora can then be directed toward building systems. However, there is a difficulty in making the inferential leap from Technology evaluation to User evaluation. In practice, there may be a decrease in measured performance of speech systems when actually fielded, compared with their performance in test-bed evaluation, in one case from 94 to 66% (Haaren et al., 1998). Sufficient Technology-centered performance is not enough: there must be metrics for size of effort, genericity, interest, usability (cf. the Eagles program (King et al., 1996)). However, User-centered evaluation does not tell the whole evaluation story either, if not properly conducted. This is illustrated in the example given by Haaren et al., where two cities that are acoustically similar (Mantes and Nantes) are misrecognized by the railway query dialog system, even while the user continues the dialog (since his goal is not to get a train ticket, but to assess the quality of the dialog system).
At present, no-one would say that the evaluation of any aspect of language processing is a closed issue. For speech recognition, dialogue evaluation remains a difficult and open problem (ATIS, MASK, ARISE, Elsnet Olympics-97). Text summarization has only just completed its very first evaluation. The increasing number of subtask evaluations in TREC and MUC suggest that technological progress can best be measured and achieved by acknowledging the intrinsic complexity of IR and IE as application areas and by breaking out some of the component areas as evaluation focal points. Needed still are methods for evaluating such (notional) components as word sense disambiguation, event argument identification, and textual discourse tracking. Machine Translation evaluation is still searching for a general, easily comprehensible yet comprehensive, methodology, as illustrated by (White and Taylor, 1998; Hovy, 1999).
We must not lose sight of the goals of evaluation: better research and better products. The community needs data to measure progress, and it needs standardization of measures, including of evaluation confidence measures (Chase, 1998).
At this time, evaluation remains difficult not least because of a lack of a clear vision within most of the technologies for the average level of current performance, the commonly recognized best practices, and the most promising new approaches.
8.4 Where We Will Be in 5 Years
The most significant issue facing evaluation over the next five years is the cycle of expectation and demand in software evolution. As capabilities become available to a wider group of people, demand is created for the new capability, and the expectation that many more things will soon be possible becomes palpable. It is difficult for anyone to separate the intractable problems from the routine in software development, except perhaps in one’s own focused area of expertise.
With respect to NL processing, the expectation invariably leads to ingenious solutions to problems, namely, the (loose) integration of language processing functions together in one system. Much of this integration will employ the simplest possible means (e.g., word processing macros) to facilitate the maximally automated passage of data from one language processing system to another. Optical character readers are already integrated with MT systems, as are browsers, detection, and extraction systems. In each case, the goal of the loose integration is saving time and avoiding complexity, which implies trying to eliminate the human from the inter-process loop, usually with disastrous consequences in lost capability. Evaluation must respond to this challenge by facilitating the best possible loose integration in these situations, by assessing the contribution of each processing system to the overall process, but also, by assessing the areas where each system’s output does particular harm to the performance of the downstream system.
At the same time, R&D and software engineering will be in the process of creating deep integration among systems (for example, several of the current experiments in speech translation; see
Chapter 7). In such integration, evaluation will have to change to accommodate the relevant issues that arise.In parallel, the development of semantics as a common foundation of processing requires a push in evaluation of such issues as WordNet (Miller, 1990), lexicon development, knowledge acquisition, and knowledge bases.
8.4.1 Expected Capabilities in Five Years
In five years, there will have been a closer integration of functions in end-to-end language processing systems. Evaluation will have to develop and apply methods which are relevant to the emerging uses of such integration, but which also have two other characteristics: they will have to be sensitive to more open-system implementations (i.e., allow for substitutions of language processing systems within the context of the larger system) while at the same time providing measures that are comparable to the historical measures of recent evaluations. They must also be more heavily user-oriented.
8.4.2 Expected Methods and Techniques
Task-oriented evaluation methodologies will form a significant thrust in evaluation methods in five years. These metrics will assess the usefulness of a system’s output for subsequent tasks. For example, MT systems will be measured by how well their output can be used by certain possible downstream tasks. This, of course, requires that the community develop measures of the tolerance levels of language processing tasks for suitable input quality.
With regard to evaluation processes themselves, we can expect them to become increasingly fast and easy to use. Long before 5 years from now it should be possible to perform a black-box evaluation of particular types of language processing systems in real time over the internet, by accessing scoring algorithms for non-subjective measures and applying them.
In particular, we should hope for evaluation approaches that make use of semi-automatic black-box approaches that are reproducible and confidential. With respect to the integration of different technologies, there should be definable control tasks around which the integrated functions should be organized.
8.4.3 Expected Bottlenecks
User-oriented evaluations will continue to be an issue, for the reasons noted above. However, they will become more commonplace. Some scoring algorithms will be built on captured knowledge gained from valid user samples, reusable automatically. This is, for example, the intended result of the ongoing MT functional proficiency scale measure. In fact, user-based evaluations are already commonplace in some speech recognition development programs, although user acceptance is not the only measure to develop.
The good news for corpus availability is not that everyone will have adopted representation and text encoding standards, but that there will be critical masses of standard forms that production of large corpora will be much simpler process.
8.5 Juxtaposition of this Area with Other Areas and Fields
8.5.1 Related Areas and Fields
As discussed above, the trend toward integration of several language processing functions within a user’s process is ongoing, and will progress toward deeper integration of functions. Evaluation must accommodate the human user component aspect of the introduction of integrated systems, as described in part. At the same time, there should be methods for evaluation of the deeper integration of language processing systems, in which, for example, the different functions share lexical, syntactic, or conceptual knowledge. It is not unreasonable to expect IR, MT, and Summarization systems to share some basic knowledge resources, such as lexicons, as well as some core processing algorithms, such as wordsense disambiguation routines. Along these lines, new tracks in the speech community demonstrate sensitivity to the integration of language processing capabilities. For example, ATIS included not only evaluations based on the speech signal, but also evaluations based on the transcribed speech signal, for laboratories working on NLP, and not on speech. Similarly, evaluation in spoken document retrieval and on topic detection/tracking includes the participation of speech researchers, working directly with the speech signal, as well as NL researchers, either working on the transcription of the speech signal or in cooperation with speech researchers.
Multimodality will increase the complexity of NL processing systems and components, because they will be required at least to be able to collaborate in their task with other communication components, so as to be able to handle several communication channels (e.g., speech and gesture recognition; see
Chapter 9). As the complexity of systems increases the combinatorics of module composition grows and assessing the different combinations becomes more difficult. To harvest the benefits of this combinatoric expansion, evaluation is needed, particularly in cross-domain approaches.8.5.2 Existing Interconnections: Shared Techniques, Resources, Theories
Evaluations are already occurring in ATIS and HUB that deal with multi-function techniques. These in effect merge the measures that exist for each in isolation. On another dimension, individual language processing functions that share certain characteristics may be evaluated alike. This is the case with the conceptually similar approach to evaluating MT and summarization, discussed above. An example of resource sharing is offered by the recent SUMMAC, which re-used parts of the TREC collection (documents, relevance assessments, and even assessment software).
8.5.3 Potential Connections That Have Not Yet Been Made
The emerging multi-modality of information, and thus in the emerging expectations for retrieval and automatic understanding, ultimately will require a multi-directional means of evaluating those techniques that integrate the multi-modality. The MT functional proficiency scale measure mentioned above is a ‘one-way’ connection from MT output to task input downstream. In this case, the other language processing tasks (extraction, detection, gisting, for instance) are all seen as accepting MT output as input. However, the flexible interactions likely to be required in the future will alter the order in which certain processes occur to optimize efficiency and accuracy. There needs to be a manner of evaluating such flexible interactions simply and quickly.
As discussed in
Chapter 9, the increase in multi-modal systems and assumptions will create a combinatory explosion of module interactions; the challenge for evaluation will be to cull the possible combinations into the best.8.5.4 What is Required for Cross-Fertilization
Continuing dialogues on resources and evaluation is an essential means of continuing the cross-fertilization. Of particular usefulness here is the commitment for joint development of generic test-beds for evaluating multi-functional and multi-modal integration. To that end, meetings such as the international LREC conference will continue to be of significant value in fostering cross-fertilization of evaluation processes, methods, and metrics.
8.5.5 What might be the Beneficial Results of Cross-Fertilization
As noted above, most of the language processing technologies that we currently can imagine will be required by the user community to be integrated. The expectation of this and other computer technologies is that the integration should be easy to accomplish (of course, it is not), and so the demand remains high even though promising approaches in the past have often not come to fruition. Given that the successful integration of the various functions is a foregone conclusion, the development of evaluation techniques, both those currently applicable and those that will be sensitive to the deep integration issues of the future, must be pursued jointly by the different language technology communities.
8.6 The Treatment of Multiple Languages in this Area
Multilingual issues are by definition germane to MT, though even here the state-of-practice has been pair-specific (and direction-specific) rather than generally driven by the wider issues of multi-lingual processing. In the other language processing technologies, multilingual issues in evaluation are a natural outgrowth of both the maturation of the technologies and the increasing availability of, and demand for, foreign language materials.
Multilingual issues have been used in evaluation of programs for quite some time. In practice, evaluation techniques have proven to extend quite easily to multiple languages. MUC-5 contained English and Japanese tracks, and MUC 6 and 7 contain a Multilingual entity task called MET (Grishman and Sundheim, 1996). The DARPA Broadcast News evaluation includes Spanish and Mandarin. It is not difficult to see how SUMMAC can be extended to include other languages. In the EU, the NATO RSG10 (1979) speech recognition evaluation employed American English, British English, French, Dutch, and German. Le-Sqale (1993—95) uses American English, British English, French, and German. Call-Home, TDT, Language identification, and Cocosda studies have all focused on multiple language recognition, synthesis and processing.
8.6.1 Need for Multilingual Treatment
Several aspects are apparent in the evaluation of multilingual data. First, given that individual technologies must adapt to handle multilingual issues, glass-box evaluations should have metrics for assessing the extensibility of particular approaches. Second, with respect to the integration issues noted above, evaluation must measure the degradation that ensues upon the introduction of a new language, as either input or output. Third, evaluations should attempt to pinpoint the best areas for ‘deep’ integration that takes into account multilingual, interlingual, or extra-linguistic conceptual models.
It is encouraging that language engineering has become less and less partitioned across nationalities because of the increasing availability of resources, but also because of the increasing movement of professionals and ideas across boundaries.
8.6.2 Bottlenecks: Resources and Techniques
Evaluation methods extend easily to new languages, but corpora do not. Suitable corpora, particularly parallel corpora, are rare. Much progress has been gained from the Hansard parallel corpus and there is promise from the United Nations proceedings. The DARPA MTEval parallel corpora, though small, have already been used to good effect in research of sociolinguistic aspects of the translation problem (Helmreich and Farwell, 1996).
In fact, the limiting factors are resources and multilingual tools for resource development. The expansion of multilingual systems will not be possible without the creation and use of common standards and resources of sufficient quality and quantity across the different languages.
8.7 References
Brown, P., J. Cocke, S. Della Pietra, V. Della Pietra, F. Jelinek, J. Lafferty, R. Mercer, P. Roossin. 1990. A Statistical Approach to Machine Translation. Computational Linguistics 16(2), 79—85.
Chase, L.L. 1998. A Review of the American Switchboard and Callhome Speech Recognition Evaluation Programs. In Proceedings of the First International Conference on Language Resources and Evaluation (LREC), 789—794. Granada, Spain.
Firmin Hand, T. and B. Sundheim. 1998. TIPSTER-SUMMAC Summarization Evaluation. Proceedings of the TIPSTER Text Phase III Workshop. Washington.
Grishman, R. and B. Sundheim (eds). 1996. Message Understanding Conference 6 (MUC-6): A Brief History. Proceedings of the COLING-96 Conference. Copenhagen, Denmark (466—471).
Helmreich, S. and D. Farwell. 1996. Translation Differences and Pragmatics-Based MT. In Proceedings of the Second Conference of the Association for Machine Translation in the Americas (AMTA-96), 43—55. Montreal, Canada.
Van Haaren, L., M. Blasband, M. Gerritsen, M. van Schijndel. 1998. Evaluating Quality of Spoken Dialog Systems: Comparing a Technology-Focused and a User-Focused Approach. In Proceedings of the First International Conference on Language Resources and Evaluation (LREC), 655—662. Granada, Spain.
Hirschman, L. 1998a. (ATIS Series) Evaluating Spoken Language Interaction: Experiences from the DARPA Spoken Language Program 1980—1985. In S. Luperfoy (ed.), Spoken Language Discourse, to appear. Cambridge: MIT Press.
Hirschman, L. 1998b. Language Understanding Evaluations: Lessons Learned from MUC and ATIS. In Proceedings of the First International Conference on Language Resources and Evaluation (LREC), 117—122. Granada, Spain.
Hovy, E.H. 1999. Toward Finely Differentiated Evaluation Metrics for Machine Translation. In EAGLES Handbook, EAGLES Advisory Group. Pisa, Copenhagen, Geneva.
King, M. et al. 1996. EAGLES Evaluation of Natural Language Processing Systems: Final Report. EAGLES Document EAG-EWG-PR.2, Center for Sprogteknologi, Copenhagen.
Mani, I. et al. 1998. The TIPSTER Text Summarization Evaluation: Initial Report.
Mariani, J. 1998. The Aupelf-Uref Evaluation-Based Language Engineering Actions and Related Projects. In Proceedings of the First International Conference on Language Resources and Evaluation (LREC), 123—128. Granada, Spain.
Miller, G.A. 1990. WordNet: An Online Lexical database. International Journal of Lexicography 3(4) (special issue).
Niemann, H., E. Noeth, A. Kiessling, R. Kompe and A. Batliner. 1997. Prosodic Processing and its Use in Verbmobil. Proceedings of ICASSP-97, (75—78). Munich, Germany.
Voorhees, E. and D. Harman. 1998. (TREC series) Overview of the Sixth Text Retrieval Conference (TREC-6). In Proceedings of the Sixth Text Retrieval Conference (TREC-6), in press. See also
http://www.TREC.nist.gov.Wahlster, W. 1993. Verbmobil, translation of face-to-face dialogs. Proceedings of the Fourth Machine Translation Summit (127—135). Kobe, Japan.
White, J.S. and T.A. O’Connell. 1994. (MTEval series) The DARPA MT Evaluation Methodologies: Evolution, Lessons, and Future Approaches. In Proceedings of the First Conference of the Association for Machine Translation in the Americas (AMTA-94). Columbia, Maryland.
White, J.S. and K.B. Taylor. 1998. A Task-Oriented Evaluation Metric for Machine Translation. In Proceedings of the First International Conference on Language Resources and Evaluation (LREC), 21—26. Granada, Spain.
White, J.S., et al. 1999. White, J.S. FIDUL assessment tasks. In prep.
[This chapter is available as http://www.cs.cmu.edu/~ref/mlim/chapter9.html .]
[Please send any comments to Robert Frederking (ref+@cs.cmu.edu, Web document maintainer) or Ed Hovy or Nancy Ide.]
Chapter 9
Multimedia Communication, including Text
Editors: Mark Maybury and Oliviero Stock
Contributors:
George Carayannis
Eduard Hovy
Mark Maybury
Oliviero Stock
Abstract
Multimedia communication is a part of everyday life and its appearance in computer applications is increasing in frequency and diversity. This article defines the area, outlines fundamental research questions, summarizes the history of this technology, identifies current challenges and concludes by predicting future breakthroughs and discussing multilinguality. We conclude describing several new research issues that systems of systems raise.
9.1 Definition of Multimedia Communication
We define communication as the interaction between human-human, human-system, and human-information. This includes interfaces to people, interfaces to applications, and interfaces to information. Following Maybury and Wahlster (1998), we define:
The majority of computational efforts have focused on multimedia human computer interfaces. There exists a large literature and associated techniques to develop learnable, usable, transparent interfaces in general (e.g., Baecker et al., 1995). In particular, we focus here on intelligent and multimedia user interfaces (Maybury, 1993) which, from the user perspective, assist in tasks, are context sensitive, adapt appropriately (when, where, how), and may:
From the developer’s perspective, there is also interest in decreasing the time, expense, and level of expertise necessary to construct successful systems.
Finally, in interactions with information spaces, the area of media content analysis (Maybury, 1997), which includes retrieval of text, audio, imagery and/or combinations thereof, plays an important role.
9.2 Fundamental Questions
The fundamental questions mirror the above definitions:
9.3 Timeline
Computer supported multimedia communication has been studied for the past three decades. We briefly characterize the major problems addressed, developments, and influence on related areas in each decade.
Late 1950s
1960s
1970s
1980s
1990s
9.4 Examples of Multimedia Information Access
Significant progress has been made in multimedia interfaces, integrating language, speech, and gesture. For example, Figure 1 shows the CUBRICON system architecture (Neal, 1990). CUBRICON enables a user to interact using spoken or typed natural language and gesture, displaying results using combinations of language, maps, and graphics. Interaction management is effected via models of the user and the ongoing discourse, which not only influence the generated responses but also manage window layout, based on user focus of attention.

Figure 1. CUBRICON Multimedia Interface Architecture.
As another example, the AlFresco system (Stock et al., 1993; Stock, et al., 1997) provides multimedia information access, integrating language, speech, and image processing, together with more traditional techniques such as hypertext. AlFresco is a system for accessing cultural heritage information that integrates in a coherent exploration dialogue language based acts with implicit and explicit reference to what has been said and shown, and hypermedia navigation.
The generation system, part of the output presentation system, is influenced by a model of the user’s interests, developed in the course of the multimodal interaction. Another aspect developed in this system is a cross-model feedback (Zancanaro et al., 1997). The user is provided fast graphical feedback of the interpretation of discourse references, profitably exploiting the large bandwidth of communication that exists in a multimodal system.
In the related area of media understanding, systems are beginning to emerge that process synchronous speech, text, and images (Maybury, 1997). For example, Figure 2 shows the results of a multimedia news analysis system that exploits redundancy across speech, language (closed caption text) and video to mitigate the weaknesses of individual channel analyzers (e.g., low level image analysis and errorful speech transcription). After digitizing, segmenting (into stories and commercials), extracting named entities (Aberdeen et al., 1995), and summarizing into key frames and key sentences, MITRE’s BNN (Merlino, Morey, and Maybury, 1997) enables a user is able to browse and search broadcast news and/or visualizations thereof. A range of on-line customizable views of news summaries by time, topic, or named entity enable the user to quickly retrieve segments of relevant content.
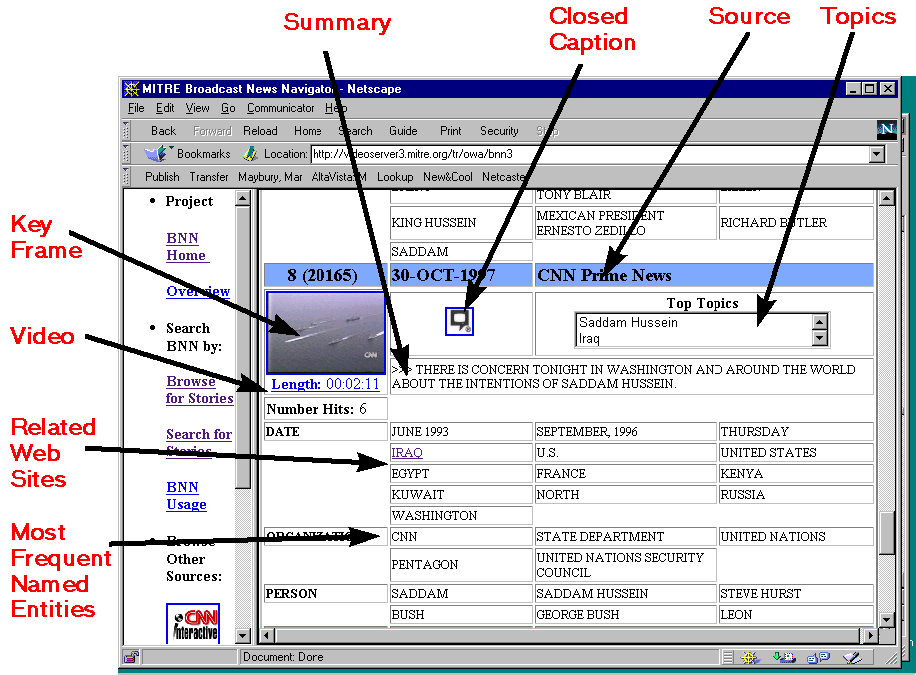
In terms of multilingual information access, one problem is that machine translation systems often provide only gist quality translations. Nonetheless, these can be useful to aid users judge relevance to their tasks. Figure 3 illustrates a page retrieved from the web by searching for German chemical companies using the German words "chemie" and "gmbh". After locating a German-language web site, a web based machine translation engine (Systran) was used to obtain a gist-quality translation of the chemical products (Figure 4). Note how the HTML document structure enhances the intelligibility of the resultant translation.

Figure 3. Original Foreign Language Internet Page.

Figure 4. Translated Language Internet Page.
9.5 Major Current Bottlenecks and Problems
Well before the 1990s, researchers identified the need for medium-independent representations and the ability to convert them automatically to medium-specific representations (Mackinlay, 1986; Roth et al., 1990; Arens and Hovy, 1995). As multimedia interfaces become more sophisticated, this need keeps expanding to include additional phenomena, including ‘lexicons’ of hand gestures, body postures, and facial expressions, and information about the non-lexical text-based and intonation-based pragmatic cues that signal speaker attitude and involvement.
As discussed in
Chapter 1, this area also has a strong need for resources of all kinds to support research on various topics, including multimedia content (e.g., Web, News, VTC), multimedia interaction (need for instrumentation), and multiparty interaction (e.g., CSCW).A third issue arises from the unprecedented increase in the development of media; almost monthly, it sometimes seems, new inventions are announced. This poses a problem for system builders, who are faced with a bewildering array of possible hardware and software combinations to choose from, but who have no way to evaluate and compare them. As a result, he or she may waste a lot of time and may end up with an inferior system, and never even know it. One way to alleviate the problem is to develop a set of standards, or at least a common framework, under which different media (both hardware devices and software applications or interfaces) can be brought together and related, using a common set of terms. In order to determine what the framework should be like, however, it is important first to understand the problems. In this paper we outline three basic problems apparent today and then describe an approach that, we believe, will help in solving them, using a construct that Hovy and Arens (1996) call Virtual Devices. A Virtual Device embodies an abstract specification of all the parameters involved in media drivers, specifically with regard to the characteristics of information they handle and the kid of display or interaction they support. These parameters include hardware and software requirements, media functionality, user task, human ergonomics, humans’ cognitive features, etc. Using some such construct, as long as it adheres to a recognized set of standards, facilitates the organization of current media devices and functionalities, the evolution of the best new ones, and cooperative research on these issues.
Finally, the questions of intellectual property (ownership and distribution of media and knowledge resources) remain a perennial problem.
9.6 Major Breakthroughs in the Near Term
Given advances in corpus based techniques for information retrieval and information extraction (e.g., commercial tools for proper name extraction with 90% performance), coupled with the current transfer of these techniques to multilingual information retrieval and extraction, we can expect their application to multilingual understanding. We also believe there is an equivalent opportunity for multimedia generation for other languages. This presents the following challenges:
Transfer of techniques from related areas will be an important concern. For example, researchers are beginning to take statistical and corpus based techniques formerly applied to single media (e.g., speech, text processing) and apply these to multimedia (e.g., VTC, TV, CSCW).
This work will enable new application areas for relatively unexplored tasks, including:
9.7 Role of Multiple Languages
As indicated above, multimodal interaction resides in the integration of multiple subfields. When extending techniques and methods to multiple languages, we have the benefit of drawing upon previous monolingual techniques. For example, language generation techniques and components (e.g., content selection, media allocation, and presentation design), built initially for monolingual generation, can often be reused across languages. Analogously, interaction management components (e.g., user and discourse models) can be reused.
Of course, many language specific phenomena remain to be addressed. For example, in generation of multilingual and multimedia presentations, lexical length affects the layout of material both in space and in time. For instance, in laying out a multilingual electronic yellow pages, space may be strictly limited given a standard format and so variability in linguistic realization across languages may pose challenges. In a multimedia context, one might need to not only generate language specific expressions, but also culturally appropriate media.

9.7.1 An Example: Computer Assisted Language Learning Products
Foreign Language Learning constitutes an example in the field of Multimedia Communication. In this field it is widely accepted that a communicative approach combining dialogues based on real life situations in the form of video and textual information could prove to be very profitable for foreign language learners. In addition, the modular design of this type of software can enable multilingual support by as many languages as required without further significant effort for localization.
Learning more than one foreign language is a political and cultural choice in Europe, a policy which aims towards preserving the cultural heritage, part of which are European languages.
Thus, in Europe it is important to be able to translate readily, especially from less-spoken to widely spoken languages or vice versa. It is equally important that young people as well as adults learn other foreign languages either for business or for cultural purposes.
The current situation with respect to the level of capabilities of the Computer Assisted Foreign Language learning products can be summarized as follows:
The above-mentioned disadvantages can now be faced on the basis of current language technologies available, which are in a position to provide attractive solutions to facilitate language acquisition on the one hand and motivate people to learn foreign languages on the other.
Future products could integrate resources offering the student the possibility to have access not only to some specific language phenomenon related a particular situation in a static way, but go a step beyond and handle dynamically all language resources.
To make things more explicit, we provide a possible scenario.
Supposing that Greek is the foreign language and that the learner’s mother tongue is French. The learner could be able at any time to open her/his French to Greek dictionary with a click on a French word, see the Greek equivalent in written form, see how this word is pronounced by means of the International Phonetic Alphabet, and hear the Greek word using a high quality text-to-speech synthesis system. Furthermore, the learner could see how a word is used in context, by having access to that part of the video where the word is actually being used. Otherwise, the learner can have access to the examples included in the dictionary and can also hear them via synthetic speech. All the above functions could apply to a Greek-French dictionary, as well. Both dictionaries are considered useful, as they respond to different needs.
Numerous other language-based tools are useful for foreign-language instruction, including:
To sum up, multimedia communication in foreign language learning situations requires the integration of many language processing tools in order to facilitate the learner to correctly learn a new language. It is a new and attractive technology that should be developed very soon.
9.8 Systems Research
Multimedia communication systems, which incorporate multiple subsystems for analysis, generation and interaction management, raise new research questions beyond the well known challenges which occur in component technologies (e.g., learnability, portability, scalability, performance, speed within a language processing system). These include inter-system error propagation, inter-system control and invocation order, and human system interaction.
9.8.1 Evaluation and Error Propagation
As systems increasingly integrate multiple interactive components, there is an opportunity to integrate and/or apply software in parallel or in sequence. The order of application of software modules is a new and nontrivial research issue. For example, in an application where the user may retrieve, extract, translate, or summarize information, one may influence the utility of the output just by sequencing systems according to their inherent performance properties (e.g., accuracy or speed). For example, one might use language processing to enhance post-retrieval analysis (extract common terms across documents, re-rank documents provide translated summaries) to focus on relevant documents. These documents might then cue the user with effective keywords to search for foreign language sources, whose relevance is assessed using a fast but low quality web-based translation engine. In contrast to this order, placing the translation step initially would have been costly, slow, and ineffective. An analogous situation arises in the search of multimedia repositories. Old and new evaluation measures, metrics, and methods will be required in this multifaceted environment.
9.8.2 Multilingual and Multimodal Sources
New research opportunities are raised by processing multilingual and multimodal sources, including the challenge of summarizing across these. For example, what is the optimal presentation of content and in which media or mix of media? See (Merlino and Maybury, 1999). Or consider that in broadcast news spoken language transcription, the best word error rates are currently around 10% for anchor speech. What is the cascaded effect of subsequently extracting entities, summarizing, or translating the text? This also extends to the nature of the interface with the user. For example, applying a low quality speech-to-text transcriber followed by a high quality summarizer may actually result in poorer task performance than providing the user with rapid auditory preview and skimming of the multimedia source.
9.8.3 User Involvement in Process
How should users interact with these language-enabled machines? Users of AltaVista are now shown foreign web sites matching their queries, with offers to translate them. When invoking the translator, however, the user must pick the source and target language, but what if the character sets and language are unrecognizable by the user? What kind of assistance should the user provide the machine, and vice versa? Should this extend to providing feedback to enable machine learning? Would this scale up to a broad set of web users? An in terms of multimedia interaction, who do we develop models of interaction that adequately address issues such as uni- and multi-modal (co)reference, ambiguity, and incompleteness?
9.8.4 Resource Inconsistencies
Finally, with the emergence of multiple language tools, users will be faced with systems that use different language resources and models. This can readily result in incoherence across language applications, an obvious case being when the language analysis module interprets a user query containing a given word, but the language generation module employs a different word in the output (because the original is not in its vocabulary). This may result in undesired implicatures by the user. For example, if a user queries a multilingual database for documents on "chemical manufacturers", and this is translated into a query for "chemical companies", many documents on marketing and distribution companies would also be included. If these were then translated and summarized, a user might erroneously infer that most chemical enterprises were not manufacturers. This situation can worsen when the system’s user and discourse models are inconsistent across problem domains.
9.9 Conclusion
We have outlined the history, developments and future of systems and research in multimedia communication. If successfully developed and employed, these systems promise:
Because of the multidimensional nature of multimedia communication, interdisciplinary teams will be necessary and new areas of science may need to be invented (e.g., moving beyond psycholinguistic research to "psychomedia" research). New, careful theoretical and empirical investigations as well as standards to ensure cross system synergy will be required to ensure the resultant systems will enhance and not detract from the cognitive ability of end users.
9.10 References
Aberdeen, J., Burger, J., Day, D., Hirschman, L., Robinson, P., and Vilain, M. 1995. Description of the Alembic System Used for MUC-6. In Proceedings of the Sixth Message Understanding Conference (MUC-VI). Advanced Research Projects Agency Information Technology Office, Columbia, MD, November 1995.
Arens, Y., L. Miller, S.C. Shapiro, and N.K. Sondheimer. 1988. Automatic Construction of User-Interface Displays. In Proceedings of the 7th AAAI Conference, St. Paul, MN, 808—813. Also available as USC/Information Sciences Institute Research Report RR-88—218.
Arens, Y. and E.H. Hovy. 1995. The Design of a Model-Based Multimedia Interaction Manager. AI Review 9(3) Special Issue on Natural Language and Vision.
Baecker, R., J. Grudin, W. Buxton, and S. Greenberg. 1995. Readings in Human-Computer Interaction: Toward the Year 2000 (2nd ed). San Francisco: Morgan Kaufmann.
Bolt, R.A. 1980. "Put-That-There": Voice and Gesture at the Graphics Interface. In Proceedings of the ACM Conference on Computer Graphics, New York, 262—270.
Brooks, F.P., M. Ouh-young, J.J. Batter, and P.J. Kilpatrick. 1990. Project GROPE--Haptic Displays for Scientific Visualization. Computer Graphics 24(4), 235—270.
Bruffaerts, A., J. Donald, J. Grimson, D. Gritsis, K. Hansen, A. Martinez, H. Williams, and M. Wilson. 1996. Heterogeneous Database Access and Multimedia Information Presentation: The Final Report of the MIPS Project. Council for the Central Laboratory of the Research Councils Technical Report RAL-TR-96-016.
Elhadad, M. 1992. Using Argumentation to Control Lexical Choice: A Functional Unification-Based Approach. Ph.D. dissertation, Columbia University.
Faconti, G.P. and D.J. Duke. 1996. Device Models. In Proceedings of DSV-IS’96.
Feiner, S. and K.R. McKeown. 1990. Coordinating Text and Graphics in Explanation Generation. In Proceedings of the 8th AAAI Conference, 442—449.
Hendricks, G. et al. 1970. NL Menus.
Hovy, E.H. 1988. Planning Coherent Multisentential Text. In Proceedings of the 26th Annual Meeting of the Association for Computational Linguistics, Buffalo, NY.
Hovy, E.H. and Y. Arens. 1996. Virtual Devices: An Approach to Standardizing Multimedia System Components . Proceedings of the Workshop on Multimedia Issues, Conference of the European Association of Artificial intelligence (ECAI). Budapest, Hungary.
Mackinlay, J. 1986. Automatic Design of Graphical Presentations. Ph.D. dissertation, Stanford University.
Mann, W.C. and C.M.I.M. Matthiessen. 1985. Nigel: A Systemic Grammar for Text Generation. In Systemic Perspectives on Discourse: Selected Papers from the 9th International Systemics Workshop, R. Benson and J. Greaves (eds), Ablex: London, England. Also available as USC/ISI Research Report RR-83-105.
Maybury, M.T. editor. 1993. Intelligent Multimedia Interfaces. AAAI/MIT Press. ISBN 0-262-63150-4. http://www.aaai.org:80/Press/Books/Maybury1/maybury.html.
Maybury, M.T. editor. 1997. Intelligent Multimedia Information Retrieval. AAAI/MIT Press. http://www.aaai.org:80/Press/Books/Maybury2.
Maybury, M.T. and W. Wahlster. editors. 1998. Readings in Intelligent User Interfaces. San Francisco: Morgan Kaufmann. ISBN 1-55860-444-8.
McKeown, K.R. 1985. Text generation: Using Discourse Strategies and Focus Constraints to Generate Natural Language Text. Cambridge: Cambridge University Press.
Merlino, A., D. Morey, and M.T. Maybury. 1997. Broadcast News Navigation using Story Segments. In Proceedings of the ACM International Multimedia Conference, 381—391. Seattle, WA, November 1997.
Merlino, A. and M.T. Maybury. 1999. An Empirical Study of the Optimal Presentation of Multimedia Summaries of Broadcast News. In I. Mani and M.T. Maybury (eds) Automated Text Summarization.
Meteer, M.W., D.D. McDonald, S. Anderson, D. Forster, L. Gay, A. Huettner, and P. Sibun. 1987. MUMBLE-86: Design and Implementation. COINS Technical Report 87-87, University of Massachusetts (Amherst).
Moore, J.D. 1989. A Reactive Approach to Explanation in Expert and Advice-Giving Systems. Ph.D. dissertation, University of California at Los Angeles.
Neal, J.G. 1990. Intelligent Multi-Media Integrated Interface Project. SUNY Buffalo. RADC Technical Report TR-90-128.
Rich, E. 1979. User Modeling via Stereotypes. Cognitive Science 3 (329—354).
Roth, S.F. and J. Mattis. 1990. Data Characterization for Intelligent Graphics Presentation. In Proceedings of the CHI’90 Conference, 193—200.
Roth, S.F., J.A. Mattis, and X.A. Mesnard. 1990. Graphics and Natural Language as Components of Automatic Explanation. In J. Sullivan and S. Tyler (eds), Architectures for Intelligent Interfaces: Elements and Prototypes. Reading: Addison-Wesley.
Stock, O. and the NLP Group. 1993. AlFresco: Enjoying the Combination of NLP and Hypermedia for Information Exploration. In M. Maybury (ed.), Intelligent Multimedia Interfaces. Menlo Park: AAAI Press.
Stock, O., C. Strappavera, and M. Zancanaro. 1997. Explorations in an Environment for Natural Language Multimodal Information Access. In M. Maybury (ed), Intelligent Multimodal Information Retrieval. Menlo Park: AAAI Press.
Wahlster, W., E. André, S. Bandyopadhyay, W. Graf, T. Rist. 1992. WIP: The Coordinated Generation of Multimodal Presentations from a Common Representation. In A. Ortony, J. Slack, and O. Stock (eds), Computational Theories of Communication and their Applications. Berlin: Springer Verlag.
Zancanaro, M., O. Stock, and C. Strappavera. 1997. Multimodal Interaction for Information Access: Exploiting Cohesion. Computational Intelligence 13(4).
[This chapter is available as http://www.cs.cmu.edu/~ref/mlim/chapter10.html .]
[Please send any comments to Robert Frederking (ref+@cs.cmu.edu, Web document maintainer) or Ed Hovy or Nancy Ide.]
Chapter 10
Government: Policies and Funding
Editors: Antonio Zampolli and Eduard Hovy
Contributors:
Nino Varile
Gary Strong
Charles Wayne
Lynn Carlson
Khalid Choukri
Joseph Mariani
Nicoletta Calzolari
Antonio Zampolli
Abstract
Language Technology has made great strides since its inception fifty years ago. Still, however, few people can participate in the growing global human-centered Information Society, partly because of impediments imposed by language barriers. One of the principal tasks of Language Technology is to overcome these barriers. It can best do so through international and, increasingly, intercontinental collaboration of research and development efforts. This chapter outlines the areas of Language Technology in urgent need of collaboration and highlights some of the potential benefits of wise funding policy in this regard.
10.1 General Context: Transatlantic Cooperation
Multilingual Language Processing has two obvious aspects. A citizen must be able to access the services of the Information Society in his/her own language, and he or she must be able to communicate and use information and services across language barriers.
The various fields of Language Processing have coexisted in the continents of Asia, Europe, and North America since the early 1960s. Despite several international organizations, including SIGIR for Information Retrieval, IAMT for Machine Translation, ACL for general Computational Linguistics, ICASSP for speech processing, and a host of smaller associations, relatively little formal cross-continent research and development has taken place. But as the fields mature, and as technology is increasingly commercialized, international cooperation for research is increasingly important. Cooperation enhances advance the state of the art by combining most effectively the strengths and the excellence developed in different regions. Cooperation also facilitates integration of language technology across languages, which is surely on of the key aspects that makes this field relevant to society at large.
In light of such arguments, the US government and the European Commission have recently signed an agreement for scientific and technological cooperation with regard to Language Technology.
This chapter addresses the issues that influence thinking by the Funding Agencies in the two continents. It draws upon the findings of the preceding chapters of this report, each chapter dedicated to a major sector of Language Technology. The goal of this chapter is to discuss and identify issues for which transatlantic cooperation is primarily needed and promises to be particularly fruitful. We indicate activities and concrete suggestions for which cooperation is likely to be effective, providing material for anyone interested in defining policy regarding intercontinental (and even local) R&D directions for Language Technology.
The interests of national and international Funding Agencies in the social, economic, industrial, and strategic potential impact of human language technology has decisively contributed to the evolution of our field. This interest is bound to grow in the current context of the global multilingual society, in which information and communication technologies are increasingly interpenetrated. Language Technology involves not only R&D issues, but also cultural and political aspects: languages and cultures are deeply interconnected, and the availability of adequate Language Technology products and services are an essential component of the networked Information Society.
A recent survey shows that R&D support of Language Technology is extremely uneven across various countries. Thus the strategy that national and international Funding Agencies adopt with regard to Language Technology will play a key role in shaping the future of the global human-centered Information Society. Language Technology is the key that can open the door to a true multilingual society.
10.2 Potential Areas of Cooperation
In this section we discuss five core areas in which intercontinental cooperation can have the most beneficial effect.
10.2.1 Standards (de facto, best practice)
Standards for language resources are seen as essential by all the panelists and discussants at the workshops that gave rise to this report. Standards for applications serve multiple purposes: they help eliminate redundancy of effort, ensure multilingual interoperability, consolidate current technical achievements and practices, allow convergence and coordination of distributed efforts, promote the development of a common software infrastructure, enable the integration of components and tools in workflow, and promote the adoption of best practices.
This holds especially for the development of multilingual applications, since each new language that is addressed can be most quickly developed to an acceptable level and incorporated if it can employ existing technology.
Various unified standardization efforts have been supported in the past, but in a somewhat piecemeal fashion. The Text Encoding Initiative (Sperberg-McQueen and Burnard, 1994) provides guidelines for electronic text encoding. Recommendations of the EU-sponsored EAGLES study for corpus encoding, lexicon representation, spoken language, and the evaluation of machine translation and speech recognition (see the three EAGLES websites
http://www.ilc.pi.cnr.it/EAGLES/home.html; http://coral.lili.uni-bielefeld.de/EAGLES; http://www.cst.ku.dk/projects/eagles2.html; King et al., 1996) have already been adopted in several countries. In the US, the TREC series of information retrieval contests (Voorhees and Harman, 1998; see Chapter 2) and MUC information extraction contests (Grishman and Sundheim, 1996; see Chapter 3) have helped put in place standards and methods of evaluation.To capitalize on the existing momentum, it has been proposed that researchers in the U.S. join EAGLES as soon as possible. Future cooperation of European and American participants should be initiated in all the fields currently covered by EAGLES Working Groups.
10.2.2 Language Resources and Related Tools
As discussed in
Chapter 1 and referred to in almost every other chapter of this report, it is clear that language resources–monolingual and multilingual, and multifunctional (shared by different language technologies)–are a central issue for efficient future development. Resources include text and speech collections, lexicons, and grammars, as well as related research and development of methods and tools for acquisition, annotation, maintenance, development, customization, etc.Language resources are an essential component of any Language Technology activity: research, system development, and training and evaluation, in both mono- and multilingual context. The integration of different technologies and languages, a major focus of this report, requires as a key enabling condition that language resources are shared among the different sectors and applications:
The need to ensure reusability, integration, global planning and coordinated international cooperation in the field of Language Resources has been stressed. This can only be achieved if there are projects explicitly dedicated to their development and maintenance. Although language resources must be tested against concrete applications, they should be developed to be multifunctional, i.e., to serve different multiple applications, and must thus be built outside of specific applications.
The cycle of language resource production includes the following phases: research, specification, manual creation and/or automatic acquisition, timing, validation, exploitation, maintenance, and subsequent identification of the next generation of language resources in correlation with user needs. It is important to plan the research and production process, technically and financially, in particular for multilingual language resources, and to create a suitable infrastructure. The production of real language resources demands time; for example, a speech database may be collected in one year or six months, a time-scale impossible for a large computational lexicon or a multimodal/multimedia database.
The value of language resources suggests that this aspect be allocated a research and development area to itself, with the production of language resources fully financed. As illustrated in the US with the Linguistic Data Consortium (LDC), distribution should be supported until self-sufficient. A distributed networked infrastructure should be established, and cooperation of ELRA and LDC should be promoted.
The richness of the multilingual capabilities associated to a language depends on the number of languages for which language resources exist. It is in the common interest that language resources are developed for as many languages as possible. A balance between the market forces and the political and social issues should be found. International cooperation in the construction of language resources is the key that can open the door to a true multilingual society.
10.2.3 Core Technologies
Given the complexity of language and real-world Language Technology applications, no application consists of a single module running independently. Many basic techniques and even functionality components are used in a variety of applications. By core technology we mean the general technology that serves as a basis for many innovative applications, in both the spoken and written areas, and includes both methods and techniques (such as vector space distance metrics, HMM technology) as well as processes (such as parsing, document indexing, etc.). It is worth noting that several basic natural language and speech processing tasks coincide with language resources tools requirements, including word sense disambiguation; dynamic acquisition of linguistic knowledge from textual data; shallow parsing; transfer of technology among applications, domains and languages; and customization.
While innovative research must continue to be fostered somewhat independently of applications, the more mature, well-delimited, and robust functionalities and techniques can be selected for general re-use. When new technologies are proven, they are still often fragmented and need advancement and integration. Often, they can be enhanced not only by good software engineering practice but also by including methods for acquiring linguistic/lexical information from corpora dynamically, at run-time.
The Language Technology community should foster the development of plug and play modules that can be easily integrated into larger systems and thereby support rapid prototyping and software application development. The recent appearance of such low-level text processing tools as part of speech taggers and proper name recognizers has had a beneficial effect on many research projects. This effect can be magnified by the development of more such tools, as well as one or more architectures or platforms upon which innovative applications/systems can be built. Existing examples of such platforms, such as GATE (Cunningham et al., 1996) and ALEMBIC (Aberdeen et al., 1996), illustrate how integrated platforms can support further research on specific targeted problems. Effort should be devoted to the creation of widely multilingual platforms.
10.2.4 Evaluation
As discussed in
Chapter 8, evaluation has on several occasions provided huge benefits for Language Technology, to researchers, commercial developers, and Funding Agencies.Much has been written about evaluation; we do not repeat the arguments here, beyond to note that it is often only through such evaluations as TREC and MUC that research areas find a common focus and make easily quantifiable progress. In this light, evaluation should cover functionality, methods, components, and application systems, and the perspectives of both the developers and the users should be considered.
The EAGLES Evaluation Working Group offers a good basis for cooperation that supports complementarity between the American (competitive evaluation) and the European experiences (standards, general methodology developed in various projects, and the user and usability perspectives). An intercontinental cooperation on a common evaluation effort should:
10.2.5 Vertical Sectoral Application Domains
The development of innovative precompetitive systems has functioned and should continue to function as a testbed for the different language resources, technologies, components, and evaluation methodologies. The appropriate balance should be found, in selecting areas, between the interests of the citizen, the integration of different sectors, the cultural and social impact, the needs of the administrations, the commercial potential, the strategic value, the industrial requirements, and the stimulus of long-term challenges.
The following types of application development have been mentioned:
The international cooperation framework gives priority to multilingual/translingual applications.
10.3 Proposals for Cooperative Projects
Standards
American researchers can immediately join EAGLES and help to plan future EAGLES-like follow-up and development efforts.
Language Resources
Corpora, lexicons, tools development and related research issues: cooperation in lexical projects (FrameNet with PAROLE/SIMPLE; WordNet with EuroWordNet; BNC-ANC-PAROLE; Multilingual parallel corpora; multilingual lexical layer design and development and related research; cross-membership and networking of data production, validation, distribution centers (e.g., PAROLE-ELRA-LDC); development of common language resources related tools; identification of priority topics; research on innovative/new types of language resources (semantic; dialogue; multimodal, etc.).
Core Technologies
Architecture for research and development; automatic learning methods (SPARKLE and ECRAN); integration of symbolic and statistical methods; word sense disambiguation; robust analyzers (shallow parsers, e.g., SPARKLE); customization of language resources; transfer of language resources and technologies to different domains, languages, applications. The core technology could be accompanied by related evaluation (e.g., as in SENSEVAL and Romanseval for word sense disambiguation).
Evaluation
Exchange of best practices in areas such as:
Practical examples include topic spotting for broadcast news and multilingual TREC with European participation.
Applications
See above.
10.4 Conclusion
Language Technology has made great strides since its inception fifty years ago. Still, however, few people can participate in the growing global human-centered Information Society, partly because of impediments imposed by language barriers. One of the principal tasks of Language Technology is to overcome these barriers. To do so, this chapter highlights the need to promote the convergence and integration of different technologies and know-how, for example by designing an integrating multilingual information access service that includes voice, written, image modalities, machine translation, information retrieval, information extraction, summarization, and browsing and display functionalities.
The wise funding of intercontinental collaboration of research and development, specifically in the areas of outlined in this chapter, will allow society to reap the benefits inherent in multilingual Language Technology.
10.5 References
Aberdeen, J., J. Burger, D. Day, L. Hirschman, D. Palmer, P. Robinson, and M. Vilain. 1996. Description of the ALEMBIC System as used in MET. Proceedings of the TIPSTER Workshop, Vienna, Virginia (461—462).
Cunningham, H, K. Humphreys, R. Gaizauskas, and Y. Wilks. 1996. TIPSTER-Compatible Projects at Sheffield. Proceedings of the TIPSTER Workshop, Vienna, Virginia (121—125).
Grishman, R. and B. Sundheim (eds). 1996. Message Understanding Conference 6 (MUC-6): A Brief History. Proceedings of the COLING-96 Conference. Copenhagen, Denmark (466—471).
King, M. et al. 1996. EAGLES Evaluation of Natural Language Processing Systems: Final Report. EAGLES Document EAG-EWG-PR.2, Center for Sprogteknologi, Copenhagen.
Sperberg-McQueen, C.M. and L. Burnard (eds). 1994. Guidelines for Electronic Text Encoding and Interchange. Text Encoding Initiative. Chicago and Oxford.
Voorhees, E. and D. Harman. 1998. (TREC series) Overview of the Sixth Text Retrieval Conference (TREC-6). In Proceedings of the Sixth Text Retrieval Conference (TREC-6), in press. See also
http://www.TREC.nist.gov.