NeuLab Presentations at ACL
There will be 5 main conference papers and 5 workshop papers co-authored by NeuLab members at ACL2017 this week, including one Best Paper Award at the Workhop on Neural Machine Translation.
Main Conference
Multi-space Variational Encoder-Decoders for Semi-supervised Labeled Sequence Transduction
- Authors: Chunting Zhou, Graham Neubig.
- Time: Monday, July 31st 13:40-13:58, Session 2D: Machine Learning 1 (NN)
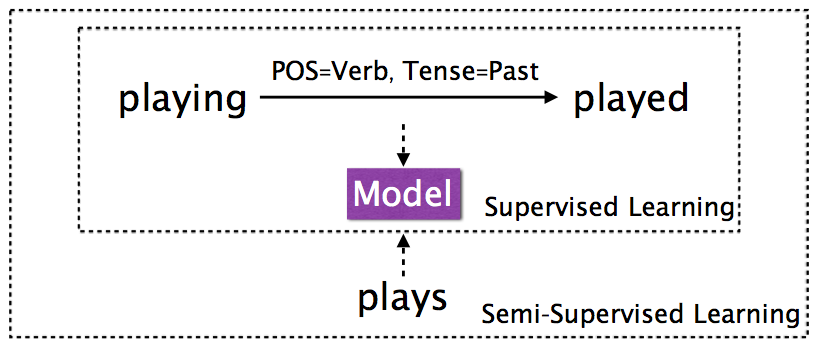
Labeled sequence transduction is a task of transforming one sequence into another sequence that satisfies desiderata specified by a set of labels. In this paper we propose multi-space variational encoder-decoders, a new model for labeled sequence transduction with semi-supervised learning. The generative model can use neural networks to handle both discrete and continuous latent variables to exploit various features of data. Experiments show that our model provides not only a powerful supervised framework but also can effectively take advantage of the unlabeled data. On the SIGMORPHON morphological inflection benchmark, our model outperforms single-model state-ofart results by a large margin for the majority of languages. Code is available here.
A Syntactic Neural Model for General-Purpose Code Generation
- Authors: Pengcheng Yin, Graham Neubig.
- Time: Monday, July 31st 15:45–16:03, Session 3B: Semantics 2 (NN)
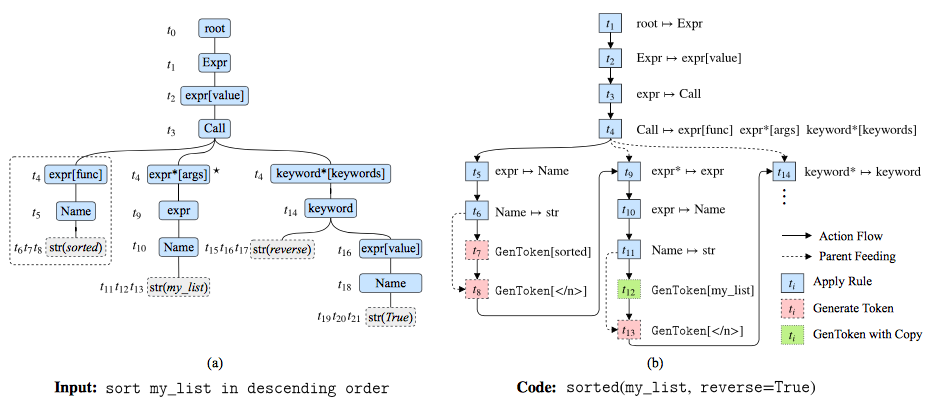
We consider the problem of parsing natural language descriptions into source code written in a general-purpose programming language like Python. Existing datadriven methods treat this problem as a language generation task without considering the underlying syntax of the target programming language. Informed by previous work in semantic parsing, in this paper we propose a novel neural architecture powered by a grammar model to explicitly capture the target syntax as prior knowledge. Experiments find this an effective way to scale up to generation of complex programs from natural language descriptions, achieving state-of-the-art results that well outperform previous code generation and semantic parsing approaches. Code is available here.
Neural Machine Translation via Binary Code Prediction
- Authors: Yusuke Oda, Philip Arthur, Graham Neubig, Koichiro Yoshino, Satoshi Nakamura.
- Time: Tuesday, August 1st 13:30–13:48, Session 5D: Machine Translation 3 (NN)

In this paper, we propose a new method for calculating the output layer in neural machine translation systems. The method is based on predicting a binary code for each word and can reduce computation time/memory requirements of the output layer to be logarithmic in vocabulary size in the best case. In addition, we also introduce two advanced approaches to improve the robustness of the proposed model: using error-correcting codes and combining softmax and binary codes. Experiments on two English ↔ Japanese bidirectional translation tasks show proposed models achieve BLEU scores that approach the softmax, while reducing memory usage to the order of less than 1/10 and improving decoding speed on CPUs by x5 to x10. Code is available here.
Learning Character-level Compositionality with Visual Features
- Authors: Frederick Liu, Han Lu, Chieh Lo, Graham Neubig.
- Time: Tuesday, August 1st 17:45-19:45, Poster Session.

Previous work has modeled the compositionality of words by creating characterlevel models of meaning, reducing problems of sparsity for rare words. However, in many writing systems compositionality has an effect even on the character-level: the meaning of a character is derived by the sum of its parts. In this paper, we model this effect by creating embeddings for characters based on their visual characteristics, creating an image for the character and running it through a convolutional neural network to produce a visual character embedding. Experiments on a text classification task demonstrate that such model allows for better processing of instances with rare characters in languages such as Chinese, Japanese, and Korean. Additionally, qualitative analyses demonstrate that our proposed model learns to focus on the parts of characters that carry semantic content, resulting in embeddings that are coherent in visual space.
Estimating Code-Switching on Twitter with a Novel Generalized Word-Level Language Detection Technique
- Authors: Shruti Rijhwani, Royal Sequiera, Monojit Choudhury, Kalika Bali, Chandra Shekhar Maddila.
- Time: Tuesday, August 1st 17:45-19:45, Poster Session.

Word-level language detection is necessary for analyzing code-switched text, where multiple languages could be mixed within a sentence. Existing models are restricted to code-switching between two specific languages and fail in real-world scenarios as text input rarely has a priori information on the languages used. We present a novel unsupervised word-level language detection technique for codeswitched text for an arbitrarily large number of languages, which does not require any manually annotated training data. Our experiments with tweets in seven languages show a 74% relative error reduction in word-level labeling with respect to competitive baselines. We then use this system to conduct a large-scale quantitative analysis of code-switching patterns on Twitter, both global as well as regionspecific, with 58M tweets.
Workshops
Blind Phoneme Segmentation With Temporal Prediction Errors
- Authors: Paul Michel, Okko Räsänen, Roland Thiollière, Emmanuel Dupoux.
- Venue: ACL Student Research Workshop.
- Time: Monday, July 31st 18:20-21:50.
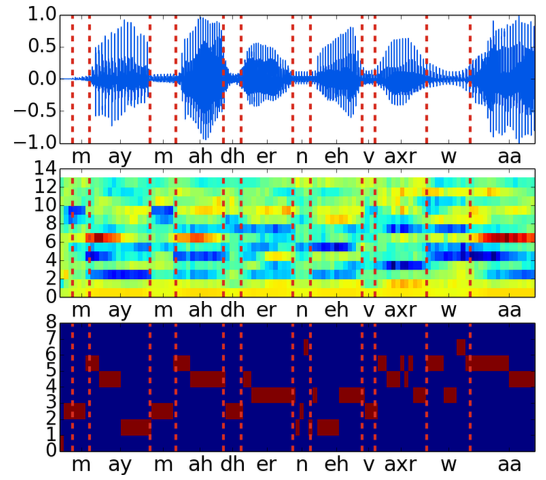
Phonemic segmentation of speech is a critical step of speech recognition systems. We propose a novel unsupervised algorithm based on sequence prediction models such as Markov chains and recurrent neural networks. Our approach consists in analyzing the error profile of a model trained to predict speech features frameby-frame. Specifically, we try to learn the dynamics of speech in the MFCC space and hypothesize boundaries from local maxima in the prediction error. We evaluate our system on the TIMIT dataset, with improvements over similar methods.
Morphological Inflection Generation with Multi-space Variational Encoder-Decoders
- Authors: Chunting Zhou, Graham Neubig.
- Venue: CoNLL-SIGMORPHON Shared Task Session.
- Time: Thursday, August 3rd 11:00-12:30.
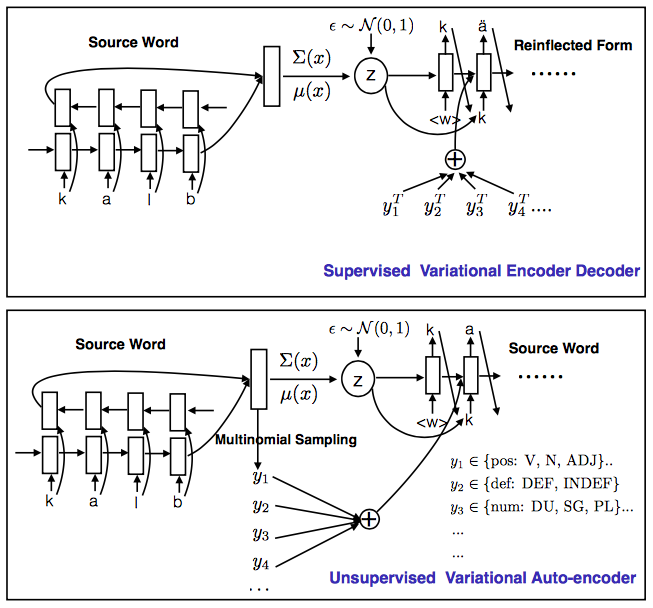
This paper describes the CMU submission to shared task 1 of SIGMORPHON 2017. The system is based on the multi-space variational encoder-decoder (MSVED) method of Zhou and Neubig (2017), which employs both continuous and discrete latent variables for the variational encoder-decoder and is trained in a semi-supervised fashion. We discuss some language-specific errors and present result analysis.
Does the Geometry of Word Embeddings Help Document Classification? A Case Study on Persistent Homology-Based Representations
- Authors: Paul Michel, Abhilasha Ravichander, Shruti Rijhwani.
- Venue: Workshop on Representation Learning for NLP.
- Time: Thursday, August 3rd 15:00-16:30.

We investigate the pertinence of methods from algebraic topology for text data analysis. These methods enable the development of mathematically-principled isometric-invariant mappings from a set of vectors to a document embedding, which is stable with respect to the geometry of the document in the selected metric space. In this work, we evaluate the utility of these topology-based document representations in traditional NLP tasks, specifically document clustering and sentiment classification. We find that the embeddings do not benefit text analysis. In fact, performance is worse than simple techniques like tf-idf, indicating that the geometry of the document does not provide enough variability for classification on the basis of topic or sentiment in the chosen datasets.
Stronger Baselines for Trustable Results in Neural Machine Translation
- Authors: Michael Denkowski, Graham Neubig.
- Venue: 1st Workshop on Neural Machine Translation.
- Time: Friday, August 4th 11:50-12:20. (Best Paper Session)

This paper won the Best Paper Award!
Interest in neural machine translation has grown rapidly as its effectiveness has been demonstrated across language and data scenarios. New research regularly introduces architectural and algorithmic improvements that lead to significant gains over “vanilla” NMT implementations. However, these new techniques are rarely evaluated in the context of previously published techniques, specifically those that are widely used in state-of-theart production and shared-task systems. As a result, it is often difficult to determine whether improvements from research will carry over to systems deployed for real-world use. In this work, we recommend three specific methods that are relatively easy to implement and result in much stronger experimental systems. Beyond reporting significantly higher BLEU scores, we conduct an in-depth analysis of where improvements originate and what inherent weaknesses of basic NMT models are being addressed. We then compare the relative gains afforded by several other techniques proposed in the literature when starting with vanilla systems versus our stronger baselines, showing that experimental conclusions may change depending on the baseline chosen. This indicates that choosing a strong baseline is crucial for reporting reliable experimental results.
An Empirical Study of Mini-Batch Creation Strategies for Neural Machine Translation
- Authors: Makoto Morishita, Yusuke Oda, Graham Neubig, Koichiro Yoshino, Katsuhito Sudoh, Satoshi Nakamura.
- Venue: 1st Workshop on Neural Machine Translation.
- Time: Friday, August 4th 15:20-16:30.
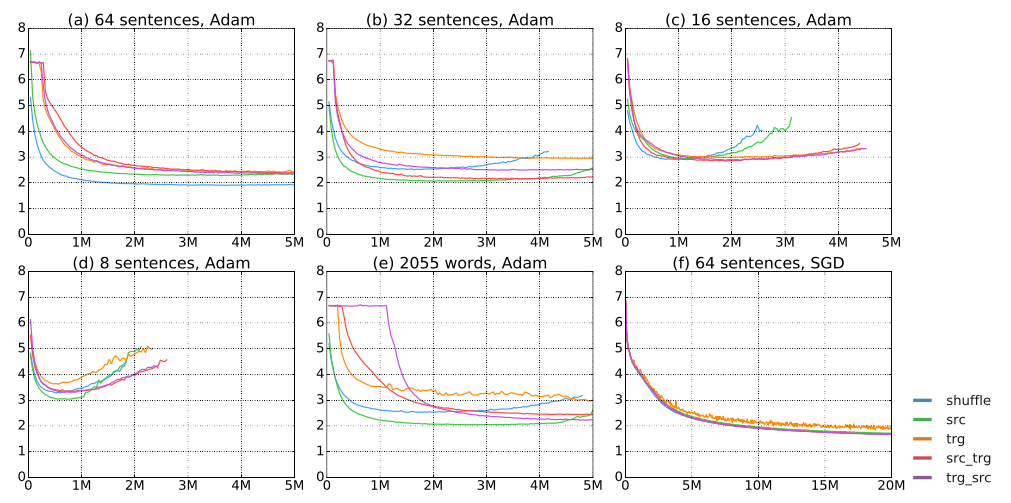
Training of neural machine translation (NMT) models usually uses mini-batches for efficiency purposes. During the minibatched training process, it is necessary to pad shorter sentences in a mini-batch to be equal in length to the longest sentence therein for efficient computation. Previous work has noted that sorting the corpus based on the sentence length before making mini-batches reduces the amount of padding and increases the processing speed. However, despite the fact that mini-batch creation is an essential step in NMT training, widely used NMT toolkits implement disparate strategies for doing so, which have not been empirically validated or compared. This work investigates mini-batch creation strategies with experiments over two different datasets. Our results suggest that the choice of a minibatch creation strategy has a large effect on NMT training and some length-based sorting strategies do not always work well compared with simple shuffling.