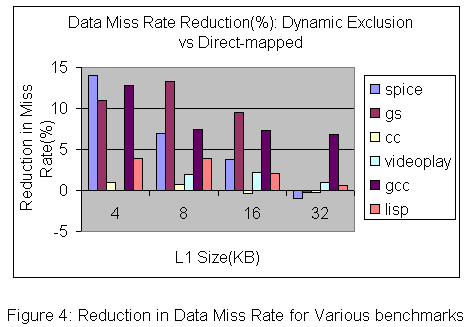
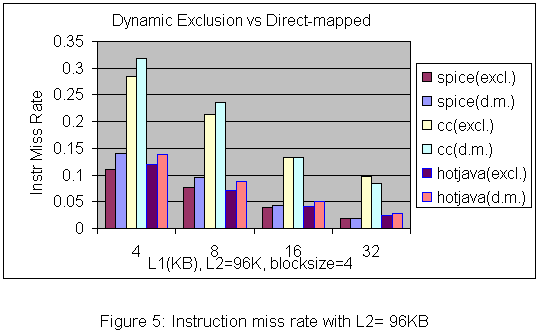
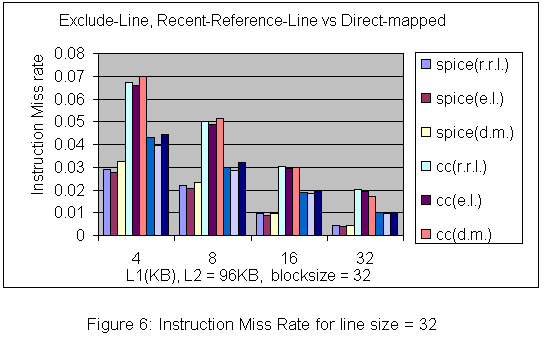
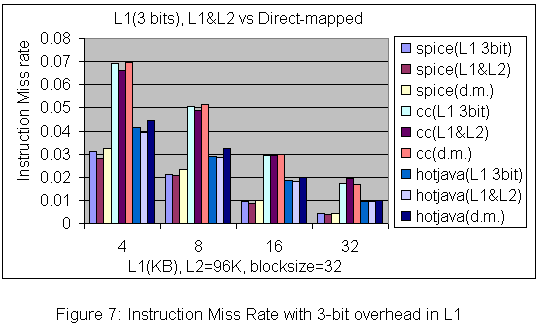
Originally discussed in a Technical Report of Western Research Laboratory
(Digital Equipment Corporation) by Scott McFarling[1], this policy tries
to recognize the instruction reference patterns and emulate the behavior
of an optimal direct-mapped cache. For the time being, we will assume each
cache line can hold only one instruction at a time. The policy for larger
cache line will be discussed later.

The Dynamic Exclusion Replacement policy is a simple hardware technique
that reduces the number of misses by dynamically determining which instructions
should be excluded from the cache. It uses a small finite-state machine(FSM)
to recognize the instruction reference patterns.
In this implementation, each cache line at the Level 1 (L1) is associated
with a hit-last bit 'h[]' and a sticky bit 's'.
The cache line at Level 2 (L2) contains only 'h[]' bit. The sticky
bit allows the cache to retain the instruction during the execution of
a conflicting instruction. Whenever there is a hit, the sticky bit is set.
In general an instruction is held in the cache while the sticky bit is
set. The sticky bit is reset whenever there is a miss. Therefore, two sequential
misses to a cache line will always remove an instruction from the cache.
The hit-last bit tells whether an instruction hit the last time it was
in the cache. This enables some instructions to be brought immediately
into the cache even when the sticky bit is set for the conflicting instruction.
Whenever an instruction is not in the L1 cache, the next level cache (L2)
or the lower level of memory hierarchy holds its hit-last bit. Hence, the
hit-last bit is set on every access to the L1 cache. This bit is transferred
to the L2 cache whenever that instruction in the L1 cache is replaced.
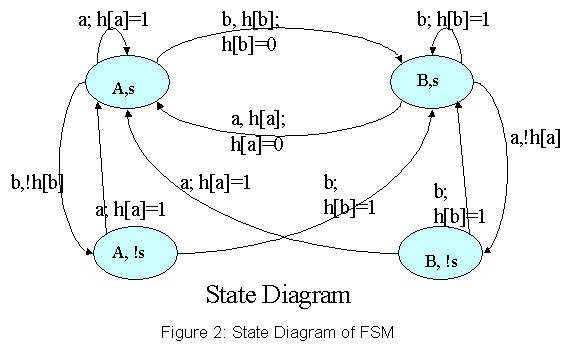
The state diagram in the Figure 2 describes the Dynamic Exclusion policy
in detail, for two conflicting instructions 'A' and 'B'.
The states 'A' and 'B' indicate instruction 'A' or 'B' is in the cache
respectively. The '!s' and 's' denote whether the sticky bit associated
with the current cache line/instruction is reset or set respectively.
The symbol 'h[p]' stands for the hit-last bit of the instruction p. For
example, the state 'A,s' means the instruction 'A' is in the L1 cache with
'sticky' bit set. There are overall four states in the L1 cache for two
conflicting instructions 'A' and 'B'.
The state diagram will be understood clearly by examining the behavior
of the three common instruction reference patterns described earlier.
One important to note is , the bit h[] does not always mean that
the relevant instruction hit the last time in the L1 cache. e.g., the transition
from 'A, !s' to 'B, s' does not alter the 'h[]' bit of 'A'
. Rather it remains set. Again, the 'B, s' to 'A, s' does reset the 'h[]'
bit of A. This aberration helps more random references to be included in
the cache faster so that performance doesn't fall with respect to conventional
direct-mapped cache in those types of references.
2.3 Dinero Simulation Methodology
In order to verify the Dynamic Exclusion Replacement Policy, the simulation
tool dinero was used. Dinero[3], as written by Mike D.Hill of the University
of Wisconsin, implements only conventional direct-mapped replacement policy
along with FIFO, LRU and Random for the set-associative caches. Two extra
bits 'sticky' and 'hit' were added in the 'stack-node' data structure
in the stack based cache implementation of dinero. In order to simulate
the L2 cache or the next level of memory hierarchy, the hit-last bit was
stored in another stack of infinite size. Effectively, the next level of
memory hierarchy was assumed to be of very large size so that during a
cache miss, the corresponding hit-last bit would be searched in the has
table and would be used by the finite state machine in order to simulate
the Dynamic Exclusion Replacement Policy. The pseudo-code for the algorithm
is given below. The first part deals with the cache miss and the second
part deals with the cache hit.