NeuLab Presentations at EMNLP 2017
There will be 3 main conference papers and 1 workshop paper co-authored by NeuLab members at EMNLP2017 this week. Come check them out!
Main Conference
Neural Lattice-to-Sequence Models for Uncertain Inputs
- Authors: Matthias Sperber, Graham Neubig, Jan Niehues, Alex Waibel.
- Time: Sunday, September 10, 10:30-12:10. Session 8C.
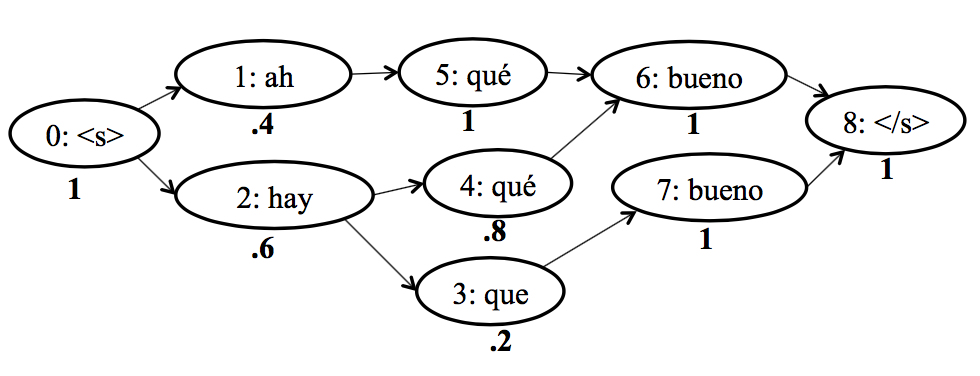
The input to a neural sequence-to-sequence model is often determined by an up-stream system, e.g. a word segmenter, part of speech tagger, or speech recognizer. These up-stream models are potentially error-prone. Representing inputs through word lattices allows making this uncertainty explicit by capturing alternative sequences and their posterior probabilities in a compact form. In this work, we extend the TreeLSTM (Tai et al., 2015) into a LatticeLSTM that is able to consume word lattices, and can be used as encoder in an attentional encoderdecoder model. We integrate lattice posterior scores into this architecture by extending the TreeLSTM’s child-sum and forget gates and introducing a bias term into the attention mechanism. We experiment with speech translation lattices and report consistent improvements over baselines that translate either the 1-best hypothesis or the lattice without posterior scores.
Learning Language Representations for Typology Prediction
- Authors: Chaitanya Malaviya, Graham Neubig and Patrick Littell.
- Time: Monday, September 11, 10:30-12:10. Poster Session 7D.
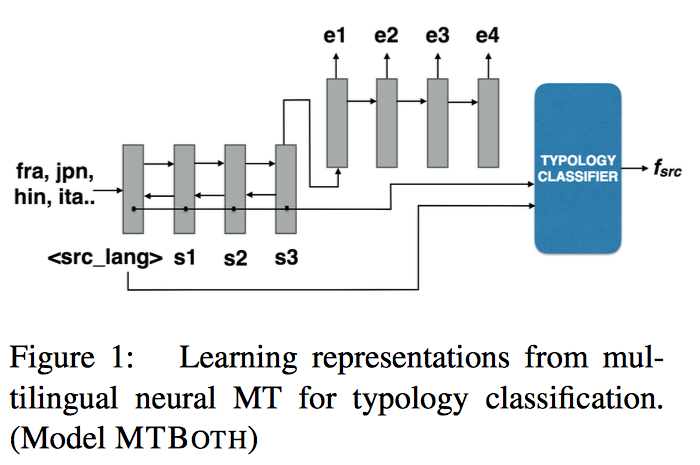
One central mystery of neural NLP is what neural models “know” about their subject matter. When a neural machine translation system learns to translate from one language to another, does it learn the syntax or semantics of the languages? Can this knowledge be extracted from the system to fill holes in human scientific knowledge? Existing typological databases contain relatively full feature specifications for only a few hundred languages. Exploiting the existence of parallel texts in more than a thousand languages, we build a massive many-to-one neural machine translation (NMT) system from 1017 languages into English, and use this to predict information missing from typological databases. Experiments show that the proposed method is able to infer not only syntactic, but also phonological and phonetic inventory features, and improves over a baseline that has access to information about the languages’ geographic and phylogenetic neighbors. Code and learned vectors are available here.
Charmanteau: Character Embedding Models For Portmanteau Creation
- Authors: Varun Gangal, Harsh Jhamtani, Graham Neubig, Eduard Hovy, Eric Nyberg.
- Time: Monday, September 11, 14:10-14:25.
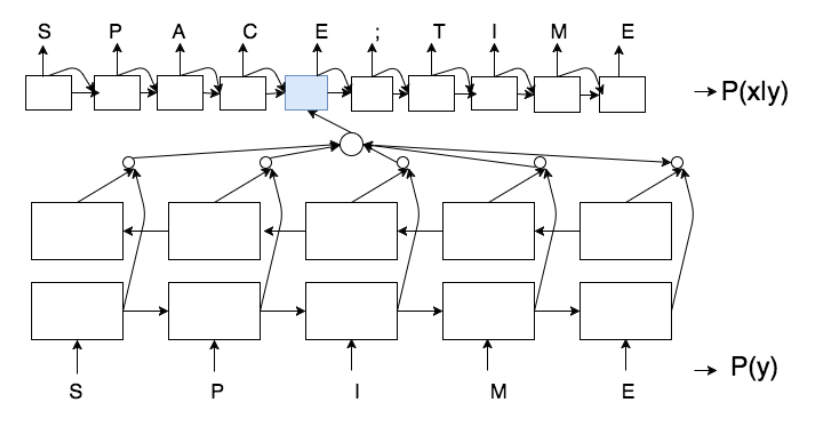
Portmanteaus are a word formation phenomenon where two words are combined to form a new word. We propose character-level neural sequence-tosequence (S2S) methods for the task of portmanteau generation that are end-toend-trainable, language independent, and do not explicitly use additional phonetic information. We propose a noisy-channelstyle model, which allows for the incorporation of unsupervised word lists, improving performance over a standard sourceto-target model. This model is made possible by an exhaustive candidate generation strategy specifically enabled by the features of the portmanteau task. Experiments find our approach superior to a state-of-the-art FST-based baseline with respect to ground truth accuracy and human evaluation.
Workshop
Tree as a Pivot: Syntactic Matching Methods in Pivot Translation
- Authors: Akiva Miura, Graham Neubig, Katsuhito Sudoh, Satoshi Nakamura.
- Venue: Conference on Machine Translation (WMT).
- Time: Friday, September 8, 14:30–14:45.

Pivot translation is a useful method for translating between languages with little or no parallel data by utilizing parallel data in an intermediate language such as English. A popular approach for pivot translation used in phrase-based or tree-based translation models combines source-pivot and pivot-target translation models into a source-target model, as known as triangulation. However, this combination is based on the constituent words’ surface forms and often produces incorrect source-target phrase pairs due to semantic ambiguity in the pivot language, and interlingual differences. This degrades translation accuracy. In this paper, we propose a approach for the triangulation using syntactic subtrees in the pivot language to distinguish pivot language words by their syntactic roles to avoid incorrect phrase combinations. Experimental results on the United Nations Parallel Corpus show the proposed method gains in all tested combinations of language, up to 2.3 BLEU points. Code is available here.