The second part,
We begin by defining the ratio of the normalized moments.
Proof:Let ![]() ,
, ![]() , and
, and ![]() be the (cumulative) distribution functions
of
be the (cumulative) distribution functions
of ![]() ,
, ![]() , and
, and ![]() , respectively. Then, there exists
, respectively. Then, there exists ![]() such that
such that
![]() .
Therefore, by definition,
.
Therefore, by definition,
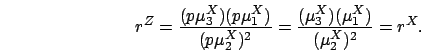
Below, unless otherwise stated, we denote
the (cumulative) distribution function of a distribution, ![]() , by
, by ![]() .
Below, we use the notation
.
Below, we use the notation ![]() repeatedly.
repeatedly.
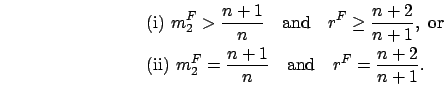
To show
![]() , consider an arbitrary
distribution,
, consider an arbitrary
distribution,
![]() . By definition
of
. By definition
of
![]() , there exists an
, there exists an ![]() -phase acyclic
PH distribution,
-phase acyclic
PH distribution, ![]() , that well-represents
, that well-represents ![]() . Then
. Then
![]() iff
iff
![]() . Hence, it suffices to prove that all
. Hence, it suffices to prove that all
![]() -phase acyclic PH distributions are in
-phase acyclic PH distributions are in
![]() .
This can be shown by proving the two properties of the Erlang-
.
This can be shown by proving the two properties of the Erlang-![]() distribution: (i) the set of Erlang-
distribution: (i) the set of Erlang-![]() distributions has
the least normalized second moment
among all the
distributions has
the least normalized second moment
among all the ![]() -phase (acyclic) PH distributions and (ii) the Erlang-
-phase (acyclic) PH distributions and (ii) the Erlang-![]() distribution has the least
distribution has the least ![]() -value among all the
-value among all the ![]() -phase acyclic
PH distributions. Note that the
Erlang-
-phase acyclic
PH distributions. Note that the
Erlang-![]() distribution,
distribution, ![]() , has
, has
Our approach is different from Aldous and Shepp [5]
and O'Cinneide [142]. Aldous and Shepp prove the least
variability of the Erlang-![]() distribution via quadratic variation (a
property related to the second moment), and hence it is unlikely that
their approach can be applied to prove property (ii), which relies on higher moments, in
particular the
distribution via quadratic variation (a
property related to the second moment), and hence it is unlikely that
their approach can be applied to prove property (ii), which relies on higher moments, in
particular the ![]() -value.
O'Cinneide extends the work by Aldous and Shepp,
considering a convex function,
-value.
O'Cinneide extends the work by Aldous and Shepp,
considering a convex function, ![]() , applied to a random variable
having an
, applied to a random variable
having an ![]() -phase PH distribution with a fixed mean.
He proves, via the theory of majorization, that the expectation of
-phase PH distribution with a fixed mean.
He proves, via the theory of majorization, that the expectation of ![]() is minimized
when the random variable
is minimized
when the random variable ![]() has an Erlang distribution.
Unfortunately, the
has an Erlang distribution.
Unfortunately, the ![]() -value of a distribution,
-value of a distribution, ![]() , is not
an expectation of
, is not
an expectation of ![]() , where
, where ![]() is a random variable with distribution
is a random variable with distribution ![]() , for a convex function
, for a convex function ![]() .
Hence, the theory of majorization does not directly apply to the
.
Hence, the theory of majorization does not directly apply to the ![]() -value.
-value.
Our proof makes use of the recursive structure of PH distributions and
shows that an ![]() -phase Erlang distribution has no greater
-phase Erlang distribution has no greater ![]() -value
than any
-value
than any ![]() -phase acyclic PH distribution.
The key idea in our proof is that any acyclic PH distribution,
-phase acyclic PH distribution.
The key idea in our proof is that any acyclic PH distribution, ![]() ,
can be seen as a mixture of the convolutions of exponential distributions,
and one of the convolutions of exponential distributions has no greater
,
can be seen as a mixture of the convolutions of exponential distributions,
and one of the convolutions of exponential distributions has no greater ![]() -value than
-value than ![]() .
This allows us to relate the minimal convolution to an Erlang distribution
when all the rates of the exponential distributions are the same.
The following lemma provides the key property of the
.
This allows us to relate the minimal convolution to an Erlang distribution
when all the rates of the exponential distributions are the same.
The following lemma provides the key property of the ![]() -value
used in our proof.
-value
used in our proof.
Proof:We prove the lemma by induction on ![]() .
Without loss of generality, we let
.
Without loss of generality, we let
![]() .
.
Base case (![]() ):
Let
):
Let
![]() and
and
![]() . Then,
. Then,

Inductive case:
Suppose that the lemma holds for ![]() .
When
.
When ![]() ,
, ![]() can be seen as a mixture of two distributions,
can be seen as a mixture of two distributions,
![]() and
and
![]() .
When
.
When
![]() , the lemma holds for
, the lemma holds for ![]() .
When
.
When
![]() , we have
, we have ![]() by the base case.
By the inductive hypothesis, there exist
by the base case.
By the inductive hypothesis, there exist
![]() such that
such that
![]() .
Thus, the lemma holds for
.
Thus, the lemma holds for ![]() . width 1ex height 1ex depth 0pt
. width 1ex height 1ex depth 0pt
We are now ready to prove that an ![]() -phase
Erlang distribution has no greater
-phase
Erlang distribution has no greater ![]() -value than any
-value than any ![]() -phase
PH distribution, which completes the proof of Lemma 1.
A proof of the following lemma is postponed to Appendix A.
-phase
PH distribution, which completes the proof of Lemma 1.
A proof of the following lemma is postponed to Appendix A.