Volumetric Features for Event
Recognition in Video
People
Description

Overview
This project explores the use of volumetric features for
event detection. We propose a novel method to correlate spatio-temporal
shapes to video clips that have been automatically segmented. Our method works
on over-segmented videos, which means that we do not require background
subtraction for reliable object segmentation. Our method, when combined
with a recent flow-based correlation technique, can detect a wide range of
actions in video.
Examples
Automatic Video Segmentation
The first step
is to extract spatio-temporal shape contours in the video using an unsupervised
clustering technique. This enables us to ignore highly variable and potentially
irrelevant features of the video such as color and texture, while preserving the
object boundaries needed for shape classification. As a preprocessing step, the
video is automatically segmented into regions in space-time using mean shift,
with color and location as the input features. This is the spatio-temporal
equivalent of the concept of superpixels. Figure 2 shows an example video
sequence and the resulting segmentation. Note that there is no explicit
figure/ground separation in the segmentation and that the objects are
over-segmented.

Volumetric video segmentation. We use mean
shift to segment the video in space-time. Volumetric segmentation leads to more
consistent regions over time, versus segmenting individual frames.
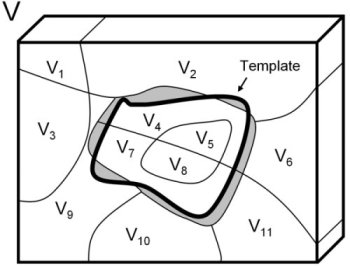
Shape Matching
Our shape matching metric is
based on the region intersection distance between the template volume and the
set of over-segmented volumes in the video. Figure 3 shows the volumetric
model of an example handwave action. The model spans both space and
time. Figure 4 illustrates how a template is matched to set of
over-segmented regions. The shape template can be efficiently scanned over
the video and events are detected when the matching distance falls below a
specified threshold.
 |
 |
| Example volumetric model of a
handwave action. |
Our shape matching
algorithm is based on region intersection between two shapes. The
shaded area represents the distance between the template and the
video. We are able to match the template with over-segmented regions
and the running time is linearly proportional to the surface area of the
three-dimensional template. |
Recognition
Like all template-based matching
techniques our baseline shape matching technique suffers from limited
generalization power due to the variability in how different people perform the
same action. A standard approach to improve generalization is to break the model
into parts, allowing the parts to move independently, and to measure the joint
appearance and geometric matching score of the parts. Allowing the parts to move
makes the template more robust to the spatial and temporal variability of
actions. This idea has been studied extensively in recognition in both images
and video. Therefore, we extend our baseline matching algorithm by introducing a
parts-based volumetric shape-matching model, illustrated in Figure 5.
Specifically, we extend the pictorial structures framework to video volumes to
model the geometric configuration of the parts and to find the optimal match in
both appearance and configuration in the video.
 |
 |
| Wave Action -- Whole
Template |
Wave Action -- Parts
Model |
| We break the template into parts for more
robustness and improved generalization
ability. |
Video of Detection Results
Event
detection in cluttered videos.
[ZIP 8MB]
Event
detection in tennis sequence.
[TAR.GZ 36MB]
References
Yan Ke,
Rahul Sukthankar,
and
Martial
Hebert.
Event Detection in Cluttered Videos.
ICCV, 2007.
[PDF
1.7MB]
Yan Ke,
Rahul Sukthankar,
and
Martial
Hebert.
Spatio-temporal Shape and Flow Correlation
for Action Recognition. Visual Surveillance
Workshop, 2007.
[PDF
1.1MB]
Yan Ke,
Rahul Sukthankar,
and
Martial
Hebert.
Efficient Temporal Mean Shift for Activity
Recognition in Video. NIPS Workshop on Activity
Recognition and Discovery, 2005.
[Paper
PDF 70KB] [Poster
PDF 900KB]
Yan Ke,
Rahul Sukthankar,
and
Martial
Hebert.
Efficient Visual Event Detection using
Volumetric Features. International Conference on
Computer Vision, 2005.
[PDF
630KB]
Funding
This research is supported by:
Copyright notice


