NeuLab Presentations at ACL 2019
NeuLab members have thirteen main conference paper presentations at ACL 2019, are presenting a paper and running a shared task at the co-located WMT 2019, and are presenting a paper at the BlackBoxNLP workshop! Come visit our posters/presentations if you’re in Florence for the conferences.
Main Conference Papers
Bilingual Lexicon Induction with Semi-supervision in Non-Isometric Embedding Spaces
- Authors: Barun Patra, Joel Ruben Antony Moniz, Sarthak Garg, Matthew R. Gormley, Graham Neubig.
- Time: Monday, July 29th. 10:50–11:10 Session 1D: Machine Translation 1
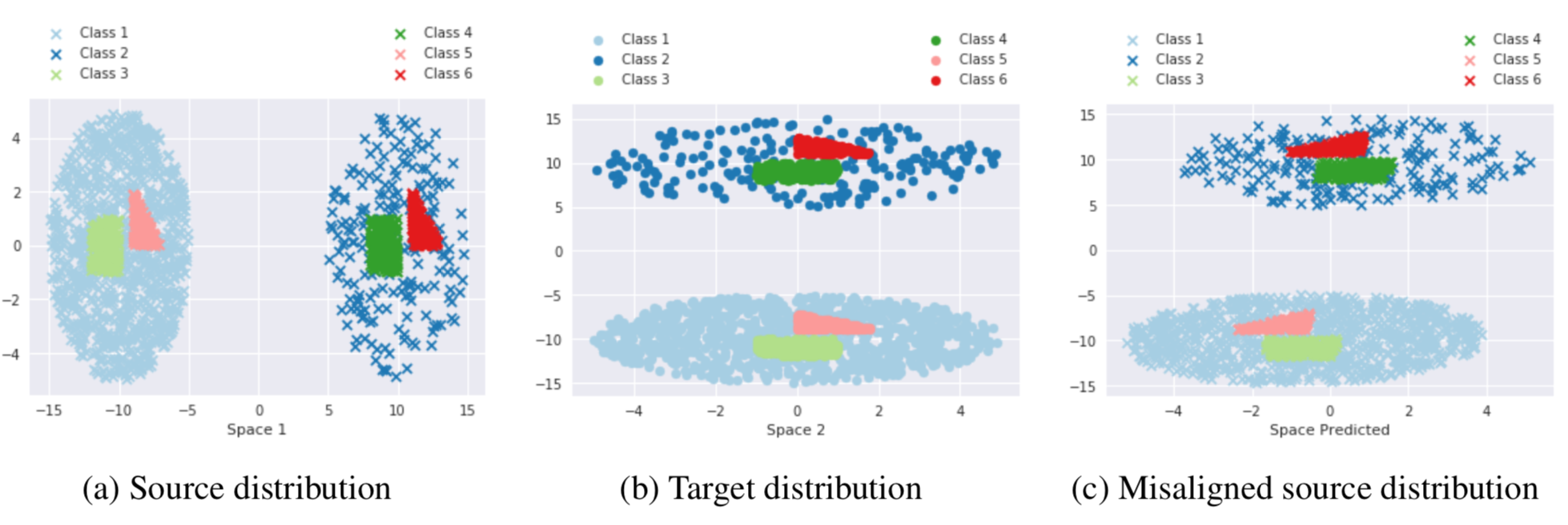
Recent work on bilingual lexicon induction (BLI) has frequently depended either on aligned bilingual lexicons or on distribution matching, often with an assumption about the isometry of the two spaces. We propose a technique to quantitatively estimate this assumption of the isometry between two embedding spaces and empirically show that this assumption weakens as the languages in question become increasingly etymologically distant. We then propose Bilingual Lexicon Induction with Semi-Supervision (BLISS) — a semi-supervised approach that relaxes the isometric assumption while leveraging both limited aligned bilingual lexicons and a larger set of unaligned word embeddings, as well as a novel hubness filtering technique. Our proposed method obtains state of the art results on 15 of 18 language pairs on the MUSE dataset, and does particularly well when the embedding spaces don’t appear to be isometric. In addition, we also show that adding supervision stabilizes the learning procedure, and is effective even with minimal supervision. Code is available here.
Self-Attentional Models for Lattice Inputs
- Authors: Matthias Sperber, Graham Neubig, Ngoc-Quan Pham, Alex Waibel
- Time: Monday, July 29th. 13:50–15:30 Poster Session 2.
Lattices are an efficient and effective method to encode ambiguity of upstream systems in natural language processing tasks, for example to compactly capture multiple speech recognition hypotheses, or to represent multiple linguistic analyses. Previous work has extended recurrent neural networks to model lattice inputs and achieved improvements in various tasks, but these models suffer from very slow computation speeds. This paper extends the recently proposed paradigm of self-attention to handle lattice inputs. Self-attention is a sequence modeling technique that relates inputs to one another by computing pairwise similarities and has gained popularity for both its strong results and its computational efficiency. To extend such models to handle lattices, we introduce probabilistic reachability masks that incorporate lattice structure into the model and support lattice scores if available. We also propose a method for adapting positional embeddings to lattice structures. We apply the proposed model to a speech translation task and find that it outperforms all examined baselines while being much faster to compute than previous neural lattice models during both training and inference.
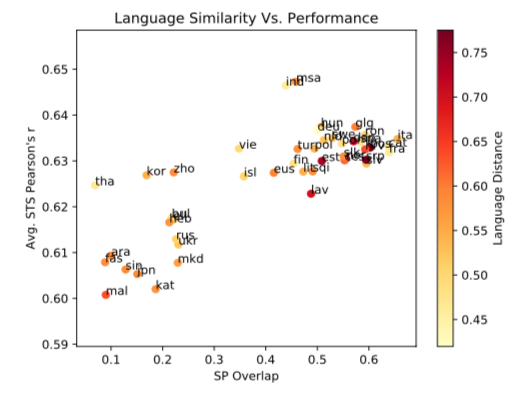
Choosing Transfer Languages for Cross-Lingual Learning
- Authors: Yu-Hsiang Lin, Chian-Yu Chen, Jean Lee, Zirui Li, Yuyan Zhang, Mengzhou Xia, Shruti Rijhwani, Junxian He, Zhisong Zhang, Xuezhe Ma, Antonios Anastasopoulos, Patrick Littell, Graham Neubig
- Time: Tuesday, July 30. 10:30–12:10 Poster Session 4.
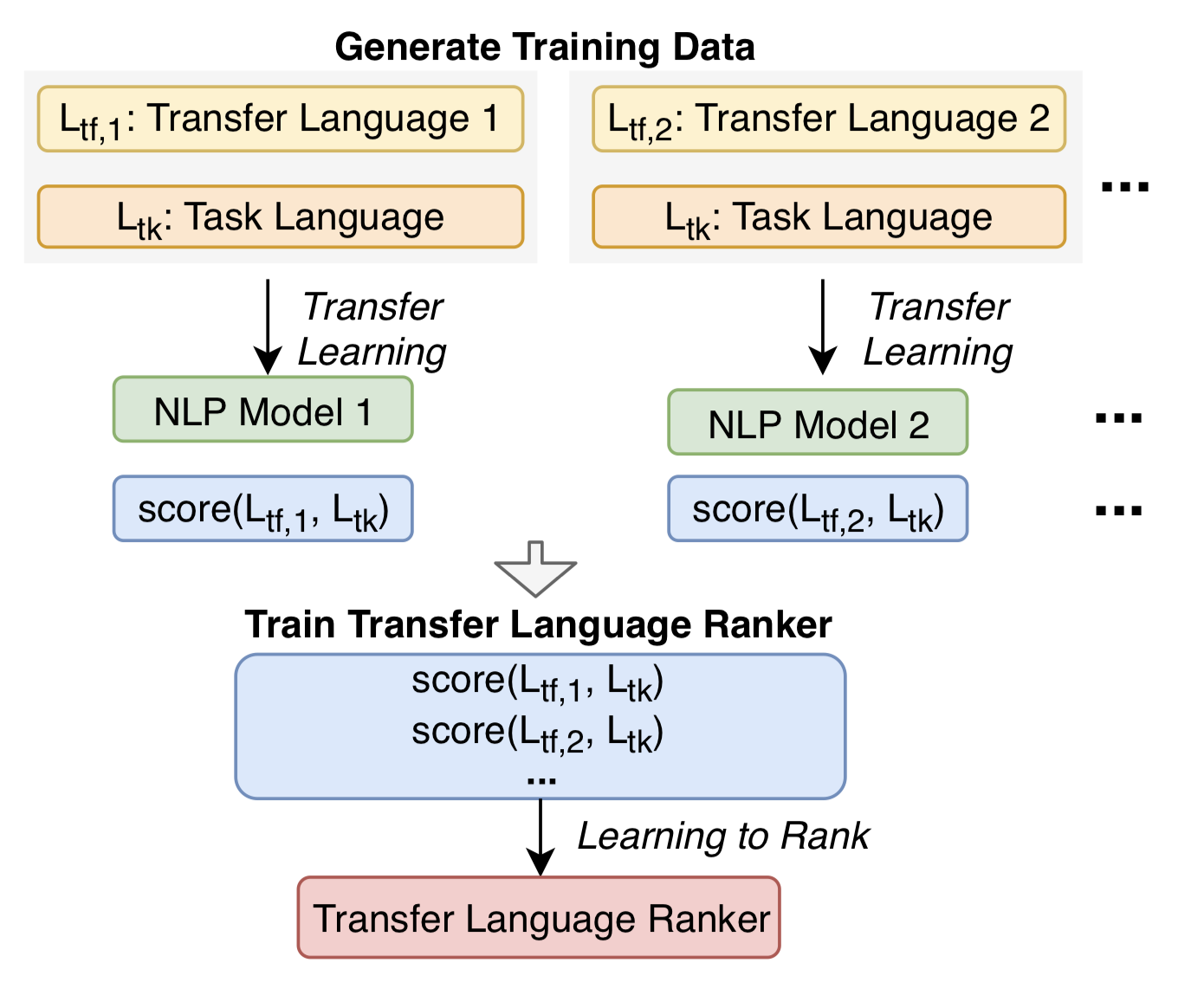
Cross-lingual transfer, where a high-resource transfer language is used to improve the accuracy of a low-resource task language, is now an invaluable tool for improving performance of natural language processing (NLP) on low-resource languages. However, given a particular task language, it is not clear which language to transfer from, and the standard strategy is to select languages based on ad hoc criteria, usually the intuition of the experimenter. Since a large number of features contribute to the success of cross-lingual transfer (including phylogenetic similarity, typological properties, lexical overlap, or size of available data), even the most enlightened experimenter rarely considers all these factors for the particular task at hand. In this paper, we consider this task of automatically selecting optimal transfer languages as a ranking problem, and build models that consider the aforementioned features to perform this prediction. In experiments on representative NLP tasks, we demonstrate that our model predicts good transfer languages much better than ad hoc baselines considering single features in isolation, and glean insights on what features are most informative for each different NLP tasks, which may inform future ad hoc selection even without use of our method. Code is available here.
Cross-Lingual Syntactic Transfer through Unsupervised Adaptation of Invertible Projections
- Authors: Junxian He, Zhisong Zhang, Taylor Berg-Kirkpatrick, Graham Neubig.
- Time: Tuesday, July 30, 2019. 10:30–12:10 Poster Session 4.
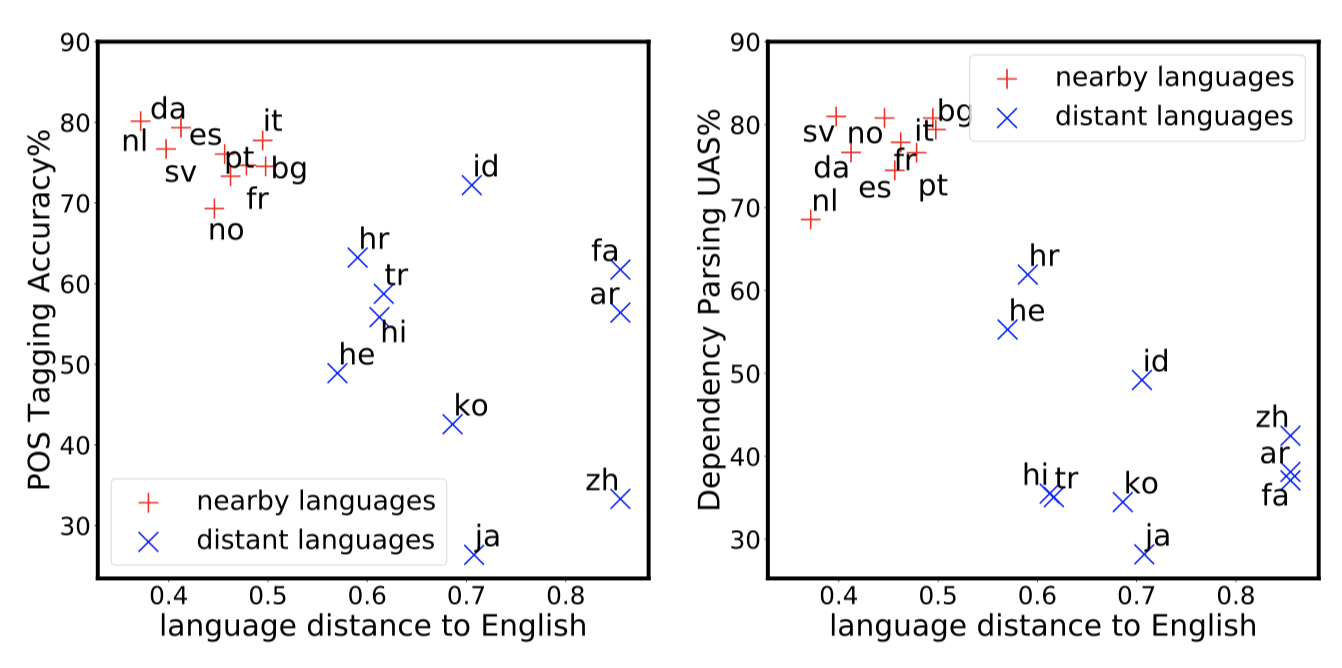
Cross-lingual transfer is an effective way to build syntactic analysis tools in low-resource languages. However, transfer is difficult when transferring to typologically distant languages, especially when neither annotated target data nor parallel corpora are available. In this paper, we focus on methods for cross-lingual transfer to distant languages and propose to learn a generative model with a structured prior that utilizes labeled source data and unlabeled target data jointly. The parameters of source model and target model are softly shared through a regularized log likelihood objective. An invertible projection is employed to learn a new interlingual latent embedding space that compensates for imperfect cross-lingual word embedding input. We evaluate our method on two syntactic tasks: part-of-speech (POS) tagging and dependency parsing. On the Universal Dependency Treebanks, we use English as the only source corpus and transfer to a wide range of target languages. On the 10 languages in this dataset that are distant from English, our method yields an average of 5.2% absolute improvement on POS tagging and 8.3% absolute improvement on dependency parsing over a direct transfer method using state-of-the-art discriminative models. Code is available here.
Domain Adaptation of Neural Machine Translation by Lexicon Induction
- Authors: Junjie Hu, Mengzhou Xia, Graham Neubig, Jaime Carbonell.
- Time: Tuesday, July 30, 2019. 10:30–12:10 Poster Session 4.
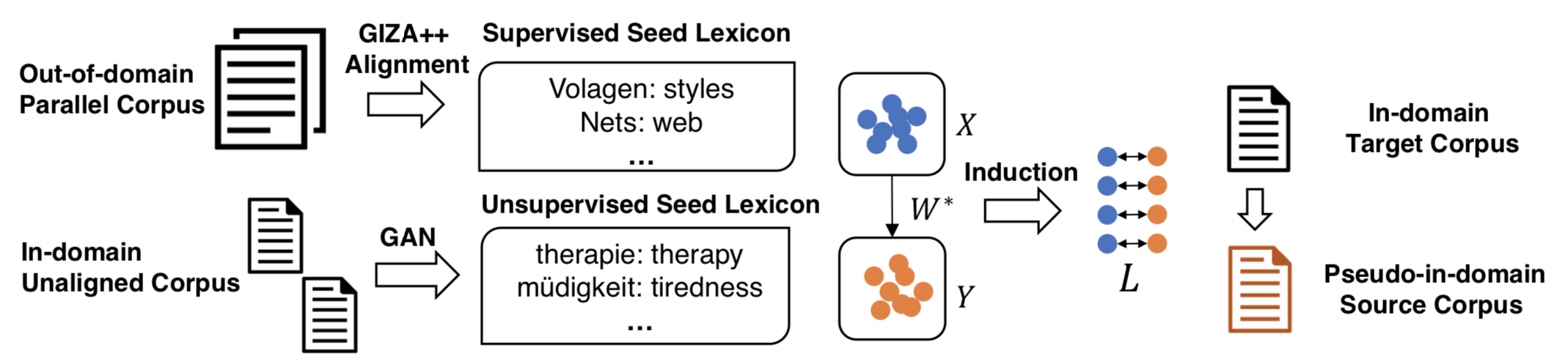
It has been previously noted that neural machine translation (NMT) is very sensitive to domain shift. In this paper, we argue that this is a dual effect of the highly lexicalized nature of NMT, resulting in failure for sentences with large numbers of unknown words, and lack of supervision for domain-specific words. To remedy this problem, we propose an unsupervised adaptation method which fine-tunes a pre-trained out-of-domain NMT model using a pseudo-in-domain corpus. Specifically, we perform lexicon induction to extract an in-domain lexicon, and construct a pseudo-parallel in-domain corpus by performing word-for-word back-translation of monolingual in-domain target sentences. In five domains over twenty pairwise adaptation settings and two model architectures, our method achieves consistent improvements without using any in-domain parallel sentences, improving up to 14 BLEU over unadapted models, and up to 2 BLEU over strong back-translation baselines. Code is available here.
Beyond BLEU:Training Neural Machine Translation with Semantic Similarity
- Authors: John Wieting, Taylor Berg-Kirkpatrick, Kevin Gimpel, Graham Neubig
- Time: Wednesday, July 31. 11:50–12:10 Session 6D: Machine Translation 3
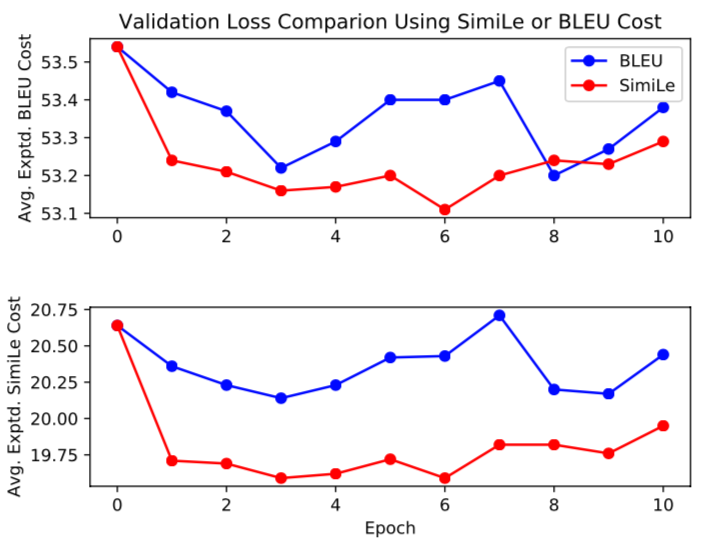
While most neural machine translation (NMT) systems are still trained using maximum likelihood estimation, recent work has demonstrated that optimizing systems to directly improve evaluation metrics such as BLEU can substantially improve final translation accuracy. However, training with BLEU has some limitations: it doesn’t assign partial credit, it has a limited range of output values, and it can penalize semantically correct hypotheses if they differ lexically from the reference. In this paper, we introduce an alternative reward function for optimizing NMT systems that is based on recent work in semantic similarity. We evaluate on four disparate languages translated to English, and find that training with our proposed metric results in better translations as evaluated by BLEU, semantic similarity, and human evaluation, and also that the optimization procedure converges faster. Analysis suggests that this is because the proposed metric is more conducive to optimization, assigning partial credit and providing more diversity in scores than BLEU. Code is available here.
Simple and Effective Paraphrastic Similarity from Parallel Translations
- Authors: John Wieting, Kevin Gimpel, Graham Neubig, Taylor Berg-Kirkpatrick
- Time: Wednesday, July 31. 10:30–12:10 Poster Session 6.
We present a model and methodology for learning paraphrastic sentence embeddings directly from bitext, removing the time-consuming intermediate step of creating paraphrase corpora. Further, we show that the resulting model can be applied to cross-lingual tasks where it both outperforms and is orders of magnitude faster than more complex stateof-the-art baselines. Code is available here.
Reranking for Neural Semantic Parsing
- Authors: Pengcheng Yin, Graham Neubig.
- Time: Wednesday, July 31. 10:30–12:10 Poster Session 6.

Semantic parsing considers the task of transducing natural language (NL) utterances into machine executable meaning representations (MRs). While neural network-based semantic parsers have achieved impressive improvements over previous methods, results are still far from perfect, and cursory manual inspection can easily identify obvious problems such as lack of adequacy or coherence of the generated MRs. This paper presents a simple approach to quickly iterate and improve the performance of an existing neural semantic parser by reranking an n-best list of predicted MRs, using features that are designed to fix observed problems with baseline models. We implement our reranker in a competitive neural semantic parser and test on four semantic parsing (GEO, ATIS) and Python code generation (DJANGO, CONALA) tasks, improving the strong baseline parser by up to 5.7% absolute in BLEU (CONALA) and 2.9% in accuracy (DJANGO), outperforming the best published neural parser results on all four datasets.
Generalized Data Augmentation for Low-Resource Translation
- Authors: Mengzhou Xia, Xiang Kong, Antonios Anastasopoulos, Graham Neubig.
- Time: Wednesday, July 31: 16:00–16:20 Session 8D: Machine Translation 4
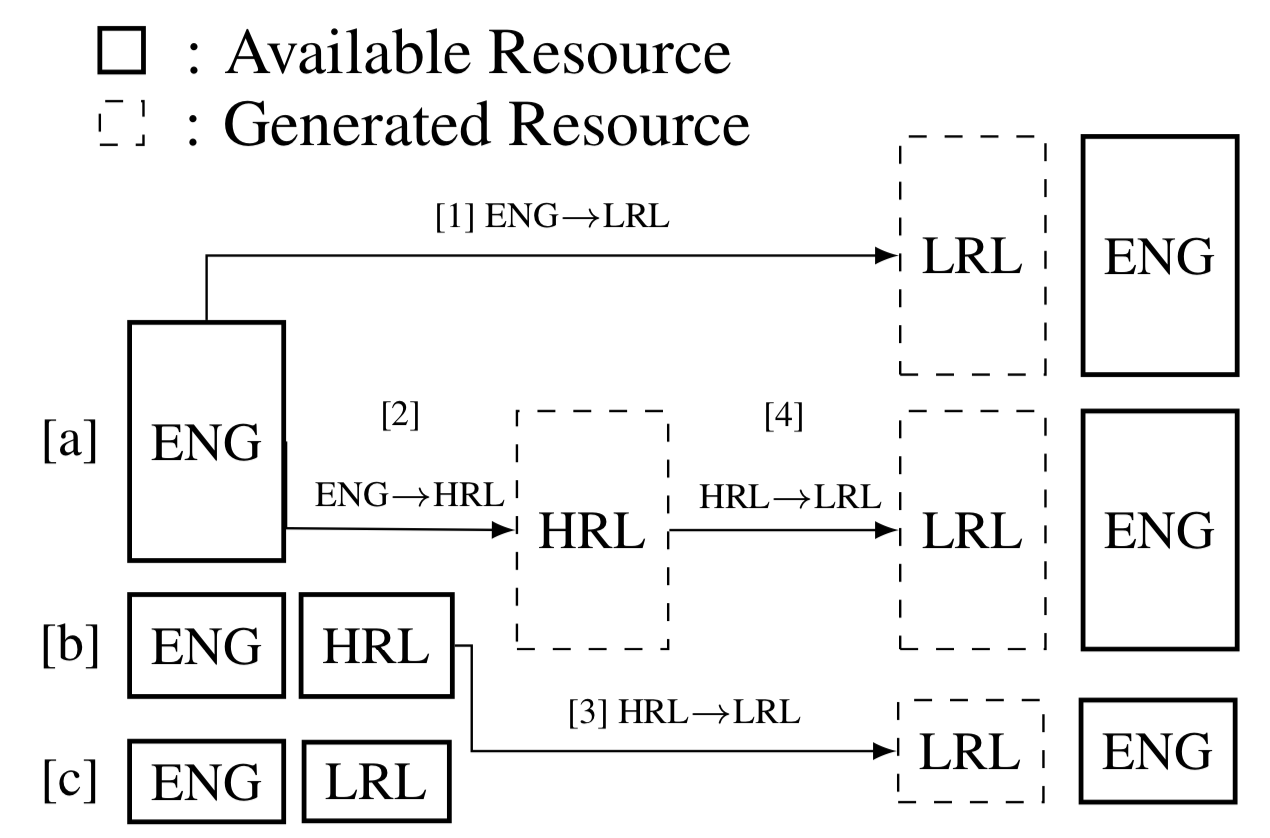
Translation to or from low-resource languages LRLs poses challenges for machine translation in terms of both adequacy and fluency. Data augmentation utilizing large amounts of monolingual data is regarded as an effective way to alleviate these problems. In this paper, we propose a general framework for data augmentation in low-resource machine translation that not only uses target-side monolingual data, but also pivots through a related high-resource language HRL. Specifically, we experiment with a two-step pivoting method to convert high-resource data to the LRL, making use of available resources to better approximate the true data distribution of the LRL. First, we inject LRL words into HRL sentences through an induced bilingual dictionary. Second, we further edit these modified sentences using a modified unsupervised machine translation framework. Extensive experiments on four low-resource datasets show that under extreme low-resource settings, our data augmentation techniques improve translation quality by up to~1.5 to~8 BLEU points compared to supervised back-translation baselines. Code is available here.
Attention-Passing Models for Robust and Data-Efficient End-to-End Speech Translation (TACL)
- Authors: Matthias Sperber, Graham Neubig, Jan Niehues, Alex Waibel.
- Time: Wednesday, July 31: 16:20–16:40 Session 8D: Machine Translation 4
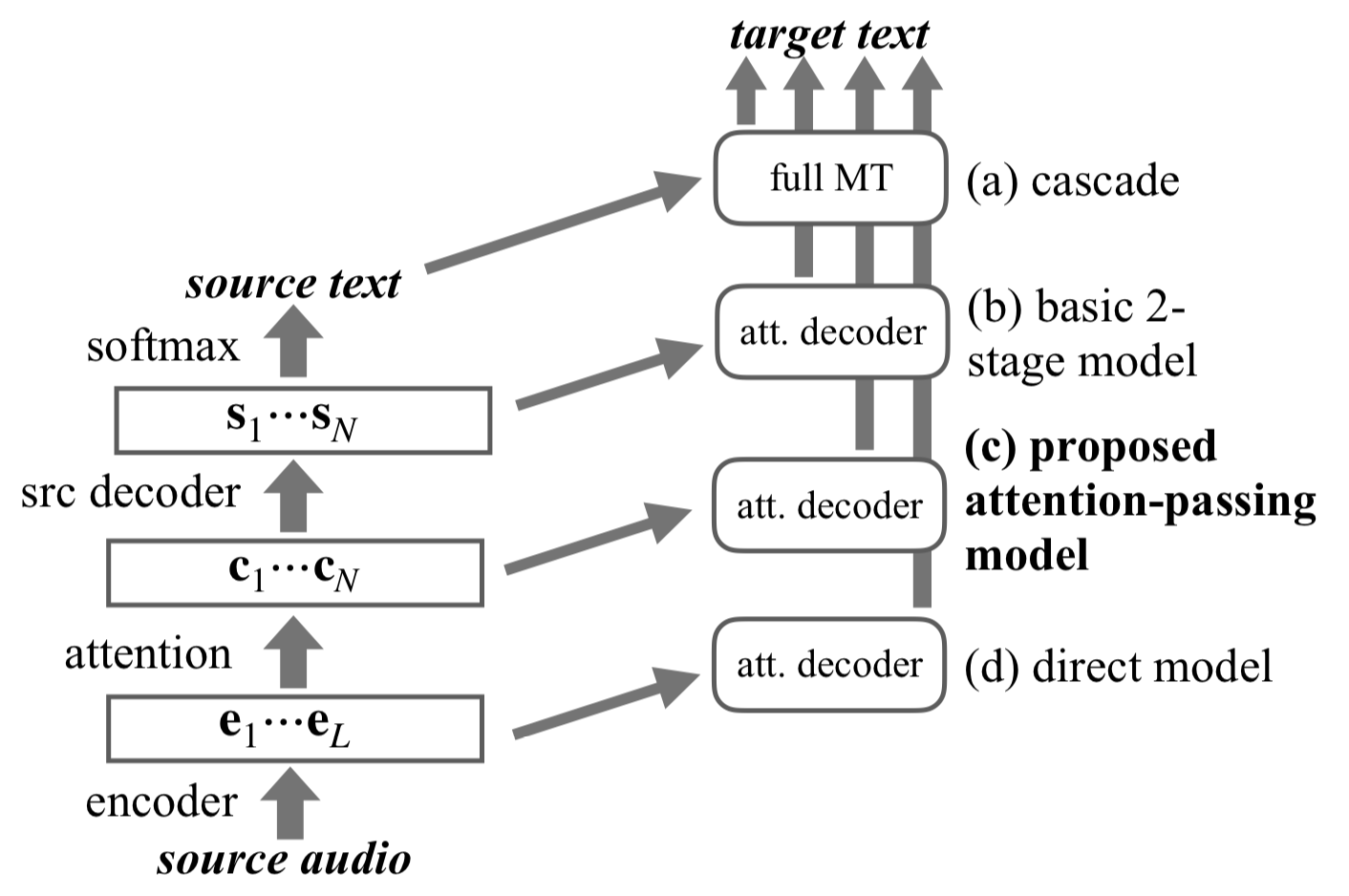
Speech translation has traditionally been approached through cascaded models consisting of a speech recognizer trained on a corpus of transcribed speech, and a machine translation system trained on parallel texts. Several recent works have shown the feasibility of collapsing the cascade into a single, direct model that can be trained in an end-to-end fashion on a corpus of translated speech. However, experiments are inconclusive on whether the cascade or the direct model is stronger, and have only been conducted under the unrealistic assumption that both are trained on equal amounts of data, ignoring other available speech recognition and machine translation corpora. In this paper, we demonstrate that direct speech translation models require more data to perform well than cascaded models, and while they allow including auxiliary data through multi-task training, they are poor at exploiting such data, putting them at a severe disadvantage. As a remedy, we propose the use of end-to-end trainable models with two attention mechanisms, the first establishing source speech to source text alignments, the second modeling source to target text alignment. We show that such models naturally decompose into multi-task-trainable recognition and translation tasks and propose an attention-passing technique that alleviates error propagation issues in a previous formulation of a model with two attention stages. Our proposed model outperforms all examined baselines and is able to exploit auxiliary training data much more effectively than direct attentional models.
Target Conditioned Sampling: Optimizing Data Selection for Multilingual Neural Machine Translation
- Authors: Xinyi Wang, Graham Neubig.
- Time: Wednesday, July 31. 17:26-17:39 Session 8D: Machine Translation 4

To improve low-resource Neural Machine Translation (NMT) with multilingual corpora, training on the most related high-resource language only is often more effective than using all data available (Neubig and Hu, 2018). However, it is possible that an intelligent data selection strategy can further improve low-resource NMT with data from other auxiliary languages. In this paper, we seek to construct a sampling distribution over all multilingual data, so that it minimizes the training loss of the low-resource language. Based on this formulation, we propose an efficient algorithm, Target Conditioned Sampling (TCS), which first samples a target sentence, and then conditionally samples its source sentence. Experiments show that TCS brings significant gains of up to 2 BLEU on three of four languages we test, with minimal training overhead. Code is available here.
Improving Open Information Extraction via Iterative Rank-Aware Learning
- Authors: Zhengbao Jiang, Pengcheng Yin, Graham Neubig
- Time: Wednesday, July 31st. 13:50–15:30 Poster Session 7
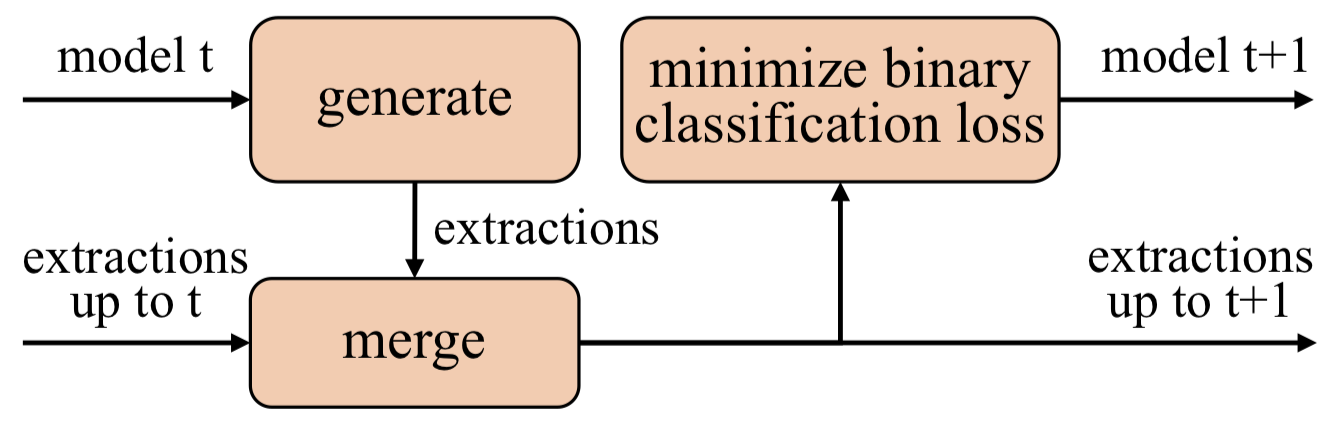
Open information extraction (IE) is the task of extracting open-domain assertions from natural language sentences. A key step in open IE is confidence modeling, ranking the extractions based on their estimated quality to adjust precision and recall of extracted assertions. We found that the extraction likelihood, a confidence measure used by current supervised open IE systems, is not well calibrated when comparing the quality of assertions extracted from different sentences. We propose an additional binary classification loss to calibrate the likelihood to make it more globally comparable, and an iterative learning process, where extractions generated by the open IE model are incrementally included as training samples to help the model learn from trial and error. Experiments on OIE2016 demonstrate the effectiveness of our method. Code is available here.
Combating Adversarial Misspellings with Robust Word Recognition
- Authors: Danish Pruthi, Bhuwan Dhingra and Zachary C. Lipton
- Time: Wednesday, July 31st. 13:50–15:30 Poster Session 7

To combat adversarial spelling mistakes, we propose placing a word recognition model in front of the downstream classifier. Our word recognition models build upon the RNN semi-character architecture, introducing several new backoff strategies for handling rare and unseen words. Trained to recognize words corrupted by random adds, drops, swaps, and keyboard mistakes, our method achieves 32% relative (and 3.3% absolute) error reduction over the vanilla semi-character model. Notably, our pipeline confers robustness on the downstream classifier, outperforming both adversarial training and off-the-shelf spell checkers. Against a BERT model fine-tuned for sentiment analysis, a single adversarially-chosen character attack lowers accuracy from 90.3% to 45.8%. Our defense restores accuracy to 75%. Surprisingly, better word recognition does not always entail greater robustness. Our analysis reveals that robustness also depends upon a quantity that we denote the sensitivity. Code is available here.
WMT 2019 Papers
Findings of the First Shared Task on Machine Translation Robustness
- Authors: Xian Li, Paul Michel, Antonios Anastasopoulos, Yonatan Belinkov, Nadir Durrani, Orhan Firat, Philipp Koehn, Graham Neubig, Juan Pino, Hassan Sajjad.
- Time: Thursday, August 1. 10:10-10:30.

We share the findings of the first shared task on improving robustness of Machine Translation (MT). The task provides a testbed representing challenges facing MT models deployed in the real world, and facilitates new approaches to improve models’ robustness to noisy input and domain mismatch. We focus on two language pairs (English-French and English-Japanese), and the submitted systems are evaluated on a blind test set consisting of noisy comments on Reddit1 and professionally sourced translations. As a new task, we received 23 submissions by 11 participating teams from universities, companies, national labs, etc. All submitted systems achieved large improvements over baselines, with the best improvement having +22.33 BLEU. We evaluated submissions by both human judgment and automatic evaluation (BLEU), which shows high correlations (Pearson’s r = 0.94 and 0.95). Furthermore, we conducted a qualitative analysis of the submitted systems using compare-mt2, which revealed their salient differences in handling challenges in this task. Such analysis provides additional insights when there is occasional disagreement between human judgment and BLEU, e.g. systems better at producing colloquial expressions received higher score from human judgment. Task web site can be found here.
Improving Robustness of Neural Machine Translation with Multi-task Learning
- Authors: Shuyan Zhou, Xiangkai Zeng, Yingqi Zhou, Antonios Anastasopoulos and Graham Neubig.
- Time: Thursday, August 1. 11:00-12:30.
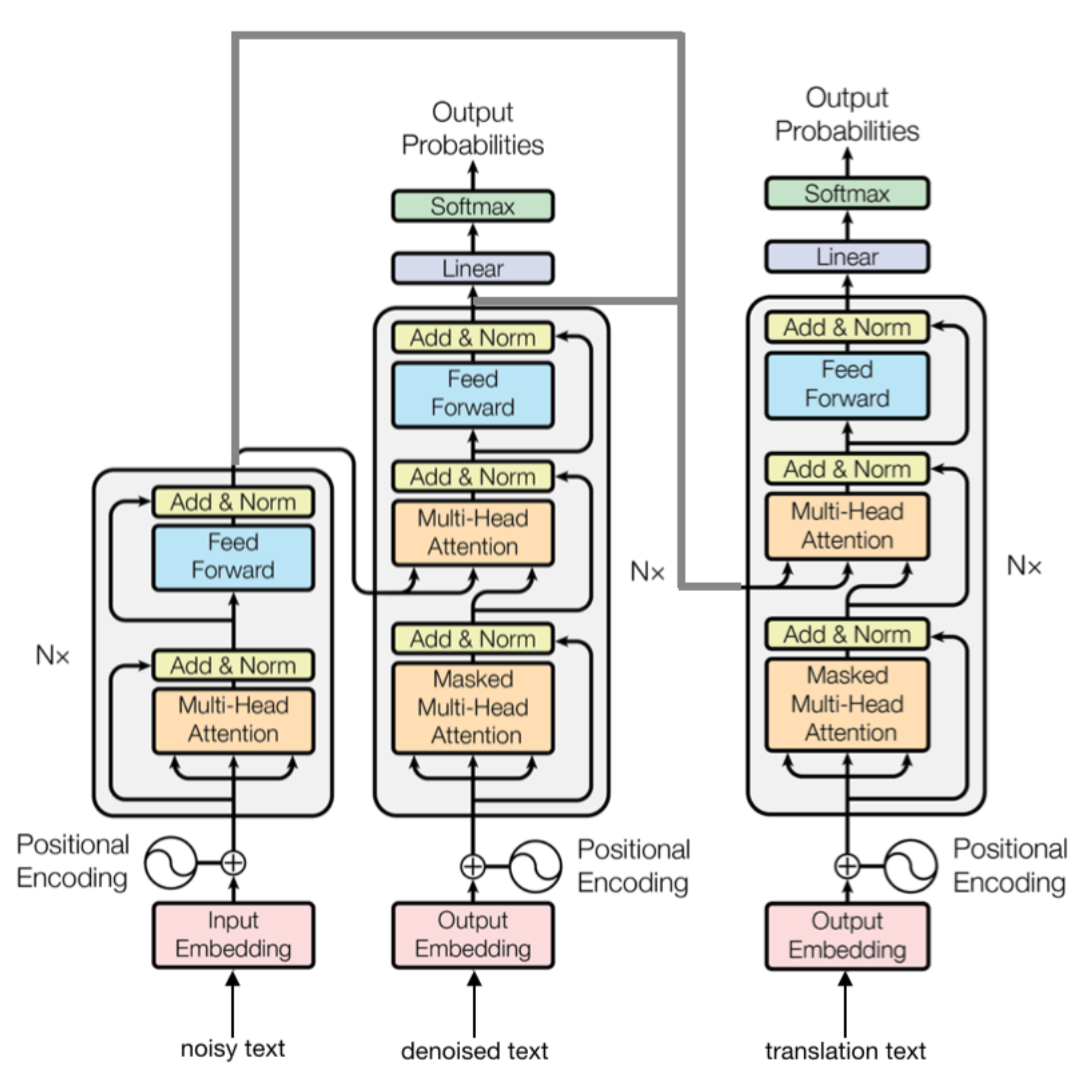
While neural machine translation (NMT) achieves remarkable performance on clean, in-domain text, performance is known to degrade drastically when facing text which is full of typos, grammatical errors and other varieties of noise. In this work, we propose a multi-task learning algorithm for transformer-based MT systems that is more resilient to this noise. We describe our submission to the WMT 2019 Robustness shared task based on this method. Our model achieves a BLEU score of 32.8 on the shared task French to English dataset, which is 7.1 BLEU points higher than the baseline vanilla transformer trained with clean text. Code is available here.
BlackBoxNLP 2019 Papers
An Analysis of Source-Side Grammatical Errors in NMT
- Authors: Antonios Anastasopoulos.
- Time: Thursday, August 1. 14:50-16:00. Poster Session 2.

The quality of Neural Machine Translation (NMT) has been shown to significantly degrade when confronted with source-side noise. We present the first large-scale study of state-of-the-art English-to-German NMT on real grammatical noise, by evaluating on several Grammar Correction corpora. We present methods for evaluating NMT robustness without true references, and we use them for extensive analysis of the effects that different grammatical errors have on the NMT output. We also introduce a technique for visualizing the divergence distribution caused by a source-side error, which allows for additional insights.