This is a supporting website for the paper:
Aligning context-based statistical models of language with brain activity during reading
Leila Wehbe, Ashish Vaswani, Kevin Knight and Tom Mitchell
Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP)
paper bibtex talkThis work is part of a larger project to study story processing, which includes other experiments: website for fMRI experiment
Brain Processes
In this paper, we use brain activity recordings to identify the the timing and location of the brain processes that are related to reading a text and constructing its meaning. More specifically, we are interested in the following processes that occur at each word when reading a story serially:
(a) keeping track of the previous context,
(b) perceiving the current word, and
(c) integrating the current word with the previous context.
We use Magnetoencephalography (MEG) in order to record the word-by-word brain activity when subjects read a complex chapter from a real novel. We chose a real passage of text to have a naturalistic experiment that mimics real-life behavior of the brain. More specifically, when compared to unrelated sentences, a real text is a much richer sample of the broad natural range of single word meanings and complex context representations.
In order to look for where and when these abstract processes occur in the brain, we need to model them numerically so we can reveal associations with the MEG data. For that purpose, we use context-based Neural Network Language Models.
Neural Network Language Models
Context-based Neural Network Language Models are algorithms that compute the probability of the
word occurring next in a sentence, given the previous word.
The functions that are needed for them to work are learned on a large corpus of text.
After learning, these models can "read" the text word by word, always predicting the next word. In
order to function, they perform the following steps every time they encounter a word:
(a) The context before the current word is summarized in a high dimensional vector of real numbers. Since the model was learned in an unsupervised manner, the individual dimensions of vector are hard to interpret, but they corresponds to properties of the previous context.
(b) The properties of the current word are also summarized in a high dimensional vector of real numbers. These properties are the fixed properties of the word, and correspond to the definition of the word in a space learned by the model. They are also hard to interpret.
(c) The model can output the probability of the current word given the context before the word was seen.
Parallelism
There is therefore a correspondance between the brain processes underlying reading, and the Neural Network components. These components are numerical representation of the context, the properties of the current word and the probability of this word. They can therefore be used for the challenging task of uncovering the reading processes from brain activity. Specifically we will use:
The context vector, to uncover the brain representation of context.
The properties vector, to uncover where and when the brain perceives the incoming word.
The word probability, to uncover the integration process in the brain.
Methods
Data acquisition
We have brain activity recordings of 3 subjects who read a chapter from Harry Potter and the Sorcerer's Stone in the MEG scanner. The words were presented one by one
at the center of the screen for 0.5 seconds each.
Brain activity is recorded at 306 sensors dispersed around the brain, it also recorded at a high temporal resolution (1KHz), but we average the signal in 100ms non-overlapping time bins.
For every word, we therefore have 306 x 5 readings of brain activity for each subject.
Prediction and classification
Our aim is to uncover the three reading processes from brain activity, i.e. find where and when in the brain they occur.
We build here models that predict the MEG activity as a function of the different components. We assess
model performance in the following way:
(1) Choose one neural network representation (e.g.: context vector, properties vector or word probability).
(2) Choose a part of brain activity (e.g.: look at one time window such as 100-200ms after word onset, or look at one time window and the sensors in one region of the brain only).
(3) Using a subset of the data, learn a model that predicts the MEG activity for a word as a function of its neural network representation.
(4) Given the MEG recording for an unseen word, guess which of two words it corresponds to, by predicting the brain activity related to those two words using the learned model.
This is a binary classification task where chance is 50%.
For each neural network component, we find when and where in the brain we are able to classify with high accuracy. This metric identifies where and when the corresponding brain process
occur. The rationale is the following: if a brain process (e.g. perceiving a word) occurs at a given time / location (e.g. 200-300ms in the temporal cortex), then classification
using the corresponding Neural Network representation (e.g. the properties vector) might succeed and the accuracy would be significantly higher than chance. On the other hand, if this process doesn't occur at that time / location, then
the model will not be able to predict brain activity correctly and classification will fail.
Results
The time dynamics of context building
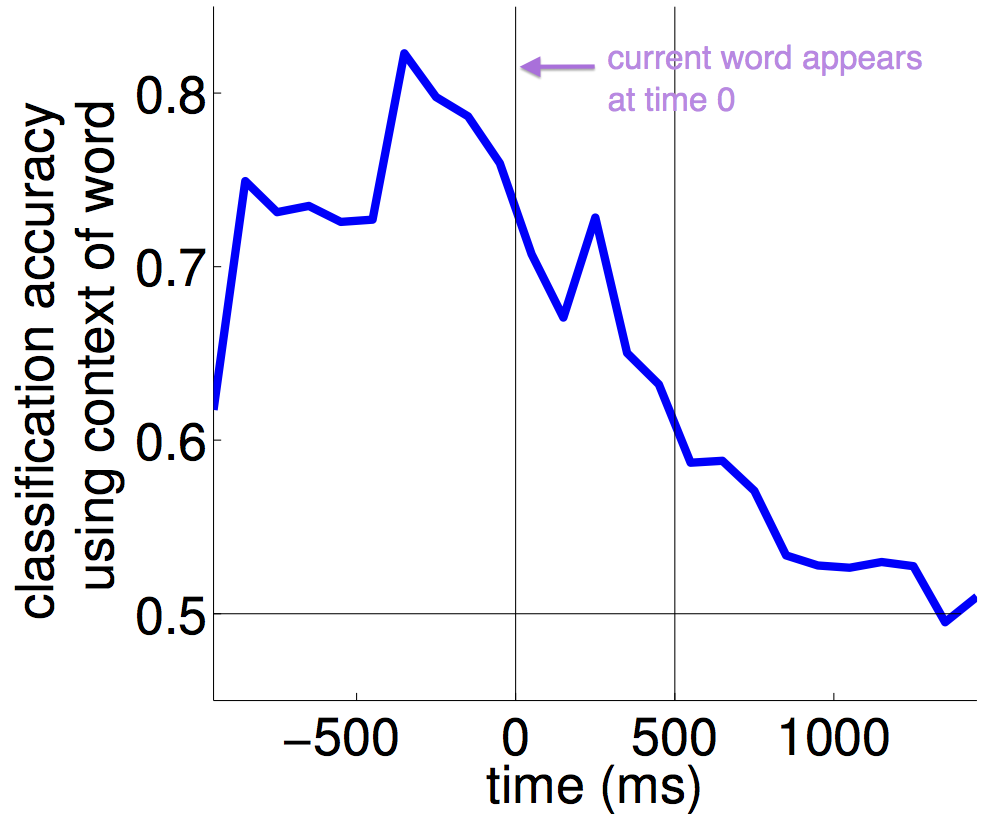
The above plot represents the accuracy in time when the context of the current word is used. 0 indicates the time when the current word appears on the screen.
Such a plot should be interpreted in the following way: high classification accuracy suggests that the corresponding brain process is occurring at that time. In this plot, the corresponding brain process is maintaining context. The plot has the following interpretation:
The context (before the word) is encoded by the brain before the word is on the screen. After the word appears, the brain starts changing its representation of context, and the classification accuracy with the old context vector drops,
until it cannot be used for classification anymore because the brain has changed its representation of context.
The progressive perception of the incoming word across the brain

The above plot represents a similar view of accuracy in time, however the classification has been retrained to specific brain regions. All curves that are visible correspond to significantly higher than chance accuracy. Every plot represents a location in the MEG helmet. The left,
right, front and back of the subject's head are indicated. The lower right plot indicates which cortical lobe each sensor samples from approximately. Here is our interpretation of the results:
There is a very interesting spatiotemporal progression of the encoding of the word's properties in the brain. There is an early
peak in the visual cortex (100-200ms), and as we move more anteriorly in the brain, the peak becomes later in the temporal lobes
(200-300ms), and even later in the frontal regions (300-400ms). This is consistent which the pathway of information after the word
is perceived in the visual cortex and the brain understands it on increasingly higher levels in increasingly anterior regions.
The integration of the new word with the previous context
Both left and right temporal cortices are involved in word integration (green ovals). This process occurs around 200-400ms. We are able to predict the MEG signal as a function of the word's probability. It seems like we are detecting the N400, a brain response which has been recently shown to not only be present for surprising target word, but to be a graded function of the word's surprisal [Frank et al., ACL 2013]. Here, we predict the brain activity of all words as a function of their probability, and not only target words.
Conclusion
Our results are consistent with a model of brain processing in which current brain activity encodes story context, and where each
new word generates additional brain activity that encodes information about the new word, flowing generally from visual posterior to left temporal,
and to increasingly anterior/frontal brain regions, culminating in an updated story context, and reflecting an overall magnitude of processing effort
that is influenced by the probability of the new word given the previous context.
Furthermore, our imaging experiment consists in a naturalistic reading task, in which a chapter from a popular novel is used. The hope behind simulating real life
reading is to make the results more generalizable. We model the brain activity related to every word, and not only specific target words. This is part of an effort to
build a generative model of the brain activity during reading.
Finally, we were able to align brain processes with uninterpretable neural network vectors. This line of thought promises to be useful not only for better understanding
brain data, but also for building better statistical language models. In their learning phase, these models will be constrained with data from a processing system that does understand language: the brain.
Contact
wehbe.contact@gmail.com