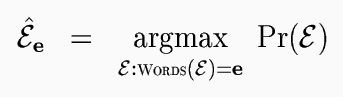
Committee:
John Lafferty, Chair
Daniel Sleator
Jaime Carbonell
Michael Collins (MIT)
The final version is available in a variety of formats:
[text abstract]
[1-sided gzipped postscript]
[2-sided gzipped postscript]
[1-sided PDF]
[2-sided PDF]
Statistical methods are effective for many natural language processing tasks, including automatic translation and parsing. This thesis brings these two applications together in two ways, using translation to aid parser construction and using parsing to improve translation quality. This is made possible by a statistical model of syntactic structure and a statistical model of the relationship between the syntax structures of two languages.
To parse a sentence is to resolve it into its component parts and describe its grammatical structure. This analysis is prerequisite to many tasks involving human language, both because a significant part of the meaning of a sentence is encoded in its grammatical structure (as opposed to the lexical selection), and because models that ignore structure are insufficient to distinguish well-formed from ungrammatical utterances. Applications that benefit from syntactic parsing include corpus analysis, question answering, natural-language command execution, rule-based automatic translation, and summarization.
Many parsers work based on rules of grammar inferred through linguistic study. However, these rules are often too rigid to accommodate real-world utterances, which often bend the rules of ``correct'' grammar in creative ways, or include minor errors, but are still easily comprehensible by human listeners. Also, many sentences are structurally ambiguous according to grammar rules, but easily disambiguated by human listeners. In these cases, correct analysis may require lexical and distributional knowledge not found in hand-crafted grammar rules. Instead of attempting to encode this knowledge manually, which would be far too difficult, researchers have turned to corpus-based statistical techniques, in which lexical and distributional knowledge is gathered from large corpora of real human-generated sentences. In addition to increased accuracy, statistical parsers tend to exhibit greater robustness in dealing with unusual utterances, which would cause a more strictly rule-based parser to fail. They also have the advantage of being easier to build and to customize, because they do not require the work of a language expert to carefully design a grammar and patiently encode a dictionary. Instead, given an appropriate framework, all but the most basic grammar rules can be learned automatically from data, resulting in a huge savings in time and effort, especially if an existing parsing system is being ported to a new language or domain.
To train a statistical parser requires large quantities of annotated data. Typically, the training data must consist of real sentences annotated with structural information of the kind the parser will eventually generate. Unfortunately, annotating these sentences can require a huge amount of work by language experts, comparable to that required to develop a rule-based grammar. However, if a rule-based parser already exists for a given language, it can be used to automatically annotate real sentences, which can then be fed into a statistical parser. Thus a rule-based parser can be parlayed into a new parser with all the advantages of a statistical technique, without the need for a language expert.
Training a parser on the output of another parser is likely to be somewhat of a controversial idea, because some of the knowledge encoded in the handcrafted grammar will likely be lost in the transfer, which could result in a statistical parser that is less accurate than the rule-based parser from which it was trained. However, this technique has several advantages. Statistical parsing is more robust than rule-based methods, and can respond to difficult inputs with graceful degradation rather than sudden failure. This is not to say that there are no rule-based ways of increasing robustness, but that it comes naturally with statistical methods. Secondly, the use of real sentences in training actually adds information to the system, enabling to make use of lexical and distributional knowledge ignored by the original rule-based system, which is especially useful in ambiguous cases. Even if the original parser is not always correct when generating training examples from ambiguous sentences, a large amount of training data should allow the statistical parser to overcome the noise and learn the patterns that occur most often. A third advantage of this technique is its versatility. Training data for a statistical parser could come not only from a single existing parser, but from various sources, if desired. For example, a few hand-coded examples could be added to introduce a new grammatical construct not found in the original parser, or the output of two or three parsers with different strengths and weaknesses could be combined to produce a new parser that combines their strengths.
When a parser is needed for a language in which no parser is yet available, the choice between carefully designing a rule-based parser or tediously annotating large amounts of data by hand in order to train a statistical parser is rather unappealing, since either approach requires a large amount of work by a language expert. However, perhaps bilingual resources can come to the rescue by enabling us to automatically annotate foreign sentences to use as training data for a new parser. If the relationship between the structure of the foreign language and a language for which a parser exists, such as English, can be systematically understood, then the structures generated by the English parser can be transferred over to the new language across an aligned bilingual corpus, resulting in a corpus of syntactically-analyzed sentences suitable for training a statistical parser in the new language. In order for this to work, we will need a model of the relationship between the syntactic structures of the two languages, and an unsupervised learning technique to train the model based on a bilingual corpus where we only know the syntactic structure of one of the two languages. If a technique can be found to infer the structure of a given foreign sentence given the words and structure of its English translation, then the resulting foreign sentence structures can be used to automatically train a new parser for the foreign language in which no parser was previously available, without the need for language experts to design grammar rules or annotate data.
Since ancient times, the ability to translate from one language to another has been valued. Automatic translation is now a reality, though for open-domain translation, automated systems cannot yet come anywhere near a bilingual human in quality. Corpus-based statistical methods currently dominate machine translation research, because it is just too difficult to write rules that capture all the complexities of actual utterances, while relatively simple statistical models have brought systems a long way toward comprehensible translation.
However, the models used in most statistical translation systems are much too simple to capture to syntactic structure of each sentence, often resulting in output that is ungrammatical or has the wrong meaning. Because important information is carried not only in the choice of words, but in their grammatical relationships, it is necessary to incorporate syntactic structure into translation models in order to meaning to be conveyed accurately and grammatically.
In this thesis, two new techniques are presented and then applied together in two different ways. First, a new statistical parser is presented. This parser, titled Lynx, is trained from sentences annotated automatically by another parser, and achieves results comparable to the original parser. Second, a statistical model of the relationship between the syntactic structure of two languages is presented, along with an unsupervised training algorithm, titled LinkSet. Putting these two parts together, we then go on to demonstrate two applications. First, we automatically induce a parser for a foreign language across a bilingual corpus. Then we improve the output of an automatic translation system by incorporating syntactic structure into its translation and language models.
My thesis statement has 4 parts:
This section gives a high-level theoretical overview of the models developed throughout this thesis. Beginning with the structural model of English sentences used in the Lynx parser we then introduce the model of the relationship between English and a foreign language used in the LinkSet bilingual parser. Then the combination and application of these two models to the induction of a new foreign-language parser and to an automatic translation system are outlined.
The Lynx parser uses a generative model Pr(E) of a structured English sentence E, a syntactic tree structure including words and labels. Parsing a given English sentence string e is the same as finding the most likely tree that yields the same surface string.
The model Pr(E), which assigns a probability to any structured English sentence, is recursively structured, breaking down the sentence structure into subtrees, and conditioning the probability of each node on the properties of its parent and immediately adjacent sibling (if any). Once it has been trained on annotated English sentences, this model can be used for parsing by searching the space of structures possible for a given sentence for the one to which the model assigns the highest probability.
When a structured English sentence is given along with its translation into a foreign language, their relationship can be modeled using the LinkSet structured translation model, which is a generative model Pr(F|E) of the transformation of a structured English sentence into a structured foreign sentence. This structured translation model, which models the probability of a given foreign sentence tree F given an English sentence tree E, is used by the LinkSet bilingual parser to find the most likely structure for a given foreign sentence f, when the words and structure of its English counterpart are known.

In principle, these models of English sentence structure and of foreign sentence structure given English sentence structure can be composed to generate a model of foreign sentence structure Pr(F), which can then be used to parse foreign sentences monolingually. The probability of a foreign sentence structure can be defined in terms of the model of English structure Pr(E) and the model of foreign structure given English structure Pr(F|E).
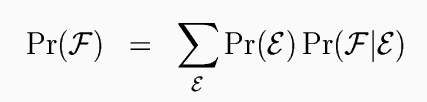
As it is given here, the probability of F is impractical to compute, since it requires summing over all (infinitely many) English structures. However, it can be approximated. Once we build a model of foreign structure, we can parse foreign sentences the same way we do English:
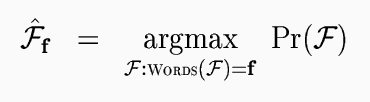
Composed differently, the monolingual English structure model Pr(E) and the structured translation model Pr(F|E) can in principle be used for translation, that is to find the most probable English rendering of a given foreign sentence. Following the noisy-channel interpretation of statistical translation that has become standard, we pretend that the foreign sentence f is a transformed version of some ``original'' English sentence e. To translate, we simply ``decode'' the foreign signal by finding the English string e most likely to have generated the foreign string f.
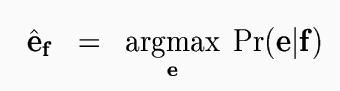
Using Bayes' rule, we can turn this around and factor out the Pr(f) that would appear in the denominator, since it does not depend on e. Then translation from a foreign language into English requires only an English language model Pr(e) and a model Pr(f | e) of translation from English to the foreign language.
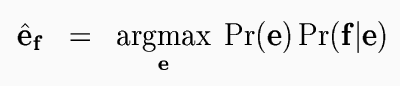
So far we have described translation of sentence strings, ignoring syntactic structure. We can incorporate our structured models of English and of the relationship between English and a foreign language by summing over all foreign structures that are consistent with the foreign string we are translating, and over all English structures.
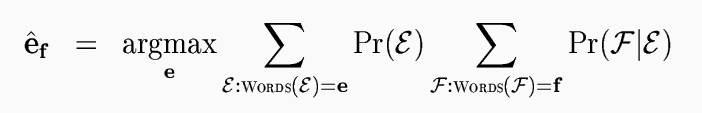
With this combined model, the best translation of a foreign sentence f can in principle be found. In practice, the sum over all English structures and over all foreign structures consistent with the given foreign sentence is infeasible to calculate. However, an approximation can enable translation hypotheses to be scored and reranked at a reasonable computational cost.
The overview above serves as an outline of this thesis. We will first introduce a model of English sentence structure, along with a method for using it to parse English sentences. Using training data derived from an existing parser, we will train the model, and then test this new statistical parser by comparing its ability to bracket sentence constituents with that of the other parser, as measured against human-annotated bracketings. Then we will introduce a model of foreign sentence structure given English sentence structure, along with an unsupervised learning technique. Training this model with a bilingual corpus, we will test its ability to align sentences by comparing the most probable alignments according to the model, as compared to human-annotated alignments. Finally, we will use these models together in two different ways. First, we will compose them to generate a stand-alone model of foreign sentence structure, which we will then use to parse foreign sentences. We will test this new parser by comparing its accuracy in bracketing unseen foreign sentences with respect to human-annotated bracketings. Second, we will enhance an automatic translation system by using these structured models to reevaluate the hypotheses it generates, comparing the resulting translations against the original system's output using standard evaluation metrics such as the BLEU and NIST scores. Along the way, we hope to gain insight into how and why to integrate syntactic structure into statistical models of natural language.
After training the Lynx parser on about 280k sentences of Wall Street Journal text annotated automatically by the Link parser, we tested both parsers against each other for precision and recall of constituent bracketing with respect to hand-annotated WSJ sentences from the Penn Treebank in a 10-fold cross-validation experiment. The results are shown in this table, which shows the number and percentage of sentences for which the method in each column beats the method in each row.
| Link | Lynx | Hybrid | Oracle | |
|---|---|---|---|---|
| Link | 30% | 10% | 30% | |
| Lynx | 30% | 23% | 30% | |
| Nulls | 7% | 20% | 27% |
The Lynx parser analyzes sentences for syntactic structure by finding the most probable structure consistent with the given text, according to a statistical model of structured sentences. The model is trained from examples. Because it is expensive to annotate examples by hand, we used an existing parser to analyze sentences collected from news articles, and used its output as training data. Although this automatically-generated training set has significantly more errors than one would expect from a hand-labeled training set, the Lynx parser is able to score as well as the Link parser at constituent bracketing. In one experiment the Lynx parser achieved an F1-score better than or equal to the score achieved by the Link parser on 70% of the sentences, and the mean scores are very close. This shows that the Lynx parser compares favorably with an established parser, which is good. However, this result is made more meaningful by the observation that the Link parser is the source of all the training data for the Lynx parser. That is, everything the Lynx parser knows about English grammar, it learned from the Link parser, with the exception of the very general principles implicit in the model's framework.
Admittedly, the Lynx parser does not score better than its source of training data, only about the same. However, on 30% of the sentences evaluated, the Lynx parser scores better than the Link parser, showing that it actually does have a significant improvement in the ability to parse some sentences, offset by inferior performance on some other sentences. Another way of looking at the difference between the two parsers is to predict the score that would result if both cooperated. If a highly accurate selector could be trained to choose which parser has a better analysis of each sentence, a gain of almost 5 percentage points is possible.
Why is the Lynx parser able to score better than its source of training data on so many sentences? There are several reasons, but the most obvious is that statistical parsing offers a significant advantage in robustness over rule-based parsing. In the rule-based Link parser, any constructions not anticipated by the designers of the grammar can only be covered through null links. There is a sharp dividing line between what is considered grammatical and what is not, which can cause sentences with a missing word to be analyzed strangely or not at all. A statistical parser such as Lynx, on the other hand, does not have a division between grammatical and ungrammatical sentences, but only a probability distribution. Thus when confronted with a sentence that would be considered ungrammatical by a more rigid grammar, a stochastic syntax model simply assigns a lower score, nevertheless selecting the structure most probable under the circumstances. This generalization yields a great increase in robustness, allowing performance to degrade gracefully on more difficult sentences.
Although all the data used to train the Lynx model was generated by the Link parser, the sentences which the Link parser parsed for this purpose were real sentences, constituting new input to the system. One of the reasons the Lynx parser is able to do so well is that it gains the benefit of the grammatical and distributional knowledge implicit in the sentences used for training, even though the analysis of these sentences by the Link parser is fallible. Most of the errors made by the Link parser when generating training data are compensated for by the large amount of data. While this training is a fully automated process, given a human-generated but unannotated text corpus (a plentiful resource), it is a semi-supervised learning process because the explicit grammar knowledge exercised by the Link parser acts as a kind of supervisor. The combination of this explicit grammar knowledge with real data contains more information than either alone.
In order to create a parser for a language in which no parser is available, without requiring extensive labor by a language expert to either design a grammar or annotate a corpus, it would be very useful to be able to infer the syntactic structure of foreign sentences. When given a bilingual corpus where a parser is already available for the opposite language (such as English), this could be done in principle by word-aligning the corpus and ``copying'' the structure across the alignments. Of course, figuring out the details of how this ``copying'' would take place could be quite tricky, or even impossible, since alignments are not always one-to-one.
In order to build a statistical translation system that accurately models the hierarchical structure of natural language, it would be very useful to be able to train a model of a structured foreign sentence given a structured English sentence. This would require designing a model capable of capturing the relevant features of the relationship between structures in two languages. Even when given a bilingual corpus in which structures are available for both languages, training such a transformational model might not straightforward, because the relationship between the structures would have to be defined in a way that could be modeled. Such corpora are not usually available anyway, especially if the two languages must be annotated using the same formalism.
Putting these two problems together, we need a way to infer the structure of a given foreign sentence (with no previous knowledge of the foreign language), given an English translation and its structure; and we need a way to train a transformational model that generates the foreign structure given the English structure. Solving these would allow us to build both a parser for the foreign language and a statistical translation system between that language and English that takes into account the syntactic structure of each sentence.
The LinkSet bilingual parser solves both of these problems together by simultaneously inferring the structure of foreign sentences, based on their English counterparts, and training a model of how the English sentences' structure must be transformed to produce the inferred foreign structures. A key insight that led to the design of LinkSet was the idea that inferring the structure of a foreign sentence given a structured English sentence is like parsing the foreign sentence using a specialized grammar, a grammar constrained by the deep structure of the English sentence, rather than by the specific grammar rules of either language. The exact definition of this specialized grammar is conceptualized as a series of transformations applied to the English structure to arrive at the foreign structure. These transformations constrain the range of structures considered possible for the foreign sentence. Then word-to-word translation probabilities to generate the actual foreign sentence from the transformed English one assign a probability to each possible structure, allowing the most probable to be selected. Furthermore, the transformations themselves can each have a probability model. To train this transformation model, an EM approach can be used, updating the likelihood of each transformation according to the probability of each sentence structure that uses it. In addition to improving the quality of foreign structures inferred, this transformational model can then be used in a translation system. Since for any sentence pair many structures are possible under the constraints of LinkSet's transformational model, bilingual parsing is a kind of unsupervised learning, using a large corpus of real data and some basic assumptions about the similarity of structures between languages to infer both the most likely structures of individual sentences in a foreign language and the relationship between the structures of the two languages.
The probability Pr(F|E) of generating a structured foreign sentence given a structured English sentence can be expressed as the probability of passing the English sentence tree through certain transformations and finding the foreign sentence tree as a result. Each major node of the tree passes through the following transformations recursively, starting with the root.
The probability of a foreign sentence tree given an English sentence tree is the product over all nodes in the English tree of the probabilities of applying these transformations in a way that results in the foreign sentence tree.
After implementing a ``bilingual parser'' based on this model, we trained it for three language pairs and tested its ability to word-align parallel texts. A summary of four experiments is shown in the table below, which is a cross-linguistic comparison of alignment results, showing F1-scores for the baseline, the best LinkSet configuration, and the oracle, where the portion of the space between the baseline and oracle claimed by LinkSet is shown as ``improvement.'' In all four cases, the LinkSet bilingual parser was able to align the words of bilingual sentence pairs significantly better than a baseline technique which took the most probable alignment according to the word-translation model without any structural information.
| Romanian | Chinese | French | French | |
|---|---|---|---|---|
| sentences | 13 | 183 | 65 | 484 |
| baseline | 45.8% | 59.7% | 54.6% | 44.3% |
| LinkSet | 50.4% | 65.4% | 67.6% | 49.2% |
| oracle | 72.3% | 88.0% | 91.1% | 82.6% |
| improvement | 17.4% | 20.1% | 35.6% | 12.8% |
Because the LinkSet Bilingual Parser is an intermediate step leading to monolingual parsers for other languages, and to structured transformation models for translation, evaluating it directly in terms of word-to-word alignment fails to fully describe its effectiveness. However, it seems reasonable to expect that the usefulness of the models trained using LinkSet would be limited by its ability to assign meaningful correspondences between the English and foreign versions of a training sentence.
Natural language parsers, which analyze human-language sentences, are useful for a wide variety of tasks, including (but not limited to) dialog, translation, classification, and corpus adaptation. Unfortunately, parsing is a hard problem, and constructing a new parsing system that works reasonably well typically requires a large effort by language experts, either in designing a grammar or in annotating training data. However, by training the Lynx parser ) using data annotated automatically by the LinkSet bilingual parser, a quick-and-dirty parser can be constructed with minimal effort and without much need for language expertise. Incremental improvements can then be made by addressing the various deficiencies of the resulting monolingual parser.
To test this ability to quickly build a working parser for a foreign language, we used two bilingual corpora (French--English and Chinese--English) to automatically build monolingual parsers for French and Chinese. We then tested these parsers by parsing test sets in each language, and comparing the structures assigned by the new parsers against hand-bracketings of the same test sentences.
| baseline | Lynx | improvement | |
|---|---|---|---|
| English | 68.2% | 92.3% | 36% |
| Chinese | 36.4% | 43.9% | 21% |
| French | 76.0% | 78.4% | 3% |
A summary of experimental results is shown in the table above, which compares the Lynx bracketing score in each language against the corresponding right-branching baseline score. Each score is the F1 combination of precision and recall, and the improvement is the margin by which Lynx does better than the baseline.
Unsurprisingly, the English version of the parser is most able to exceed the performance of its baseline. Although the Chinese version does not achieve a very impressive score, it does reasonably well, making a significant improvement over its baseline. The French version, on the other hand, is almost the reverse of the Chinese: While failing to improve very much over its baseline, it does quite well overall, with high precision and recall. The French baseline scores higher than the English baseline, perhaps because the French sentences are more consistently right-branching than English or Chinese, or perhaps because the hand-annotator favored right-branching interpretations of the sentences.
To our knowledge this is the first demonstration by anyone of a monolingual parser being induced across a bilingual corpus. (Others have induced more basic text analysis tools.) No knowledge was used except for the sentence-alignment of the corpus and the original English parser; given these resources, the building of a foreign-language parser was completely unsupervised.
In this unsupervised-learning setting, it came as somewhat of a surprise that EM training was unable to improve the quality of the induced parsers beyond their original levels. In some sense it could be considered a relief, considering the huge computational cost involved. However, perhaps a better EM technique would yield improvement, since our EM training was a fairly crude approximation of the ideal parameter estimation method, with sentence-level rather than feature-level granularity. A related improvement would be to use the entire lattice generated by the LinkSet bilingual parser for each sentence, rather than just the most probable sentence found within it. While this would probably increase computational and memory requirements, a cleverly integrated system could probably accomplish this kind of training without massively increasing the (already quite high) processing burden for training. Such a system would probably give better results; whether they would be significantly better is hard to say without having time to actually do the experiment.
Our case study on the French negation phrase (ne...pas) focuses on one such mismatch. In the original formulation, the LinkSet model was unable to account for this phrase properly, because of its one-to-one alignment model. While the LinkSet model can, through the use of null links, deal reasonably well with contiguous multi-word phrases aligned to single words in the other language, a non-contiguous phrase presented a problem. Because the LinkSet parser was unable to correctly align this phrase, part of the phrase was incorrectly aligned each time it appeared in the training data, resulting in an incorrect model of the phrase in the French Lynx parser. However, we were able to address this problem fairly easily by narrowing the overly broad word-translation model for those specific words and by allowing some English words to effectively align to more than one foreign word.
The problem of discontiguous many-to-one alignment is quite general and may be at the root of many misaligned phrases. Therefore this case study is not just about one difficult phrase, but about a whole class of mappings between languages that many alignment techniques are unable to handle. While many translation systems use phrase-to-phrase alignment, these approaches typically deal only with contiguous phrases. As our experiment shows, a simple extension to the LinkSet model can enable it to handle discontiguous phrases. (While a relatively straightforward extension of the LinkSet model, it is still significant enough a change to be implemented with a quick fix to the existing code base; hence the narrowly focused experiment.) Making this modification to LinkSet in general would probably be a significant step forward, but undoubtedly some tricky mismatches would remain. However, our case study suggests that for any particular language pair, progress could quickly be made from a quick and dirty induced parser to a higher-quality parser through focused incremental improvements such as the one we have demonstrated.
In order to economically test the efficacy of the syntax-based Lynx and LinkSet models in a translation system, we use the models to assign scores to the translation hypotheses generated by a state-of-the-art statistical translation system. Using these scores, we can rerank the hypotheses and select the best one according to the new models. This method allows various models to be compared on the translation task without requiring a whole new translation system to be built each time. However, it does have one major drawback: when the new models are used to rerank the hypotheses generated by another system, they are limited to selecting the best translation generated by that system, even if the new model would have assigned a higher score to a better translation never generated by the base system. Thus, a reranking approach will tend to underestimate the potential of a new model because its range of outputs is artificially constrained. On the other hand, a reranking experiment is a good first step in evaluating new models for translation, because of its relatively low cost. If a model will not work well, we would want to discover that fact before investing months of effort in building a new translation decoder. If a reranking experiment shows that a new model has good potential, the effort of building a decoder that can take advantage of its strengths may then be justified.
A translation system that uses the Lynx and LinkSet models to rerank hypotheses works like this:
To test this idea, we trained the Lynx and LinkSet parsers using a Chinese--English corpus, and used an existing statistical translation system to generate 100-best lists of English translations for another corpus of Chinese sentences, for each of which four reference translations were available. We reranked the translation hypotheses using scores from Lynx and LinkSet, and evaluated the improvement in translation quality using a variety of measures.
For each sentence, sorting the 100 translation hypotheses by score yields a hypothesis ranking. We ranked the hypotheses according to the original decoder score, the Lynx score, the LinkSet score, and by combinations of these scores. As a point of comparison, we also ranked the hypotheses according to their NIST scores with respect to the reference translations. To evaluate the system-generated rankings, we measured the rank-order distance between each system's ranking for each sentence and the corresponding rankings given by BLEU score and by NIST score. We used the Kendall rank correlation (τ) as a measure of agreement between rankings; this distance is the number of adjacent pairs that must be swapped in order to bring the rankings into agreement. Because the rankings are defined through sorting a list of scores, any sets of identical scores will yield partial orderings; this is not a problem for this distance metric.

The figure above shows the average distance between the rankings of various systems and the NIST-score ranking, grouped by sentence length. The sentences were grouped by length into bins of width five. Six different system combinations were compared: the original decoder score, the Lynx score, both of these together, and each of these three with the LinkSet score. For these experiments, each system was weighted equally. Additional trials, in which varying weights were used for each system, gave almost identical results. In this graph, three distinct lines are visible, the top (worst) one representing the decoder alone, the next one representing the decoder plus LinkSet, and the bottom (best) line representing the rest of the system combinations, which all have very similar results. All of these best combinations include the Lynx score. This chart shows that among these systems, the Lynx score is the best approximation of the ranking given by the NIST scores, and that no combination of systems significantly outperforms the unadorned Lynx score. However, the combination of all three systems does slightly better than the Lynx score alone. Meanwhile, the LinkSet score is able to bring a small improvement when added to the decoder score, but not as much as the Lynx score. For long sentences, especially those 80 words and longer, the lines converge. This happens because we were unable to get Lynx and LinkSet scores for the longest sentences due to the computational constraints mentioned above. The steady decline in quality as sentences get longer, clearly visible on the chart, is probably caused by a corresponding decline in Lynx parser accuracy caused by the combination of the increased complexity of parsing longer sentences and the effect of time-outs cutting short the search for the best parse according to the Lynx model.
Our experiments have shown that scores assigned by the Lynx and LinkSet parsers to translation decoder output can produce a significant improvement in the ranking of the hypotheses over the decoder's original ranking. However, when only the number-one hypothesis is taken into account, no significant gains were made in the end-to-end performance of the translation system. Advancing this edge is a very hard problem, especially when we confine ourselves to the space between current system performance and the best performance possible through reordering the hypotheses the decoder currently produces.
The main point of this work has been the integration of syntactic structure into the statistical models used in translation --- both monolingual language models and models of translation from one language to another. Through the development of the Lynx and LinkSet models and parsers, we have taken a big step in that direction, and shown that adding models of syntactic structure can improve the output of a state-of-the-art statistical translation system. In the future, we hope to see systems that continue in this direction to combine the best of both the theory-based and statistical worlds, using statistical models carefully crafted to capture all the features linguistic theory tells us are relevant, constrained enough to be trained on a reasonable amount of data, and general enough to apply to a broad range of languages and domains.
Here is a concise summary of the conclusions detailed in the chapters above:
These are the main contributions of this thesis:
Taking a step back from the details of this thesis, we can see a theme running throughout: incorporating syntax into generative models of human language, which is just a special case of a more general theme: combining knowledge with statistical models. In this thesis we incorporated linguistic knowledge into statistical models of language structure and of the relationship between different languages' structures. The linguistic knowledge appears in the guise of model structure and of the selection and dependencies of model parameters. That is, theory guides the construction of models so that they can capture the phenomena the theory tells us are relevant. An alternate way of combining knowledge with statistical modeling is to incorporate plenty of small statistical models into what is structurally a knowledge-based system, which could also be pictured as a rule-based system in which statistical models govern the application of each rule. Such approaches that give more explicit attention to rules may be more appropriate for certain applications, especially those in which the rules can be easily expressed. Our approach, which implicitly incorporates knowledge into the design of an over-arching statistical model, is in many ways more elegant because it has a simple probabilistic interpretation and is very flexible in its ability to be trained on new data without special programming. However, it can sometimes be difficult to modify such a model to capture phenomena previously missed, or to make sure it does not suffer too much from the complexity that requires too much time, space, and training data to be useful.
In order to enable computers to handle the complexities of natural language, and of many other phenomena as well, we need the combined power of theoretical knowledge and real-world statistics. Creating tools to bring these together should pay off not only in natural language processing, but in a variety of fields.
Copyright 2003 Peter Venable