NeuLab Presentations at NAACL 2019
NeuLab members have seven main conference paper presentations, a demo presentation, and an invited talk at NAACL 2019! Come check them out if you’re in Minneapolis for the conference.
Main Conference Papers
Lost in Interpretation: Predicting Untranslated Terminology in Simultaneous Interpretation
- Authors: Nikolai Vogler, Craig Stewart, Graham Neubig.
- Time: Monday June 3, 2019, 12:12-12:30. Speech Session. Nicollet A.

Simultaneous interpretation, the translation of speech from one language to another in real-time, is an inherently difficult and strenuous task. One of the greatest challenges faced by interpreters is the accurate translation of difficult terminology like proper names, numbers, or other entities. Intelligent computer-assisted interpreting (CAI) tools that could analyze the spoken word and detect terms likely to be untranslated by an interpreter could reduce translation error and improve interpreter performance. In this paper, we propose a task of predicting which terminology simultaneous interpreters will leave untranslated, and examine methods that perform this task using supervised sequence taggers. We describe a number of task-specific features explicitly designed to indicate when an interpreter may struggle with translating a word. Experimental results on a newly-annotated version of the NAIST Simultaneous Translation Corpus (Shimizu et al., 2014) indicate the promise of our proposed method. Code is available here.
Competence-based Curriculum Learning for Neural Machine Translation
- Authors: Emmanouil Antonios Platanios, Otilia Stretcu, Graham Neubig, Barnabas Poczos, Tom M. Mitchell.
- Time: Monday June 3, 2019, 17:18-17:36. Machine Translation Session. Nicollet B/C.
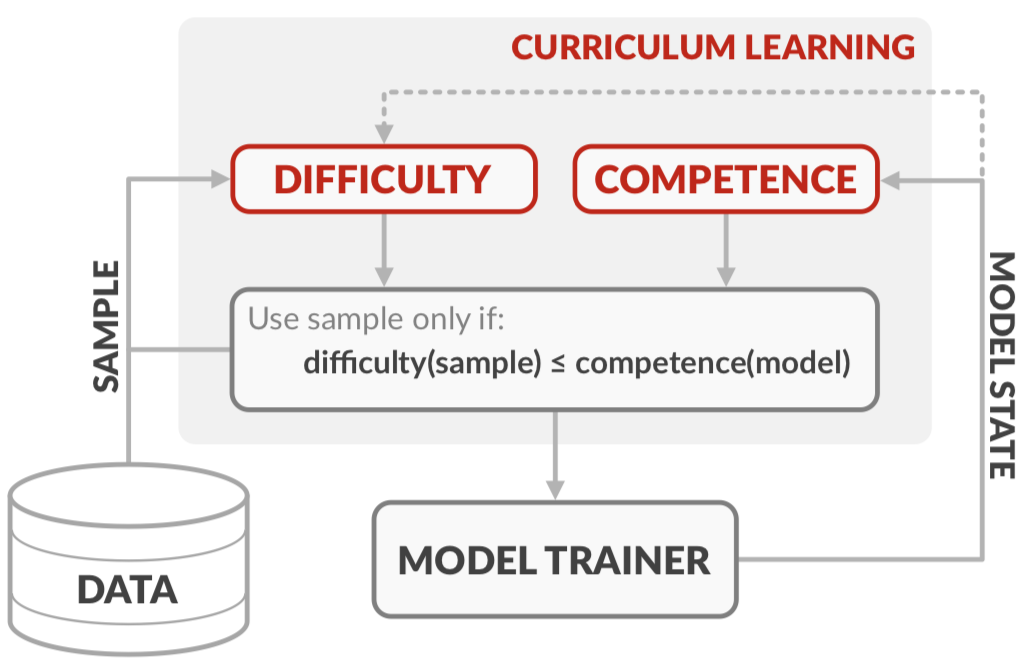
Current state-of-the-art NMT systems use large neural networks that are not only slow to train, but also often require many heuristics and optimization tricks, such as specialized learning rate schedules and large batch sizes. This is undesirable as it requires extensive hyperparameter tuning. In this paper, we propose a curriculum learning framework for NMT that reduces training time, reduces the need for specialized heuristics or large batch sizes, and results in overall better performance. Our framework consists of a principled way of deciding which training samples are shown to the model at different times during training, based on the estimated difficulty of a sample and the current competence of the model. Filtering training samples in this manner prevents the model from getting stuck in bad local optima, making it converge faster and reach a better solution than the common approach of uniformly sampling training examples. Furthermore, the proposed method can be easily applied to existing NMT models by simply modifying their input data pipelines. We show that our framework can help improve the training time and the performance of both recurrent neural network models and Transformers, achieving up to a 70% decrease in training time, while at the same time obtaining accuracy improvements of up to 2.2 BLEU. Code is available here.
Density Matching for Bilingual Word Embedding
- Authors: Chunting Zhou, Xuezhe Ma, Di Wang, Graham Neubig.
- Time: Tuesday, June 4, 2019 9:54-10:12. Multilingual NLP Session. Nicollet D.
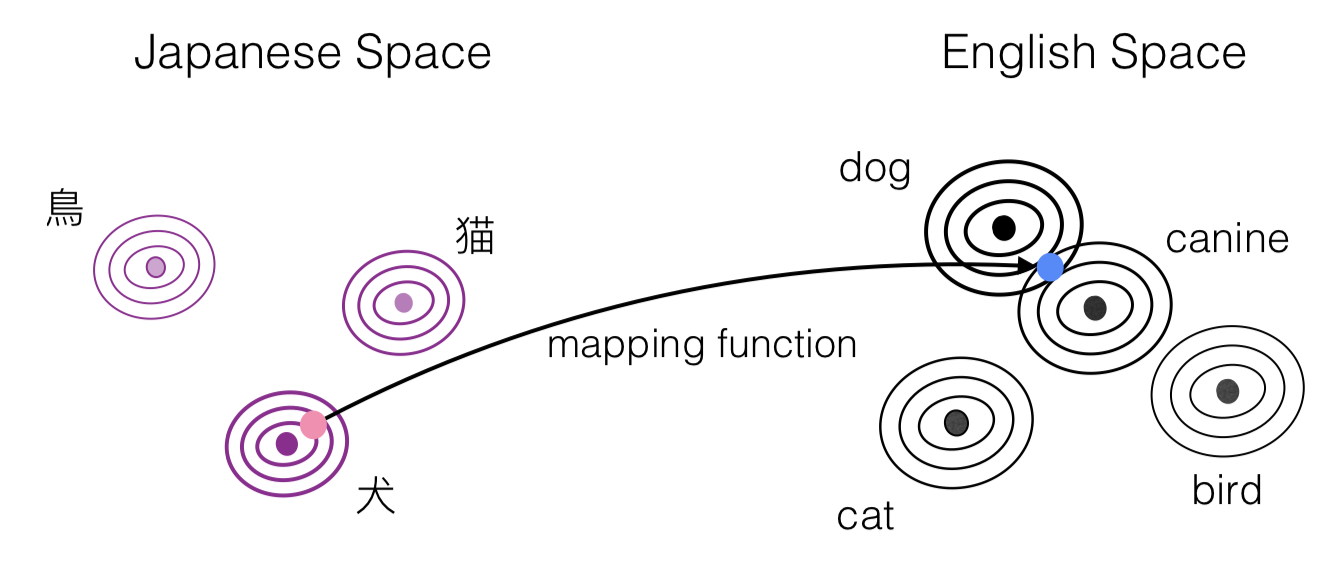
Recent approaches to cross-lingual word embedding have generally been based on linear transformations between the sets of embedding vectors in the two languages. In this paper, we propose an approach that instead expresses the two monolingual embedding spaces as probability densities defined by a Gaussian mixture model, and matches the two densities using a method called normalizing flow. The method requires no explicit supervision, and can be learned with only a seed dictionary of words that have identical strings. We argue that this formulation has several intuitively attractive properties, particularly with the respect to improving robustness and generalization to mappings between difficult language pairs or word pairs. On a benchmark data set of bilingual lexicon induction and cross-lingual word similarity, our approach can achieve competitive or superior performance compared to state-of-the-art published results, with particularly strong results being found on etymologically distant and/or morphologically rich languages. Code is available here.
Improving Robustness of Machine Translation with Synthetic Noise
- Authors: Vaibhav Vaibhav, Sumeet Singh, Craig Stewart, Graham Neubig.
- Time: Tuesday, June 4, 2019 9:00-10:30. Poster Session. Hyatt Exhibit Hall.

Modern Machine Translation (MT) systems perform consistently well on clean, in-domain text. However most human generated text, particularly in the realm of social media, is full of typos, slang, dialect, idiolect and other noise which can have a disastrous impact on the accuracy of output translation. In this paper we leverage the Machine Translation of Noisy Text (MTNT) dataset to enhance the robustness of MT systems by emulating naturally occurring noise in otherwise clean data. Synthesizing noise in this manner we are ultimately able to make a vanilla MT system resilient to naturally occurring noise and partially mitigate loss in accuracy resulting therefrom. Code is available here.
Neural Machine Translation of Text from Non-Native Speakers
- Authors: Antonios Anastasopoulos, Alison Lui, Toan Nguyen, David Chiang.
- Time: Wednesday, June 5, 2019 10:30-10:48.

Neural Machine Translation (NMT) systems are known to degrade when confronted with noisy data, especially when the system is trained only on clean data. In this paper, we show that augmenting training data with sentences containing artificially-introduced grammatical errors can make the system more robust to such errors. In combination with an automatic grammar error correction system, we can recover 1.5 BLEU out of 2.4 BLEU lost due to grammatical errors. We also present a set of Spanish translations of the JFLEG grammar error correction corpus, which allows for testing NMT robustness to real grammatical errors.
On Evaluation of Adversarial Perturbations for Sequence-to-Sequence Models
- Authors: Paul Michel, Xian Li, Graham Neubig, Juan Miguel Pino.
- Time: Wednesday, June 5, 2019 11:24-11:42. Machine Translation Session. Northstar A.

Adversarial examples — perturbations to the input of a model that elicit large changes in the output — have been shown to be an effective way of assessing the robustness of sequence-to-sequence (seq2seq) models. However, these perturbations only indicate weaknesses in the model if they do not change the input so significantly that it legitimately results in changes in the expected output. This fact has largely been ignored in the evaluations of the growing body of related literature. Using the example of untargeted attacks on machine translation (MT), we propose a new evaluation framework for adversarial attacks on seq2seq models that takes the semantic equivalence of the pre- and post-perturbation input into account. Using this framework, we demonstrate that existing methods may not preserve meaning in general, breaking the aforementioned assumption that source side perturbations should not result in changes in the expected output. We further use this framework to demonstrate that adding additional constraints on attacks allows for adversarial perturbations that are more meaning-preserving, but nonetheless largely change the output sequence. Finally, we show that performing untargeted adversarial training with meaning-preserving attacks is beneficial to the model in terms of adversarial robustness, without hurting test performance. Code is available here.
Learning to Describe Phrases with Local and Global Contexts
- Authors: Shonosuke Ishiwatari, Hiroaki Hayashi, Naoki Yoshinaga, Graham Neubig, Shoetsu Sato, Masashi Toyoda and Masaru Kitsuregawa.
- Time: Wednesday, June 5, 2019 14:24-14:42. Discourse Session. Northstar A.
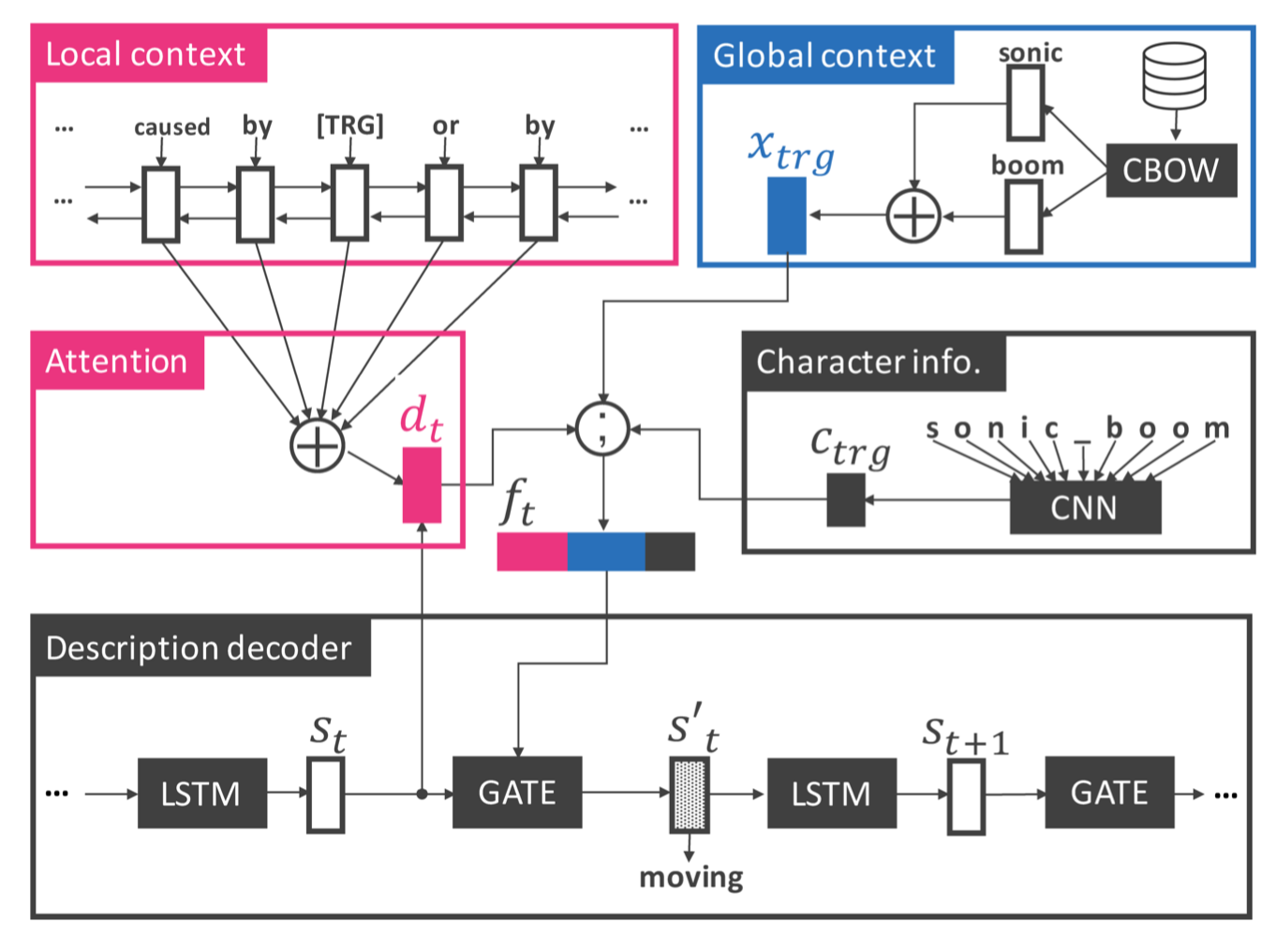
When reading a text, it is common to become stuck on unfamiliar words and phrases, such as polysemous words with novel senses, rarely used idioms, internet slang, or emerging entities. If we humans cannot figure out the meaning of those expressions from the immediate local context, we consult dictionaries for definitions or search documents or the web to find other global context to help in interpretation. Can machines help us do this work? Which type of context is more important for machines to solve the problem? To answer these questions, we undertake a task of describing a given phrase in natural language based on its local and global contexts. To solve this task, we propose a neural description model that consists of two context encoders and a description decoder. In contrast to the existing methods for non-standard English explanation [Ni+ 2017] and definition generation [Noraset+ 2017; Gadetsky+ 2018], our model appropriately takes important clues from both local and global contexts. Experimental results on three existing datasets (including WordNet, Oxford and Urban Dictionaries) and a dataset newly created from Wikipedia demonstrate the effectiveness of our method over previous work. Code is available here.
Demo Paper
compare-mt: A Tool for Holistic Comparison of Language Generation Systems
- Authors: Graham Neubig, Zi-Yi Dou, Junjie Hu, Paul Michel, Danish Pruthi, Xinyi Wang.
- Time: Monday, June 3, 2019 17:00-18:30. Poster Session. Hyatt Exhibit Hall.
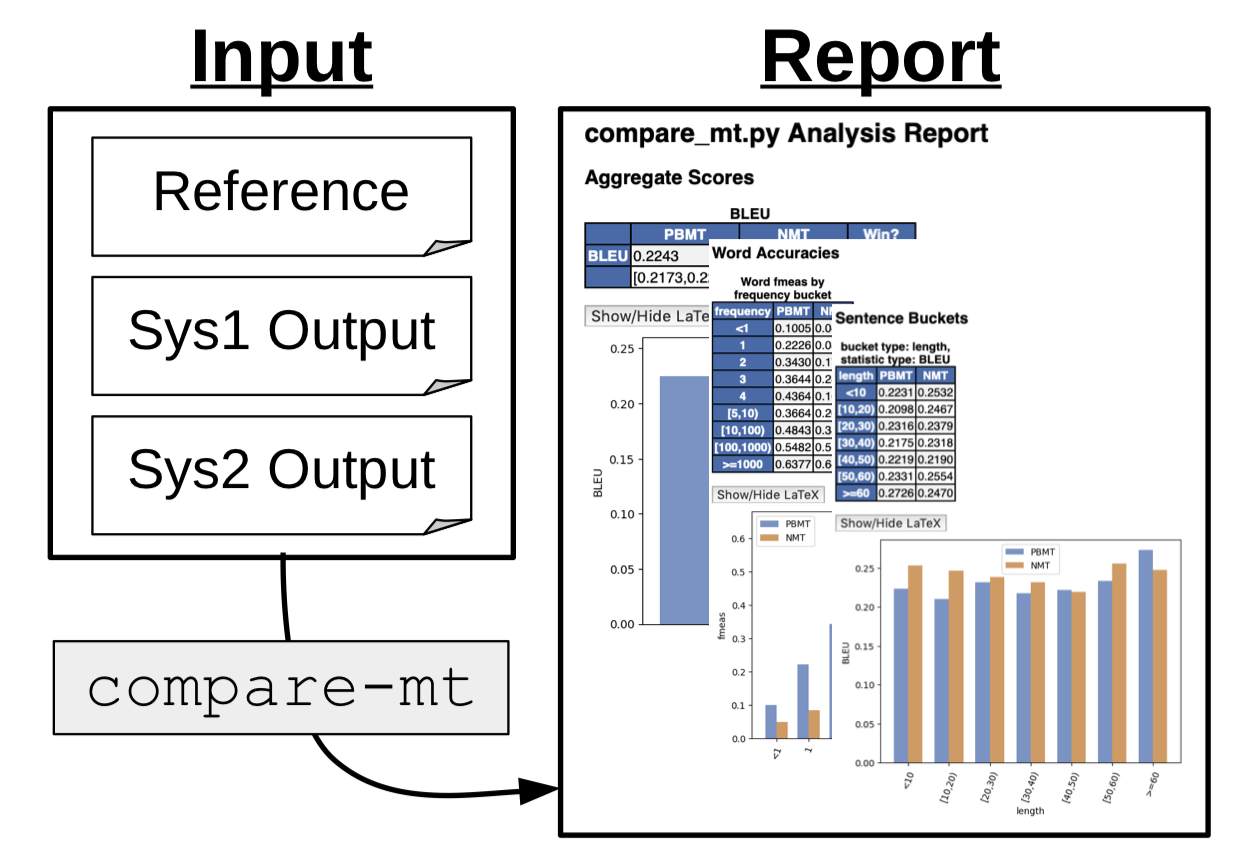
In this paper, we describe compare-mt, a tool for holistic analysis and comparison of the results of systems for language generation tasks such as machine translation. The main goal of the tool is to give the user a high-level and coherent view of the salient differences between systems that can then be used to guide further analysis or system improvement. It implements a number of tools to do so, such as analysis of accuracy of generation of particular types of words, bucketed histograms of sentence accuracies or counts based on salient characteristics, and extraction of characteristic n-grams for each system. It also has a number of advanced features such as use of linguistic labels, source side data, or comparison of log likelihoods for probabilistic models, and also aims to be easily extensible by users to new types of analysis. Code is available here.
Talk
Methods for Optimizing and Evaluating Neural Language Generation
What can Statistical Machine Translation teach Neural Text Generation about Optimization?
- Speaker: Graham Neubig.
- Time: Thursday, June 6, 2019 9:05-9:45.
In 2016, I co-authored a wide-sweeping survey on training techniques for statistical machine translation. This survey was promptly, and perhaps appropriately, forgotten in the tsunami of enthusiasm for new advances in neural methods for text generation. Now that the dust has settled after five intense years of research into neural sequence-to-sequence models and training methods therefore, perhaps it is time to revisit our old knowledge and see what it can teach us with respect to training techniques for neural models. In this talk, I will broadly overview several years of research into sequence-level training objectives for neural networks, then point out a several areas where our understanding of training techniques that still lag significantly behind what we knew for more traditional approaches to SMT.