Presentations at EACL
There will be three presentations of papers co-authored by NeuLab members at EACL2017 this week, including one Outstanding Paper Award for Adhi’s work.
Cross-Lingual Word Embeddings for Low-Resource Language Modeling
- Authors: Oliver Adams, Adam Makarucha, Graham Neubig, Steven Bird, Trevor Cohn.
- Time: Thursday 17:30-19:30 Poster Session
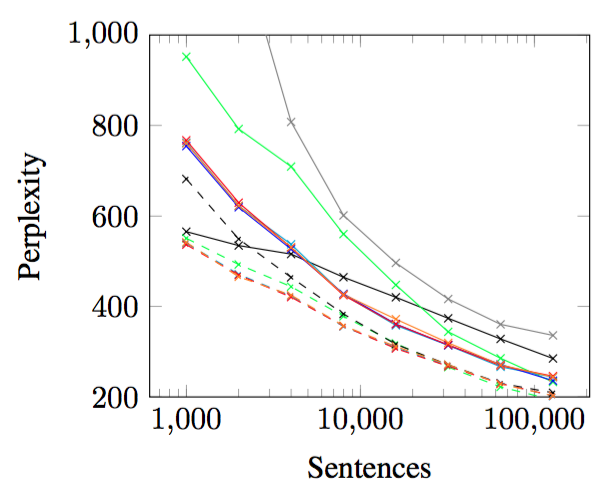
Most languages have no established writing system and minimal written records. However, textual data is essential for natural language processing, and particularly important for training language models that would facilitate speech recognition. However, bilingual lexicons are often available, since creating lexicons is a fundamental task of documentary linguistics. We investigate the use of such lexicons to improve language models, when textual training data is limited to as few as a thousand sentences. The method involves learning cross-lingual word embeddings as a preliminary step in training monolingual language models. Results across a number of languages show that language models with this pre-training (the dashed lines in the above graph) improve over models without this pre-training. Application to Yongning Na, a threatened language, highlights challenges in deploying the approach in real low-resource environments.
Learning to Translate in Real-time with Neural Machine Translation
- Authors: Jiatao Gu, Graham Neubig, Kyunghyun Cho, Victor O.K. Li.
- Time: Friday 11:40-12:00 Session 7A: Machine Translation and Multilinguality
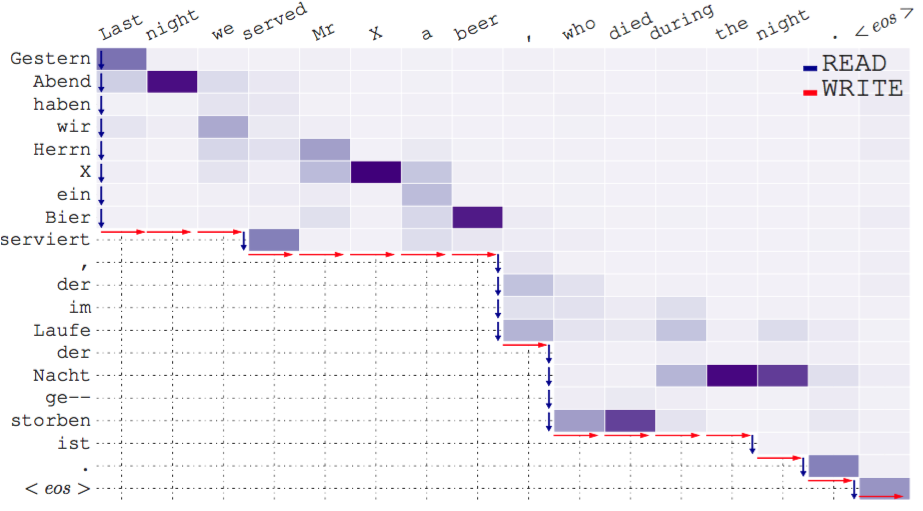
Translating in real-time, a.k.a. simultaneous translation, outputs translation words before the input sentence ends, which is a challenging problem for conventional machine translation methods. We propose a neural machine translation (NMT) framework for simultaneous translation in which an agent learns to make decisions on when to wait for new input (read), or generate a translation (write), as shown in the figure above. To trade off quality and delay, we extensively explore various targets for delay and design a method for beam-search applicable in the simultaneous MT setting. Experiments against state-of-the-art baselines on two language pairs demonstrate the efficacy of the proposed framework both quantitatively and qualitatively.
What Do Recurrent Neural Network Grammars Learn About Syntax?
- Authors: Adhiguna Kuncoro, Miguel Ballesteros, Lingpeng Kong, Chris Dyer, Graham Neubig and Noah A. Smith
- Time: Friday 16:00-16:25 Session 8A: Outstanding Papers 1

Recurrent neural network grammars (RNNG) are a recently proposed probabilistic generative modeling family for natural language. They show state-ofthe-art language modeling and parsing performance. We investigate what information they learn, from a linguistic perspective, through various ablations to the model and the data, and by augmenting the model with an attention mechanism (GA-RNNG) to enable closer inspection. We find that explicit modeling of composition is crucial for achieving the best performance. Through the attention mechanism, we find that headedness plays a central role in phrasal representation (with the model’s latent attention largely agreeing with predictions made by hand-crafted head rules, albeit with some important differences). By training grammars without nonterminal labels, we find that phrasal representations depend minimally on nonterminals, providing support for the endocentricity hypothesis.