Contents
1. Overview
This document discusses the parsing utilities provided by the Lemur toolkit. They have been designed with flexibility and extendibility in mind. If the functionality required is not currently implemented by the toolkit, it should be easy to add the functionality and plug it into the parser framework. The first section describes the parser applications and their options. The other section describes the parser architecture or API for developers.2. The Parser Architecture for Lemur

The Lemur parser architecture revolves around one class, TextHandler, that allows for the chaining or pipelining of common parser components. A TextHandler may be a stop-word list, stemmer, indexer, or parser. Information is passed from a source, through TextHandlers that modify information and pass it on, to a destination TextHandler. An example of a source TextHandler would be a parser.A stemmer would modify text and pass the information on to other TextHandlers. A destination TextHandler might write parsed data to a file or push build an index. The diagram below is an example of how TextHandlers might be chained.
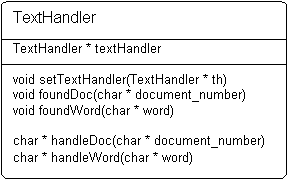
The TextHandler class enforces chaining through its interface. A diagram summarizing the functions of the TextHandler class is given below.The next TextHandler in a chain is set using the setTextHandler function. For example calling the Parser's setTextHandler function with an argument of the Stop-word list would cause information to be passed from the Parser to the Stop-word list.TextHandlers may modify the information it receives before passing the information on to the next TextHandler.To do this, provide implementations to either the handleDoc or handleWord functions.For example, a stemmer would stem the word in the handleWord function.An Indexer would need to implement both handleDoc and handleWord functions. Inside those functions, the Indexer would push the words and documents into an index.
The foundDoc and foundWord functions enforce the chaining of the calls.When either is called, the corresponding handleDoc/handleWord function is called with an argument of the document number or word. The foundDoc or foundWord function of the textHandler of the object is then called using the return value of the handleDoc/handleWord as the argument. Base implementations of all functions are provided by the TextHandler class, a subclass will only need to override the functions that it needs. In general, subclasses should only override handleDoc and handleWord functions. Classes that provide sources for information should call the foundWord and foundDoc functions of their textHandler.
The TextHandler class provides the basis for most of the classes used by Lemur for parsing. The hope is that this class will provide a flexible base for extending parser functionality. The following subsections discuss classes used by the parser applications. The only of the following classes that does not extend the TextHandler class is the WordSet class.
WordSet
The WordSet class is a simple wrapper to a set. It is useful for stop-word lists or acronym lists. It can load a list from a file. The file format is one word per line. WordSet does NOT remove white space on either side of the word be careful when editing these files. The contains function is used to check the presence of a word in the set.
Parser
The Parser class is a generic interface for the parsers in the toolkit. It assumes subclasses implement a parse function, which takes a filename. The acronym list is WordSet, and both parsers check uppercase words and recognized acronyms against this list. If the word is in the acronym list, it is left uppercase. Otherwise, the word is converted to lowercase. If you do not wish to support the acronym list when you design your parser, that is fine. You can simply ignore the acronym list.
Both the TrecParser and the WebParser remove contractions and possessives, have a simple acronym recognizer, and convert words to lowercase.
TrecParser
The TrecParser provides a simple but effective parser for NIST's TREC document format. It recognizes text in the TEXT, HL, HEAD, HEADLINE, TTL, and LP fields.
WebParser
The WebParser behaves very similarly to the TrecParser. It parses HTML documents in the NIST TREC format used for the Web Tracks.The parser removes HTML tags. Text within SCRIPT tags is removed, as is text in HTML comments.
ReutersParser
The ReutersParser extracts the TEXT, HEADLINE, and TITLE fields and removes other tags.
Stemmer
The Stemmer class provides an interface for stemmers. All that is required of a subclass is that it implement the stemWord function. The stemWord function should overwrite the current word. Currently, the toolkit provides one subclass, PorterStemmer.
PorterStemmer
PorterStemmer uses Porter's official stemmer (in c) to stem words. The PorterStemmer class does not stem words beginning with an uppercase letter. This is to prevent stemming of acronyms or names.
Stopper
The Stopper class is a subclass of the WordSet class and the TextHandler class. It replaces words in the stop-word list with a NULL pointer.
QueryTextHandler
The QueryTextHandler checks to see if a word in the query occurs more often in uppercase than original form in an Index. If the uppercase form is more common than the original form, the word is added to the query. This is to handle cases where acronyms are not capitalized in the query,
WriterTextHandler
The WriterTextHandler class writes information from a TextHandler chain to a file. This file is in a format compatible with BuildBasicIndex.
InvFPTextHander
The InvFPTextHandler takes information from a TextHandler chain and uses InvFPPushIndex to build an InvFPIndex. Stop-words are not counted in the document length.
3. The Parser Applications There are three parser applications provided in the toolkit. PushIndexer builds a database, ParseToFile writes parsed text to a file, and ParseQuery parses queries and writes output to file. All applications use a parameter file for specifying parameters for parsing. The format of the file is:parameter = value; /* comment */The first command line argument must be the parameter file. The other command line arguments specify the data files for applications to parse. 3.1 PushIndexer
PushIndexer builds a database using either the TrecParser or WebParser class and InvFPPushIndex.
Usage: PushIndexer paramfile [datfile1]* [datfile2]* ...
* data files can be specified on the command line OR in a file specified as the dataFiles parameter
Summary of parameters in paramfile:
- index Name of the index (without the .ifp extension).
- memory Memory (in bytes) of InvFPPushIndex (def = 96000000).
- stopwords Name of file containing stopword list. Words in this file should be one per line. If this parameter is not specified, all words are indexed.
- acronyms Name of file containing acronym list (one word per line). Uppercase words recognized as acronyms (e.g. USA U.S.A. USAs USA's U.S.A.) are left uppercase if in the acronym list. If no acronym list is specified, acronyms will not be recognized.
- docFormat Specify "trec" for standard TREC formatted documents or "web" for web TREC formatted documents. The default is "trec".
- stemmer Specify "porter" to use Porter's stemmer. If no stemmer is specified, no stemmer will be used.
- dataFiles Name of file containing list of datafiles (one line per datafile name). If not specified, must enter datafiles on command line.
ParseToFile parses documents and writes output compatible with BuildBasicIndex. The program uses either the TrecParser class or WebParser class to parse.
Usage: ParseToFile paramfile datfile1 datfile2 ...
Summary of parameters in paramfile:
-
outputFile Name of file to output parsed documents to.
- stopwords Name of file containing stopword list. Words in this file should be one per line. If this parameter is not specified, all words are output to the file.
-
acronyms
Name of file containing acronym list (one word per line). Uppercase words recognized as acronyms (e.g.
USA U.S.A. USAs USA's U.S.A.) are left uppercase if in the acronym list. If no acronym list is specified, acronyms
will not be recognized.
-
docFormat Specify trec for standard TREC formatted documents or web for web TREC formatted documents. The
default is trec.
- stemmer Specify porter to use Porter's stemmer.If no stemmer is specified, no stemmer will be used.
ParseQuery parses queries using either the TrecParser or WebParser class and an Index.
Usage: ParseQuery paramfile datfile1 datfile2 ...
Summary of parameters in paramfile:
-
queryOutFile The name of the file to write the parsed queries to.
- index
Name of the index (with the .ifp
or .bsc extension).
- stopwords
Name of file containing stopword list. Words in this file should be one per line. If this parameter is not specified, all words are left in the
query.Ā
- acronyms
NameĀ of file containing acronym list (one word per line). Uppercase words
recognized as acronyms (eg USA U.S.A. USAs USA's U.S.A.) are left uppercase as
USA if USA is in the acronym list.Ā If
no acronym list is specified, acronyms will not be recognized.
- docFormat Specify trec for standard TREC formatted documents or web for web TREC formatted documents. The
default is trec.
- stemmer Specify porter to use Porter's stemmer. If no stemmer is specified, no stemmer will be used.
The Lemur Project Last modified: Thu Dec 13 16:32:42 EST 2001