Lightweight Structured Text Processing
PhD Thesis Proposal
Robert C. Miller
rcm@cs.cmu.edu
School of Computer Science
Carnegie Mellon University
April 30, 1999
Abstract
Web pages, source code, and other text documents contain structured data
worthy of automatic processing -- searching, sorting, reformatting, calculating,
and so on. Unfortunately, generic text-processing tools limit their input
and output to generic formats that may not match the format the user wants
to process. The usual solution to this problem is a custom program that parses
the source text and processes it, but custom parsers are hard to build
and often discard useful information from the source document. I propose
a new approach, lightweight structured text processing, in which users
describe relevant document structure interactively and manipulate documents
directly with generic tools. This approach will be embodied in LAPIS, a system
for displaying and processing web pages, source code, and text files. LAPIS
makes several contributions: (1) text constraints, a new pattern language
for identifying regions of text in a simple, readable, composable, expressive,
and robust manner; (2) algorithms and representations for implementing text
constraints with reasonable efficiency; (3) an architecture for composing
and reusing structure detectors, such as external C++ or HTML parsers; (4)
a user interface that integrates pattern matching, manual selection, learning
from examples, and external parsers, allowing the user to combine these
techniques for convenient structure description; (5) the ability to refer
to "presentation-level" structure that may not be directly reflected in the
linear text, such as page layout, typesetting, and table rows and columns;
and (6) the ability to handle variations and exceptions in document structure
by specifying fuzzy patterns. My thesis is that lightweight structured text
processing lets users describe and manipulate many kinds of text structure,
from implicit to explicit, formal to informal, and presentation-level to
logical-level, allowing the user to manipulate the text in its original format,
and delivering the convenience, speed, and scalability of automation without
the cost or difficulty of writing a custom program.
Thesis Committee
Brad Myers, CMU (co-chair)
David Garlan, CMU (co-chair)
Jim Morris, CMU
Brian Kernighan, Bell Labs
1 Introduction
Text documents written for human readers are full of structure, designed
to help readers understand and use the information contained within. For
example, consider a list of user interface toolkits found on the Web [Myers97].
This page describes over a hundred UI toolkits with entries like those shown
in Figure 1.1.
InterViews,
Stanford University,
interviews-bugs@interviews.stanford.edu,
ftp:interviews.stanford.edu,
FREE,
C++/X/Unix, Toolkit/Structured Graphics
Tk/Tcl, J. Ousterhout,
UC Berkeley, Computer Science Division, Berkeley, CA, 94720,,
FREE,
X/11; research system, contains an IB, toolkit
Visual C++, Microsoft,
10700 Northup Way,
Bellevue, Washington 98004,
(800) 426-9400,
MS-Windows only, IB + programming environment |
|
Figure 1.1.
Excerpt from a web page describing user interface
toolkits.
|
To find free toolkits that support X Windows and Microsoft Windows, a human
reader must understand the structure of this document: which parts
represent toolkits, and how the features "free," "supports X," and "supports
Microsoft Windows" are encoded in a toolkit record. An automated search tool
needs essentially the same knowledge to perform the task automatically.
Knowledge of document structure enables not only searching, but also filtering,
sorting, computing statistics, reformatting, and a variety of other automatic
processing. Applying these operations to text documents is impossible without
a custom structure detector, also called a parser. Custom parsers
are hard enough to build that few users would consider building a parser
for a single web page, despite all the benefits that automation could provide.
Automated text processing is becoming increasingly important, especially
for office workers. In 1993, half of all U.S. office workers used a computer
[CB93], and the number is expected to rise to 80% by the year 2000 [Bill95].
As more and more workers go online, and more and more information becomes
available online through the World Wide Web and other sources, office workers
will need automatic tools to organize, process, and interact with online
information. Since information sources vary widely, and every worker's needs
are different, these tools must be easy for end-users to customize.
This thesis introduces a new approach to text processing, called lightweight
structured text processing, which seeks to automate processing of structured
data in documents. In the lightweight structured text processing model, the
user creates a structure detector for a document in a "lightweight" manner
(defined below), then manipulates the document structure with generic tools.
For the UI toolkits task, for instance, the user might describe the relevant
structure of a toolkit entry by specifying the boundaries of a toolkit record
and the locations of the price and supported-platforms fields within a record.
Using these descriptions, the user can invoke a generic Find tool to search
for toolkits with certain features, or a Sort tool to reorder the toolkits,
or a Reformat tool to display them differently.
Lightweight structured text processing is an extension of the "software tools"
approach [KP81] popularized by Unix, in which text is processed by constructing
pipelines of generic programs like grep and sort. Unix tools
expect input in a simple machine-readable format (an array of lines), however,
making it difficult to apply them to documents with rich custom structure,
like web pages, source code, and plain text data files. Even when a
document can be converted to the form required by a tool, the conversion
process may throw away important information, like typesetting, page layout,
or context. By separating structure description from generic tools,
lightweight structured text processing solves many text-processing tasks
without the need for conversion.
Separating structure description from generic tools is one of the two key
features of lightweight structured text processing. The other key feature
is the term "lightweight," referring to structure description that are
incremental and easy to use. Structure description is hard in most
text-processing systems. Since it usually involves grammars or regular
expressions, structure description is regarded as a job for programmers,
not end-users [NMW98]. Structure description is also assumed to be needed
rarely -- for instance, when a new programming language appears. In these
systems, more emphasis is given to expressive power and performance than
ease of use. By contrast, in lightweight structured text processing, structure
description is done by end-users, frequently -- even for one-shot
tasks like finding a UI toolkit. We need lightweight structure description
techniques that make common tasks easy, while complex tasks are still possible.
I have identified the following five areas as key components of lightweight
structure description: (1) pattern language usability; (2) composability
and reuse; (3) integration of selection, pattern-matching, learning from
examples, and parsing; (4) use of "presentation-level" structure; and (5)
robustness to variations and exceptions. These five areas are defined in
more detail below. Existing text-processing systems are deficient in some
or all of the areas.
1. Pattern language usability. Traditional text pattern languages
(context-free grammars and regular expressions) have demonstrated that describing
structure declaratively, using patterns, is a powerful and expressive technique.
Unfortunately, grammars and regular expressions are hard to learn, hard to
read, and often hard to apply in practice. Regular expressions use a cryptic
syntax with single-character operators (like *, +, [...]). To use an operator
character literally, it must be quoted (usually with \), which is
a source of error and makes expressions hard to read. Context-free grammars
have similar syntactic problems. Both regular expressions and grammars require
the user to remember many idioms for common structures, such as
"[^"]*" for a quoted string, or X(,X)* for a comma-separated list.
These characteristics have prevented regular expressions and context-free
grammars from gaining wide acceptance outside the programming community.
2. Composability and reuse. It should be possible to combine and reuse
structure detectors, to minimize the amount of information that the user
needs to provide for a new structure detector. Actual documents frequently
use a variety of conventional formats. The UI toolkits page contains not
only HTML markup, but also URLs, email addresses, mailing addresses, and
phone numbers, all in conventional syntax that could be obtained from a library.
Unfortunately, many text-processing systems require the user to start from
scratch for every task. Furthermore, many systems use an abstract syntax
tree representation of the document that prevents combining structure
detectors, since only one tree can be created and processed at a time.
3. Integration of pattern-matching, selection, learning from examples,
and parsing. A lightweight system should provide many ways to specify
structure: not just patterns, but also manual selection, inference from examples,
parsing by external programs, or any combination of these. With a
battery of structure description techniques at their disposal, users can
choose the most convenient combination for the task at hand. Unfortunately,
most text-processing systems provide only one way to select the text to be
processed: word processors (like Microsoft Word [Mic97]) use manual selection,
programming-by-demonstration systems (like TELS [WM93], Cima [Mau94], EBE
[Nix85], and Tourmaline [Myers93]) use inference, text-processing languages
(like Perl [WS91], Awk [AKW88], SNOBOL [GPP71], and Icon [GG83]) use patterns,
and syntax-directed editors (like Gandalf [HN86], the Cornell Program Synthesizer
[TTH81], and Grif [QV86]) use external parsers. This lack of integration
is unfortunate because combining structure description techniques can be
powerful. For example, if a simple pattern matches 99% of the toolkits on
the UI toolkits page, it may be reasonable to correct the handful of mistakes
by manual selection, rather than complicate the pattern with special cases.
To give another example, in large data sets where pattern-matching errors
are hard to find, inference may help by finding possible errors: regions
which match the pattern but differ in some respect from most other matches,
or conversely, regions which don't match the pattern but which are more similar
to matches than to mismatches. No system known to the author has explored
the synergies between direct manipulation, machine learning, pattern languages,
and programming in a single user interface.
4. Presentation structure. One kind of text structure is logical
structure, based on interpreting the text as a linear sequence of symbols.
Examples include document structure (with concepts like chapters, sections,
paragraphs, sentences, and words), sentence structure (nouns, verbs,
prepositions), and programming language syntax (statements, expressions,
declarations). Another general category of text structure is presentation
structure, based on representing the text as a two-dimensional, typeset
document. Examples of presentation structure include page layout (pages,
columns, boxes, lines, margins, indents), typesetting (typeface, type size,
color), and tables (rows, columns, headers, cells, etc.). From a user's point
of view, the structure of a document is often a mix of logical and
presentation structure, because authors and readers regard the document from
both perspectives. On the UI toolkits page, each toolkit record is basically
a sequence of comma-separated fields (a logical description), but
the toolkit name appears in boldface, and the supported platforms generally
appear at the beginning of the last line of a record (presentation
descriptions). Lightweight structure description should allow the user
to describe text structure in terms of logical structure, presentation structure,
or any combination, whatever is most natural. Existing pattern languages
work exclusively at the logical level.
5. Robustness. Real documents by human authors exhibit variations
and exceptions. Grammars and regular expressions tend to overspecify structure,
which makes them brittle in the face of variations. For example, a
grammar might describe part of a UI toolkit entry as PhoneNumber?
EmailAddress? URL? (where ? indicates that the field is optional).
This grammar depends on the order of fields, which is not only unnecessary
(since these three fields can be distinguished easily by their content) but
also brittle (because the order may vary). To make the grammar
robust with respect to variation, the user is forced to devise a
complicated pattern that covers all the possible cases. In contrast, lightweight
structure description should be biased toward robustness. The pattern language
should avoid overspecific descriptions, in order to represent, for instance,
that a toolkit entry may contain a PhoneNumber, an EmailAddress, and/or a
URL, without actually specifying their order. The pattern language should
also be able to express fuzzy knowledge, such as the fact that a person's
name usually contains all capitalized words (e.g., "James Foley"),
but not necessarily (e.g., "Andries van Dam").
I propose to build a system called LAPIS (Lightweight Architecture for Processing
Information Structures) that embodies the concept of lightweight structured
text processing, with new solutions to the five problems identified above.
The novel contributions of LAPIS are:
-
a pattern language, text constraints, that is designed to be simple,
readable, composable, expressive, and robust;
-
algorithms and representations for implementing text constraints with reasonable
efficiency;
-
techniques for detecting and using presentation structure as well as logical
structure;
-
a system architecture and document representation for composing and reusing
multiple structure detectors simultaneously;
-
a user interface that integrates the various ways of detecting structure:
manual selection, inference, patterns, and external parsers; and
-
an implementation that combines all these techniques, shown to be usable
by formal testing.
The proposed text constraints language describes regions in a document in
terms of relational operators (like before, after, in,
and contains). Text constraints can be used not only to query structure
(as in Function containing "exit"), but also to define new structure
from scratch:
Sentence = ends with delimiter SentencePunct;
SentencePunct = ('.' | '?' | '!'),
just before Whitespace,
but not '.' at end of Abbreviation;
Abbreviation = 'Dr.' | 'Mr.' | 'Mrs' | 'Mrs'; # etc.
|
Although the language needs further development, I believe text constraints
will be more readable and comprehensible for users than grammars or regular
expressions, because a structure description can be reduced to a list of
simple, intuitive constraints which can be read and understood individually.
User testing will show whether this is really the case.
A prototype of LAPIS has been built to demonstrate the system architecture,
text constraints language, and user interface. The prototype is a web browser
which can display and process not only web pages, but also source code and
text files. Text constraints are implemented as an algebra operating over
sets of regions, using efficient set representations to achieve reasonable
efficiency. In addition to text constraints, the prototype provides three
other structure description methods: manual selection, simple inference from
one example, and external parsers. Parsers for HTML, Java, and plain text
are included. The prototype provides two generic tools for processing structure:
Filter displays only the regions matching a text constraint pattern
(eliminating other text from the display), and Sort sorts the matching
regions by the value of a subfield. The collection of parsers and tools in
LAPIS is extensible, and more will be included in the final system.
My thesis is:
Lightweight structured text processing lets users describe and manipulate
many kinds of text structure, from implicit to explicit, formal to informal,
and presentation-level to logical-level, allowing the user to manipulate
the text in its original format, and delivering the convenience, speed, and
scalability of automation without the cost or difficulty of writing a custom
program.
In the next section, I give more motivation for lightweight structured text
processing by presenting example tasks in the domains of interest (web pages,
text data files, and source code). The subsequent four sections present LAPIS
in more detail: Section 3 describes the system architecture, Section 4 describes
structure detection techniques, Section 5 describes the text constraints
language, and Section 6 describes the language implementation. Section 7
outlines my plans for evaluating the thesis. Section 8 surveys related work,
Section 9 presents a schedule for completing the thesis, and Section 10
concludes.
2 Scenarios
This section gives more motivation for lightweight structured text processing
by describing three representative scenarios. Each scenario features a real
example of custom text structure, plus several tasks that would be desirable
to perform automatically.
Each scenario is drawn from a different domain. The first scenario is from
the World Wide Web, the second from plaintext databases (simple databases
stored in text form), and the third from program source code. The discussion
of each domain points out features of the domain that are challenging for
other text-processing systems and describes how LAPIS will address these
challenges.
2.1 Web Pages
By far the largest source of structured text is the World Wide Web. Nearly
every web page uses a custom structure represented in HTML. Examples include
lists of publications, search engine results, product catalogs, news briefs,
weather reports, stock quotes, sports scores, etc.
A concrete example of text structure on the Web is the user interface toolkits
list described in the Introduction. Another is the table of microprocessors
found at the CPU Info Center [Burd98]. An abridged version of this page is
shown in Figure 2.1.
| Processor |
Source |
Date
(ship) |
Bits
(i/d) |
Clock
(MHz) |
SPEC-92 |
SPEC-95 |
Units
/
Issue |
Pipe
Stages
int/ldst/fp |
Cache
(i/d) |
Vdd
(V) |
Tech
(um) |
Size
(mm2) |
Xsistor
(106) |
| int |
fp |
int |
fp |
kB |
Assoc |
Intel
x86 |
8088 |
[vi] |
79 |
v/16 |
5 |
- |
- |
- |
- |
1/1 |
1/1/na |
- |
- |
5.0 |
3.0 |
|
0.029 |
| 80286 |
[vi] |
82 |
v/16 |
6 |
- |
- |
- |
- |
1/1 |
1/1/na |
- |
- |
5.0 |
1.5 |
|
0.134 |
| i386DX |
[vi] |
85 |
v/32 |
16 |
|
|
- |
- |
1/1 |
|
- |
- |
5.0 |
1.5 |
|
0.275 |
| i486DX |
[vi] |
89 |
v/32 |
25 |
16.8 |
7.4 |
- |
- |
2/1 |
5/na/5? |
8 u. |
4 |
5.0 |
1.0 |
|
1.2 |
| P5 |
[vi] |
93 |
v/32 |
60 |
70.4 |
55.1 |
- |
- |
3/2 |
5/na/8 |
8/8 |
2/2 |
5.0 |
0.8 |
296 |
3.1 |
Pentium II
(Klamath) |
[vi] |
97 |
v/32 |
233 |
|
|
9.5 |
6.4 |
7/3(D) |
|
16/16 |
4/4 |
2.8 |
0.35 |
203 |
7.5 |
Cyrix/IBM
x86 |
6x86MX
(MII) |
[vi] |
97 |
v/32 |
150 |
(PR166) |
|
|
3/2 |
7/7/? |
64 u. |
4 |
2.9 |
0.35 |
197 |
6.0 |
| AMD |
386 |
[cm] |
90 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| Am486 |
[pn] |
95 |
v/32 |
120 |
|
|
|
|
2/1 |
|
|
|
|
0.5 |
|
|
| Am5x86 |
[vi] |
95 |
v/32 |
133 |
|
|
|
|
2/1 |
|
16 u. |
|
|
0.35 |
43 |
|
| K5 |
[39,vi] |
96 |
v/32 |
90 |
(PR120) |
|
|
6/4 |
5/5/5? |
16/8 |
4/4 |
3.5 |
0.35 |
161 |
4.3 |
| K6 |
[vi,
is97,
55] |
97 |
v/32 |
166 |
|
|
|
|
7/6(D) |
6/7/7(D) |
32/32 |
2/2 |
2.9 |
0.35 |
162 |
8.8 |
K6-3D
(K6-2) |
[vi] |
98 |
v/32 |
266 |
|
|
|
|
7/6(D) |
6/7/7(D) |
32/32 |
2/2 |
|
0.25 |
81 |
9.3 |
| K6+-3D |
[vi] |
98 |
v/32 |
400 |
|
|
|
|
7/6(D) |
6/7/7(D) |
2/32 |
|
|
0.25 |
135 |
21.3 |
|
Figure 2.1. Excerpt from a web
page describing microprocessors.
|
The structure in this table is mainly presentation structure. Each row of
the table describes a different microprocessor, and each column specifies
a different feature.
Processing the table requires extracting each row and extracting the appropriate
column entries for the row. Note, however, that some table cells span multiple
rows (such as "Intel x86" in the leftmost column), indicating that the feature
is shared by all the microprocessors it spans. This common convention has
implications for text-processing systems that only support logical structure.
Since presentation structure is usually derived from the logical structure
of a document, users can sometimes make do with text-processing systems that
operate only on logical structure by translating presentation concepts back
to the logical concepts that would generate them. In HTML, for example, a
table is specified by logical markup, using TR elements for rows and TD elements
for cells. Thus, in a simple table, it may be possible to identify the table
cell at row i, column j using the logical specification "the
jth TD element in the ith TR". When cells span multiple rows
or columns, however, this simple translation fails, because the TD element
for the row-spanning cell appears only in the first TR it covers, not in
every TR. LAPIS avoids these problems by using the actual table-layout algorithm
to define the row and column structure as it appears to the user.
To illustrate the kinds of generic tools that might be applied to this table,
consider the following tasks:
-
Filtering: To decide which Intel-compatible CPU to purchase in a new
PC, a user might want to look at only a few late-model processors (e.g.,
Intel Pentium II, Cyrix 6x86MX, AMD K6) for easy comparison of their features.
One way to do this would be to redisplay the table showing only the rows
of interest, with multi-row cells repeated to make the table a simple grid.
Columns that are irrelevant to the user's comparison could be filtered out
in a similar way.
-
Sorting: For finding the fastest processors available, the default
display order is not useful. A user might want to sort the rows of the table
by benchmark rating (SPEC-92 or SPEC-95) or clock speed. As with filtering,
the sorted table would be created by redisplaying the table as a simple grid
(by repeating the row-spanning cells), then sorting by a given column.
-
Graphing: To study Moore's Law, a user might graph the transistor
count or clock speed against the year of introduction. It might also be
interesting to graph this Moore's Law curve separately for each chip
manufacturer, to see which manufacturers are ahead of the curve and which
ones lag behind. This task requires extracting data from specific columns
across all the rows of the table and feeding the data to a charting tool.
One might ask at this point, why not use a database, spreadsheet, or charting
system which already provides tools for filtering, sorting, and graphing?
One answer is, certainly, those systems are appropriate to the task.
Unfortunately, the microprocessor table is available only in HTML format,
which is a portable, readable, and tremendously popular text format, but
not designed for import into database systems. The table's structure must
be described in order to import the table in the first place. Another answer
is that the user may want the filtered or sorted output to be in HTML also
(perhaps for the same reasons that the original data was in HTML -- for easy
posting on the Web). Importing to a database system, then exporting back
to HTML, may throw away valuable information that the database system cannot
represent, like annotations, typesetting, and text surrounding the table.
A final complication, characteristic of the Web, is that web databases are
often divided into multiple pages connected by hyperlinks, in order to keep
pages small and easy to browse. As a simple example, the CPU Info Center
separates its processor listings into two pages, one for general microprocessors
and the other for embedded microprocessors. Other web sites have more
complicated, hierarchical organizations, like Yahoo! [Yahoo99]. Many sites
do not even expose the complete database for browsing, requiring the user
to submit one or more queries (all search engines work this way). Tools for
processing web structure must therefore be capable of gathering the data
by submitting forms and crawling through hyperlinks. LAPIS will include these
capabilities, derived from the WebSPHINX end-user web crawler [MBh98].
2.2 Text Data Files
Many users store small databases in text files, rather than in database systems.
Text is popular because it is compact, readable, portable between computer
systems, and easy to edit and annotate using familiar tools. As text databases
grow larger, however, manual editing becomes more time-consuming, and the
need arises for filtered or sorted views of the data.
Consider an address list, consisting of people's names and contact information.
Figure 2.2 shows an excerpt from the list (with names changed).
Norm Pederson,
Assistant Professor,
Dept. of Computer Science
University of Brewing Science
55 Plummer Street
San Francisco, CA 94117
(415) 555-8765
norm@somewhere.edu
http://web.nowhere.edu/~norm/norm.html
Isaac Newton
Institute For Advanced Studies
Cambridge University
Cambridge MK7 6AA
UK
<Isaac.Newton@nowhere.ac.uk>
Comment: Laws of motion
Alan Turing
Palo Alto Laboratory
2300 Mountainview Ave Bldg 4
Palo Alto CA 94304
415-813-????
|
|
Figure 2.2. An address list represented
as a text file.
|
The structure of this address list includes people's names, institutions,
mailing addresses (which in turn consist of street address, city, state or
province, country, and postal code), phone numbers, email addresses, URLs,
and comments. The format of the file is far from uniform, however -- sometimes
the city and state are separated by a comma, sometimes not; sometimes the
email address appears in angle brackets, sometimes not. These variations
and exceptions, which are common in plain text, pose serious problems for
traditional methods of structure description. LAPIS addresses these problems
in two ways. First, LAPIS provides general relational operators like
before, after, in, and contains, which
need not depend on the precise punctuation used to separate fields. Second,
LAPIS can augment these general operators with fuzzy knowledge, like the
fact that the city and state are usually separated by a comma, to
improve matching precision and help detect errors.
Several tasks for address lists were proposed in a test suite for
programming-by-demonstration [PM93]:
-
Reformat a single-line address in the form name, address, phone
number into the multi-line format used in the address file.
-
Reformat the phone numbers into a form required by an autodialer,
consisting of seven digits followed by an area code (as in 666-6451, 415).
If the area code is local, omit it.
-
Mail-merge a set of addresses with a letter. Generate a fresh copy
of the letter for each address, putting the address at the top and the
recipient's name in the salutation. (Although many word processors include
a mail-merge feature, it usually requires the address list to be stored in
a database or other standard structure.)
Since these tasks were suggested in the context of programming-by-demonstration
(PBD), it may be helpful to contrast the PBD approach to these tasks with
the lightweight structured text processing approach. In the usual PBD model,
the user demonstrates a task by manually editing some examples: selecting
text, copying and pasting, deleting and inserting characters, etc. From this
low-level demonstration, the PBD system infers a program consisting of data
descriptions (what the user selects) and a sequence of editing actions, possibly
including conditionals and iterations.
In the lightweight structured text processing approach, however, the data
descriptions (structure) are specified separately from the editing actions
(tools). Inference is only one of several ways to specify a data description.
The user may also write a pattern, invoke an external parser, select some
regions manually, or use a combination of these methods. Using data descriptions
as parameters, the user invokes tools that process the entire document at
once. For the phone numbers task, the user might invoke a Reformat tool that
takes two parameters: a data description matching the records to reformat
(e.g., "PhoneNumber") and a template with embedded data descriptions showing
how to reformat each record (e.g., "[FirstThreeDigits]-[LastFourDigits],
[AreaCode]", where AreaCode, FirstThreeDigits, and LastFourDigits are the
components of a PhoneNumber). Iterations are performed implicitly by the
tools, and many conditionals can be handled by restricting the data descriptions
(e.g., "PhoneNumber containing AreaCode = 412" to operate only on local phone
numbers).
2.3 Source Code
Structure in program source code can take many forms. Module or class interfaces
are an important form of structure, in the sense that the types and functions
exported by an interface define a syntax for the interface's clients. For
instance, the Amulet user interface toolkit [MBF+97] provides a dynamic object
system on top of C++, defining interfaces for creating objects, accessing
slots (data fields), and establishing constraints among slots. Some of these
interfaces use the C++ macro preprocessor to introduce new syntax, such as
constraint formulas (Figure 2.3).
// Put in an Am_HEIGHT slot. Sets the height to the height of the object's
// owner, minus this object's Am_TOP, minus Am_BOTTOM_OFFSET
Am_Define_Formula (int, Am_Fill_To_Bottom)
{
Am_Object owner = self.Get_Owner ();
if (!owner.Valid()) return 0;
return (int)(owner.Get(Am_HEIGHT)) - (int)(self.Get(Am_TOP))
- (int)(owner.Get(Am_BOTTOM_OFFSET));
}
|
Figure 2.3. Amulet constraint formulas are
defined by special syntax, using the macro
Am_Define_Formula.
|
From the programmer's perspective, the structure of a constraint formula
is similar to an ordinary function, with a name, return type, and body, but
expressed in a custom syntax using the Am_Define_Formula macro.
Another custom structure in Amulet is the syntax for accessing object slots,
using Get and Set. In the example above,
owner.Get(Am_HEIGHT)represents an access to a slot named
Am_HEIGHT from the object owner.
Here are some useful applications of Amulet structure that could be performed
by generic tools:
-
Reformatting is necessary when an interface changes. An early version
of Amulet used the syntax obj.Get(slot,result) to get a slot, putting
the return value into result. In later releases, this syntax changed
to result=Get(slot), forcing Amulet developers to change their programs.
A tool that could replace all occurrences of the old syntax with the new
syntax would be invaluable. Most generic text-processing systems (like Perl
and awk) are unable to handle this task properly, because they lack a parser
for the programming language. LAPIS not only integrates such parsers, but
embeds them in a framework which allows extended syntax (like Amulet's) to
be defined and used as well.
-
Program understanding is important for developers trying to learn
or modify a large system. Examples of program-understanding tools include
call graphs, inheritance diagrams, cross-reference lists, and program dependence
graphs. Murphy and Notkin [MN96] have shown that lexical methods, though
sometimes inaccurate, are nevertheless fast and effective for generating
these kinds of artifacts, particularly if no parser for the language is
available. Like Murphy & Notkin's system, LAPIS can use lexical information
found by pattern-matching, but LAPIS can also take advantage of syntactic
information if a suitable parser is available.
-
Statistics about interface usage can be very helpful to developers.
One study [VZM+99] computed a number of statistics about constraint usage
in a group of Amulet programs, including: How many constraints are
programmer-defined formulas, and how many are built-in to the toolkit? How
many constraints are used simply for graphical layout? How often are side-effects
(Set) used in constraint formulas? The answers to these questions
might be used to improve the design of the toolkit.
-
Syntax coloring can make Amulet programs more readable by highlighting
constraint formula definitions and slot accesses in a unique color. Many
interactive development environments include syntax coloring for generic
C++ syntax, but these environments are hard to specialize for customized
syntax.
-
Static checking can warn about Amulet-specific errors at compile time.
For example, the Am_Fill_To_Bottom constraint of Figure 2.3 is almost
always installed in the Am_HEIGHT slot of an object, as its comment
indicates. A static checker that warns about violations of this rule can
eliminate some errors at compile time.
Coding conventions like commenting and indentation are another form of structure
in source code, based on presentation structure rather than logical structure.
If, for example, the terminating brace of an if statement doesn't
line up with the opening brace, then the programmer may have nested the blocks
incorrectly. Existing systems for source code processing, which work entirely
at the logical level, make it impossible to express these kinds of error
checks.
Source code can also include composite structure, making it necessary to
combine multiple structure detectors. In Java, for example, methods are
frequently preceded by a "documentation comment" which can include various
kinds of fields, such as @param to describe method parameters and
@return to describe the return value. Since documentation comments
tend to lag behind when changes are made to the actual code, it would be
helpful for a static checking tool to report methods whose documentation
disagrees in the number or names of parameters. Expressing this rule requires
combining Java syntax (the method definition) with documentation comment
syntax (@param, @return, etc.).
3 System Architecture
Figure 3.1 shows the current system architecture of LAPIS. The architecture
consists essentially of three parts: a document viewer, an extensible collection
of structure detectors, and an extensible collection of tools. The rest of
this section describes the three parts in more detail, after a brief detour
to describe the document representation that lets the parts to work together.

|
Figure 3.1. The LAPIS
system architecture. The document viewer loads and displays documents. Structure
detectors annotate documents with structure labels, such as name, city,
postal code, and email shown in the example document fragment.
Tools use structure labels to manipulate documents.
|
3.1 Structure Representation
In many structured text editing systems, documents are represented by a
hierarchical tree of nodes corresponding to the document structure. In contrast,
the current design of LAPIS represents a document as a simple string of
characters. The structure of a document is represented by sets of
regions. Formally, a region is an interval [b, e] of
inter-character positions in a string, where 0 <= b <= e
<= n (n is the length of the string). A region [b,e]
identifies the substring that starts at the bth cursor position (just
before the bth character of the string) and ends at the eth
cursor position (just before the eth character, or at the end of the
string if e=n). The length of a region is e-b.
To represent structure in a document, LAPIS stores a set of regions identified
by a label. For example, the HTML tags might be represented by a set of regions
labeled Tag, corresponding to all the regions of the document that
were parsed as tags by an HTML parser. The regions in a region set can nest
or overlap arbitrarily. In the worst case, this means that a region set can
contain up to n2 regions, where n is the length
of the document. In practice, most region sets take only linear space, either
because the regions are nonoverlapping or nonnesting, or because the region
set is dense enough to be represented by region intervals (described
in more detail in Section 6).
Labeled region sets enable a document to have multiple coexisting structures,
which is vital for composability and reuse. For example, a web page containing
a publications list can be interpreted both as HTML structure, generating
labeled region sets like Tag and Element, and as bibliographic
structure, generating labeled region sets like Title,
Author, and Source. Since the representation of HTML structure
and bibliographic structure is the same (labeled region sets), the user can
refer to both structures in the same way, even in the same expression.
3.2 Document Viewer
The primary user interface component of LAPIS is the document viewer. In
the current prototype, the document viewer is a web browser written in Java
1.1 using Sun's Java Foundation Classes (JFC).
The document viewer performs three functions:
-
Document loading and display. Documents may come from disk, from the
Web, or from the output of generic tools. Plain text files and source code
are displayed as plain text; web pages can be displayed either as rendered
pages or as raw HTML source. The document viewer behaves like a web browser
in most other respects, including active hyperlinks, a browsing history with
Forward and Back commands, and Stop and Reload commands to cancel or restart
operations.
-
Structure detection. Structure detectors recognize the structure of
documents and generate labeled region sets. Examples of structure detectors
include HTML and Java parsers, the page layout engine (which detects presentation
structure), and document-specific structure detectors created by the user.
The user can also detect structure interactively, by a variety of means:
entering text constraint expressions, selecting regions and assigning them
labels manually, or teaching by example. The document viewer highlights detected
structure in context, to help the user with iterative development.
-
Tool invocation. Tools use structure to process the document. A tool
is invoked by a menu command in the document viewer. Parameters (if any)
are provided by selecting regions in the viewer or entering values in a dialog
box. Output is displayed in the document viewer.
3.3 Structure Detectors
A structure detector scans a document and generates a collection of
labeled region sets. Structure detectors interpret a particular text format
and label its components in the document. The LAPIS prototype includes three
built-in structure detectors:
-
HTML: a hand-coded HTML parser that detects HTML tags and elements.
-
Java: a Java parser (automatically generated by the JavaCC
parser-generator [Sun98]) that detects syntactic elements in a Java source
file, including classes, declarations, statements, expressions, and identifiers.
-
Character: a hand-coded lexical scanner that classifies runs of similar
characters in a document, such as Whitespace, Letters,
Digits, etc.
Structure detectors can be invoked manually on a document, or automatically
by associating the structure detector with a MIME type pattern and/or a URL
pattern. Whenever a document with a matching MIME type or URL is loaded,
the structure detector is invoked. Multiple structure detectors can be invoked
on a document, but only a single namespace is supported by the LAPIS prototype,
so the names generated by different parsers should be chosen uniquely. The
final LAPIS system will alleviate this problem by supporting multiple independent
namespaces.
Structure detectors can take advantage of structure labeled by other detectors.
For example, a structure detector for the CMU online library catalog [CMU98]
can refer to structure labels generated by an HTML parser. Structure detectors
can be composed and reused in this manner, communicating through the structure
labels attached to documents. In the prototype, the user is responsible for
ensuring that structure detectors are invoked in the proper order, so that,
for example, HTML labels are generated before the online catalog detector
needs them. The final system will provide mechanisms for specifying dependencies
among structure detectors to alleviate this problem.
In the future, more built-in structure detectors will be added to LAPIS,
including:
-
USEnglish. will detect structure that depends on conventions of American
English, like Time, Date, Currency,
Sentence, and Paragraph.
-
Presentation will detect presentation structure, such as
Line, Bold, Italic, Row, and
Column, by augmenting the document viewer's rendering algorithms.
Since presentation structure may be changed by user actions (like resizing
the window), having the rendering algorithms generate the structure ensures
that labeled structures will always agree with what the user sees.
LAPIS can be easily extended with new structure detectors by writing a system
of text constraints and associating it with a MIME type or URL pattern. The
prototype also supports detectors written in Java, and in the future LAPIS
will provide an external interface for detectors written in languages other
than Java.
Structure detection can also be done interactively, as described in Section
4.
3.4 Tools
A tool accepts one or more region sets as parameters and uses them
to manipulate the document. The current LAPIS prototype includes two tools:
-
Filter. This tool displays only the text included in a region set,
eliminating all text outside the region set from the display. By default,
Filter inserts linebreaks between nonoverlapping regions to keep the display
readable. Currently, documents are filtered at the source text level -- even
HTML documents. The result may be illegal HTML (with orphaned start tags
or end tags), but the web browser seems to render it passably.
-
Sort. The Sort tool filters the display down to a region set,
like Filter, and also reorders the regions. A region set can only be sorted
if it is nonoverlapping, so that the document can be cut up into records
and rearranged. Regions can be sorted alphabetically or numerically. By default,
the sort key is the entire content of a region, but the user can also provide
an additional region set describing the sort key field.
I propose to add several more tools:
-
Reformat. This tool will take two parameters: a region set matching
the records to reformat, and a template with embedded region set descriptions
showing how to reformat each record. Among other uses, Reformat will allow
the user to connect LAPIS with arbitrary external tools by extracting content
from a document and converting it to a format that can be imported by the
other tool, such as tab-delimited text.
-
Calculate. This tool will compute counts, sums, averages, and other
statistics on a region set, treating the regions as numbers where necessary.
It will also be able to apply a numerical function to each region in a region
set (for example, multiplying by 10, or converting from Celsius to Fahrenheit).
-
Difference. This tool will find the differences between two region
sets, like the Unix utility diff.
-
Chart. This tool will take multiple region sets and display them as
a chart (e.g., a line chart or bar chart). This built-in charting tool will
provide only a limited set of options. Users with more sophisticated needs
might use Reformat to generate input for an external charting system like
gnuplot or Microsoft Excel.
-
Pretty-print. This tool will allow the user to assign a rendering
style (font and color) to a region set, so that, for instance, all function
names might be drawn in blue italics.
-
Automatic hyperlinking. This tool will transform a set of regions
into hyperlinks to some other location in the document (or another document).
Hyperlinking might be used to connect variable references with definitions,
for example.
-
Web crawling. This tool will automatically retrieve all the hyperlinks
in a set of regions, generating a page by concatenating them together (as
in WebSPHINX [MBh98]).
Many other useful tools could be provided. Like structure detectors, the
collection of tools can be extended by the user. LAPIS will provide several
ways to attach new tools, including Reformat (to convert to an external tool's
input format), a simple scripting language, a Java interface (for tools coded
in Java), and an external interface (for tools written in other languages).
4 Structure Detection Techniques
Structure detection is the problem of finding and labeling structure
in documents. The input to a structure detector is a document (or set of
documents); the output consists of one or more labeled region sets.
LAPIS will provide four structure detection mechanisms: pattern-matching,
manual selection, inference from examples, and programming. Although these
techniques have been used individually in other text-processing systems,
they have never been integrated into a single system. LAPIS will demonstrate
the usability and functionality benefits of combining all four techniques.
The section begins with a discussion of feedback, which lets the user check
whether structure detection has been done correctly. Then, the four
structure detection techniques are described. The discussion defines each
technique, describes how it is realized in the LAPIS prototype, and lists
the advantages of the technique, particularly when combined with the other
techniques.
4.1 Feedback
Users need feedback to check that the structure of a document has been detected
correctly. The LAPIS prototype provides two forms of feedback: a hierarchical
label browser showing the labeled region sets generated by structure
detectors, and highlighting of region sets in context.
The label browser lists the labeled region sets in the current document (Figure
4.1c). The user can select a label from the label browser and see its
corresponding region set highlighted in the document. In the prototype, labels
are arranged in a hierarchy of specialization -- e.g., the Characters region
set (representing all characters in the document) expands into Whitespace,
Alphanumeric, and Punctuation. Other arrangement options will be explored
in the final system, including containment and ordering relationships (e.g.,
an IfStatement contains a BooleanExpression followed by a Statement). To
arrange the labels, the label browser relies on explicit relationship information
provided by structure detectors. Labels assigned interactively by the user
lack this information, so the prototype simply displays them in alphabetical
order at the top level. The final system will provide ways to specify the
relationships among user-defined labels by dragging and dropping in the label
browser.
Highlighting displays a region set in the document viewer. In the prototype,
a region set is highlighted by changing the background color of all the
characters that appear in some region in the set (Figure 4.1b). This rendering
technique is simple to implement and familiar to users, because of its similarity
to text selection. Unfortunately, this technique merges adjacent and overlapping
regions together, without distinguishing their endpoints. I propose to
investigate better ways to display overlapping region sets in context.
To view all the highlighted regions in the prototype, the user can either
scroll the document or use the Next Match and Previous Match
commands to jump from one highlighted region to another.
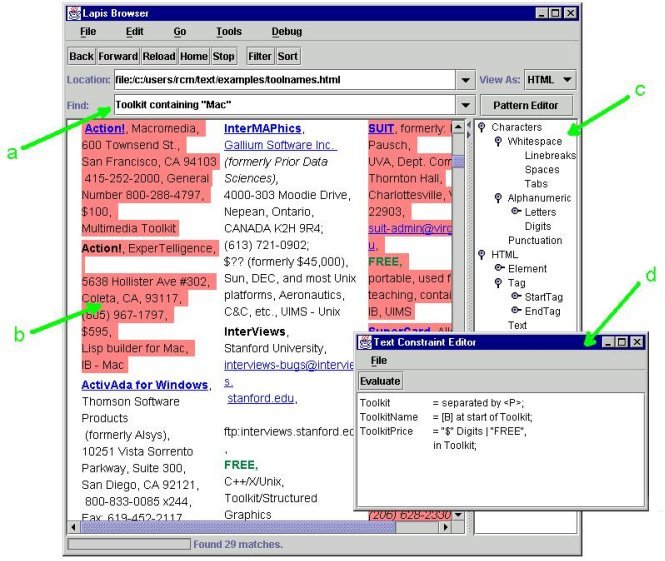
|
Figure 4.1. LAPIS prototype showing some
of the user interface components used for structure detection and feedback:
(a) Find box, where a text constraint expression may be entered to find it
in the document; (b) highlighted region set, showing the result of executing
the expression in the Find box; (c) label browser, showing the region set
labels in the document; and (d) text constraint editor, for developing a
system of text constraint expressions.
|
4.2 Patterns
The first structure detection technique is pattern matching. A
pattern language consists of primitives and operators for describing
strings of text. When used for structure detection, a pattern is
matched against a document, yielding the set of regions in the document
that match the pattern. Examples of pattern languages include regular
expressions, context-free grammars, SNOBOL [GPP71], and Icon [GG83]. LAPIS
introduces a new pattern language, text constraints, which tries to
address the usability problems in existing pattern languages. Text constraints
are described in Section 5.
The LAPIS prototype offers two places where the user can enter text constraints.
Figure 4.1a shows the Find text box. When the user enters a text constraint
expression here, the region set matching the expression is highlighted in
the document. Figure 4.1d shows the Text Constraint Editor, a separate window
which allows the user to load, save, edit, and invoke systems of text
constraints. In the final system, patterns will be used in other places as
well. For example, one of the parameters to the Reformat tool will be a template
containing embedded patterns.
Pattern matching has several advantages. Patterns are compact, declarative,
and textual. A pattern can be used in place of an explicit label for a region
set, which can simplify the operation of other structure detectors. For example,
the prototype's Java parser labels all statements as Statement,
leaving it to the pattern language to specialize this general region set
into particular kinds of statements: Statement starting with "if",
Statement starting with "while", etc.
Patterns are also useful as feedback for inference. The inference technique
in LAPIS will be designed so that its hypotheses can be represented as patterns,
so that the patterns can be presented to the user for confirmation or correction.
4.3 Selection
Selection is how the user manually points to a region in a document. In the
familiar direct-manipulation technique popularized by the Macintosh, the
user positions the mouse cursor at one end of the region, holds down the
mouse button, drags the cursor to the other end of the region, and releases.
Other techniques for selecting text are also in common use. For our purposes,
the important thing about selection is that the user is acting as
a structure detector, identifying a piece of document structure by eye and
pointing to it by hand.
In the prototype, the selection is distinct from the highlighted
region set that shows matches to a pattern. The selection is a
single, contiguous region, whereas the highlighted region set may contain
multiple, noncontiguous regions. The selection changes whenever the
user clicks somewhere in the document, whereas the highlighted region set
changes only when the user enters a new pattern in the Find box or selects
a different label in the Label browser. The distinction between the
selection and the highlighted region set is indicated to the user by different
colors of highlighting: the selection is blue, but the region set is red.
Both kinds of highlighting can coexist and overlap in the document viewer.
The current selection is always available as a one-element region set labeled
Selection. By referring to Selection in a pattern, the
user can limit the pattern's scope to a manually selected region of the document.
In general, however, a user may want to construct a region set by
selection. The prototype handles this problem with menu commands for
constructing a labeled region set from selections. The Label
command adds the current selection to the region set with the given label.
If the highlighted region set was highlighted by label (as opposed to an
unlabeled pattern), then the Label command uses this label by
default. By applying Label repeatedly to a sequence of selections,
the user can build up a labeled region set by hand. A corresponding
UnLabel command removes the selection from a given labeled region
set by deleting regions that lie inside the selection and trimming the ends
of regions that overlap the selection.
This design is a prototype, which is likely to evolve with experience.
In particular, I plan to investigate using discontiguous selection to create
anonymous region sets, without having to name them. Discontiguous selection
would allow the separate highlights for the selection and the highlighted
region set to be combined into a single highlighted selection.
Manual selection is useful as a way to restrict attention to part of a document
that can be selected more easily than it can be described, such as the content
area of a web page (omitting navigation bars and advertisements). Manual
selection can also fix errors made by patterns, inference, or external parsers,
as long as the errors aren't too numerous. For example, if a simple pattern
matches 99% of the desired regions, it may be reasonable to correct the remaining
mistakes by manual selection.
Correcting a pattern involves a tradeoff between convenience and
reproducibility. Corrections made with Label and UnLabel are convenient
but not automatically reproducible, since Label and UnLabel change only the
labeled region set and not the pattern that originally created it.
Applying the pattern again would not repeat the corrections. At the other
end of the tradeoff, modifying the pattern to fix it is less convenient but
easily reproducible. Inference (described next) lies somewhere in between,
treating manual corrections as positive and negative examples for generating
a corrected pattern. By providing all three of these structure detection
mechanisms, LAPIS lets the user choose the point on the tradeoff that is
most appropriate to the task.
4.4 Inference
Inference takes a set of example regions (positive or negative) and generalizes
from the examples to generate a description of a region set. Inference
is an essential feature of automatic information extraction ([Frei98], [KWD97])
and programming-by-demonstration (TELS [WM93], Cima [Mau94], Tourmaline
[Myers93], Grammex [LNW98], and EBE [Nix85]).
The LAPIS prototype includes a simple inference technique called "What's
This?" The user selects a region and right-clicks on it, which brings up
a menu listing the labeled region sets to which the selected region belongs.
This inference technique uses only a single positive example (the selected
region) and generates very simple generalizations (the available labels for
the region). The final LAPIS system will draw on previous machine learning
research to provide more elaborate inference, using multiple examples, hints
([Mau94], [McD98]), and more complicated generalizations represented as text
constraints.
Inference has a number of advantages as a structure detection technique.
Inference has a shallow learning curve. To get started, novice users need
only learn how to provide examples (and possibly hints) and check whether
inferences are correct. Since LAPIS will display the inferred descriptions
as patterns, inference will help the user climb the learning curve by disclosing
the primitives and operators of the pattern language, acting as a
self-disclosing interface [DiG96].
Inference can also uncover latent regularities that the user might not have
noticed. From examples, an inference algorithm might deduce that typical
human names are between 10 and 30 characters long, contain two or three
capitalized words, and contain no digits or unusual punctuation. These kinds
of deductions can help debug other structure detectors by finding
unusual matches or mismatches and pointing them out to the user as possible
errors. For an example of how the final LAPIS system might apply this idea,
suppose the user tries to write a pattern to match the authors in a large
bibliography. In addition to highlighting matches to the user's pattern,
the system applies an inference algorithm to find features that are common
to most (but not all) matches, such as "10-30 characters long". These features
are used to rank the matches, allowing the user to browse the most unusual
matches first. Since these matches are the most likely to be wrong, the user
can find and fix errors in the pattern more quickly. Using inference to rank
matches by dissimilarity may significantly speed up debugging of structure
detectors, particularly on large data sets where errors might be few and
far between.
Finally, inference benefits from the presence of other structure detection
techniques, because the labeled region sets created by other techniques provide
new, domain-specific concepts that can be used in generalization. For example,
after a Java parser has been invoked, the inference algorithm has access
to a wealth of concepts about Java programs (variables, declarations,
expressions, statements, etc.) that would have been difficult or impossible
to infer automatically.
4.5 Programs
The fourth and final structure detection technique is writing a program,
also called a parser. A parser may be written with a traditional
programming language such as C++ or Java, with a text-processing language
like Perl [WS91] or Awk [AKW88], or with a parser-generator like Yacc [John75].
A parser is a black box which, once invoked, has no interaction with the
user.
In the LAPIS prototype, a parser is a Java class implementing the
Parser interface. Several parsers are provided in the prototype,
including parsers for HTML and Java. The Java parser is automatically generated
from a grammar by the JavaCC parser-generator [Sun98]. The grammar is an
existing JavaCC example, modified to generate region sets for certain
nonterminals (statements, expressions, and declarations, among others). Thus
LAPIS can take advantage of existing parsers without substantial recoding.
In the future, LAPIS will provide an external interface for parsers written
in languages other than Java.
Programs are necessary for computations that are difficult or impossible
to express in a simple pattern language. For source code, such computations
include type checking, type inference, control flow and data flow analysis,
and other kinds of program analysis. The rendering algorithms used to layout
HTML pages are another kind of parser, which identifies and labels presentation
structure.
Supporting external parsers enables reuse of standard formats, like C++,
Java, or HTML, for which off-the-shelf parsers already exist. Parsers are
harder to extend and modify than the other structure detection techniques,
however. Having patterns or manual selection available as well makes it possible
to override or extend the behavior of a parser to some extent, without having
to open its black box.
5 Text Constraints
Text constraints (TC) is my new language for specifying text structure using
relationships among regions (substrings of the text). TC is similar to languages
for querying structured text databases, such as Proximal Nodes [NBY95], GC-lists
[CCB95], p-strings [GT87], tree inclusion [GT87], Maestro [Mac91], and PAT
expressions [ST92]. A survey of structured text query languages is found
in [BYN96].
Unlike these languages, however, TC is intended not merely for queries, but
for the general problem of structure description. In other structured query
languages, an expression like "Gettysburg" in Title in Article queries
an abstract syntax tree created by an external parser, in which
Title and Article are nodes. In TC, Title and
Article may be defined by TC expressions themselves. TC enables
the user to define a system of expressions to describe the structure of the
document, without having to build an external parser or learn a different
language for structure description.
TC is an algebra over sets of regions. Operators take region sets as arguments
and generate a region set as the result. TC permits an expression to match
an arbitrary set of regions, unlike other structured text query languages
that constrain region sets to certain types. For example, regular expression
matching is usually restricted to nonoverlapping sets, GC-lists are restricted
to nonnesting sets, and Proximal Nodes are restricted to hierarchical sets.
The following discussion presents the current design of text constraints
used in the LAPIS prototype. The language is expected to evolve with experience.
5.1 Literals
Literal strings are matched by an expression of the form "literal"
or 'literal'. Thus "Gettysburg" finds all regions exactly
matching the literal characters "Gettysburg". Literal matching can generate
overlapping regions, so matching "aa" against the string "aaaaa"
would yield 4 regions.
The LAPIS prototype also supports regular expression literals, which
are expressions of the form /regexp/. Our regular expression matcher
is based on the OROMatcher library for Java [ORO98]. The library follows
Perl regular expression syntax and semantics, returning a set of nonoverlapping
regions that are as long as possible.
5.2 Labels
A region set can be assigned a label, which is a simple identifier like
PhoneNumber or Title. Labels are assigned by other structure
detectors (as described earlier under System Architecture) or by a
constraint definition, for example:
GettysburgAddress = starts with "Four score and seven years ago", ends
with "shall not perish from the earth"
Labeled region sets can be referenced by a constraint expression:
Sentence at start of GettysburgAddress
A constraint system is a set of constraint definitions separated by
semicolons. A constraint system is a structure detector, since it assigns
labels to region sets. Like other structure detectors, a constraint system
can be associated with MIME types and URLs, so that the constraint system
is invoked every time a page with a corresponding MIME type or URL is loaded.
5.3 Region Relations
TC operators are based on six fundamental binary relations among regions:
before, after, in, contains,
overlaps-start-of, and overlaps-end-of. (Similar relations
on time intervals were defined in [Allen83].) The region relations are defined
as follows:
| [b1, e1] before [b2,
e2] |
if and only if e1 <= b2 |
| [b1, e1] after [b2,
e2] |
if and only if e2 <= b1 |
| [b1, e1] in [b2,
e2] |
if and only if b2 <= b1 and
e1 <= e2 |
| [b1, e1] contains
[b2, e2] |
if and only if b1 <= b2 and
e2 <= e1 |
| [b1, e1] overlaps-start-of
[b2, e2] |
if and only if b1 <= b2 <=
e1 <= e2 |
| [b1, e1] overlaps-end-of
[b2, e2] |
if and only if b2 <= b1<= e2
<= e1 |
The six region relations are illustrated in Figure 5.1.

|
Figure 5.1. Fundamental region relations in an
example string. Regions A-F are related to region R
as follows:
A before R; B overlaps-start-of R; C contains R; D in
R; E overlaps-end-of R; and F after R.
|
These six region relations are complete in the sense that every pair of regions
is found in at least one of the relations. Some regions may be related in
several ways, however. For example, in Figure 5.1, if A's end point were
identical to R's start point, then we would have both A before R and
A overlaps-start-of R. We define a set of derived relations in which
regions have coincident endpoints:
| R1 just-before R2 |
if and only if both R1 before R2
and R1 overlaps-start-of R2 |
| R1 just-after R2 |
if and only if both R1 after R2 and
R1 overlaps-end-of R2 |
| R1 starts-with R2 |
if and only if both R1 contains
R2 and R1 overlaps-start-of
R2 |
| R1 ends-with R2 |
if and only if both R1 contains
R2 and R1 overlaps-end-of
R2 |
| R1 at-start-of R2 |
if and only if both R1 in R2 and
R1 overlaps-start-of R2 |
| R1 at-end-of R2 |
if and only if both R1 in R2 and
R1 overlaps-end-of R2 |
Figure 5.2 illustrates these derived relations.

|
Figure 5.2. Region relations with coincident
endpoints. Regions A-F are related to region R as follows:
A just-before R; B at-start-of R; C at-end-of R; D
starts-with R; E ends-with R; and F just-after
R.
|
Another useful derived relation is overlaps, which is the union
of the four relations in, contains, overlaps-start-of,
and overlaps-end-of:
| R1 overlaps R2 |
if and only if |
R1 in R2
or R1 contains R2
or R1 overlaps-start-of R2
or R1 overlaps-end-of R2 |
In Figure 5.1, the regions B, C, D, and E overlap R, but A and F do
not.
5.4 Relational Operators
Each region relation corresponds to a relational operator in TC. Relational
operators are unary operators, which take a set of regions S and generate
the set of regions that stand in the given relation to some region in S:
-
before S: all regions that are before some region
in S
-
after S: all regions that are after some region
in S
-
in S: all regions that are in some region in S
-
contains S: all regions that contain some region
in S
-
... and so on.
For example, in an HTML document, the constraint expression in Tag
matches all regions inside some HTML tag.
Relational operators can also be used as binary infix operators, as in the
expression Tag containing "www.cs.cmu.edu". This expression is syntactic
sugar for the intersection of two region sets, Tag and containing
"www.cs.cmu.edu". When used as binary operators, all relational operators
have equal precedence and right associativity, so X in Y containing Z
should be understood as X in (Y containing Z).
5.5 Set Intersection, Union, and Difference
Constraints that must be simultaneously true of a region are expressed by
separating the constraint expressions with commas. The region set matched
by
X1,X2,...,Xn is the
intersection of the region sets matched by
X1,...,Xn. For example just after
"From:", just before "\n" describes all regions that start immediately
after a "From:" caption and end at a newline. The expression
Sentence, Line matches all regions that are simultaneously
a Sentence and a Line -- in other words, sentences that
take up exactly one full line.
Alternative constraints are specified by separating the constraint expressions
with "|". The region set matched by X1 | X2 ...
| Xn is the union of the region sets matched by
X1,X2,...,Xn.
Set difference is indicated by but not. The region set
matched by X1 but not X2 is the region set
that matches X1 after removing all regions
that match X2.
5.6 Delimiter Operators
When some of the relational operators are combined in an expression, the
resulting region set can be larger than the user anticipates. For example,
the expression starts with A, ends with B matches every possible
pair of A and B, even if other A's and B's occur in between. For situations
where only adjacent pairs are desired, any relational operator can be modified
by the keyword delimiter:
-
starts with delimiter S: all regions that start with some region
in S and overlap no other region in S.
-
ends with delimiter S: all regions that end with some region in
S and overlap no other region in S.
-
just before delimiter S: all regions that are just before some region
in S and overlap no other region in S.
-
just after delimiter S: all regions that are just after some region
in S and overlap no other region in S.
-
... and so on.
Another useful operator is defined in terms of delimiter operators:
-
separated by S: all regions that overlap no region in S (defined
as before delimiter S | after delimiter S)
For example, separated by BlankLine would find paragraphs separated
by blank lines.
5.7 Concatenation and Background
Concatenation of regions is indicated by then. Thus the expression
"Gettysburg" then "Address" matches regions that consist of "Gettysburg"
followed by "Address", with nothing important in between. The meaning of
nothing important depends on a parameter called the background.
The background is a set of regions. Characters in the background regions
are ignored when concatenating or intersecting constraint expressions. For
example, when the background is Whitespace, the expression
"Gettysburg" then "Address" matches not only GettysburgAddress,
but also Gettysburg Address, and even Gettysburg Address split across two
lines. Relational operators that require adjacency also use the background,
so the expression "Gettysburg" just before "Address" will successfully
match the word "Gettysburg" in "Gettysburg Address".
The LAPIS prototype chooses a default background based on the current document
view, following the guideline that any text not printed on the screen is
part of the background. In the plain text view, the default background is
Whitespace. In the HTML view, the default background is the union
of Whitespace and Tag, since HTML tags affect rendering
but are not actually displayed.
The background can also be set explicitly using the ignoring directive.
To change the background temporarily for the duration of a constraint expression,
use the form expression ignoring X. The background
can be removed by setting it to Nothing (which generates the empty
region set). For convenience, the dot operator X . Y
can be used as syntactic sugar for (X Y) ignoring Nothing.
Thus "Gettysburg" . "Address" matches only regions
of the form "GettysburgAddress".
5.8 Expressiveness
The theoretical power of TC --- that is, the set of languages that can be
matched by a TC expression --- depends on the power of the matchers and parsers
it uses. If the matchers and parsers generate only regular languages, then
the TC expression is also regular, since regular languages are closed under
the TC operators (concatenation, intersection, and union). Since context-free
languages are not closed under intersection, however, a TC expression using
context-free parsers may match a non-context-free language.
In the prototype, a TC constraint system that uses only literals (no regular
expressions or external parsers) is not as powerful as a regular expression,
because TC lacks recursive constraints or repetition operators (such as the
Kleene closure, *). The final LAPIS system will address this problem, as
described next.
5.9 Planned Extensions
The text constraint language has room for improvement as a lightweight structure
description technique. I propose to add the following extensions:
Counting and quantities. It will be possible to refer to regions by
number (e.g. 2nd Line in Table) and use numeric relational operators
(e.g. Toolkit containing Price < 100).
Recursive definitions. Constraint systems will support recursive or
mutually recursive constraint definitions. Combining recursive definitions,
concatenation, and set union will allow TC constraint systems to express
the same languages as context-free grammars. Since TC also includes set
intersection and difference, which cannot be represented by context-free
grammars [HU79], TC will be more expressive than context-free grammars.
Fuzzy qualifiers. It will be possible to precede a constraint expression
by one of the following fuzzy qualifiers: always,
usually, rarely, never. A fuzzy qualifier describes
how important it is for a matching region to satisfy the constraint.
Always indicates that the constraint must always be satisfied, so
regions which do not satisfy the constraint are thrown out. This is the default
behavior when no fuzzy qualifier is given. Conversely, never indicates
that the constraint must never be satisfied, which is equivalent to performing
a set difference with but not. The other fuzzy qualifiers
(usually, rarely) are probabilistic. Each region receives
a probability weight based on the fuzzy constraints it satisfies, where
usually constraints increase a region's probability and
rarely constraints decrease the probability. The result of a
fuzzy-qualified constraint is therefore a fuzzy set [DP80], in which
every possible region has a degree of membership between 0 and 1 given by
its probability weight.
The probability weights in a fuzzy region set can be used in two ways. First,
the fuzzy set can be reduced to an ordinary region set by applying an acceptance
threshold, such that only regions with probability weight greater than the
threshold are accepted as members of the set. Thresholding would be required
to apply tools to a fuzzy region set. Second, the probability weights can
be used to find potentially false accepts or false rejects by ordering regions
according to their probability and finding regions just above and below the
acceptance threshold. These "borderline" regions could be suggested to the
user as possible pattern-matching errors.
6 Implementation
This section describes the implementation of text constraints used in the
current LAPIS prototype. Among the interesting features of the implementation
is a novel representation, the region interval, for certain kinds
of region sets. Region intervals are particularly good at representing the
result of a region relation operator. By a simple transformation, region
intervals may be regarded as rectangles in two-dimensional space, allowing
the prototype to draw on earlier research in computational geometry to find
a data structure suitable for storing and combining collections of region
intervals.
6.1 Region Interval Representation
The key ingredient to an implementation of text constraints is choice of
representation: how shall region sets be represented? One alternative is
a bitvector, with one bit for each possible region in lexicographic order.
With a bitvector representation, every region set requires
O(n2) space, where n is the length of the document.
Since most region sets have only O(n) elements in practice, the bitvector
representation wastes space. Another alternative represents a region set
as a list of explicit pairs [b,e], which is more appropriate for sparse
sets. Unfortunately the region sets generated by relational operators are
not sparse. To choose a pathological example, after [0,0]
matches every possible region. In general, for a region relation op
and region set X, op X may have
O(n2) elements in practice.
Other systems have dealt with this problem by restricting region sets to
nested sets [14] or overlapped sets [4], sacrificing expressiveness for linear
storage and processing. Instead of restricting region sets, the LAPIS
prototype compresses dense region sets with a novel representation called
region intervals. A region interval is a tuple [b,c; d,e],
representing the set of all regions [x,y] such that b <= x
<=c and d <=y <=e. Essentially, a region interval is
a set of regions whose starts and ends are given by intervals, rather than
points. A region interval is depicted by extending the standard notation
for regions ( |----| ), replacing the vertical lines denoting the region's
endpoints with boxes denoting intervals.
A few facts about region intervals follow immediately from the definition:
-
The set of all regions in a string of length n can be represented
by the region interval [0,n; 0,n].
-
The singleton region set {[b,e]} is represented by the region interval
[b,b; e,e].
-
A region interval [b,c; d,e] represents the empty set if b >
c or d > e or b > e.
-
A region interval [b1, c1; d1,
e1] is a subset of another region interval
[b2, c2; d2, e2] if and
only if b2 <= b1 <= c1 <=
c2 and d2 <= d1 <=
e1 <= e2.
-
The intersection of two region intervals [b1, c1;
d1, e1] and [b2, c2;
d2, e2] is [max(b1, b2),
min(c1, c2); max(d1, d2),
min(e1, e2)], which may of course be the empty
set.
Region intervals are particularly useful for representing the result of applying
a region relation operator. Given any region X and a region relation
op, the set of regions which are related to X by op
can be represented by exactly one region interval, as shown in Figure 6.1.
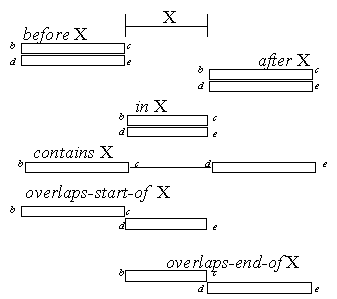
|
Figure 6.1. Region intervals corresponding
to the relational operators.
|
By extension, if a region relation operator is applied to a region set with
m elements, then the result can be represented with m region
intervals (possibly fewer, since some region intervals may be subsets of
others).
This result extends to region intervals as well: applying a region relation
operator to a region interval yields exactly one region interval. For example,
the result of before [b,c; d,e] is the set of all regions which
are before some region in [b,c; d,e]. Assuming the region interval
is nonempty, every region ending at or before c qualifies (since all
such regions are before the region [c,d] in the region interval),
but none others, so the result of this operator can be described by the region
interval [0,c; 0,c].The table below shows how to represent
the result of each region relation operator with a region interval.
| before [b,c; d,e] |
[0,c; 0,c] |
| after [b,c; d,e] |
[d,n; d,n] |
| in [b,c; d,e] |
[b,e; b,e] |
| contains [b,c; d,e] |
[0,c; d,n] |
| overlaps-start-of [b,c; d,e] |
[0,c; b,e] |
| overlaps-end-of [b,c; d,e] |
[b,e; d,n] |
We can represent an arbitrary region set by a union of region intervals,
which is simply a collection of tuples. The size of this collection may still
be O(n2) in the worst case (consider, for example, the
set of all regions [b,e] of even length, which must be represented
by O(n2) singleton region intervals), but most collections
are O(n) in practice.
To summarize, the union-of-region-intervals representation enables a
straightforward implementation of the text constraints language:
-
Literals: convert the set of regions generated by literal matching
into a union of region intervals by replacing each region [b,e] with
the singleton region interval [b,b; e,e].
-
Relational operators: to compute region relation operator op,
replace each region interval [b,c; d,e] with the region interval
given by op [b,c; d,e].
-
Union: merge the two collections of region intervals, eliminating
region intervals that are subsets of other region intervals.
-
Intersection: intersect every possible pair of region intervals (one
from each collection) and collect the intersections.
6.2 Region Space
It remains to choose a representation for the collection of region intervals
that provides the necessary operations: region relations, union, and
intersection.
A 2D geometric interpretation of regions will prove helpful. Any region
[b,e] can be regarded as a point in the plane, where the x-coordinate
indicates the start of the region and the y-coordinate indicates the end.
This two-dimensional interpretation of regions will be referred to as region
space (see Figure 6.2). Strictly speaking, only points with integral
coordinates correspond to regions, and even then only if they lie above the
45-degree line, where b <= e.
|
Figure 6.2. A region [b, e] corresponds
to a point in region space.
|
Under this interpretation, a region interval [b,c; d,e] corresponds
to an axis-aligned rectangle in region space.
|
Figure 6.3. A region interval [b,c; d, e]
corresponds to a rectangle in region space.
|
Two region intervals intersect if and only if their region space rectangles
intersect. A region interval is a subset of another if and only if its rectangle
is completely enclosed in the other's rectangle.
The region space perspective enables a rather elegant view of the region
relation operators, as shown in Figure 6.4. In the figure, the six fundamental
region relations (before, after, overlaps-start-of, overlaps-end-of, in,
and contains) are represented by shaded areas, such that every point
Y in the closed area labeled op satisfies Y op X.

|
Figure 6.4. Region space areas (relative to point
X) corresponding to the region relation operators.
|
A region set can be represented as a union of region intervals, which in
turn can be represented as a union of axis-aligned rectangles in region space.
The goal is a data structure representing a union of rectangles with the
following operations:
-
Create (P): create a union of rectangles from a set of rectangles
P
-
Union (R,S): combine two unions of rectangles R and S
-
Intersect (R,S): intersect two unions of rectangles R and S
-
Relation (op, R): generate a new union of rectangles by applying a
region relation operator op elementwise to R.
Ideally, these operations should take linear time and linear space. In other
words, finding the intersection or union of a collection of M rectangles
with a collection of N rectangles should take O(N+M+F) time
(where F is the number of rectangles in the result), and computing
a region relation on a collection of N rectangles should take
O(N) time. The data structure itself should store N rectangles
in O(N) space.
Research in computational geometry and multidimensional databases has developed
a variety of data structures and algorithms for storing and intersecting
collections of rectangles, including plane-sweep algorithms, k-d trees, quadtrees
of various kinds, R-trees , and R+-trees (see [Sam90] for a survey).
The LAPIS prototype uses a variant of the R-tree [Gut84]. The R-tree is a
balanced tree derived from the B-tree, in which each internal node has between
m and M children, for some constants m and M. The
tree is kept in balance by splitting overflowing nodes and merging underflowing
nodes. Rectangles are associated with the leaf nodes, and each internal node
stores the bounding box of all the rectangles in its subtree. The decomposition
of space provided by an R-tree is adaptive (dependent on the rectangles stored)
and overlapping (so nodes in the tree may represent overlapping regions).
To keep lookups fast, the R-tree insertion algorithm attempts to minimize
the overlap and total area of nodes using various heuristics. In one heuristic,
for example, a new rectangle is inserted in the subtree that would increase
its overlap with its siblings by the least amount. One set of heuristics,
called the R*-tree [BKSS90], has been empirically shown to be efficient for
random collections of rectangles. Initially the R*-tree heuristics were used
in the LAPIS prototype. The rectangle collections generated by text constraints
are not particularly random, however; they tend to be distributed
linearly along some dimension of region space, such as the 45-degree line,
the x-axis, or the y-axis. Overall performance was improved by a factor of
5 by storing the rectangles in the leaves in lexicographic order, eliminating
the expensive placement calculations without sacrificing the tree's logarithmic
decomposition of region space.
Two R-trees T1 and T2 can be intersected by traversing the trees in tandem,
comparing the current T1 node with the current T2 node and expanding both
nodes only if their bounding boxes overlap. Traversing the trees in tandem
has the potential for pruning much of the search, since if two nodes high
in each tree are found to be disjoint, the rectangles stored in their subtrees
will never be compared. In most cases, tandem tree intersection takes time
O(N+M+F). It will never do worse than O(NM + F). Tandem tree
traversal is effective for implementing set intersection, union, and difference.
The R-tree representation is also useful for highlighting region sets in
the document viewer. The viewer window displays only part of the document
at a time. Suppose we call this part of the document VisibleRegion.
By intersecting overlaps VisibleRegion with the region
set to be highlighted, the document viewer can quickly determine which regions
are actually visible, and render highlights only for those regions.
6.3 Performance
The LAPIS prototype is written in Java 1.1 using the Sun Java Foundation
Classes (JFC). The core text constraints engine is implemented in about 3500
lines of code. The web browser consists of about 1000 lines of code on top
of the JFC JEditorPane text component.
The text constraints engine can evaluate an operator at a typical rate of
20,000 regions per second, using Symantec JIT 3.0 on a 133 MHz Pentium. The
actual evaluation time of a text constraint expression varies according to
the complexity of the expression and the size of its intermediate results.
The text constraint expressions used in the examples were all evaluated in
less than 0.1 second, on text files and web pages ranging up to 80KB in size.
7 Evaluation
An important part of the proposed thesis will be evaluation of the system.
Evaluation will determine how well LAPIS satisfies its goals of making structure
description lightweight and usable.
Throughout its development, LAPIS will undergo informal user testing to refine
the user interface and pattern language. To get feedback from a wider audience,
LAPIS will also be released for general use. The initial prototype described
in this thesis proposal will be made public in May 1999.
Once LAPIS has been sufficiently developed, it will be tested with a two-part
formal evaluation. The first part of the evaluation will determine how LAPIS
compares to other text processing systems by measuring its performance on
several real, large, complex tasks, like the examples in the Scenarios section.
The tasks will be drawn from three domains: the World Wide Web, source code,
and plain text databases. The performance of LAPIS on each task will be evaluated
by various measures, including:
-
Structure description size: the minimum amount of input required to
describe a structure detector, counting pattern length, number of examples
for inference, and number of manual corrections. This measurement estimates
the level of human effort required to build the structure detector.
-
Processor time: CPU time spent searching for patterns, running external
parsers, and inferring generalizations from examples. This measurement estimates
the computer power needed to build and apply a structure detector.
-
Storage overhead: memory needed to store labeled region sets created
by structure detection, expressed as a fraction of the size of the documents
processed.
-
Labeling error: fraction of regions that are incorrectly labeled by
a structure detector, as a function of description size. This measurement
estimates the robustness of LAPIS detectors to variation and exceptions in
real data.
For the sake of comparison, the same tasks will be performed and measured
using other systems, where reasonable. Compared systems will include a text
editor with search-and-replace and keyboard macros (such as Emacs), a
text-processing language (such as Perl), and Unix pipe-and-filter tools.
The second part of the evaluation will test LAPIS with users in a small formal
study. Levels of text-processing experience differ widely among computer
users. Some users use essentially no automation, browsing and editing documents
by direct manipulation. Others are more comfortable with automated tools,
ranging from global search-and-replace, to keyboard macros, to shell utilities
and text-processing languages. I propose to test users with at least enough
automation experience to be comfortable using global search-and-replace.
In the study, participants will first receive a brief tutorial demonstrating
the structure detection mechanisms and tools available in LAPIS. Participants
will then perform a set of small but non-trivial tasks like the examples
in the Scenarios section, drawn from the Web and plain text databases. (The
third domain, source code, makes no sense for nonprogrammers.) The chosen
tasks will require building a custom structure detector for a document, then
applying generic tools to the detected structure.
The study will first determine whether nonprogramming users can solve the
tasks using LAPIS. Then, the participants' solutions will be used to evaluate
the novel aspects of LAPIS. Questions to be answered include:
-
Usability of text constraints: How easy is it to learn text constraints?
What errors do participants make in writing text constraints?
-
Integrated structure detection mechanisms: To what extent do participants
use patterns, inference, and manual selection? Do participants combine multiple
structure detection mechanisms? How do participants use each mechanism: for
exploring document structure? For describing new structure? For finding errors?
For correcting errors?
-
Presentation-level structure: Do participants use presentation structure?
Do participants prefer presentation structure or logical structure, when
a region set could be described either way? Do participants combine presentation
and logical structure in a single description?
The study will also collect the participants' subjective evaluations of LAPIS.
8 Related Work
A number of systems address text-processing tasks similar to LAPIS. The systems
described in this section are divided roughly into four domains: unstructured
(plain) text, structured text, web pages, and source code. These domains
certainly overlap. Tools designed for unstructured text are often applied
to structured text as well, and many tools designed for structured text can
be configured to process web pages or source code as special cases.
8.1 Unstructured Text
Automatic manipulation of plain text has a long, rich history. This section
will only survey the highlights, which can be divided into three classes:
programming languages, programmable text editors, and
programming-by-demonstration systems.
The oldest programming language specialized for text processing is probably
SNOBOL [GPP71], a string manipulation language with an embedded pattern language.
Its successor was Icon [GG83], which integrated pattern-matching more tightly
with other language features by supporting goal-directed evaluation. Another
family of text processing languages use regular expressions for pattern matching.
One example is Awk [AKW88], which implicitly iterates over the lines of a
text file, applying pattern-action rules to each line. Another is Perl [WS91],
which embeds regular expression matching in a general-purpose scripting language.
Other languages commonly used for text processing include Unix shell scripts
and tools [KP81], and the parser-generator tools Lex [Lesk75] and Yacc [John75].
Text-processing languages provide excellent performance and expressiveness,
but operate in a batch mode that lacks the ability to view pattern matches
in context and combine programmed patterns with interactive selection.
Programmable editors include Emacs [Stall81] and Microsoft Word [Mic97].
These editors provide two kinds of automation: keyboard macros which can
be recorded and replayed, and full-fledged programming languages with access
to editor commands. Sam [Pike87] combines an interactive editor with a command
language that manipulates regions matching regular expressions. Regular
expressions can be pipelined to automatically process multiline structure
in ways that line-oriented systems cannot. Unlike LAPIS, however, Sam does
not provide mechanisms for naming, composing, and reusing the structure described
by its regular expressions.
The last class of unstructured text processing systems are
programming-by-demonstration (PBD) systems. In most PBD systems, the user
demonstrates a task by manually editing examples, from which the system infers
a generalized program for transforming other instances of the same problem.
Systems that take this approach include EBE [Nix85], TELS [WM93], Cima [Mau94],
and DEED [Fuji98]. Another approach is found in Tourmaline [Myers93], which
infers formatting styles for headings, tables, bibliographic references by
generalizing from one example using domain-specific heuristics. Finally,
Visual Awk [LH95] transforms Awk into a visual programming language, preserving
Awk's implicit iteration over lines but representing regular-expression pattern
matching and text transformation with a graphical language. In general, PBD
systems have a shallow learning curve, since they draw on the user's prior
experience with manual text editing. However, users do not always trust the
system's inferences [Cypher93], and most PBD systems provide no way to verify
or correct the inferred program other than trying more examples. Most PBD
systems also strive for domain independence, which limits their effectiveness
on richly-structured text like web pages and source code. The inference features
in LAPIS will be able to take advantage of domain knowledge provided by other
structure detectors, such as external parsers.
8.2 Structured Text
A step beyond plain text are systems capable of recognizing, representing,
and processing document structure. These systems can be divided into roughly
four classes: markup languages, structure-oriented editors, structured text
query languages, and structure-aware user interfaces.
Markup languages, such as SGML [Gold92] and its successor XML [W3C96], are
a popular way to represent structured text. Markup languages use explicit
delimiters in the document to represent hierarchical structure. A separate
document type definition (DTD) defines the markup codes and specifies legal
combinations of markup. Most systems for automatic processing of SGML/XML
follow the pattern-action style of Awk, with implicit iteration over nodes
of the markup tree. Examples include OmniMark [Omni99], DSSSL [Clark96],
and XSL [W3C97]. These systems require explicit markup in the documents to
be processed, so source code and plain text cannot be processed.
Structure-oriented editors enjoyed a vogue in the 1980s, mainly for editing
programs, but also for editing other kinds of structured documents. Most
structure-oriented editors are configured with a structure description, typically
an augmented context-free grammar, which describes the transformation between
concrete syntax and abstract syntax. Examples of structure-oriented editors
include Emily [Han71], Gandalf [HN86], the Cornell Program Synthesizer [TTH81],
Grif [QV86], and MacGnome [MPMV94]. Structure-oriented editors enforce
consistency between a document and its structure description, so that generating
a syntactically incorrect document is impossible. Lightweight structured
text processing takes a different approach, recognizing and using structure
but not requiring it.
Structured text databases are an important application of structured text
processing. A variety of query languages have been proposed, including Proximal
Nodes [NBY95], GC-lists [CCB95], p-strings [GT87], tree inclusion [KM93],
Maestro [Mac91], and PAT expressions [ST92]. A survey of structured text
query languages is found in [BYN96]. Of particular interest is sgrep [JK96],
a variant of the grep searching tool that uses a structured text query
language instead of regular expressions. Sgrep inspired the idea of incorporating
other generic tools (like sort) into a structured text processing
system. The text constraints language in LAPIS borrows ideas from structured
text query languages, but unlike those languages, TC supports concatentation
of regions, arbitrary region sets (not just nested or nonoverlapping sets),
and unary region relation operators.
A recent trend in structured text processing are systems that use recognized
structure to trigger user interface actions. This category, which might be
called structure-aware user interfaces, includes Cyberdesk [DAW98],
Apple Data Detectors [NMW98], and LiveDoc [MBo98]. These systems resemble
LAPIS in architecture, with a collection of structure detectors for finding
structure (like email addresses and URLs) and a collection of actions that
can be performed on a piece of structure (like sending email or browsing
to a URL). LAPIS focuses more on the problem of creating structure detectors,
which was largely deferred by these systems.
Machine learning has offered some solutions to the problem of inferring structure
detectors from examples. Results obtained by Freitag [Frei98] and Kushmerick
et al [KWD97] show how to infer effective, lexical structure detectors
("wrappers") for structured text, including web pages and seminar announcements.
A PBD approach is found in the Grammex system [LNW98], which infers context-free
grammars from a few examples annotated by the user.
8.3 Web Pages
The enormous variety and volume of structured text on the Web has spurred
development of systems specialized to processing web content. These systems
generally fall into three categories: query languages, web crawlers, and
programming-by-demonstration systems. Web-specific systems may be more powerful
than LAPIS when operating on web pages, at the expense of flexibility in
other application domains.
Web query languages treat the Web as a database which can be queried. Queries
are usually expressed with a variant of SQL augmented with structure operators
(like in and containing) and hyperlink path operators. Examples
of SQL-based web query languages include HyQL [BD98] and WebSQL [AMM97].
A different kind of web processing language is WebL [KM98], which embeds
a structured text pattern language and web access primitives in a scripting
language.
Web crawlers are programs that fetch and process web pages by following
hyperlinks. Crawler development systems typically follow the pattern-action
style, with implicit iteration over web pages. Examples include WebSPHINX
[MBh98], MacroBot [IPG97], WebCutter/Mapuccino [Maar97], and the TkWWW robot
[Spet94].
Programming-by-demonstration has also been applied to the web domain. Some
web PBD systems learn how to extract parts of a web page based on examples.
Systems in this class include Turquoise [MM97], Internet Scrapbook [SK98],
and InfoBeans [BD99]. Another system, Live Agent [Agent98], infers a sequence
of browsing actions from the user's demonstration.
8.4 Source Code
Source code transformation systems fall into two categories: syntactic methods,
which operate on an abstract syntax tree, and lexical methods, which operate
on the program text directly.
Syntactic methods parse program text into an abstract syntax tree before
processing. Since parsing ordinarily discards some information from the program
(such as comments and indentation), syntactic systems must either take pains
to preserve this information in the syntax tree or be limited to applications
where this information is unimportant. C-to-C [Mil95] is a framework for
C extension language translators which addressed this problem, recording
extra information in its parse tree in order to generate more comprehensible
translations. ASTLOG [Crew97] is a Prolog-based pattern language for searching
(but not transforming) abstract syntax trees, which supports higher-order
patterns.
Lexical methods operate on the program text directly, or as a simple stream
of tokens. Lexical methods are not as accurate as syntactic methods, but
often simpler and faster, and transformations can be made on the program
text directly. In practice, lexical methods are usually ad-hoc solutions
using unstructured text processing systems like Awk, Perl, and Lex/Yacc.
An exception is the Lexical Source Model Extraction system [MN96], a
pattern-action rule system in which patterns are regular expressions over
program tokens and actions consist of Icon code.
9 Schedule
The planned schedule for completing the thesis is shown below.
| Implementation |
9 months |
| Evaluation, part 1 (tasks) |
3 months |
| Evaluation, part 2 (user study) |
3 months |
| Write-up |
3 months |
|
| Total |
18 months |
10 Conclusions
This thesis proposal introduces the concept of lightweight structured text
processing, in which the user creates and composes lightweight structure
detectors interactively, then manipulates the structure with generic
tools. The feasibility of lightweight structured text processing will
be demonstrated by a working implementation, LAPIS, which will be evaluated
with real tasks and real users.
LAPIS will make a number of contributions to the problem of making structure
detection more usable and lightweight:
-
a new pattern language, text constraints, that is designed to be simple,
readable, composable, robust, and expressive;
-
algorithms and representations for implementing text constraints with reasonable
efficiency;
-
techniques for detecting and using presentation structure as well as logical
structure;
-
a system architecture and document representation suitable for composing
and reusing multiple structure detectors simultaneously;
-
a user interface that integrates various ways of detecting structure: manual
selection, patterns, inference from examples, and external parsers; and
-
an implementation that combines all these techniques, shown to be usable
by formal testing.
Looking beyond text processing to other domains, this thesis may point to
new ways for users to customize general-purpose applications: by describing
structure detectors and applying generic tools to the structure. For example,
a video editor might describe credits, scenes, shots, and wipes. The hope
is that providing ways to describe structure interactively and reuse the
structure for different tasks will encourage users to do more tasks
automatically, helping users realize more of the power of programmable computers.
References
[Agent98] Agentsoft, Inc.
LiveAgent, 1998.
http://www.agentsoft.com/liveagent.html
[AKW88] A.V. Aho, B.W. Kernighan, and P.J. Weinberger. The AWK Programming
Language. Addison-Wesley, 1988.
[Allen83] J. Allen. "Time Intervals." Communications of the ACM, v26
n11, 1983, pp 822-843.
[AMM97] G. Arocena, A. Mendelzon, G. Mihaila.
"Applications
of a Web Query language." Proceedings of the 6th International WWW
Conference, Santa Clara, California, April 1997.
[BD98] M. Bauer and D. Dengler. "TrIAs -- An Architecture for Trainable
Information Assistants." AAAI98 Workshop on AI and Information
Integration.
[BD99] M. Bauer and D. Dengler. "InfoBeans -- Configuration of Personalized
Information Assistants." Proceedings IUI 99, pp 153-156.
[Bill95] P. Billingsley. "Hard Test for Soft Products." SIGCHI Bulletin,
v27 n1, January 1995, p. 10.
[BKSS90] N. Beckmann, H-P. Kriegel, R. Schneider, and B. Seeger. "The R*-tree:
an efficient and robust access method for points and rectangles." ACM
SIGMOD Intl Conf on Managment of Data, 1990, pp 322-331.
[Burd98] T. Burd.
General
Processor Information, 1998.
http://infopad.eecs.berkeley.edu/CIC/summary/local/
[BYN96] R. Baeza-Yates and G. Navarro. "Integrating contents and structure
in text retrieval." ACM SIGMOD Record, v25 n1, March 1996, pp 67-79.
[CB93] U.S. Census Bureau.
"Computer
Use in the United States: October 1993."
http://www.census.gov/population/www/socdemo/computer.html
[CCB95] C.L.A. Clarke, G.V. Cormack, and F.J. Burkowski. "An algebra for
structured text search and a framework for its implementation." The Computer
Journal, v38 n1, 1995, pp 43-56.
[Clark96] J. Clark. Document Style Semantics and Specification Language
(DSSSL). ISO/IEC 10179, 1996. http://www.jclark.com/dsssl/
[CMU99] Carnegie Mellon University Libraries.
WebCat online library
catalog, 1999. http://www.library.cmu.edu/cgi-bin/WebCat/
[Crew97] R. F. Crew. "ASTLOG: A Language for Examining Abstract Syntax Trees."
Proceedings of the USENIX Conference on Domain-Specific Languages,
Santa Barbara, California, October 1997.
[DAW98] A.K. Dey, G.A. Abowd, and A. Wood.
CyberDesk:
A Framework for Providing Self-Integrating Ubiquitous Software Services.
Proceedings IUI '98, January 1998.
http://www.cc.gatech.edu/fce/cyberdesk/pubs/IUI98/IUI98.html
[DiG96] C. J. DiGiano. Self-Disclosing Design Tools: An Incremental Approach
Toward End-User Programming. PhD Thesis, Department of Computer Science,
University of Colorado at Boulder, 1996. Available as technical report
CU-CS-822-96.
[DP80] D. Dubois, H. Prade. Fuzzy sets and systems : theory and
applications. Academic Press, 1980.
[Frei98] D. Freitag, "Multistrategy learning for information extraction."
Proceedings of ICML-98.
[Fuji98] Y. Fujishima. "Demonstrational Automation of Text Editing Tasks
Involving Multiple Focus Points and Conversions." Proceedings IUI 98,
pp 101-108.
[GG83] R.E. Griswold and M.T. Griswold. The Icon Programming Language.
Prentice-Hall, 1983.
[Gold92] C.F. Goldfarb. The SGML Handbook. Clarendon Press, 1992.
[GPP71] R.E. Griswold, J. F. Poage and I. P. Polonsky. The SNOBOL4 Programming
Language. Prentice-Hall, 1971.
[GT87] G.H. Gonnet and F.W. Tompa. "Mind your grammar: a new approach to
modelling text." Proceedings 13th VLDB Conference, 1987, pp 339-345.
[Gut84] A. Guttman. "R-Tree: a dynamic index structure for spatial searching."
ACM SIGMOD Intl Conf on Managment of Data, 1984, pp 47-57.
[Han71] W.J. Hansen. "User engineering principles for interactive systems."
AFIP Conference proceedings, Fall joint computer conference, 1971,
pp 523-532.
[HN86] N. Habermann and D. Notkin. "Gandalf: Software development environments."
IEEE Transactions on Software Engineering. v12 n12, December 1986,
pp 1117-1127.
[HU79] J.E. Hopcroft, J.D. Ullman. Introduction to Automata Theory, Languages,
and Computation. Addison-Wesley, 1979.
[IPG97] Information Projects Group, Inc.
MacroBot, 1997.
http://www.ipgroup.com/macrobot/
[JK96] Jaakkola, J. and Kilpelainen, P. "Using sgrep for querying structured
text files." University of Helsinki, Department of Computer Science,
Report C-1996-83, November 1996.
[John75] S.C. Johnson. "Yacc -- Yet Another Compiler Compiler." Computing
Science Tech. Rep. 32, AT&T Bell Labs, Murray Hill, NJ.
[KM93] P. Kilpelainen and H. Mannila. "Retrieval from hierarchical texts
by partial patterns." Proceedings SIGIR '93, pp 214-222, 1993.
[KM98] T.Kistler and H. Marais. "WebL -- A Programming Language for the Web."
Proceedings of WWW7, Brisbane, Australia, April 1998.
[KP81] B.W. Kernighan and P.J. Plauger. Software Tools in Pascal.
Addison-Wesley, 1981.
[KWD97] N. Kushmerick, D.S. Weld, and R. Doorebos. "Wrapper Induction for
Information Extraction." Proceedings of IJCAI-97.
[Lesk75] M.E. Lesk. "Lex -- a Lexical Analyzer Generator." Computing Science
Tech. Rep. 39, AT&T Bell Labs, Murray Hill, NJ.
[LH95] J. Landauer and M. Hirakawa.
"Visual AWK:
a model for text processing by demonstration." Proceedings 11th
International IEEE Symposium on Visual Languages '95, September 1995.
http://www.computer.org/conferen/vl95/talks/T32.html
[LNW98] H. Lieberman, B.A. Nardi, D. Wright. "Grammex: Defining Grammars
by Example." CHI 98 Conference Summary, pp 11-14.
[Maar97] Y. S. Maarek, et al.
"WebCutter:
A System for Dynamic and Tailorable Site Mapping." Proceedings of
WWW6, Santa Clara, USA, April 1997.
http://proceedings.www6conf.org/HyperNews/get/PAPER40.html
[Mau94] D. Maulsby.
Instructible
Agents. PhD thesis, Department of Computer Science, University of
Calgary. 1994. ftp://ftp.cpsc.ucalgary.ca/pub/users/maulsby/
[Mac91] I. MacLeod. "A query language for retrieving information from hierarchic
text structures." The Computer Journal, v34 n3, 1991, pp 254-264.
[MBh98] R.C. Miller and K. Bharat.
"SPHINX: A
Framework for Creating Personal, Site-Specific Web Crawlers."
Proceedings of WWW7, Brisbane, Australia, April 1998.
http://www.cs.cmu.edu/~rcm/www/papers/www7/www7.html
[MBF+97] B.A. Myers, E. Borison, A. Ferrency, R. McDaniel, R.C. Miller, A.
Faulring, B.D. Kyle, P. Doane, A. Mickish, A. Klimovitski.
"The
Amulet V3.0 Reference Manual." Carnegie Mellon University School of Computer
Science Technical Report CMU-CS-95-166-R2, and Human Computer Interaction
Institute Technical Report CMU-HCII-95-102-R2. March 1997.
[MBo98] J.R. Miller and T. Bonura. "From Documents to Objects: An Overview
of LiveDoc." SIGCHI Bulletin, v30 n2, April 1998, pp 53-58.
[McD98] R.G. McDaniel and B.A. Myers. "Building Applications Using Only
Demonstration." Proceedings IUI 98.
[Mic97] Microsoft Corporation. Microsoft Word 97.
http://www.microsoft.com/
[Mil95] R.C. Miller.
"A
Type-checking Preprocessor for Cilk 2, a Multithreaded C
Language." Master's thesis, MIT Department of Electrical Engineering
and Computer Science, May 1995.
ftp://theory.lcs.mit.edu/pub/cilk/rcm-msthesis.ps.Z
[MM97] R.C. Miller and B.A. Myers. "Creating Dynamic World Wide Web Pages
By Demonstration." Carnegie Mellon University School of Computer Science
Tech Report CMU-CS-97-131 (and CMU-HCII-97-101), May 1997.
[MN96] G.C. Murphy and D. Notkin. "Lightweight Lexical Source Model Extraction."
ACM Transactions on Software Engineering and Methodology, v5 n3, July
1996, pp 262-292.
[MPMV94] P. Miller, J. Pane, G. Meter, and S. Vorthmann. "Evolution of Novice
Programming Environments: The Structure Editors of Carnegie Mellon University."
Interactive Learning Environments, v4 n2, 1994, pp 140-158.
[Myers93] B.A. Myers. "Tourmaline: Text Formatting by Demonstration." In
A. Cypher, ed., Watch What I Do: Programming By Demonstration. MIT
Press, 1993.
[Myers97] B.A. Myers.
User Interface Software
Tools, 1997. http://www.cs.cmu.edu/~bam/toolnames.html
[NBY95] G. Navarro and R. Baeza-Yates. "A language for queries on structure
and contents of textual databases." Proceedings of SIGIR'95, pp 93-101.
[Nix85] R. Nix. "Editing by Example." ACM Transactions on Priogramming
Languages and Systems, v7 n4, October 1985, pp 600-621.
[NMW98] B.A. Nardi, J.R. Miller, and D.J. Wright. "Collaborative, Programmable
Intelligent Agents." Communications of the ACM, v41 n3, March 1998,
pp 96-104.
[Omni99] OmniMark Technologies.
OmniMark, 1999.
http://www.omnimark.com/
[ORO98] Original Reusable Objects, Inc.
OROMatcher, 1998.
http://www.oroinc.com/
[Pike87] R. Pike.
"The Text Editor
sam." Software Practice & Experience, v17 n11, Nov 1987, pp
813-845. http://plan9.bell-labs.com/cm/cs/doc/87/1-05.ps.gz
[PM93] R. Potter and D. Maulsby. "A Test Suite for Programming by Demonstration."
In A. Cypher, ed., Watch What I Do: Programming By Demonstration.
MIT Press, 1993.
[QV86] V. Quint and I. Vatton. "Grif: an interactive system for structured
document manipulation." Text Processing and Document Manipulation, Proceedings
of the International Conference, Cambridge University Press, 1986, pp
200-213.
[Sam90] H. Samet. The Design and Analysis of Spatial Data Structures.
Addison-Wesley, Reading, MA, 1990.
[SK98] A. Sugiura and Y. Koseki. "Internet Scrapbook: Automating Web Browsing
Tasks by Demonstration." Proceedings UIST 98, pp 9-18.
[Spet94] S. Spetka.
"The
TkWWW Robot: Beyond Browsing." Proceedings of WWW2: Mosaic and the
Web, 1994.
http://www.ncsa.uiuc.edu/SDG/IT94/Proceedings/Agents/spetka/spetka.html
[ST92] A. Salminen and F.W. Tompa. "PAT expressions: an algebra for text
search." UW Centre for the New Oxford English Dictionary and Text
Research Report OED-92-02, 1992.
[Stall81] R. M. Stallman. "EMACS: the extensible, customizable self-documenting
display editor." Proc ACM SIGPLAN SIGOA Symposium on Text Manipulation,
SIGPLAN Notices, v16 n6, 1981, pp 147-156.
[Sun98] Sun Microsystems, Inc.
JavaCC, 1998.
http://www.suntest.com/JavaCC/
[TTH81] T. Teitelbaum, T. Reps, and S. Horwitz. "The why and wherefore of
the Cornell Program Synthesizer." Proc ACM SIGPLAN SIGOA Symposium on
Text Manipulation, SIGPLAN Notices, v16 n6, 1981, pp 8-16.
[VZM+99] B.T. Vander Zanden, B.A. Myers, P. Szeleky, D. Giuse, R. McDaniel,
R. Miller, R. Halterman, D. Kosbie.
"Lessons Learned About
One-Way, Dataflow Constraints in the Garnet and Amulet Graphical Toolkits,"
in preparation, 1999. http://www.cs.utk.edu/~bvz/constraints.pdf
[W3C96] World Wide Web Consortium.
Extensible Markup Language (XML),
1996. http://www.w3.org/XML/
[W3C97] World Wide Web Consortium.
Extensible Stylesheet Language
(XSL), 1997. http://www.w3.org/Style/XSL/
[WM93] I. H. Witten and D. Mo. "TELS: Learning Text Editing Tasks from Examples."
In A. Cypher, ed., Watch What I Do: Programming By Demonstration.
MIT Press, 1993.
[WS91] L. Wall and R.L. Schwartz. Programming Perl. O'Reilly &
Associates, 1991.
[Yahoo99] Yahoo! Inc. Yahoo!,
1999. http://www.yahoo.com/