SpecDS—simple tools for spectral learning of dynamical systems
Software
Here is the code, as a zip archive. It is licensed under the GPL—see the download for more information.The most important function is specds.m, for learning a dynamical system from data.
An example of usage is in hmmex.m: it builds a simple HMM, samples from it, and learns it back from the sampled data. See the walkthrough below for more information.
This is a very simple implementation; most of the complexity comes from the way we compute covariance matrices in specds.m, which is more complex than it should be to keep Matlab from running out of memory by making many copies of the observations. A bit more complexity could probably make this computation a lot faster as well, but that's not implemented yet.
The best documentation of this algorithm is probably the ICML tutorial slides. The following paper contains more information, but some details are slightly out of date:
Byron Boots, Sajid Siddiqi, and Geoff Gordon. Closing the Learning-Planning Loop with Predictive State Representations. International Journal of Robotics Research (IJRR), 30(7):954-966, 2011.
Walkthrough
Once you've downloaded the code and uncompressed it, switch Matlab to the specds directory, and load the file hmmex.m. The file uses cell mode: if you select the menu item Cell/Enable cell mode, you can then use Cmd-Enter (or Ctrl-Enter on a PC) to execute each cell, one at a time. Or, you can simply run the file all at once; the code includes short pauses between each plot.The first cell sets some parameters for later learning, then builds a simple HMM. The second cell visualizes the HMM:
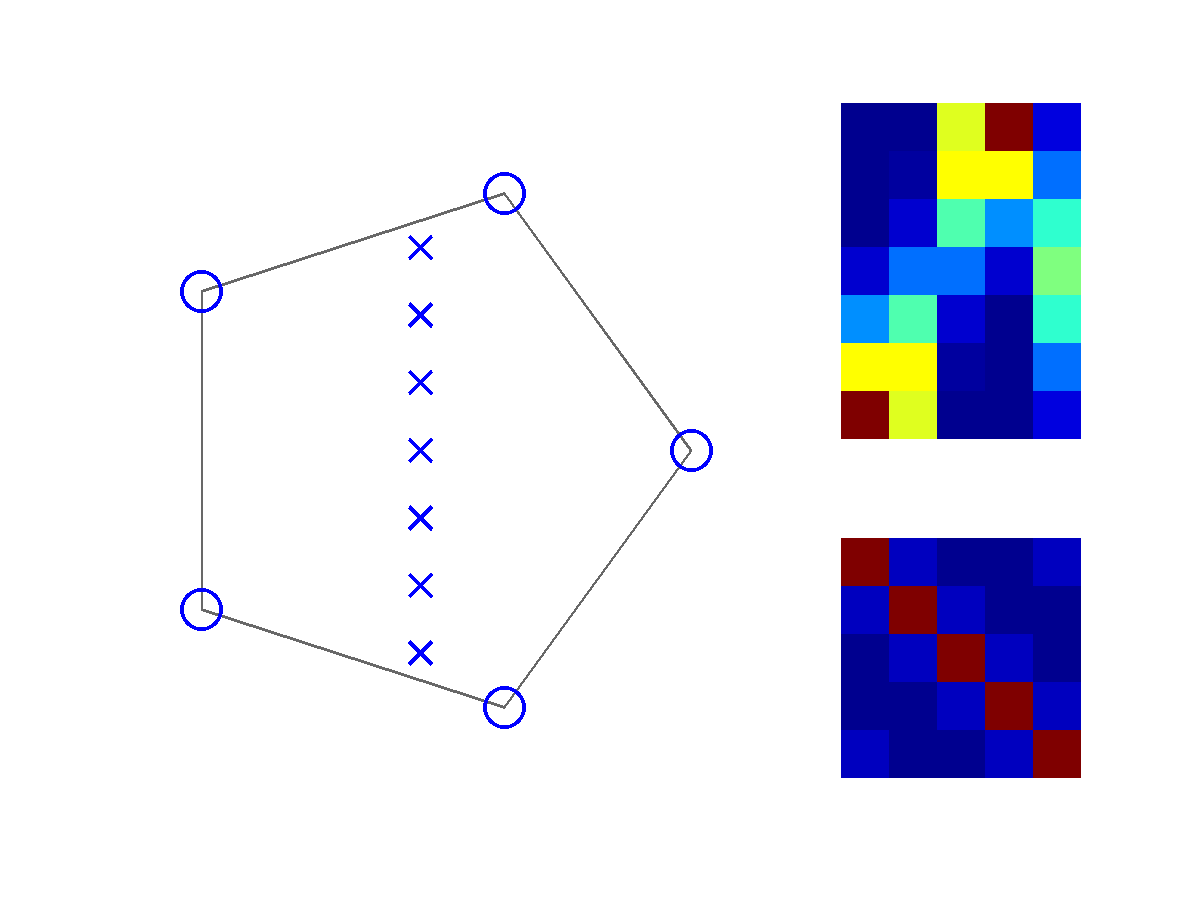
The HMM is generated by placing states (circles) and observations (crosses) in the plane. Transition probabilities are higher between nearby states, and observation probabilities are higher for nearby (state, observation) pairs. The left-hand plot shows the placements, while the right hand heat maps show the transition (lower) and observation (upper) probabilities. Each column corresponds to a possible current state; each row gives the probability distribution for either the next state or the next observation.
The third cell samples a single trajectory of 50k time steps from the
HMM, and the fourth cell displays a portion of the sampled trajectory:

In this figure, the first block of 7 rows shows 200 consecutive time steps: entry (i,t) is 1 if we saw observation i at step t, and 0 otherwise. Subsequent blocks of rows are shifted left, one time step at a time. One of the important quantities in the spectral learning algorithm is the covariance of the columns of this repeatedly-shifted-and-stacked matrix of observations. In particular, if we consider the green line to be the present, then everything above the green line is the past, and everything below is the future; we then want the covariance of the past with the future. (In the code, npast controls the number of time steps we look back into the past, and nfut controls the number of time steps we look into the future. Using a window like this is not necessary for the algorithm—we can use arbitrary features of the past and future—but such a window is a simple and useful choice of features.)
The fifth cell learns back the model: the call is
modl = specds(obsmat, [], npast, nfut, k, lambda);Here obsmat is the matrix of sampled observations (before shifting and stacking—the code does this for you). The parameters are the window lengths, the desired state-space dimension k of the learned model, and a regularization (ridge) parameter lambda. The output modl is a matlab struct:
modl =
npast: 10
nfut: 5
k: 10
lambda: 1
obsbasis: []
nlabs: 0
nobs: 7
futbasis: [35x10 double]
labelbasis: [0x10 double]
svs: [10x1 double]
past2state: [10x70 double]
sbar: [11x1 double]
s1: [11x1 double]
trso: [11x11x7 double]
tro: [7x11x7 double]
The fields are documented in the code, but the most important ones are
sbar (the learned steady-state belief) and tro and
trso (the learned model parameters). These can be used for
tracking, as described in the above paper, and as will be illustrated
below.The code can also take a cell array of observation matrices instead of obsmat (in case we have observed more than one trajectory from the same dynamical system). The second parameter (empty in this case) is for partial supervision: we can use trajectory-level or observation-level labels to help us learn a better state space. These labels only need to be present at train time, and we can predict them if desired at test time. (Use help specds for more information about these and other features.)
The sixth cell compares the true and learned models:
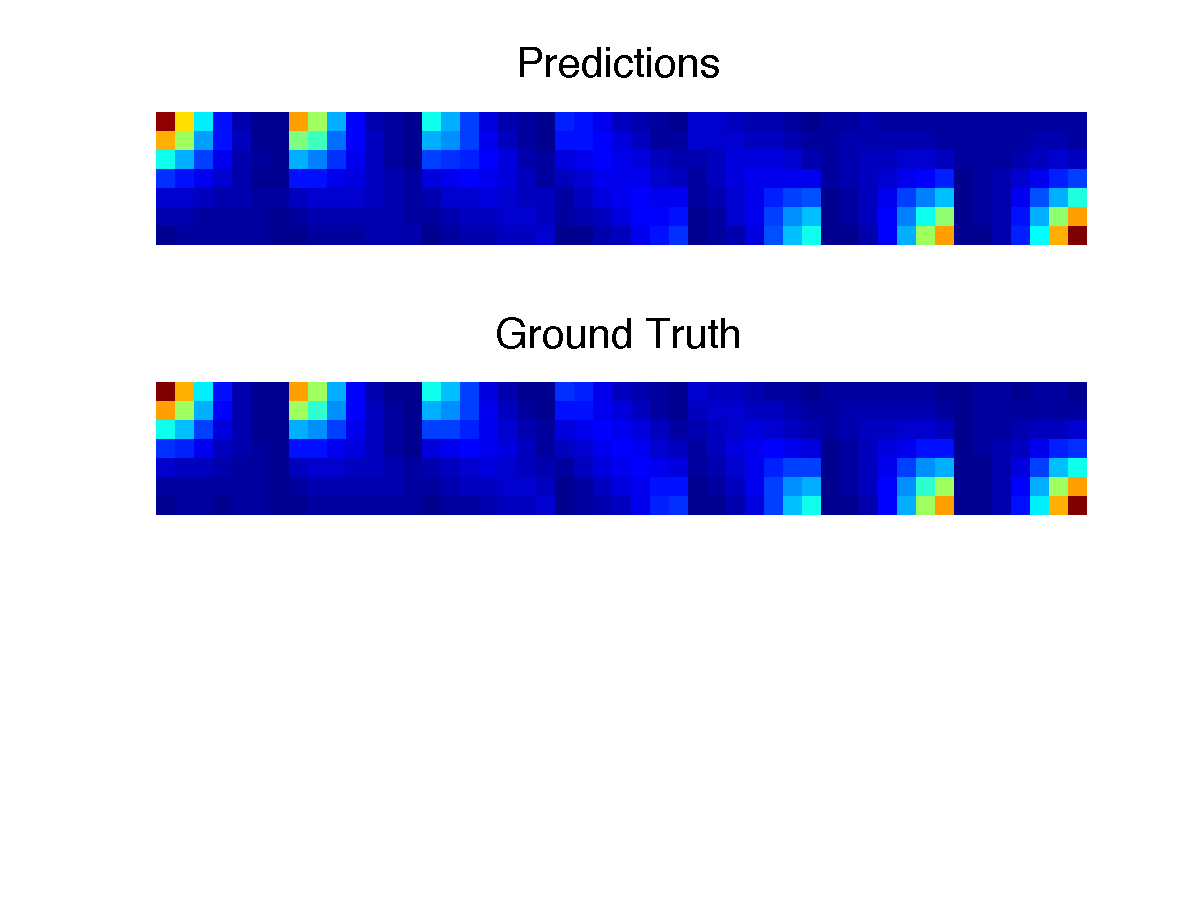
Each plot in this image shows the probability density of triples of consecutive observations—one for the true model and one for the learned model. (They look nearly identical, but there are actually small differences.) In each plot, the major blocks correspond to the seven possible initial observations in the triple; the second observation corresponds to moving left or right in each block, and the third to moving up and down.
Making this plot provides a nice example of how to use the learned model: to get the modeled probability distribution over triples, we start from sbar, then apply the tracking update twice (for the first two observations, represented as ei and ej in the code). We read off the probabilities of each of these observations and multiply them together; finally, we multiply by the probabilities of all possible final observations to get a column of the preds matrix.
In general, if the state is in st and we have observed ei, the filtering update is:
ocov = tensprod(modl.tro, st, 2, 1); st = tensprod(modl.trso, st, 2, 1) * (ocov \ ei);and the diagonal of ocov will contain the probabilities of all possible observations at st. (These estimated probabilities should always sum to 1, but some may be negative if we have tried to learn a high-dimensional model from little data.)
The seventh and last cell in the file makes a convergence plot. (This cell may take a little while to run, since it is repeatedly calling the learning algorithm, using data sets of up to nearly a million time steps.)
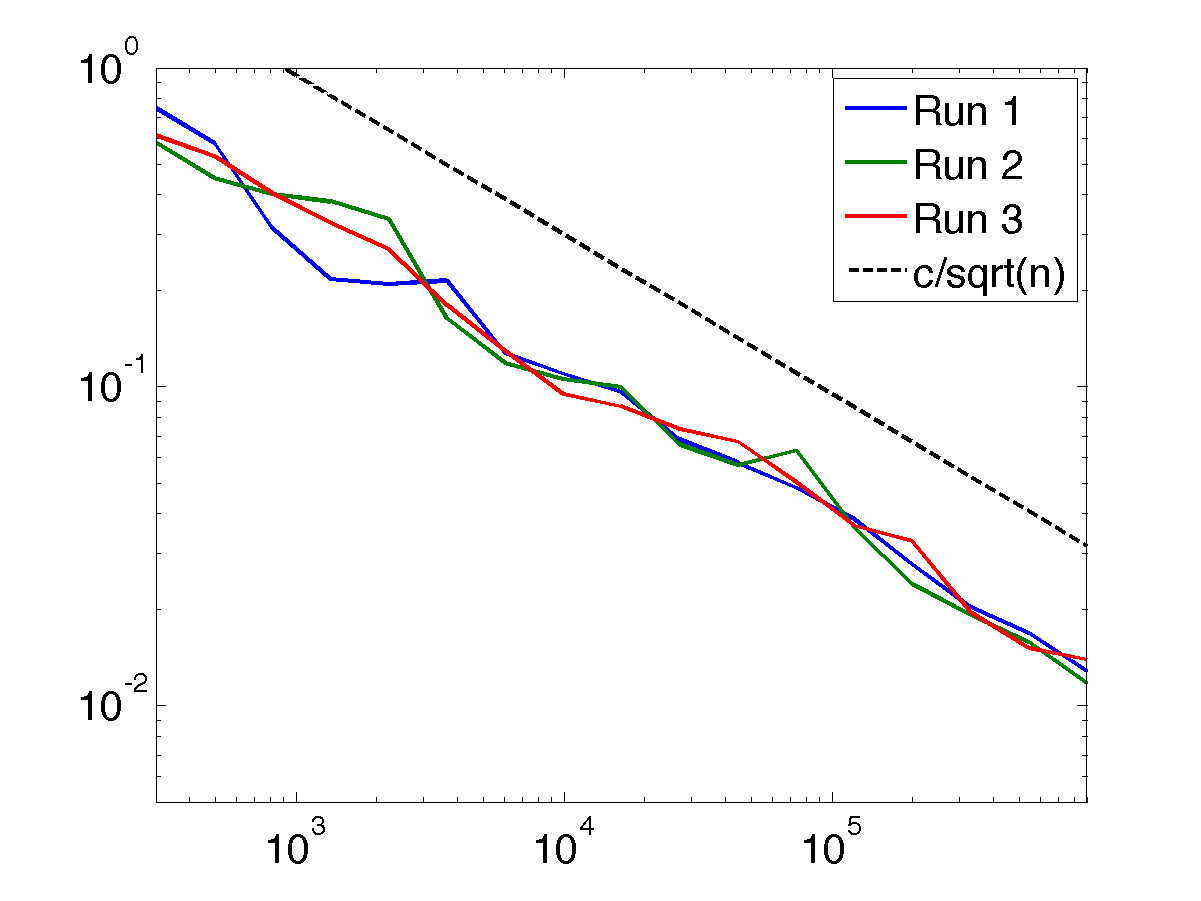
The image shows three separate runs of the model. For each run, it plots the error between the true and learned model—the L1 difference between the two matrices in the previous figure. This error is scaled so that a value of 1 means that we are doing only as well as if we had predicted a uniform distribution. (Note the log scales on both axes.) For comparison, the plot also includes a straight line of slope -1/2, corresponding to the expected convergence rate of O(1/√n) for n time steps worth of data.