Stochastic Process
- Classes of stochastic processes:
- White noise
- A continuous-time process is called white noise if for arbitrary n, sampling at arbitrary time instants t_1, t_2, ..., t_n, the resulting random variables, X_{t_1}, X_{t_2}, ..., X_{t_n} are independent, i.e., their joint pdf f(x_1, x_2, ..., x_n)= f(x_1)*f(x_2)*...*f(x_n).
- marginal distribution is enough to determine joint pdf of all orders.
- Gaussian processes:
- used to model noise
- white Gaussian noise: marginal pdf is Gaussian.
- colored (and wide sense stationary) Gaussian noise: characterized by marginal distribution and autocorrelation R(\tau).
- heavily used in communication theory and signal processing, due to 1) Gaussian assumption is valid in many practical situations, and 2) easy to obtain close-form solutions with Gaussian processes. E.g., Q function and Kalman filter.
- Poisson processes:
- used to model arrival processes
- heavily used in queueing theory, due to 1) Poisson assumption is valid in many practical situations, and 2) easy to obtain close-form solutions with Poisson processes. E.g., M/M/1 and Jackson networks.
- Renewal processes
- used to model arrival processes
- heavily used in queueing theory, e.g., M/G/1, G/M/1, G/G/1
- Markov processes:
- the queue in M/M/1 is a Markov process.
- Semi-Markov processes
- the queue in M/G/1 and G/M/1 is a semi-Markov process.
- Random walk
- Brownian motion
- Wiener process
- Diffusion process
- Self similar process, long range dependence (LRD) process, short range dependence (SRD) process
- Similar to Probability theory, the theory of stochastic process can be developed with non-measure theoretic probability theory or measure theoretic probability theory.
- How to characterize a stochastic process:
- Use n-dimensional pdf (or cdf or pmf) of n random variable at n randomly selected time instants. (It is also called nth-order pdf). Generally, the n-dimensional pdf is time varying. If it is time invariant, the stochastic process is stationary in the strict sense.
- To characterize the transient behavior of a queueing system (rather than the equilibrium behavior), we use time-varying marginal cdf F(q,t) of the queue length Q(t). Then the steady-state distribution F(q) is simply the limit of F(q,t) as t goes to infinity.
- Use moments: expectation, auto-correlation, high-order statistics
- Use spectrum:
- power spectral density: Fourier transform of the second-order moment
- bi-spectrum: Fourier transform of the third-order moment
- tri-spectrum: Fourier transform of the fourth-order moment
- poly-spectrum.
- Limit Theorems:
- Ergodic theorems: sufficient condition for ergodic property. A process possesses ergodic property if the time/empirical averages converge (to a r.v. or deterministic value) in some sense (almost sure, in probability, and in p-th mean sense).
- Laws of large numbers
- Mean Ergodic Theorems in L^p space
- Necessary condition for limiting sampling averages to be constants instead of random variable: the process has to be ergodic. (not ergodic property)
- Central limit theorems: sufficient condition for normalized time averages converge to a Gaussian r.v. in distribution.
- Laws of large numbers
- Weak law of large numbers (WLLN)
- Sample means converge to a numerical value (not necessarily statistical mean) in probability.
- Strong law of large numbers (SLLN)
- Sample means converge to a numerical value (not necessarily statistical mean) with probability 1.
- (SLLN/WLLN) If X1, X2, ... are i.i.d. with finite mean \mu, then sample means converge to \mu with probability 1 and in probability.
- (Kolmogorov): If {X_i} are i.i.d. r.v.'s with E[|X_i|]<infinity and E[X_i]= \mu, then sample means converge to \mu with probability 1.
- For {X_i} are i.i.d. r.v.'s with E[|X_i|]<infinity, E[X_i]= \mu, and Var(X_i)=infinity, then sample means converge to \mu with probability 1. But the variance of sample means does not converge to 0. Actually, the variance of sample means is infinity. This is an example that convergence almost sure does not imply convergence in mean square sense.
- Mean Ergodic Theorems:
- Sample means converge to a numerical value (not necessarily statistical mean) in mean square sense.
- A stochastic process is said to be mean ergodic if its sample means converge to the expectation.
- Central limit theorems (CLT)
- Normalized sample means converge to a Gaussian random variable in distribution.
- Normalized by the standard deviation of the sample mean.
- Like lim_{x goes to 0}x/x=1 (the limit of 0/0 is a constant), CLT characterizes that as n goes to infinity, (S_n-E(X)/(\sigma/sqrt(n)) converges to a r.v. N(0,1), i.e., convergence in distribution. By abusing notation a bit, lim_{n goes to \infty}(S_n-E(X)/(\sigma/sqrt(n)) = Y, the limit of 0/0 is a r.v.
- SLLN/WLLN is about the re-centered sample mean converging to 0. CLT is about the limit of 0/0.
- (Lindeberg-Levy): If {x_i} are i.i.d. and have finite mean m and finite variance \sigma^2 (\neq 0), then
the CDF of [(\sum_{i=1}^n x_i /n) - m]/(\sigma/\sqrt{n}) converges to a Gaussian distribution with mean 0 and unity variance.
- Comments: WLLN/SLLN does not require finite variance but they obtain convergence with probability and in probability, respectively; stronger than convergence in distribution in CLT. Why?
- The difference is that in WLLN/SLLN, sample means converge to a deterministic value rather than a random variable as in CLT. Since CLT also requires finite variance, CLT gives a stronger result than WLLN/SLLN. That is, WLLN/SLLN only tell that sample means converge to a deterministic value but WLLN/SLLN do not tell how sample means converge to the deterministic value (in what distribution?). CLT tells that the sample mean is asymptotically Gaussian distributed.
- Implication of CLT: The aggregation of random effects follows Gaussian distribution. We can use Gaussian approximation/assumption in practice and enjoy the ease of doing math with Gaussian r.v.'s.
- Proof1, Proof2
- What's the intuition of CLT? Why do we have this phenomenon (sample means converge to a Gaussain r.v.)?
- Non-identical case: If {x_i} are independent but not necessarily identically distributed, and if each x_i << \sum_{i=1}^n x_i for sufficiently large n, then
the CDF of [(\sum_{i=1}^n x_i /n) - m]/(\sigma/\sqrt{n}) converges to a Gaussian distribution with mean 0 and unity variance.
- Non-independent
case:
There are some theorems which treat the case of sums of non-independent variables, for instance the m-dependent central limit
theorem, the martingale central limit theorem and the central limit theorem for mixing processes. - How to characterize the correlation structure of a stochastic process?
- auto-correlation function R(t1,t2)=E[X(t1)X(t2)]
- For wide-sense (covariance) stationary process, R(\tau) = R(t1,t1+\tau) for all t1 \in R.
- If the process is a white noise with zero mean, R(\tau) is a Dirac delta function, the magnitude of which is the double-sided power spectrum density of the white noise. Note that the variance of a r.v. at any time in a white process is infinity.
- If R(\tau) is a Dirac delta function, then the r.v.'s at any two different instant are orthogonal.
- In discrete time, we have similar conclusions:
- If a random sequence consists of i.i.d. r.v.'s, R(n) is a Kronecker delta function, the magnitude of which is the second moment of a r.v.
- If R(n) is a Kronecker delta function, then the r.v.'s at any two different instant are orthogonal.
- R(t1,t2) characterizes orthogonality between a process' two r.v.'s at different instant.
- Cross-reference: temporal (time) autocorrelation function of a deterministic process (which is energy limited):
- R(\tau)= \int_{-infinity}^{+infinity} X(t)*X(t+\tau) dt
- Discrete time: R(n) = \sum_{i=-infinity}^{+infinity} X(i)*X(i+n)
- auto-covariance function C(t1,t2)=E[(X(t1)-E[X(t1)])(X(t1)-E[X(t1)])]
- For wide-sense (covariance) stationary process, C(\tau) = C(t1,t1+\tau) for all t1 \in R.
- If the process is a white noise, C(\tau) is a Dirac delta function, the magnitude of which is the double-sided power spectrum density of the white noise.
- If C(\tau) is a Dirac delta function, then the r.v.'s at any two different instant are (linearly) uncorrelated.
- In discrete time, we have similar conclusions:
- If a random sequence consists of i.i.d. r.v.'s, C(n) is a Kronecker delta function, the magnitude of which is the variance of a r.v.
- If C(n) is a Kronecker delta function, then the r.v.'s at any two different instant are uncorrelated.
- C(t1,t2) characterizes linear correlation between a process' two r.v.'s at different instant.
- C(t1,t2)>0: positively correlated
- C(t1,t2)<0: negatively correlated
- C(t1,t2)=0: uncorrelated
- mixing coefficient:
- Why is Toeplitz matrix important?
- The covariance matrix of any wide-sense stationary discrete-time process is Toeplitz.
- A n-by-n Toeplitz matrix T = [t_{i,j}], where t_{i,j}=a_{i-j}, and a_{-(n-1)}, a_{-(n-2)}, ... a_{n-1} are constant numbers. Only 2n-1 numbers are enough to specify a n-by-n Toeplitz matrix.
- In a word, the diagonals of a Toeplitz matrix is constant (constant-along-diagonals).
- Toeplitz matrix is constant-along-diagonals; circulant matrix is constant-along-diagonals and symmetric along diagonals.
- Toeplitz matrix: "right shift without rotation"; circulant matrix: "right shift with rotation".
- Why is circulant/cyclic matrix important?
- Circulant matrices are used to approximate the behavior of Toeplitz matrices.
- A n-by-n circulant matrix C=[c_{i,j}], where each row is a cyclic shift of the row above it. Denote the top row by {c_0, c_1, ..., c_{n-1}}. Other rows are cyclic shifts of this row. Only n numbers are enough to specify a n-by-n circulant matrix.
- Circulant matrices are an especially tractable class of matrices since their inverse, product, and sums are also circulants and it is straightforward to construct inverse, product, and sums of circulants. The eigenvalues of such matrices can be easily and exactly found.
- Empirical/sample/time average (mean)
- Borel-Cantelli theorem
- The first Borel-Cantelli theorem
- If sum_{n=1}^{\infty} Pr{A_n}<\infty, then Pr{limsup_{n goes to \infty} A_n}=0.
- Intuition (using a queue with infinite buffer size): if the sum of probability of queue length=n is finite, then the probability that the actual queue length is infinite is 0, i.e., the actual/expected queue length is finite with probability 1.
- E[Q]=sum_{n=1}^{\infty} Pr{Q>=n}, this is another way to compute expectation.
- The second Borel-Cantelli theorem
- If {A_n} are independent and sum_{i=1}^n Pr{A_i} diverges, then Pr{limsup_{n goes to \infty} A_n}=1.
1. First-order result (about mean): WLLN/SLLN
Question: Can we use the sample mean to estimate the expectation?
WLLN studies the sufficient conditions for![]() or
or ![]() (in probability). Let
(in probability). Let![]() . If WLLN is
satisfied for every
. If WLLN is
satisfied for every ![]() , the estimator is called a consistent estimator.
, the estimator is called a consistent estimator. ![]() .
.
- (Markov)
If
 , then
, then  ; i.e., convergence in mss implies convergence in
probability.
; i.e., convergence in mss implies convergence in
probability. - For
wide sense stationary LRD process with
 and
and 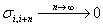 , we have
, we have  . So in this
LRD case, sample mean is a consistent estimator.
. So in this
LRD case, sample mean is a consistent estimator. - (Khintchin)
If
 are iid random
variables with
are iid random
variables with  (and possibly infinite variance), then
(and possibly infinite variance), then  . Note that
here
. Note that
here converges in probability even if
converges in probability even if  does not
converge in mss (infinite variance case).
does not
converge in mss (infinite variance case).
SLLN studies the sufficient conditions for ![]() (with probability 1).
(with probability 1).
- (Kolmogorov)
If
 are iid random
variables with
are iid random
variables with  (and possibly infinite variance), then
(and possibly infinite variance), then  . Note that
here
. Note that
here converges with probability 1 even if
converges with probability 1 even if  does not
converge in mss (infinite variance case).
does not
converge in mss (infinite variance case).
2. Second-order result (about variance): convergence in mss and CLT
- Mean
ergodic theorem:
 .
. - Mean
ergodic theorem (wide sense stationary, WSS): Let
 be WSS with
be WSS with  . If
. If  and covariance
and covariance , then
, then  .
. - For
LRD process with
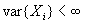 and
and 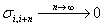 , we have
, we have  . So in this
LRD case, as the number of samples increases, the variance of the
estimator (sample mean) reduces.
. So in this
LRD case, as the number of samples increases, the variance of the
estimator (sample mean) reduces. - LRD
with covariance matrix
 has
has  , i.e., the variance of the estimator does not reduce
due to more samples.
, i.e., the variance of the estimator does not reduce
due to more samples. - LRD
with covariance matrix
 has
has  , i.e., the variance of the estimator does not reduce
to 0 due to infinite samples.
, i.e., the variance of the estimator does not reduce
to 0 due to infinite samples. - SRD
process always has
 since
since  implies
implies  .
. - Note that mean ergodic theorem only tells the condition for the variance of the sample mean to converge but does not tell the convergence rate. We expect a good estimator has a fast convergence rate, i.e., for a fixed n, it should have small variance; in terms of convergence rate, we know the relation iid>SRD>LRD holds, i.e., iid sequence has the highest convergence rate.
- CLT:
- Motivation:
WLLN tells the first-order behavior of the estimator, sample mean; i.e.,
sample means converge to the expectation and we have unbiased estimator
since
 Mean ergodic
theorem tells the second-order behavior of the estimator; i.e., the variance
of the sample means converges to 0.
The next question is: what about the distribution of the
estimator? This is answered by
CLT.
Mean ergodic
theorem tells the second-order behavior of the estimator; i.e., the variance
of the sample means converges to 0.
The next question is: what about the distribution of the
estimator? This is answered by
CLT. - (Lindeberg-Levy
CLT): If
 are iid random
variables with
are iid random
variables with  and
and  , then
, then  , where Y is a normal random variable with mean
, where Y is a normal random variable with mean  and variance
and variance  .
. - Denote
 . I.e.,
. I.e.,  , where
, where  is a normal
random variable with zero mean and unity variance.
is a normal
random variable with zero mean and unity variance. - How to use CLT: given the normal distribution of the estimator (sample means), we can evaluate the performance of the estimator (e.g., confidence interval). That is, CLT provides approximations to, or limits of, performance measures (e.g., confidence interval) for the estimator, as the sample size gets large. So, we can compute the confidence interval according to the normal distribution.
- Since
 , we also have
, we also have  . Then we can
compute the confidence interval of
. Then we can
compute the confidence interval of  .
. - CLT does not apply to self-similar processes since the randomness does not average out for self-similar processes. The sample means have the same (non-zero) variance; i.e., even if the number of samples goes to infinity, the variance of the sample mean does not go to zero.
- CLT
only use the expectation and variance of the sample mean since the sample
mean is asymptotically normal.
High order statistics of the sample mean are ignored. Why is the limiting distribution
Gaussian? In the proof
using moment-generating function, we see that the high-order terms
 are gone since
first order and second order statistics dominate the value of the
moment-generating function as n goes to infinity. Intuitively, first order and second
order statistics can completely characterize the distribution in the
asymptotic region, since the randomness is averaged out; we only need to
capture the mean and variance (energy) of the sample mean in the
asymptotic domain. Gaussian
distribution is maximum entropy distribution under the constraints on
mean and variance.
are gone since
first order and second order statistics dominate the value of the
moment-generating function as n goes to infinity. Intuitively, first order and second
order statistics can completely characterize the distribution in the
asymptotic region, since the randomness is averaged out; we only need to
capture the mean and variance (energy) of the sample mean in the
asymptotic domain. Gaussian
distribution is maximum entropy distribution under the constraints on
mean and variance. - What about LRD, subexponential distribution, heavy-tail distribution?
- Large deviation theory
- Motivation:
WLLN tells
 But it does
not tell how fast it converges to zero.
Large deviation theory characterizes the convergence rate. Why is this important? Because in many applications, we need
to compute the probability of a rare event like
But it does
not tell how fast it converges to zero.
Large deviation theory characterizes the convergence rate. Why is this important? Because in many applications, we need
to compute the probability of a rare event like  where
where is large.
is large. - Large
deviation principle (LDP) is about computing a small probability
 for sufficiently large n, more specifically,
for sufficiently large n, more specifically, or
or  for
a>E[X]. LDP characterizes the
probability of a large deviation of
for
a>E[X]. LDP characterizes the
probability of a large deviation of  in the order
in the order 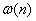 about the
expectation n*E[X]; i.e., a large deviation of
about the
expectation n*E[X]; i.e., a large deviation of  in the order
in the order  about the
expectation E[X].
about the
expectation E[X]. - In
contrast, CLT is for computing
 . It
characterizes the probability of a small deviation in the order
. It
characterizes the probability of a small deviation in the order  about the expectation. As n goes to infinity,
about the expectation. As n goes to infinity,  goes to 0; so
it is a small deviation with respect to a fixed expectation. On the other hand, this deviation
goes to 0; so
it is a small deviation with respect to a fixed expectation. On the other hand, this deviation 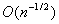 is in the same
order of the variance of the sample mean, so that this deviation
normalized by the variance is still finite.
is in the same
order of the variance of the sample mean, so that this deviation
normalized by the variance is still finite. - For
LRD process with
 and
and  , even though we have WLLN, i.e.,
, even though we have WLLN, i.e.,  , the probability
, the probability  does not
satisfy large deviation principle (i.e., the convergence rate is not
exponential). We need to
compress the time axis to obtain large deviation principle.
does not
satisfy large deviation principle (i.e., the convergence rate is not
exponential). We need to
compress the time axis to obtain large deviation principle.
White Gaussian noise:
- The
auto-correlation function:
 .
. - The
power spectral density:

- The
marginal PDF is Gaussian with zero mean, infinite variance. If the white Gaussian noise passes a
filer with frequency response H(f) in frequency band [-B,B], the resulting
marginal PDF is Gaussian with zero mean, variance
 .
.
Given a state
equation and observation equation of a system,
x_{n+1} = A* x_n + v_n
y_n = B * x_n
where A and B are
invertible square matrices, and v_n are i.i.d. and independent of x_n, then the
observation y_n is a Markov chain (not a general HMM). Since y_{n+1}=B* x_{n+1} = B*A* x_n + B*
v_n = B*A* B^{-1} * y_n + B* v_n, hence y_n is a Markov chain, i.e., the next
state is independent of the past, given the current state.