NeuLab Presentations at EMNLP 2019
NeuLab will be presenting at EMNLP 2019, and co-located events at CoNLL 2019, WNGT 2019, and DeepLo 2019! Come visit our posters/presentations if you’re in Hong Kong for the conferences.
EMNLP 2019 Papers
Pushing the Limits of Low-Resource Morphological Inflection
- Authors: Antonios Anastasopoulos, Graham Neubig
- Time: Tuesday, November 5. 13:30–15:00 Poster Session 2.
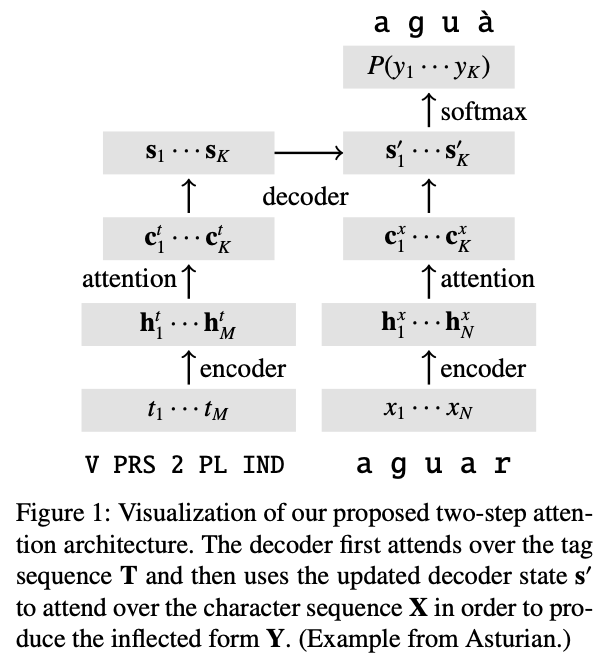
Recent years have seen exceptional strides in the task of automatic morphological inflection generation. However, for a long tail of languages the necessary resources are hard to come by, and state-of-the-art neural methods that work well under higher resource settings perform poorly in the face of a paucity of data. In response, we propose a battery of improvements that greatly improve performance under such low-resource conditions. First, we present a novel two-step attention architecture for the inflection decoder. In addition, we investigate the effects of cross-lingual transfer from single and multiple languages, as well as monolingual data hallucination. The macro-averaged accuracy of our models outperforms the state-of-the-art by 15 percentage points. Also, we identify the crucial factors for success with cross-lingual transfer for morphological inflection: typological similarity and a common representation across languages.
A Little Annotation does a Lot of Good: A Study in Bootstrapping Low-resource Named Entity Recognizers
- Authors: Aditi Chaudhary, Jiateng Xie, Zaid Sheikh, Graham Neubig, Jaime Carbonell
- Time: Tuesday, November 5. 14:06–14:24 Session 2D: Information Extraction 1
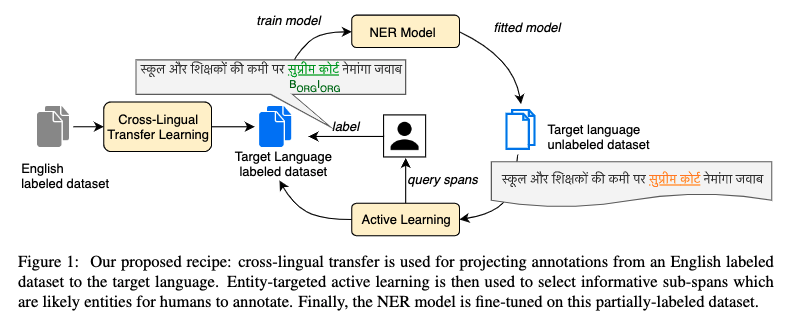
Most state-of-the-art models for named entity recognition (NER) rely on the availability of large amounts of labeled data, making them challenging to extend to new, lower-resourced languages. However, there are now several proposed approaches involving either cross-lingual transfer learning, which learns from other highly resourced languages, or active learning, which efficiently selects effective training data based on model predictions. This paper poses the question: given this recent progress, and limited human annotation, what is the most effective method for efficiently creating high-quality entity recognizers in under-resourced languages? Based on extensive experimentation using both simulated and real human annotation, we find a dual-strategy approach best, starting with a cross-lingual transferred model, then performing targeted annotation of only uncertain entity spans in the target language, minimizing annotator effort. Results demonstrate that cross-lingual transfer is a powerful tool when very little data can be annotated, but an entity-targeted annotation strategy can achieve competitive accuracy quickly, with just one-tenth of training data.
Handling Syntactic Divergence in Low-resource Machine Translation
- Authors: Chunting Zhou, Xuezhe Ma, Junjie Hu, Graham Neubig
- Time: Tuesday, November 5. 15:30–16:18 Poster Session 3.

Despite impressive empirical successes of neural machine translation (NMT) on standard benchmarks, limited parallel data impedes the application of NMT models to many language pairs. Data augmentation methods such as back-translation make it possible to use monolingual data to help alleviate these issues, but back-translation itself fails in extreme low-resource scenarios, especially for syntactically divergent languages. In this paper, we propose a simple yet effective solution, whereby target-language sentences are re-ordered to match the order of the source and used as an additional source of training-time supervision. Experiments with simulated low-resource Japanese-to-English, and real low-resource Uyghur-to-English scenarios find significant improvements over other semi-supervised alternatives.
Unsupervised Domain Adaptation for Neural Machine Translation with Domain-Aware Feature Embeddings
- Authors: Zi-Yi Dou, Junjie Hu, Antonios Anastasopoulos, Graham Neubig
- Time: Tuesday, November 5. 15:30–16:18 Poster Session 3.

The recent success of neural machine translation models relies on the availability of high quality, in-domain data. Domain adaptation is required when domain-specific data is scarce or nonexistent. Previous unsupervised domain adaptation strategies include training the model with in-domain copied monolingual or back-translated data. However, these methods use generic representations for text regardless of domain shift, which makes it infeasible for translation models to control outputs conditional on a specific domain. In this work, we propose an approach that adapts models with domain-aware feature embeddings, which are learned via an auxiliary language modeling task. Our approach allows the model to assign domain-specific representations to words and output sentences in the desired domain. Our empirical results demonstrate the effectiveness of the proposed strategy, achieving consistent improvements in multiple experimental settings. In addition, we show that combining our method with back translation can further improve the performance of the model.
Investigating Meta-Learning Algorithms for Low-Resource Natural Language Understanding Tasks
- Authors: Zi-Yi Dou, Keyi Yu, Antonios Anastasopoulos
- Time: Tuesday, November 5. 15:30–16:18 Session 3B: Semantics.
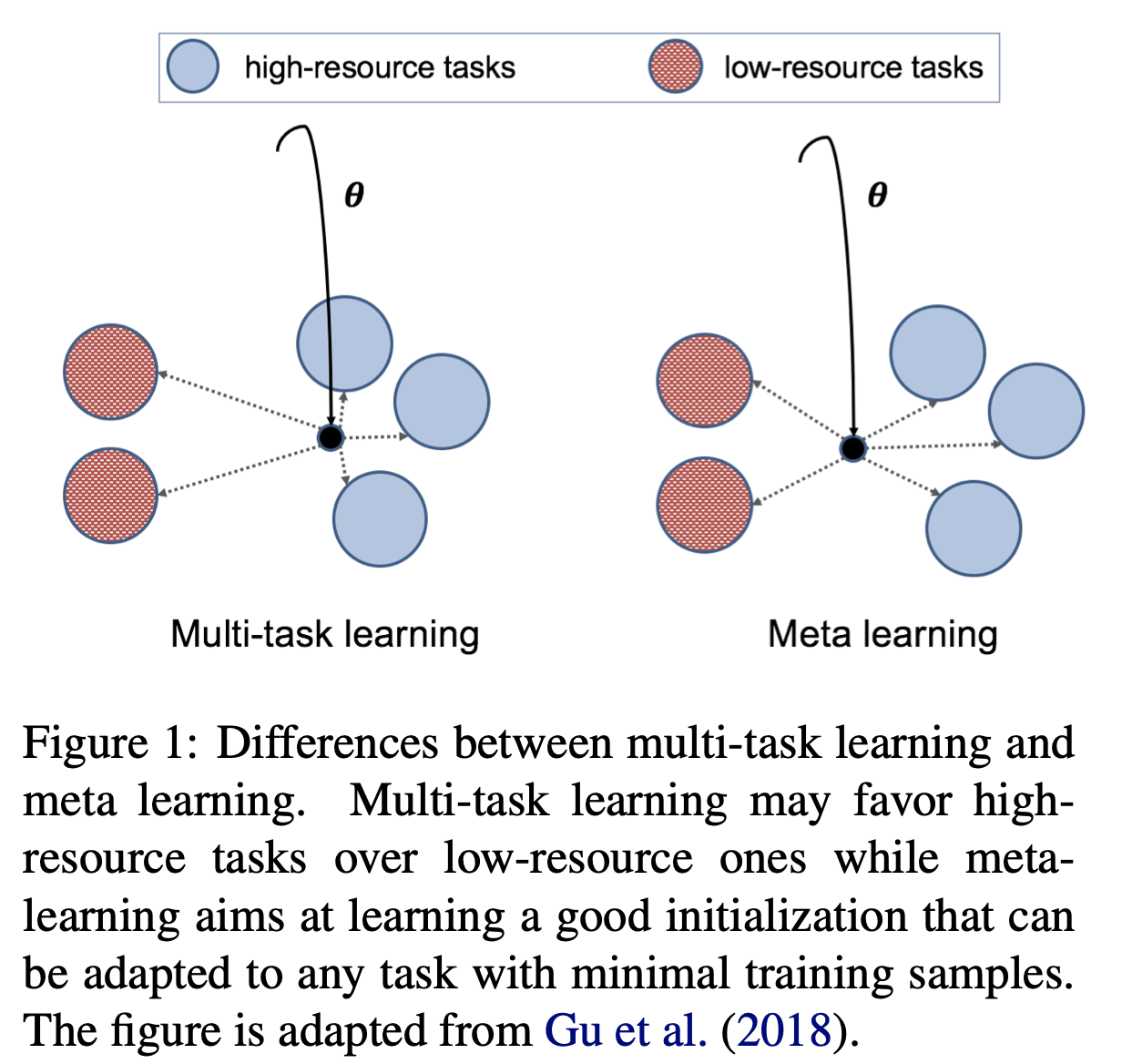
Learning general representations of text is a fundamental problem for many natural language understanding (NLU) tasks. Previously, researchers have proposed to use language model pre-training and multi-task learning to learn robust representations. However, these methods can achieve sub-optimal performance in low-resource scenarios. Inspired by the recent success of optimization-based meta-learning algorithms, in this paper, we explore the model-agnostic meta-learning algorithm (MAML) and its variants for low-resource NLU tasks. We validate our methods on the GLUE benchmark and show that our proposed models can outperform several strong baselines. We further empirically demonstrate that the learned representations can be adapted to new tasks efficiently and effectively.
A Surprisingly Effective Fix for Deep Latent Variable Modeling of Text
- Authors: Bohan Li, Junxian He, Graham Neubig, Taylor Berg-Kirkpatrick, Yiming Yang
- Time: Wednesday, November 6. 15:30–16:18 Poster Session 7.
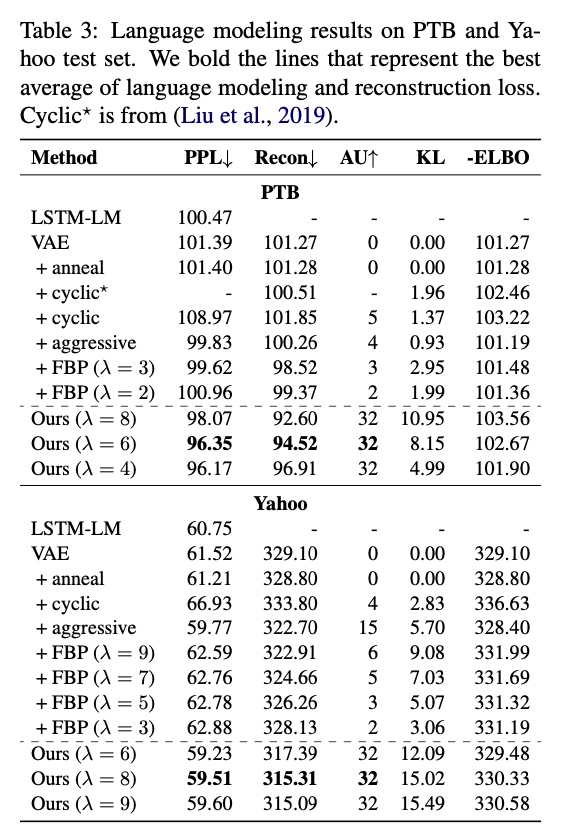
When trained effectively, the Variational Autoencoder (VAE) is both a powerful language model and an effective representation learning framework. In practice, however, VAEs are trained with the evidence lower bound (ELBO) as a surrogate objective to the intractable marginal data likelihood. This approach to training yields unstable results, frequently leading to a disastrous local optimum known as posterior collapse. In this paper, we investigate a simple fix for posterior collapse which yields surprisingly effective results. The combination of two known heuristics, previously considered only in isolation, substantially improves held-out likelihood, reconstruction, and latent representation learning when compared with previous state-of-the-art methods. More interestingly, while our experiments demonstrate superiority on these principle evaluations, our method obtains a worse ELBO. We use these results to argue that the typical surrogate objective for VAEs may not be sufficient or necessarily appropriate for balancing the goals of representation learning and data distribution modeling.
FlowSeq: Non-Autoregressive Conditional Sequence Generation with Generative Flow
- Authors: Xuezhe Ma, Chunting Zhou, Xian Li, Graham Neubig, Eduard Hovy.
- Time: Wednesday, November 6. 16:30–18:00 Poster Session 8.

Most sequence-to-sequence (seq2seq) models are autoregressive; they generate each token by conditioning on previously generated tokens. In contrast, non-autoregressive seq2seq models generate all tokens in one pass, which leads to increased efficiency through parallel processing on hardware such as GPUs. However, directly modeling the joint distribution of all tokens simultaneously is challenging, and even with increasingly complex model structures accuracy lags significantly behind autoregressive models. In this paper, we propose a simple, efficient, and effective model for non-autoregressive sequence generation using latent variable models. Specifically, we turn to generative flow, an elegant technique to model complex distributions using neural networks, and design several layers of flow tailored for modeling the conditional density of sequential latent variables. We evaluate this model on three neural machine translation (NMT) benchmark datasets, achieving comparable performance with state-of-the-art non-autoregressive NMT models and almost constant decoding time w.r.t the sequence length.
CoNLL 2019 Papers
Comparing Top-down and Bottom-up Neural Generative Dependency Models
- Authors: Austin Matthews, Graham Neubig, Chris Dyer
- Time: Sunday, November 3. 16:30–18:00 Poster Session 1.
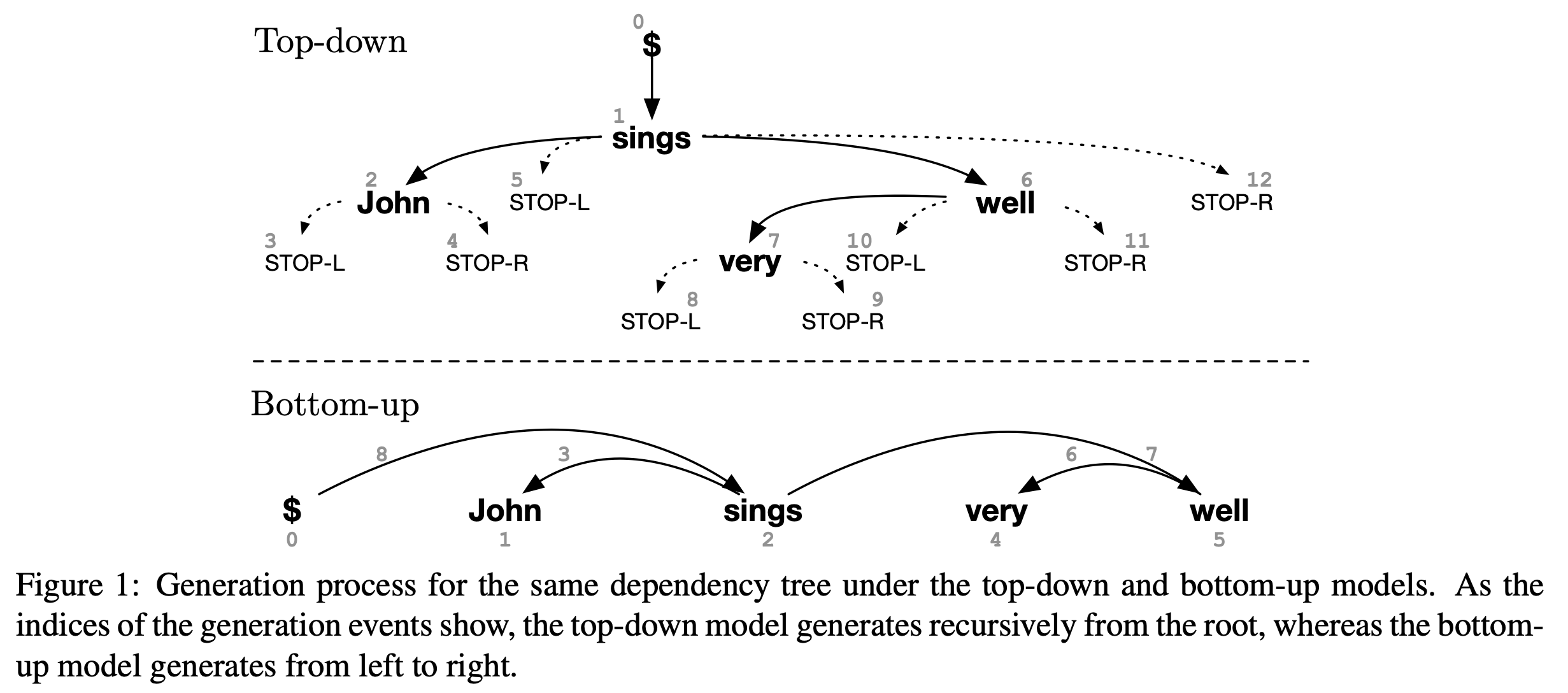
Recurrent neural network grammars (RNNGs) generate sentences using phrase-structure syntax and perform very well in terms of both language modeling and parsing performance. However, since dependency annotations are much more readily available than phrase structure annotations, we propose two new generative models of projective dependency syntax, so as to explore whether generative dependency models are similarly effective. Both models use RNNs to represent the derivation history with making any explicit independence assumptions, but they differ in how they construct the trees: one builds the tree bottom up and the other top down, which profoundly changes the estimation problem faced by the learner. We evaluate the two models on three typologically different languages: English, Arabic, and Japanese. We find that both generative models improve parsing performance over a discriminative baseline, but, in contrast to RNNGs, they are significantly less effective than non-syntactic LSTM language models. Little difference between the tree construction orders is observed for either parsing or language modeling.
WNGT 2019 Papers
Findings of the Third Workshop on Neural Generation and Translation
- Authors: Hiroaki Hayashi, Yusuke Oda, Alexandra Birch, Ioannis Konstas, Andrew Finch, Minh-Thang Luong, Graham Neubig, Katsuhito Sudoh
- Time: Monday, November 4. 09:00–09:10.
This document describes the findings of the Third Workshop on Neural Generation and Translation, held in concert with the annual conference of the Empirical Methods in Natural Language Processing (EMNLP 2019). First, we summarize the research trends of papers presented in the proceedings. Second, we describe the results of the two shared tasks 1) efficient neural machine translation (NMT) where participants were tasked with creating NMT systems that are both accurate and efficient, and 2) document generation and translation (DGT) where participants were tasked with developing systems that generate summaries from structured data, potentially with assistance from text in another language.
Domain Differential Adaptation for Neural Machine Translation
- Authors: Zi-Yi Dou, Xinyi Wang, Junjie Hu, Graham Neubig
- Time: Monday, November 4. 10:40–11:40. Poster Session.

Neural networks are known to be data hungry and domain sensitive, but it is nearly impossible to obtain large quantities of labeled data for every domain we are interested in. This necessitates the use of domain adaptation strategies. One common strategy encourages generalization by aligning the global distribution statistics between source and target domains, but one drawback is that the statistics of different domains or tasks are inherently divergent, and smoothing over these differences can lead to sub-optimal performance. In this paper, we propose the framework of {\it Domain Differential Adaptation (DDA)}, where instead of smoothing over these differences we embrace them, directly modeling the difference between domains using models in a related task. We then use these learned domain differentials to adapt models for the target task accordingly. Experimental results on domain adaptation for neural machine translation demonstrate the effectiveness of this strategy, achieving consistent improvements over other alternative adaptation strategies in multiple experimental settings.
DeepLo 2019 Papers
Towards Zero-resource Cross-lingual Entity Linking
- Authors: Shuyan Zhou, Shruti Rijhwani, Graham Neubig
- Time: Monday, November 4. 14:45–15:30. Poster Session 2.

Cross-lingual entity linking (XEL) grounds named entities in a source language to an English Knowledge Base (KB), such as Wikipedia. XEL is challenging for most languages because of limited availability of requisite resources. However, much previous work on XEL has been on simulated settings that actually use significant resources (e.g. source language Wikipedia, bilingual entity maps, multilingual embeddings) that are unavailable in truly low-resource languages. In this work, we first examine the effect of these resource assumptions and quantify how much the availability of these resource affects overall quality of existing XEL systems. Next, we propose three improvements to both entity candidate generation and disambiguation that make better use of the limited data we do have in resource-scarce scenarios. With experiments on four extremely low-resource languages, we show that our model results in gains of 6-23% in end-to-end linking accuracy.