NeuLab Presentations at NAACL 2018
NeuLab members have six paper presentations, a tutorial, and an invited talk at NAACL 2018, one of the top conferences in natural language processing and computational linguistics! Come check them out if you’re in New Orleans for the conference.
Tutorial
Modelling Natural Language, Programs, and their Intersection
- Authors: Graham Neubig and Miltiadis Allamanis.
- Time: Friday, June 1, Morning Tutorial Session (9:00-12:30).

As computers and information grow a more integral part of our world, it is becoming more and more important for humans to be able to interact with their computers in complex ways. One way to do so is by programming, but the ability to understand and generate programming languages is a highly specialized skill. As a result, in the past several years there has been an increasing research interest in methods that focus on the intersection of programming and natural language, allowing users to use natural language to interact with computers in the complex ways that programs allow us to do. In this tutorial, we will focus on machine learning models of programs and natural language focused on making this goal a reality. First, we will discuss the similarities and differences between programming and natural language. Then we will discuss methods that have been designed to cover a variety of tasks in this field, including automatic explanation of programs in natural language (code-to-language), automatic generation of programs from natural language specifications (language-to-code), modeling the natural language elements of source code, and analysis of communication in collaborative programming communities. The tutorial will be aimed at NLP researchers and practitioners, aiming to describe the interesting opportunities that models at the intersection of natural and programming languages provide, and also how their techniques could provide benefit to the practice of software engineering as a whole.
Invited Talk
Morphology – When is it Useful in Neural Models?
- Authors: Graham Neubig.
- Time: SCLeM Workshop, June 6, 2:00-2:45
In this talk, I will cover several topics related to morphology: how is the best way to analyze it, and how can we effectively incorporate it into neural models?
Main Conference
Attentive Interaction Model: Modeling Changes in View in Argumentation
- Authors: Yohan Jo, Shivani Poddar, Byungsoo Jeon, Qinlan Shen, Carolyn Rose and Graham Neubig.
- Time: Saturday, June 2, 10:30-12:00, Elite Hall B.

We present a neural architecture for modeling argumentative dialogue that explicitly models the interplay between an Opinion Holder’s (OH’s) reasoning and a challenger’s argument, with the goal of predicting if the argument successfully changes the OH’s view. The model has two components: (1) vulnerable region detection, an attention model that identifies parts of the OH’s reasoning that are amenable to change, and (2) interaction encoding, which identifies the relationship between the content of the OH’s reasoning and that of the challenger’s argument. Based on evaluation on discussions from the Change My View forum on Reddit, the two components work together to predict an OH’s change in view, outperforming several baselines. A posthoc analysis suggests that sentences picked out by the attention model are addressed more frequently by successful arguments than by unsuccessful ones. Code and data are released open source.
Guiding Neural Machine Translation with Retrieved Translation Pieces
- Authors: Jingyi Zhang, Masao Utiyama, Eiichro Sumita, Graham Neubig and Satoshi Nakamura.
- Time: Sunday, June 3, 15:30-17:00, Elite Hall B.

One of the difficulties of neural machine translation (NMT) is the recall and appropriate translation of low-frequency words or phrases. In this paper, we propose a simple, fast, and effective method for recalling previously seen translation examples and incorporating them into the NMT decoding process. Specifically, for an input sentence, we use a search engine to retrieve sentence pairs whose source sides are similar with the input sentence, and then collect n-grams that are both in the retrieved target sentences and aligned with words that match in the source sentences, which we call “translation pieces”. We compute pseudoprobabilities for each retrieved sentence based on similarities between the input sentence and the retrieved source sentences, and use these to weight the retrieved translation pieces. Finally, an existing NMT model is used to translate the input sentence, with an additional bonus given to outputs that contain the collected translation pieces. We show our method improves NMT translation results up to 6 BLEU points on three narrow domain translation tasks where repetitiveness of the target sentences is particularly salient. It also causes little increase in the translation time, and compares favorably to another alternative retrievalbased method with respect to accuracy, speed, and simplicity of implementation.
Handling Homographs in Neural Machine Translation
- Authors: Frederick Liu, Han Lu and Graham Neubig.
- Time: Sunday, June 3, 15:30-17:00, Elite Hall B.

Homographs, words with different meanings but the same surface form, have long caused difficulty for machine translation systems, as it is difficult to select the correct translation based on the context. However, with the advent of neural machine translation (NMT) systems, which can theoretically take into account global sentential context, one may hypothesize that this problem has been alleviated. In this paper, we first provide empirical evidence that existing NMT systems in fact still have significant problems in properly translating ambiguous words. We then proceed to describe methods, inspired by the word sense disambiguation literature, that model the context of the input word with context-aware word embeddings that help to differentiate the word sense before feeding it into the encoder. Experiments on three language pairs demonstrate that such models improve the performance of NMT systems both in terms of BLEU score and in the accuracy of translating homographs. Code is available open source.
Using Morphological Knowledge in Open-Vocabulary Neural Language Models
- Authors: Austin Matthews, Graham Neubig and Chris Dyer.
- Time: Sunday, June 3, 14:00-15:30, Elite Hall B.
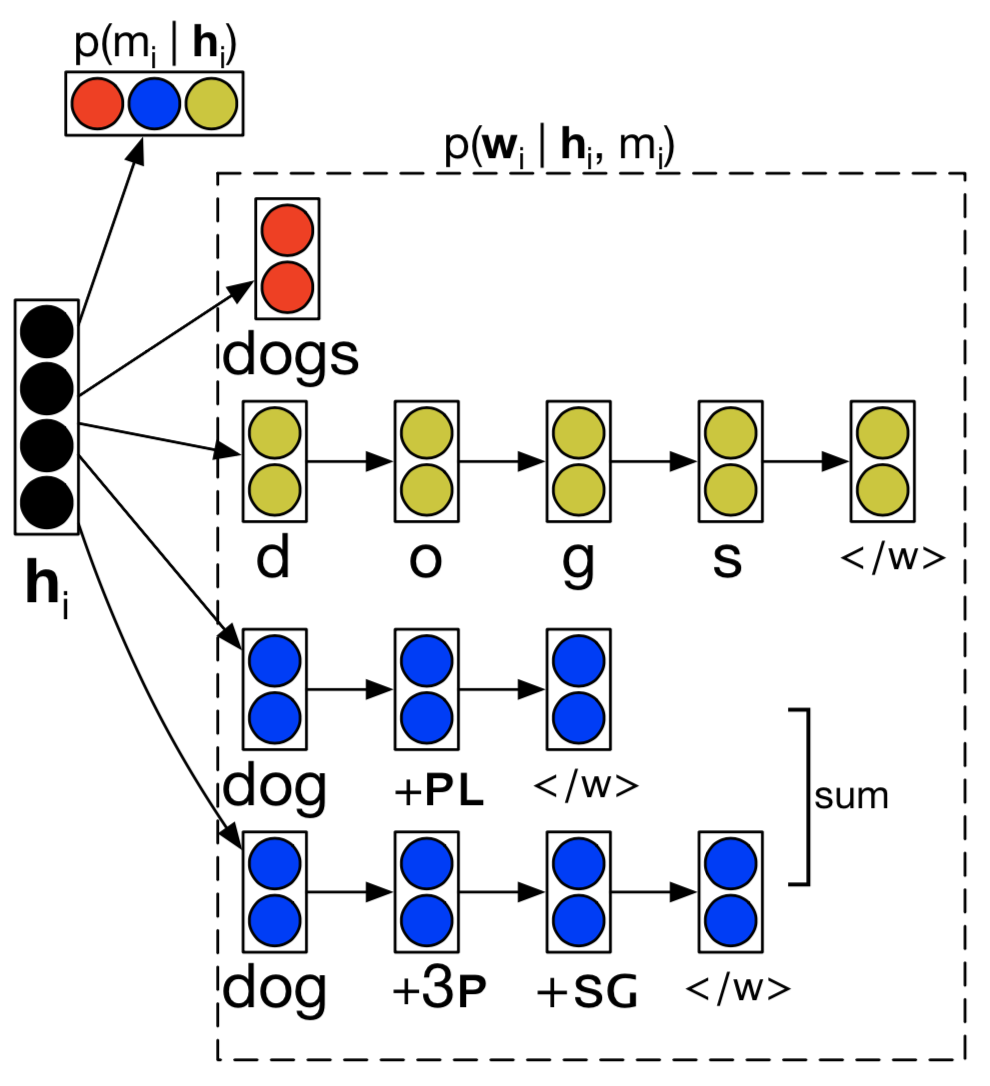
Languages with productive morphology pose problems for language models that generate words from a fixed vocabulary. Although character-based models allow any possible word type to be generated, they are linguistically naïve: they must discover that words exist and are delimited by spaces—basic linguistic facts that are built in to the structure of word-based models. We introduce an openvocabulary language model that incorporates more sophisticated linguistic knowledge by predicting words using a mixture of three generative processes: (1) by generating words as a sequence of characters, (2) by directly generating full word forms, and (3) by generating words as a sequence of morphemes that are combined using a hand-written morphological analyzer. Experiments on Finnish, Turkish, and Russian show that our model outperforms character sequence models and other strong baselines on intrinsic and extrinsic measures. Furthermore, we show that our model learns to exploit morphological knowledge encoded in the analyzer, and, as a byproduct, it can perform effective unsupervised morphological disambiguation.
When and Why Are Pre-trained Word Embeddings Useful for Neural Machine Translation?
- Authors: Ye Qi, Devendra Sachan, Matthieu Felix, Sarguna Padmanabhan and Graham Neubig.
- Time: Sunday, June 3, 15:30-17:00, Elite Hall B.

The performance of Neural Machine Translation (NMT) systems often suffers in lowresource scenarios where sufficiently largescale parallel corpora cannot be obtained. Pretrained word embeddings have proven to be invaluable for improving performance in natural language analysis tasks, which often suffer from paucity of data. However, their utility for NMT has not been extensively explored. In this work, we perform five sets of experiments that analyze when we can expect pre-trained word embeddings to help in NMT tasks. We show that such embeddings can be surprisingly effective in some cases – providing gains of up to 20 BLEU points in the most favorable setting. Scripts/data to reproduce experiments have been released.
Neural Lattice Language Models
- Authors: Jacob Buckman and Graham Neubig.
- Time: Sunday, June 3, 15:30-17:00, Elite Hall B.

In this work, we propose a new language modeling paradigm that has the ability to perform both prediction and moderation of information flow at multiple granularities: neural lattice language models. These models work by constructing a lattice of possible paths through a sentence and marginalizing across this lattice to calculate probability of a sequence or optimize parameters. This approach allows us to seamlessly incorporate linguistic intuitions – including polysemy and existence of multiword lexical items – into our language model. We evaluate our approach on multiple language modeling tasks and show that a neural lattice model over English that utilizes polysemous embeddings is able to improve perplexity by 9.95% relative to a word-level baseline, and a Chinese neural lattice language model that handles multi-character tokens is able to improve perplexity by 20.94% relative to a character-level baseline. Code has been released open-source.