Addressing Feature Ambiguity for Point-Based 3D Object Recognition
People
Alvaro Collet Romea
Martial Hebert
Description
In many of the current point-based 3D object recognition systems, specific point-to-point correspondences from 3D model to 2D image are obtained initially by matching discriminative features. Much of the recent research in local image features has been to design descriptors that are as discriminative and robust as possible to obtain point-to-point matches. Discriminative matching, however, prevents features with similar descriptors from being matched, even though these features contain rich information about the pose of the object. The presence of similar features is an inherent issue in matching and no amount of tuning parameters or design of local features can circumvent this problem. In this project, we demonstrate that a small amount of generalization by quantizing the descriptors can significantly improve the robustness of matching and thus the performance of specific object recognition.
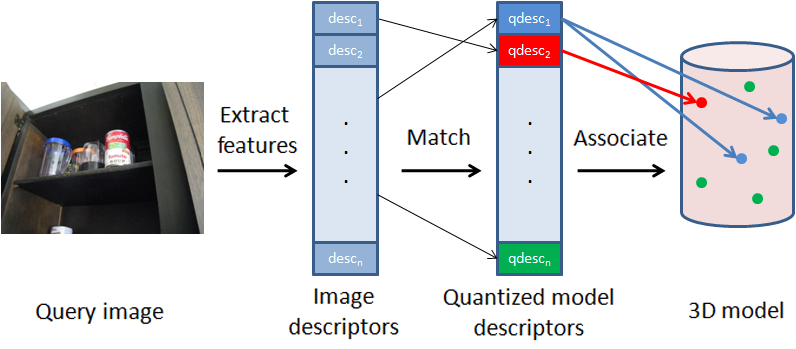 |
| Figure 1. Quantization framework. Features are extracted from a query image and then matched to a set of quantized model descriptors. Each quantized model descriptor is associated with all of its possible locations on the 3D model, which allows similar features to be matched. |
We propose to maintain feature ambiguity by quantizing the features on a model. Each quantized feature is associated with a descriptor and all of its possible model locations. These quantized features are still matched discriminatively, but the quantization allows us to associate a feature on a query image with multiple locations on a model. Because retaining feature ambiguity increases the potential number of outliers, we demonstrate an efficient way to handle these additional correspondences.
Another issue that arises in the real world is that objects in unstructured environments can appear in any orientation and position, often significantly different from the images used to train the model. Accounting for all possible viewpoints is infeasible, yet a 3D recognition system must still recover the object pose given a finite set of training images. In the past, this has been addressed by using affine invariant features, affine invariant patches and view clustering. Here we take the approach of simulating novel viewpoints and adding features extracted from affine transformed training images to our model. One problem with this approach is that the number of features on the model increases significantly, with many features having similar descriptors. We show that our quantization framework facilitates matching to these features and that handling viewpoint in this way can significantly increase the performance of 3D object recognition.
 |
| Figure 2. Example detections from our challenging dataset. The images were taken in cluttered environments with different lighting conditions and with the objects under various viewpoints and occlusions. The bottom two rows show the views used to generate the models for two objects. |
 |
| Figure 3. Averaged Precision/Recall plots: (left) Gordon and Lowe, (center) EPnP, and (right) Collet et al. For each plot, we show the improvements from simulated affine features (SA), quantization (Q) and the combination of the two (SA+Q). |
Dataset
The CMU Grocery Dataset (CMU10_3D) containing 620 images of 10 objects in cluttered household environments with ground truth. [ZIP 84MB]References
[1] Edward Hsiao, Alvaro Collet and Martial Hebert. Making specific features less discriminative to improve point-based 3D object recognition. IEEE Conference on Computer Vision and Pattern Recognition (CVPR) , June, 2010.
Funding
This material is based upon work partially supported by the National Science Foundation under Grant No. EEC-0540865. Edward Hsiao is partially supported by a National Science Foundation Graduate Research Fellowship.